Abstract--- The major issue related to the protection of private information in online analytical processing system (OLAP), is the privacy concern in the adversarial inference or private information from OLAP query answers. The most previous works on privacy preserving OLAP focuses on a single aggregate function and multiple aggregate functions which deal with both exact disclosure and partial disclosure of the data. It is performed using the combination of the simple aggregate functions which guarantees the level of privacy disclosure as required by the user. The malicious user can exploit the correlation among data to infer sensitive information from a series of seemingly innocuous data accesses based on data dependency, database schema and semantic knowledge, the system constructs a semantic inference modal that represents the possible inference channels and the violation detection system keeps track of the user history when the infer sensitive information exceeds the pre specified threshold the current query will be rejected. The violation detection system combines all users query history and rejects the query. The closeness of the user is calculated based on the amount of the information that flow from one user to another.
Keywords--- OLAP (Online Analytical Processing), Privacy, Information Theory
I. INTRODUCTION
ATA mining (knowledge discovery from data) is defined as non-trivial extraction of implicit, previously unknown, and potentially useful information from large data sets or databases. It is also called as Knowledge discovery (mining) in databases (KDD), knowledge extraction, data/pattern analysis, data archeology, data dredging, information harvesting and business intelligence. It is the entire process of applying computer-based methodology, including new techniques for knowledge discovery, from data. There are several major data mining techniques have been developed including association, classification, clustering, prediction and sequential patterns.
II. OLAPOVERVIEW
Online analytical processing (OLAP) is an approach to swiftly answer multi-dimensional analytical (MDA) queries. OLAP is part of the broader category of business intelligence, which also encompasses relational reporting and data mining. OLAP enables analysts, managers, and executives to gain
M. Ragul Vignesh, PG Scholar, Department of Information Technology, SNS College of Technology, Coimbatore, India
C. Senthil Kumar, Assistant Professor, Department of Information Technology, SNS college of Technology, Coimbatore, India. E-mail: [email protected]
insight into data through fast, consistent, interactive access to a wide variety of possible views of information.
A. Privacy Requirement
Due to privacy concerns, the owner of a data cube may not want a user to have access to all the information stored in it. Privacy requirements on a data cube may be defined over the cells in the data cube, and/or the data tuples in the relational back end of it. It chooses a cell as the granularity for specification of privacy requirements due to our focus on the processing of OLAP queries. Privacy requirements on tuples can also be transformed to requirements on data cube cells. In our model, a user does not have the right to access all cells in the data cube. It refers to all cells that a user cannot access as sensitive cells for the user. A user should not be capable of compromising the value of a sensitive cell from the query answers it receives. There are two measures for the compromise of a sensitive cell: exact and partial disclosure. While exact disclosure occurs if the exact value of cell is known to a user, partial disclosure occurs whenever a user has a significant change between its prior and posterior belief on the value of a cell.
B. External Knowledge
Besides receiving aggregate query answers, a user may also learn certain information about a sensitive cell from sources outside the OLAP system. It refers to such information as the external knowledge of the user. There are various types of external knowledge which may lead to the disclosure of sensitive cells. To ensure the security of sensitive cells, it adopts a conservative assumption that if a cell is not sensitive to a user, then the user knows the value of the cell as preknowledge. It refers to such a nonsensitive cells as the preknown cells of user. It counts all preknown cells as 0 in the computation of query answers. Inference problem occurs if a user can infer certain information about a sensitive cell from the received query answers as well as the preknown cells.
III. LITERATURE REVIEW
The core of any OLAP system is an OLAP cube also called a 'multidimensional cube' or a hypercube. It consists of numeric facts called measures which are categorized by dimensions. The cube metadata is typically created from a star schema or snowflake schema of tables in a relational database. Measures are derived from the records in the fact table and dimensions are derived from the dimension tables.
Each measure can be thought of as having a set of labels, or meta-data associated with it. A dimension is what describes these labels; it provides information about the measure. Any number of dimensions can be added to the structure such as Store, Cashier, or Customer by adding a foreign key column to the fact table. This allows an analyst to view the measures
OLAP Online Privacy Control
M. Ragul Vignesh and C. Senthil Kumar
along any combination of the dimensions. It introduces the system models for privacy protection in OLAP. In particular, it presents the system settings, models of privacy intrusion attacks and defensive countermeasures, performance measures for privacy disclosure and query availability, as well as the formal problem definition of inference control in OLAP. Decision support systems such as On-line Analytical Processing (OLAP) are becoming increasingly important in industry. These systems are designed to answer queries involving large amounts of data and their statistical averages in near real time. It is well known that access control alone is insufficient in eliminating all forms of disclosures, as information not released directly may be inferred indirectly from answers to legitimate queries. This is known as the inference problem.
