A GENERATOR BASED ASSOCIATIVE
CLASSIFIER FOR IMBALANCED
DATASETS
SIREESHA RODDA
CSE Department, GITAM Institute of Technology, GITAM University Visakhapatnam, Andhra Pradesh, INDIA
PROF. SHASHI MOGALLA
CSSE Department, College of Engineering, Andhra University, Visakhapatnam, Andhra Pradesh, INDIA
Abstract :
In this paper, a new variant of Associative Classifier has been proposed. Most Associative Classifiers perform classification on Class Association Rules obtained from a complete set of Frequent Itemsets. The main disadvantage of associative classifiers is that huge number of class association rules are generated. Handling large set of class association rules is a challenging problem. In this paper, a new framework has been proposed which uses class association rules generated from a complete set of frequent generators. The classification rules thus obtained are smaller in size, lesser in total number and non-redundant in nature when compared to those obtained from classification rules generated by a complete set of frequent itemsets. Furthermore, the scalability of the classifier is ensured by the use of trie datastructure to store the set of frequent generators which directly represent the class association rules in this case. Experiments and comparison against classifiers like C4.5and variants on imbalanced and balanced data confirm our claims.
Keywords: Associative Classification, Association Mining, Frequent Generators, Imbalanced Dataset
I. INTRODUCTION
Rule-based Classifiers have the advantage of easy interpretability when compared to other classifiers. Associative Classifiers[2] are popular rule-based classifiers apart from Decision Trees[9]. Initially, a classification model is built using training dataset. Each of the training examples are represented in terms of the values of the set of attributes and the class to which the training example belongs. Generally, Association Mining (AM)[1] refers to the task of finding the complete set of frequent itemsets from which class association rules are generated based on their association with the pertinent class labels. Associative Classification deals with the set of features as itemsets and applies Association Mining techniques to discover set of frequent itemsets that occur in the training dataset based on a user specified minimum support threshold. An associative classifier uses the Class Association Rules (CARs) generated by Association Mining to predict the class label of an unseen instance.
Once the classification model is built using CARs, it is evaluated on the test data. It has been shown that Associative Classifiers show better performance than other classifiers. The rules generated by the classifier are understandable to the human user. However, Associative classifiers suffer from a disadvantage that the number of CARs is often huge. This considerably increases the time taken to build classification model. Also, care must be taken to eliminate redundant rules when they are generated. Even after rule pruning, the number of classification rules is still large.
metrics used for comparing the performance of various classifiers. Section 5 presents and analyzes the results obtained while comparing them with the performance of other classifiers. Section 6 presents conclusions.
II. RELATED WORK
Associative Classification was first proposed by Ali K. et.al.[3] which uses partial classifiers based on associations. CBA[1] is a classical associative classifier which essentially operates in two steps. First step generates all Class Association Rules (CARs) based on Apriori-based algorithm. The CARs are then sorted in the order of precedence. In the second step, the rules are selected to build the classifier. The test instance is assigned the class of the matching rule with highest precedence.
The Associative Classification technique provides simple, easy to understand CARs. Several studies[4,5,6,7,8] have shown that Associative Classifiers can achieve accuracy similar to or higher than other traditional classification techniques like C4.5[9]. However most Associative Classification techniques face the difficulty of mining huge number of CARs. This is due to the large number of Frequent Itemsets generated by the Association Mining algorithm. The task of Association Mining is to find the set of all frequent itemsets that satisfy a minimum support threshold. The number of frequent itemsets can be undesirably large, especially in the case of dense datasets. Generating large number of itemsets increases the computation cost and I/O cost. Increasing the minimum support threshold might reduce the number of frequent itemsets but some useful itemsets maybe missed because they fail to pass the minimum support threshold. Decreasing the minimum support threshold might generate unmanageable number of frequent itemsets. Hence, a compressed representation is necessary which would result in manageable size of interesting patterns, devoid redundancy, even when the minimum support threshold is low.
