Prioritized Direction based Switch for Bufferless
Network on Chip Architecture
Sajid Gul Khawaja
College of Electrical and Mechanical Engineering E-mail: [email protected]Mian Hamza Mushtaq
Member, IEEE E-mail: [email protected]Dr. Shoab A. Khan
College of Electrical and Mechanical Engineering E-mail: [email protected]Abstract--- This paper represents a bufferless Network on Chip (NoC) architecture for a generic multi-array based architecture. A weighted priority based routing technique will be employed that handles contention based on destination direction. The results will represent the comparative effectiveness of the design with a XY based switch.
Matrix multiplication application is tested and mapped as the process entities (PEs) to demonstrate the effectiveness of the NoC design. The NoC architecture is synthesized and tested on FPGA platform as a prototype.
Index Term --- Bufferless, Routing Scheme, NoC, SoC
I. INTRODUCTION
In Multi-Processor-System-On-Chip (MpSoC), the system is comprised of multiple processors and functional units. In the past, inter-module on-chip was mostly based on shared buses between various masters and slaves. This communication approach is feasible for a system with a small number of modules. However, recent systems which require high volume transfer of data between multiple modules across the chip are not straightforwardly serviced by bus based interconnects. To serve the communication needs of such large systems scalable-packet-switched Network-on-Chips (NoC) [1] have been developed. NoC provides a feasible solution to handle the performance and the scalability issues, and is actively studied in academia [12, 13, 14, and 15].
Bufferless deflection scheme has been a point of recent studies [3, 4, 5, and 6] in on-chip networks. On-chip wires are cost effective and buffer cost is much significant [1] than off-chip networks making it a feasible alternative. Queuing at router buffers is done via router buffers when packets or flits cannot be routed immediately due to contention [7]. Several techniques, introduction of virtual channels, deflection or dropping flits, are used to eliminate router buffers to reduce the NoC cost [11]. These bufferless schemes drop or retransmit the packet or flit from the source [9] or round-robin based deflection [10, 6] to a free output port in case of contention.
The routing algorithm is one of key research areas of a NoC design. XY routing scheme is a distributed deterministic routing algorithm where decision about the output port is made
switch address. XY routing algorithm is simple to implement. Drawback of XY routing scheme is that it resorts to packet drop incase of a deadlock which acts as a bottleneck in the performance of the NoC architecture. Wang Zhang et al, compares common XY and Odd-even (OE) routing algorithms in [16]. Wang Zhang et al proposed OE routing algorithm in [16] which is complex to implement but provides better deadlock-free communication to the network. Keeping the issue of deadlock in our mind we have proposed prioritized direction based scheme which improves the route assignment after deflection to minimize delay without resorting to packet
drop.
The rest of this paper is organized as follows: Section II provides the necessary background on bufferless interconnects and sets the context of our proposed design. Section III discusses our architecture for the NoC. Section IV presents our novel routing scheme. Section V discusses the comparative results of our technique compared to a reference design. Section VI discusses the implementation of Canon’s algorithm as process entities on our design. Section VII discusses the implementation of our design on hardware. Finally, Section VIII provides a summary of our work and future directions.
II. BACKGROUND
the assimilated packets to be resent after the desired port becomes free on average results in a comparable increase in latency to deflection based routing. Therefore bufferless NoCs are an energy and area cost-efficient alternative to their buffered counterparts.
A. Weighted priority contention resolution
The concept of weighted priority is that multiple checks are made by the allocator, in the switch, to assign an output port to packets in case of contention. Our proposed allocator design first considers the direction of the destination node of each packet; it then assigns a weight to packet based on the direction which has the shortest distance to the destination. Any contention of weights at this point is resolved by comparing hop count of the packets causing contention. If still there is any further contention it is resolved in a round-robin fashion. Thus, distance which the packet has to travel due to being deflected is minimized.
III. NOC’S ARCHITECTURE
Main design of our NoC architecture comprises of the following components: Switch, Transmission control unit, FIFO (optional), and Communication controller. Figure 1 shows the bottom up layered architecture of our design.
The architecture for our proposed design was carefully structured after exploring different options. The architecture can handle two modes of transmissions; one which require acknowledgments from the destination (analogous to TCU), as well those which do not require acknowledgement (analogous to UDP). These different modes of communication are handled by a single optional component called the Transmission control unit.