IV. EXISTING SYSTEM
The existing systems use the inference detection scheme with the help of the aggregate functions present in the information theoretic approach. The aggregate functions such as Min-Like and Sum-Like functions are considered. Past works focus on the inference problems. The main objective is to reject all unsafe queries submitted by user and also to maximize the query availability level when the unsafe query is rejected.
C. Workflow
The main objective is to reject all unsafe queries submitted by the user ck. So the sensitivity for all sensitive cells has to be calculated but possible cells are large and grow exponentially. So we maintain an upper bound estimate ɭmax(Qk). This can be calculated by
ɭmax(Qk)=max(ɭp(x;QkU{q})-ɭp(x;Qk))
This calculated the threshold value for the available preknown cells or the sensitive cells.
D. Aggregate Functions
The computation of ɭmax(Qk) critically depends on the aggregate function of queries.
MIN-Like Functions
MIN-like functions include MIN and MAX. A common property of MIN-like functions is, for query size |q|>>1, there is H(q)<<H(x). The obtained with the help of MIN-Like function is
Hmax(q|Qk)< max H(q)/H(x) ~ 1/293
H(x) of MIN queries without violating the privacy requirements of data owners.
SUM-Like Functions
SUM-like functions include COUNT, SUM, AVG, MEDIAN, MODE, and STANDARD DEVIATION. The basic idea of processing a SUM-like query is to count the number of cells covered by the query that can independently change the query answer without influencing (or violating) the historic queries answers and the prior knowledge of the adversaries.
Query is rejected if the following breach occurs [Hmax(q|Qk) / 1- Hmax(Qk)] < ½log(Hq/ Hq-1)
E. Inference Algorithm
In the algorithm, we use lp to denote the current upper-bound estimate on Hmax(Qx). When Qk=ɸ, the initial values of the parameters are µk = ∞, σk = 0, and ɭ= 0.
With the algorithm, when a new query q is received, the data warehouse server computes an upper-bound estimate on Kmax(q|Qk) as l0, and answers the query if and only if l p + l 0 is less than the owner-specified threshold l. The algorithms satisfy the simulatable auditing model. Note that the algorithm makes the answer/reject decision for a received query q based on q, the query history Qk, the preknown set Gk, the prior distribution of the cells, and nothing else. It does not use the values of sensitive cells or the answer to q as input. As such, all inputs to Algorithm is public information available to the users. Thus, the answer/ reject decisions made by the data warehouse server are fully simulatable by the users. Due to the definition of simulatable auditing, the auditor (i.e., the data warehouse server) is simulatable with the algorithms. Note that due to the simulatable auditing property, the data warehouse server will not disclose any additional private information through query rejections. Thus, the rejected queries need not be taken into account by the inference control algorithm. This is reflected in the design of the algorithm, as the rejected queries are not recorded by the data warehouse server.
V. PROBLEM DESCRIPTION
Inference control algorithms are used to provide the security to the private data in the data warehouse. It proposes an information-theoretic inference control approach that protects private information against both exact and partial disclosure. It mainly concentrates on general query auditing problems, real-world privacy measure, and integration of data collection, inference control, and information sharing. This
approach shows that the level of privacy disclosure cannot exceed thresholds specified by data owners and concentrates on providing maximum available or preknown data without disclosing the sensitive fields.
The main problems faced are listed below
α. Defense against colluding users is not possible in previous work
β. Answering to skeletal query is only possible ∞. User log are not maintained
A. Solving Problem
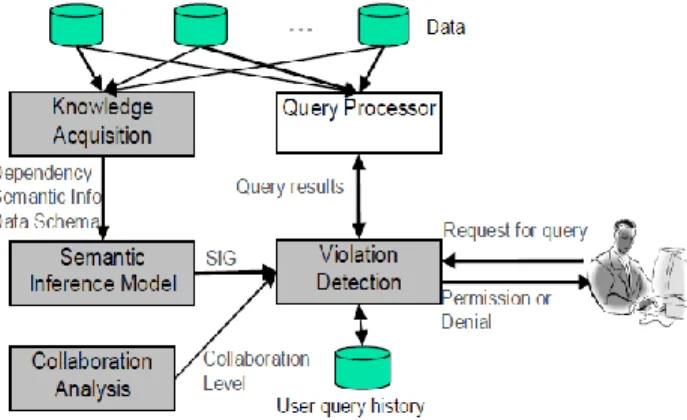
α. To solve the problem of the colluding user a novel approach called semantic inference modal is followed. Based on data dependency, database schema and semantic knowledge, the system constructs a semantic inference model (SIM) that represents the possible inference channels from any attribute to the pre-assigned sensitive attributes. The SIM is then instantiated to a semantic inference graph (SIG) for query-time inference violation detection. For a single user case, when a user poses a query, the detection system will examine his/her past query log and calculate the probability of inferring sensitive information. For multi-user cases, the users may share their query answers to increase the inference probability. Therefore, there is a need to develop a model to evaluate collaborative inference based on the query sequences of collaborators and their task-sensitive collaboration levels. Experimental studies reveal that information authoritativeness, communication fidelity and honesty in collaboration are three key factors that affect the level of achievable collaboration
Figure 5.2: Framework of SIM
β. To solve the batch query processing problem approach called as Non-Skeleton query processing is used. Finally for the above approaches consider only the skeleton queries by this OLAP system, but the user may also issue non-skeleton queries such as range queries each of which covers more than one value (but fewer than all values) of an attribute.