Several works have proposed to eliminate redundancy from a complete set of frequent items, which include frequent closed itemsets[10] and generators[11]. Frequent closed itemsets are the maximal itemsets among the itemsets appearing in the same set of transactions, and generators are the minimal itemsets. Several studies[12,13] show that the frequent closed itemsets are condensed representation of complete set of frequent itemsets. The number of frequent closed itemsets is much smaller than total number of frequent itemsets. However, frequent closed itemsets still contain some amount of redundancy. Generators are minimal itemsets among itemsets appearing in the same set of transactions. Generators are non-redundant and concise in nature. The set of generators in a dataset uniquely represents the patterns in the dataset. Though the number of generators obtained can be little more than the number of frequent closed itemsets, the length of a classification rule based on generators is on average smaller than the length of a classification rule based on frequent closed itemsets. Generators are a concise, loss-less and non-redundant representation of all frequent itemsets for the purpose of generating association rules [13]. In this paper, we propose to develop Associative Classifier from generators and prove that the set of class association rules thus generated is much more effective compared to the set of class association rules generated from all frequent itemsets. To the best of our knowledge, no previous work has considered using Associative Classifier based on frequent generators.
III. METHODOLOGY
Let D be the set of transactions where each transaction T is a set of items (I). A transaction T is said to contain an itemset X if
X
T
.a)Association Rules
An Association rule is of the form X Y where
X
I
,Y
I
and X∩Y=∅. The rule XY has support s in transaction database D if s% of the transactions in D containX
Y
. The rule X Y has confidence c in the transaction dataset if c% of the transactions in D that contain X also contain Y. Association Rule Mining is the problem of discovering all the association rules whose support and confidence are greater than the user specified minimum support and minimum confidence respectively.b)Class Association Rules
c) Closed Itemsets
Let I be an itemset, the Closure operator is defined in terms of the following functions: σ(I)={t
TrDB|
i
I, i
t}, returns set of all the tuples that contain all items in If(T)= { i
R |
t
T, i
t}, returns all the items that are included in all the transactions of TClosure operator, c(I)= f(σ(I)), returns set of all the items appearing in all the transactions in which all the items in Itemset I has appeared.
An Itemset is closed if and only if c(I)=I.
An itemset I is closed iff for all proper supersets J, σ(I) is a proper superset of σ(J). A closed itemset that is frequent is called Frequent Closed Itemset.
d) Generators
An itemset I is a generator of a closed itemset J if it is one of the smallest itemsets with c(I)=J.
Definition: An Itemset l is a generator if there does not exist l´ such that l´
l and support(l´)=support(l). According to the above definition, the empty set
is a generator in any dataset. If an itemset is generator and has support atleast as minimum support, then the itemset is called a frequent generator.Generators also satisfy the anti-monotone property: If l is not a generator, then
l´
l, l´ is not a generator. The cardinality of generators will be greater than or equal to that of closed itemsets as there will be atleast one generator for each closed itemset.e) Tries
The data structure trie[26,27] has been used successfully in previous works[28] for suitable storing and easy retrieval of frequent itemsets. In frequent itemset mining, determining the support of itemsets is a quick process. In frequent itemset mining, a link is labeled by a frequent item and a node represents an itemset, which is the set of items in the path from the root to the leaf. The label of a node stores the counter of the itemset that the node represents.
This paper uses Generator-based Associative Classifier framework for classifying datasets. It adopts the concept of finding generators from GcGrowth Algorithm[14]. Conventional Associative Classification techniques generate Class Association Rules resulting from all frequent itemsets. The disadvantage of this approach is the huge number of frequent itemsets resulted from Association Mining, which in turn generate large number of class association rules. Even if pruning is applied, the number of frequent itemsets is still large. Frequent closed itemsets and frequent generators are two alternatives for condensing the set of frequent itemsets, in order to represent them concisely and in a loss-less manner[15]. Though the number of frequent closed itemsets can be slightly smaller than number of frequent generators, the size of the association rules formed by closed itemsets, is on an average, greater than the size of association rules formed by generators. Hence, generators are preferable to closed itemsets while forming class association rules
The paper mainly focuses on imbalanced datasets, but the algorithm is designed to give satisfactory results for roughly balanced datasets as well. This paper adopts the methodology suggested by the authors[16], for the development of Associative Classifier based on all Frequent Itemsets. This paper proposes the use of frequent generators instead of all frequent itemsets to build Associative Classifiers.