Fig. 1. Bottom up Layered Architecture
B. Communication Controller:
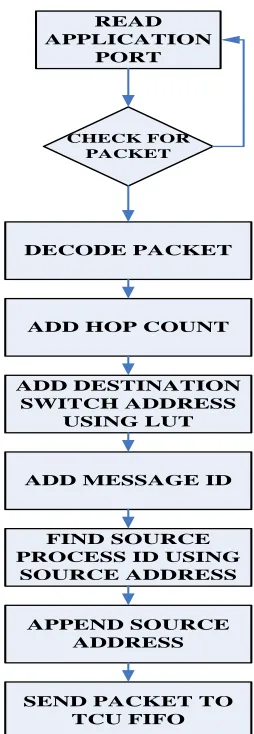
Communication controller is part of the network interface unit. The controller receives packets from the application and uses a look up table to determine the network address of the packet destination. It then translates the packet into a form which is usable by the network, adding header, address and control information to the original packet, finally the packet is inserted into a FIFO for injection into the network. The communication controller also handles the inverse process, where it receives a packet from the network, and with appropriate de-packaging steps it is forwarded to the application.
READ APPLICATION
PORT
CHECK FOR PACKET
DECODE PACKET
ADD HOP COUNT
ADD DESTINATION SWITCH ADDRESS
USING LUT
ADD MESSAGE ID
FIND SOURCE PROCESS ID USING
SOURCE ADDRESS
APPEND SOURCE ADDRESS
SEND PACKET TO TCU FIFO
Fig. 3. Flow Diagram showing packetization of Data
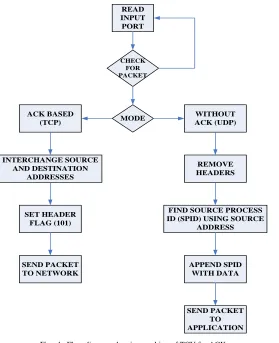
C. Transmission Control Unit (TCU):
The transmission control unit is an optional unit for the network interface units, which functions to control packet transmissions where an acknowledgment is required from the destination. At the source node, it waits to receive an acknowledgement of the last set packet before ejecting the next packet in queue to the network. At the destination node, the TCU sends the acknowledgment packet if the corresponding flag is set in the packet. Identification of acknowledgment address at the destination end is determined by the address of the source node which is appended in the packet from the
source. TCU handles the cases where acknowledgements are needed to send and receive. By keeping the design modular, the same network can have transmissions which may or may not require acknowledgement packets.
Figure 4 shows the flow diagram that illustrates working/functionality of the TCU for acknowledgment handling
CHECK FOR PACKET
MODE READ INPUT PORT
ACK BASED (TCP)
WITHOUT ACK (UDP)
INTERCHANGE SOURCE AND DESTINATION
ADDRESSES
REMOVE HEADERS
SET HEADER FLAG (101)
FIND SOURCE PROCESS ID (SPID) USING SOURCE
ADDRESS
APPEND SPID WITH DATA
SEND PACKET TO APPLICATION SEND PACKET
TO NETWORK
Fig. 4. Flow diagram showing working of TCU for ACK
IV. SWITCH ALLOCATOR DESIGN
We propose a change in the bouncing routing algorithm which elevates the performance rate of the bufferless NoC architecture. The proposed model uses weighted priority based contention resolution as a mean to improving the success rate of the packets by minimizing the chance that the packets are routed in an unprofitable direction.
A. Architecture:
Decision for the selection of output port of a packet has been made on the bases of a directional-priority. This weight assignment technique has been utilized in the directional-priority mechanism. The purpose of this directional-priority is to assign a productive direction to the packets even in case of a collision at the router. Priority, from 1 to 8, is assigned to the packet depending upon the direction of the destination node from the current router. Directional priority is then used to assign output direction to the packet, e.g. if a packets destination node exists at North-East direction, directional priority 2 is assigned to that packet. Using this value (2) packet is assigned North as the probable output direction for that packet.
Fig. 5. Shows how directional priority is assigned based on the direction packet
want to travel
Fig. 6. Example case for clash in direction
Our proposed technique is designed to resolve the deadlock/contention by routing the, deadlock causing, packets to another output node in such a way that the distance from the destination node is not affected. Assuming that if the priority function assigns the Eastern output port to the two packets; both the packets cannot still be routed to the same output port. Now the decision of which packet is to given priority lies with the hop count of the packets. If the hop count of the packet from the northern input is greater than that of the packet from the western input then the former is given priority whereas packet from West is reassigned to the Southern output. Directional priority is utilized for assigning a new productive direction to the iWest packet. Thus it is routed via the southern output so that the packet keeps moving towards its destination which lies in the South Eastern direction. Incase if the hop count of both the packets is same then the packet from the North is given priority over the packet from West and are thus routed accordingly.