i Proposed Framework
Learning Phase:
1. The majority (or negative) and minority (or positive) class labels of the dataset are identified depending on their frequency of occurrence.
2. The training dataset is then divided into two partitions: Pmaj (the training data instances belonging to majority class) and Pmin (the training data instances belonging to minority class). For each partition, each training instance is represented as a transaction after removing its class label.
Let Ai be an itemset belonging to Partition with class label Cj. The Class Support of Ai is calculated using the following equation:
Ai → Cj)= σA UCσC Eq.(1)
The local support of a itemset corresponds to the fraction of instances containing the itemset in that partition. If the support of an itemset is greater than some user-defined threshold, it is considered to be frequent.
4. Once frequent generators are identified, generation of classification rules is straight forward. The right hand side of the rule is the class label of the partition currently being used, and its left hand side is the locally frequent generator.
5. Load the partition Pmin into main memory. For each frequent generator in Pmaj , find the conditional support count in Pmin.Using that, the global frequency of the itemset in the training data set could be found. This value could be used to obtain Confidence(Conf), Complement Class Support(CCS), and Strength Score(SS) using the formulas given below.
CCS Ai → Cj)= Eq.(2)
Conf Ai → Cj)= Eq.(3)
SS Ai → Cj) [17]= where t=0.01 Eq.(4)
Strength Score represents the accuracy with which Ai indicates the belongingness of Ai with Cj. 6. Repeat step 5 after loading partition Pmaj to find the global counts of frequent items in Pmin.
Classification Phase:
7. For every test instance, find the set of classification rules applicable from the majority class(negative class) and set of CARs applicable from the minority class(positive class).
Calculate the Scoring Function[16] that indicates the belongingness of the test example in minority class as given below:
S[17] = Eq.(5)
Where k= Eq. (6)
If k>1, value of k is substituted, otherwise k=1is substituted. S ε [0, 1].
If the ‘S’value of the test instance tends to one, minority class is suggested, otherwise majority class is suggested.
If the ‘S’ value of the test instance is greater than some cutoff value, then minority class label is assigned to the instance, otherwise majority class label is assigned.
ii Condensed Representation of Frequent Itemsets
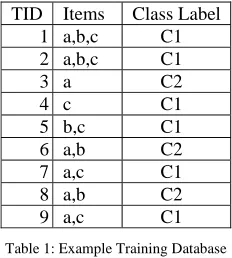
To better illustrate the above algorithm, consider the training database in Table 1. Let, minimum support threshold be 30%
TID Items Class Label 1 a,b,c C1 2 a,b,c C1 3 a C2 4 c C1 5 b,c C1 6 a,b C2 7 a,c C1 8 a,b C2 9 a,c C1 Table 1: Example Training Database
Items a,b,c a,b,c c b,c a,c a,c
Table 2: Partition P1 belonging to majority class (C1)
Items a a,b a,b
Table 3: Partition P2 belonging to minority class (C2)
The frequent itemsets generated for P1 and their corresponding support counts from Table 2 are: {<a,3>,<b,3>,<c,6>,<ab,2>,<bc,3>,<ac,2>,<abc,2>}. The set of frequent generators are: {<a,3>,<b,3>,<c,6>, <abc,2>,<ac,2>}. For Partition P2, the frequent itemsets generated from Table 2 are: {<a,3>,<b,2>,<ab,2>}. The set of frequent generators are: {<a,3>,<b,2>}. The classification rules generated are:
a→C1, with SS=0.495, b→C1, with SS=0.447, c→C1, with SS=100, ab→C1, with SS=0.246, ac→C1, with SS=33, a→C2, with SS=0.639, b→C2, with SS=0.784
the rule c→C1 is a strong rule because the itemset c is associated with class C1 but not class C2, which is evident from the corresponding SS value.
Classification Phase:
For test instance ab, the rules invoked are: a→C1, b→C1, ab→C1 from majority (negative) class, and a→C2, b→C2 from minority (positive) class. The total strength score of positive rules (SSpos) is (0.6396+0.7843). The total strength score of negative rules (SSneg) is (0.495+0.447+0.246). Percentage of majority class is 66.67% and that of minority class is 33.33%. From Eq. (6), value of k is 3.4815. Substituting these values in Eq. (5), we get S value to be 0.65. The threshold value for S is 0.5. If S value of a test instance is greater than 0.5, it belongs to minority class. Otherwise, it belongs to majority class. S value of test instance ab is 0.65 indicating that ab belongs to minority class C2. For test instance ac, S value is 0.021 indicating that it belongs to majority class C1. For test instance c, S value is 0 indicating that c always belongs to majority class C1.
IV. PERFORMANCE METRICS
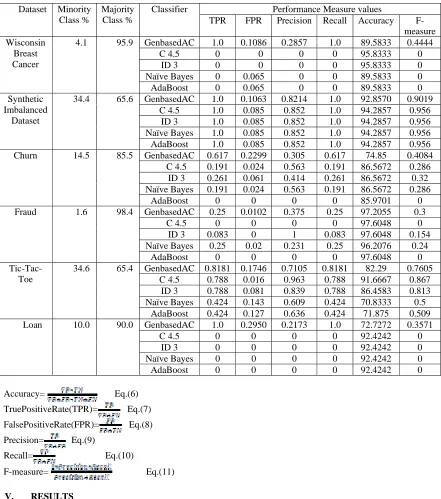
Table 4: Results Comparison of different classifiers
Dataset Minority Class %
Majority Class %
Classifier Performance Measure values
TPR FPR Precision Recall Accuracy F-measure Wisconsin
Breast Cancer
4.1 95.9 GenbasedAC 1.0 0.1086 0.2857 1.0 89.5833 0.4444
C 4.5 0 0 0 0 95.8333 0
ID 3 0 0 0 0 95.8333 0
Naïve Bayes 0 0.065 0 0 89.5833 0
AdaBoost 0 0.065 0 0 89.5833 0 Synthetic
Imbalanced Dataset
34.4 65.6 GenbasedAC 1.0 0.1063 0.8214 1.0 92.8570 0.9019 C 4.5 1.0 0.085 0.852 1.0 94.2857 0.956
ID 3 1.0 0.085 0.852 1.0 94.2857 0.956 Naïve Bayes 1.0 0.085 0.852 1.0 94.2857 0.956
AdaBoost 1.0 0.085 0.852 1.0 94.2857 0.956
Churn 14.5 85.5 GenbasedAC 0.617 0.2299 0.305 0.617 74.85 0.4084 C 4.5 0.191 0.024 0.563 0.191 86.5672 0.286
ID 3 0.261 0.061 0.414 0.261 86.5672 0.32 Naïve Bayes 0.191 0.024 0.563 0.191 86.5672 0.286
AdaBoost 0 0 0 0 85.9701 0
Fraud 1.6 98.4 GenbasedAC 0.25 0.0102 0.375 0.25 97.2055 0.3
C 4.5 0 0 0 0 97.6048 0
ID 3 0.083 0 1 0.083 97.6048 0.154
Naïve Bayes 0.25 0.02 0.231 0.25 96.2076 0.24
AdaBoost 0 0 0 0 97.6048 0
Tic-Tac-Toe
34.6 65.4 GenbasedAC 0.8181 0.1746 0.7105 0.8181 82.29 0.7605 C 4.5 0.788 0.016 0.963 0.788 91.6667 0.867
ID 3 0.788 0.081 0.839 0.788 86.4583 0.813
Naïve Bayes 0.424 0.143 0.609 0.424 70.8333 0.5
AdaBoost 0.424 0.127 0.636 0.424 71.875 0.509
Loan 10.0 90.0 GenbasedAC 1.0 0.2950 0.2173 1.0 72.7272 0.3571
C 4.5 0 0 0 0 92.4242 0
ID 3 0 0 0 0 92.4242 0
Naïve Bayes 0 0 0 0 92.4242 0
AdaBoost 0 0 0 0 92.4242 0
Accuracy= Eq.(6) TruePositiveRate(TPR)= Eq.(7) FalsePositiveRate(FPR)= Eq.(8) Precision= Eq.(9)
Recall= Eq.(10)
F-measure= Eq.(11)
V. RESULTS
In our experiments, we compare GeneratorbasedAC with Naïve Bayes[21], AdaBoost[22], ID3[23], and C4.5[9]. We use Weka’s implementations[24] for Naïve Bayes, AdaBoost, ID3, and C4.5. GeneratorbasedAC was implemented using Java. The performance of different classifiers is evaluated on three classification datasets using performance metrics like Precision, Recall, True Positive Rate, False Positive Rate, Accuracy and F-measure. For the sake of comparison, a minimum support threshold of 0.01 is used for the classifiers. All the experiments were carried out using 10-fold cross validation. In C4.5 we use its default confidence level of 25% in pruning.