V. EXPERIMENTATION AND RESULTS (XY SWITCH VS. WEIGHTED PRIORITY):
Simulations on MODELSIM were carried out to check the functionality of NoC architecture using our proposed switch design. The results were then compared against the common XY switch which uses XY routing scheme. A 3*2 mesh size was set for the network and test traffic was generated at different based with the destination sources for the packets selected by a random criteria. The results for average latency and success rate are plotted.
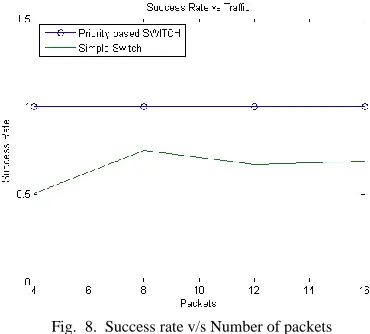
As can be seen from the results the weighted priority shows lower average latency as a result of the allocation decisions. From the second graph, the success rate of the packets for weighted priority remained at 100% even when injection rate became 333% of the given mesh size. This means the packets were not getting stuck in endless deflection loops, also known as livelocks, due to the weighted priority mechanism. This is not true for the case of the XY switch as can be see from the results.
Figure 7 compares the average latency, with respect to the network traffic, of XY switch and our proposed switch.
Fig. 7. Average Latency v/s Number of packets
Figure 8 compare the success rate of the designs, XY and our proposed switch.
Fig. 8. Success rate v/s Number of packets
The switch designs were synthesized for a Vertex’s device for same packet length. Results for Area and maximum Frequencies of both the design units are listed in the table below.
TABLE I
AREA AND FREQUENCY COMPARISON
Serial # Area and Frequency Comparison
Design Type Area Frequency
1 Priority Based Deign
6061 out of 122880 (4%)
85.667MHz
2 XY switch
5353 out of 122880 (4%)
94.029MHz
design could be made for a fair comparison, but this is beyond the scope of this paper.
A. Tradeoff between XY and Weighted Priority Switch From the above stated results tradeoff between different parameters, latency, throughput, area, frequency and success rate can be made.
Weighted priority switch is designed to provide deadlock free communication and a lower ratio of dropped packets against injection rate whereas XY does not guarantee deadlock free communication and it has higher ratio of dropped packets against injection rate. Weighted priority switch provides better throughput than XY switch as significantly lower number of packets are dropped in case of deadlock\contention.
Average latency of a weighted priority switch is lower than or at most equal to the XY switch. Average latency depends directly on how many packets are to be retransmitted. While weighted priority resolves the deadlock issues by providing a more feasible route to the packet thus avoiding packet drop, it can result in an increase in packets’ latency. Incase of a XY switch a deadlock is resolved by dropping the packet thus that packet has to be retransmitted. Retransmission causes excessive latency thus causing a higher average latency than weighted priority switch. In the above design latency is lowered by approximately 36% via using weighted priority switch for 333% injection rate of the given mesh size.
Contention resolution in weighted priority switch requires extra logic than a normal XY which causes an increase in area. The area cost for weighted priority switch is not very significant; in this design approximately 13% increase in area was observed.
Synthesized frequency for the weighted priority switch is affected as more logic means more combinational delay and a larger critical path for the design, thus weighted priority design results in a lower frequency than an XY switch. In this design approximately 10% decrease in frequency was observed.
VI. IMPLEMENTATION OF PARALLEL MATRIX MULTIPLICATION USING CANON’S ALGORITHM ON NOC ARCHITECTURE: Parallel algorithm has been implemented on our architecture as an example of a multiple processor system on chip. Parallel matrix multiplication algorithm was selected as functional node units which are connected via the NoC. There exist a number of algorithms which deal with parallel block multiplication of matrix. We implemented Cannon's Algorithm as it is based on message passing and is an efficient algorithm.
By splitting communication from the computation of the parallel matrix, a scalable framework could be designed with code manageability for future implementations of various parallel matrix algorithms. This can be done without modifying the communication (NoC) part of the implementation.
Fig. 9. Matrix Layout
Each block of the matrix in the figure, e.g. P0, P3, P5 etc represents a sub-matrix. We have implemented matrix multiplication for a 9x9 matrix. Our sub-matrix size is “3x3”. Thus, each block of the matrix is representing a 3x3 matrix. These sub-matrices have been mapped onto 9 processors. Therefore each processing entity has one sub-matrix representing blocks An, Bn, and Cn each. From an architectural point of view, the NoC enables the processing entities to communicate directly with adjacent processing entities across rows and columns as well as indirectly with all other processing entities.