those of closed itemsets, we have preferred to work on generators. Because we are dealing with imbalanced datasets also, it is important to retain all the itemsets that satisfy the required minimum support threshold. The results of classifying synthetic imbalanced dataset is presented in Table 5. Only Generator based Associative Classifier was able to predict all the test instances of the minority class correctly where other classifiers have failed. Table 6 shows results of classifying Wisconsin Breast Cancer Dataset. The dataset under consideration is roughly balanced in nature.
VI. CONCLUSIONS
This paper proposes a new framework for developing an Associative Classifier using frequent generators. The resulting classifier is found to be more efficient as number of class association rules are less and the length of the rules is also less. This classifier is specifically designed to handle imbalanced datasets unlike most classifiers which assume approximately balanced class distributions for datasets. The classifier’s performance is compared with other classifiers with respect to six performance metrics. Results show that the proposed classifier performs better than other classifiers.
ACKNOWLEDGEMENT
The author is grateful to Dr. Limsoon Wong from whose webpage the implementation for GcGrowth algorithm was taken. The author is also grateful to the Machine Learning Repository provided by University of California at Irving from where the datasets were taken. The author would like to express gratitude to Dr. David. L. Olson for having contributed Loan Dataset and Fraud Dataset from his work.
VII. REFERENCES
[1] R. Agrawal and R. Srikant (1994). Fast Algorithm for mining association rules. In Proc. Of VLDB’94, Santiago, Chile, Sept. 1994. [2] Liu B, Hsu W, Ma Y (1998). “Integrating Classification andAssociation Rule Mining”. In: Proceeding of the Fourth International
Conference on Knowledge Discovery and Data Mining, New York,pp.80-86.
[3] Ali K, Manganaris K, Srikant R (1997) Partial classification using association rules. In: Proceeding of the third international conference on knowledge discovery and data mining, Newport Beach,California, pp 115–118
[4] Janssens D, Wets G, Brijs T and Vanhoof K (2003). “Integrating classification and association rules by proposing adaptations to CBA”. In: Proc. of the 10th International Conference on Recent Advances in Retailing and Services Science, Portland, Oregon. [5] Li W, Han J, Pei J (2001). “CMAR: Accurate and Efficient Classification Based on Multiple Class-Association Rules”. In: Proc. of the
1st IEEE International Conference on Data Mining, San Jose, California, pp.369-376.
[6] B. Lent, A. Swami, and J. Widom. Clustering association rules. In ICDE’97, England, April 1997.
[7] G. Dong, X. Zhang, L. Wong, and J. Li. Caep: Classification by aggregating emerging patterns. In DS’99 (LNCS 1721), Japan, Dec. 1999.
[8] K. Wang, S. Zhou, and Y. He. Growing decision tree on support-less association rules. In KDD’00, Boston, MA, Aug. 2000. [9] Quinlan JR (1993) C4.5: programs for machine learning. Morgan Kaufmann, San Mateo
[10] N. Pasquier, Y. Bastide, R. Taouil, and L. Lakhal. Discovering frequent closed itemsets for association rules. In Proc. of the 7th ICDT Conference, pages 398–416, 1999.
[11] Y. Bastide, N. Pasquier, R. Taouil, G. Stumme, andL. Lakhal. Mining minimal non-redundant association rules using frequent closed itemsets. In Proc. Of Computational Logic Conference, pages 972–986, 2000.
[12] Claudio Lucchese, Salvatore Orlando, Raffaele Perego(2006). Mining frequent closed itemsets out of core, In Proc. Of 2006 SIAM Conference on Data Mining, pp:419-429.
[13] James Cheng, Yiping Ke, and Wilfred Ng.δ-Tolerance Closed Frequent Itemsets. In Proceedings of the 6th IEEE International Conference on Data Mining (ICDM), pages 139-148, 2006.
[14] Haiquan Li, Jinyan Li, Limsoon Wong, Mengling Feng, Yap-Peng Tan. Relative Risk and Odds Ratio: A Data Mining Perspective. Proceedings of 24th ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, pages 368--377, Baltimore, Maryland, June 2005.
[15] Jinhong Li, Bingru Yang, Wei Song, Wei Hou. (2008). Clustering frequent itemsets based on generators. In Proc. of Second International Conference on Intelligent Information Technology Application. Vol. 2, pp:1083-1086.
[16] Sireesha Rodda, M. Shashi, A new approach to Associative Classifier Development for imbalanced datasets, International Journal of Computer Applications in Engineering, Technology, and Sciences, Vol.2, Issue. 1
[17] Arunasalem, Bavani. & Chawla, Sanjay. & University of Sydney. 2006 Parameter-free classification for imbalanced data scoring using complement class support, School of Information Technologies, The University of Sydney, [Sydney, N.S.W.]
[18] Nitesh V. Chawla, C4.5 and Imbalanced datasets: investigating the effect of sampling method, probabilistic estimate and tree structure, In Proc. of ICML’03 workshop on class imbalances, 2003
[19] Cheng G. Weng, Josiah Poon. A New Evaluation Measure for Imbalanced Datasets, Conferences in Research and Practice in Information Technology, Vol. 87, pp:27-32
[20] Qiong Gu, Zhihua Cai, Li Ziu, Classification of Imbalanced Data Sets by Using the Hybrid Re-sampling Algorithm Based on Isomap, In LNCS, Advances in Computation and Intelligence, vol. 5821, pp:287-296, 2009
[21] T. Hastie, R. Tibshirani, and J. Friedman. Elements of Statistical Learning. Springer, 2001.
[22] Y. Freund and R. E. Schapire. A decision-theoretic generalization of on-line learning and an application to boosting. In European Conference on Computational
[23] Learning Theory, pages 23–37, 1995.
[25] I. Witten and E. Frank. Data mining: practical machine learning tools and techniques with Java implementations.
[26] ACM SIGMOD Record, 31(1):76–77, 2002. [25] University of California at Irving, Machine Learning Repository,
http://www.ics.uci.edu/~mlearn/MLRepository.html
[27] [26] R. de la Briandais. File searching using variable-length keys. In Western Joint Computer Conference, pages 295– 298, March 1959.
[28] E. Fredkin. Trie memory. Communications of the ACM, 3(9):490–499, 1960. [29] Ferenc Bodon. A fast apriori implementation. FIMI, 2003.