Fig. 10. State Diagram representation of Canon’s Algorithm
A. Constraints
Canon's algorithm is complex to implement as generalized algorithm. This however may be done by using the following constraints
• All matrices are assumed to be square.
• The decomposition of input matrices is also done into square sub-blocks.
• The sub-matrix size should be multiple of main matrix size.
In order to determine the actual implementation complexity and network performance, we used ModelSIM tool to simulate our design. Simulations have been done by initializing the state machine that sends number of packets through network based on the canon’s algorithm.
VII. IMPLEMENTATION ON FPGAPLATFORM
practical feasibility of our design. Canon’s algorithm was used as an application to test the functionality of the network.
When we were planning for basic NoC prototype, we first started with a larger network, but the design took a very large amount of hardware resource. For this reason the network parameters, such as mesh size and packet length, were scaled down. Though scaling down leads to a small prototype yet it demonstrates the functionality of our design on hardware.
VIII. CONCLUSION
A weighted priority based mechanism was proposed for bufferless network on chips for a generic multi-array based architecture. The goal was to improve the success rate of the packets and minimize the additional latency caused by deflected routing. The implementation was compared to a XY based bufferless NoC and the results highlighted the effectiveness of our design. Further, the packets were shown not to be effected by livelocks. A parallel matrix algorithm was mapped to process entities and synthesized on FPGA platform. In future work we plan to work on cost-efficient and optimized Network on chips for FPGA platforms.
REFERENCES
[1] W. J. Dally and B. Towles, “Route packets, not wires: On-chip interconnection networks,” in Proc. of the 38th annual Design Automation Conf., 2001.
[2] Thomas Moscibroda and Onur Mutlu, A Case for Bufferless Routing in On-Chip Networks, 2009
[3] M. Millberg, R. Nilsson, R. Thid, and A. Jantsch. Guaranteed bandwidth using looped containers in temporally disjoint networks within the Nostrum network on chip. In DATE, 2004.
[4] Z. Lu, M. Zhong, and A. Jantsch. Evaluation of on-chip networks using deflection routing. In GLSVLSI, 2006
[5] C. Gomez, M. E. Gomez, P. Lopez, and J. Duato. Reducing packet dropping in a bufferless NoC. In Euro-Par, 2008.
[6] C. Gomez, M. E. Gomez, P. Lopez, and J. Duato. A bufferless switching technique for NoCs. In Wina, 2008.
[7] W. J. Dally, “Virtual-channel flow control,” IEEE Trans. on Parallel and Distributed Systems, vol. 3, no. 2, 1992.
[8] S. Tota, M. R. Casu, and L. Macchiarulo. Implementation analysis of NoC: a MPSoC trace-driven approach. In GLSVLSI-16, pages 204{209, New York, NY, USA, 2006. ACM.
[9] C. G´omez, M. E. G´omez, P. L´opez, and J. Duato, “Reducing packet dropping in a bufferless NoC,” in Proc. of the 14th intl. Euro-Par conf. on Parallel Processing, 2008
[10] P. Baran, “On distributed communication networks,” in IEEE Trans. on communication systems, 1964.
[11] George Michelogiannakis, Daniel Sanchez, William J. Dally, Christos Kozyrakis “Evaluating Bufferless Flow Control for On-Chip Networks”
[12] M. Dall’Osso, G. Biccari, L. Giovannmi, D. Bertozzi, and L. Benini, “xpipes: a Latency intensive Parameterized Network-on-chip Architecture for Multiprocessor SoCs”, International conference on Computer Design 2003, pp.536-539
[13] M. Millberg, E. Nilson, R. Thid, S. Kumar, and A. Jantsch,”The Nostrum backbone-a communication protocol stack for networks on chip” Proceeding of the VLSI Design Conference, Jan. 2004, pp. 693-696
[14] K. Srinivasan, K. S. Chatha, “A low complexity heuristic for design of custom network-on-chip architectures”, DATE 2006, pp.130-135
[15] K. Srinivasan , K. S. Chatha and G. Konjevod "Linear programming based technique for synthesis of network-on-chip architectures", IEEE TVLSI, April 2006, vol. 14, pp. 407-420 [16] Wang Zhang, Ligang Hou, Jinhui Wang, Shuqin Geng and