Since the cells covered by a non-skeleton query can always be separated into multiple non-overlapping skeleton queries, an easy method to process a non-skeleton query with distributive aggregate function (e.g., MIN, MAX, and SUM) is to transform the non-skeleton query into a sequence of skeleton ones, and to answer the non-skeleton query iff all
(transformed) skeleton ones can be answered.
Since the answer to the non-skeleton query can always be derived from the set of answers to the skeleton queries, the safety of private information is guaranteed. These processing of non-skeleton queries will be done by the same way as the skeleton queries done but may provide low query availability.
∞. The user logs are maintained with the help of the various access control mechanisms available.
VI. RESULT
α. In the multiple-user inference environment, the users can share their query answers to collaboratively infer sensitive information. Collaborative inference is related to the collaboration level as well as the inference channels of the user-posed queries. For inference violation detection, we developed a collaborative inference model that combines the collaborators’ query log sequences into inference channels to derive the collaborative inference of sensitive information. User profiles and questionnaire data provide a good starting point for learning collaboration levels among collaborative users.
β. It shows that the privacy can be provided to the sensitive data present in the data warehouse without disclosure of them. Most of the queries presented to the system are answered and query rejection rate is comparatively less compared to the previous approaches. Here the entropy values are calculated for the each and every sensitive data present inside the database. The particular threshold values are fixed for each and every data. If the entropy value reaches the threshold the query is rejected. The main purpose is to provide the data without rejection and also without disclosing the private sensitive data.
A. Sample Training Phase (β)
The following figure shows the training phase for the OLAP system in JAVA. These are used for loading the training set which are required for the data analysis.
Figure 5.1.2: Trainer for OLAP Modal
B. Analysis Phase (β)
The loaded dataset are analyzed and then both the skeletal query and non-skeletal queries are being processed.
Figure 5.2: Analysis Phase Result
C. Semantic Modal Generation (α)
The semantic inference graph is generated with the help of the semantic inference modal. Then the user collaboration or closeness is calculated and their combined query history is noted.
D. Analysis Phase (α)
The loaded dataset are analyzed and values are noted for the colluding users.
E. Performance (α and β)
The performances of the problems α and β are noted and compared for the performance analysis.
Figure 5.3: Performance of α
VII. CONCLUSION AND FUTURE WORK
By the end of the implementation the system should show the expected performance with the appropriate query acceptance and rejection inside the query analyzer with the various algorithms running through them. Here the results and placed for the processing of both skeletal and non-skeletal query processing in the system.
The collaborative inference problems are avoided with the help of the semantic inference modal. It is proven to be more efficient by reducing the query rejection rated and also not by disclosing any private data to the users. This work mainly concentrated on the inference problem.
The future work may focus on considering the multiple techniques available for data privacy. Combining the techniques such perturbation, inference control and good access control mechanism may provide better data privacy for multiple aggregate functions in future.
REFERENCES
[1] Agrawal.R, Srikant.R, and Thomas.D, 2005, “Privacy Preserving OLAP,” Proc. ACM SIGMOD, pp. 251-262.
[2] Chen.B, LeFevre.K, and Ramakrishnan.R, 2007, “Privacy Skyline: Privacy with Multidimensional Adversarial Knowledge,” Proc. 33rd Int’l Conf. Very Large Data Bases, pp. 770-781
[3] Dwork.C, McSherr.F, Nissim.K, and Smith.A, 2006, “Calibrating Noise to Sensitivity in Private Data Analysis,” Proc. Third Theory of Cryptography Conf., pp. 265-284.
[4] Raymond W. Yip, and Karl N. Levitt, 1998. “Data Level Inference Detection in Database Systems.” PCSFW:Proceedings of the 11th Computer Security Foundations Workshop.
[5] Sung.Y, Liu..Y, Xiong.H, and Ng.A, 2006, “Privacy Preservation for Data Cubes,” Knowledge and Information Systems, vol. 9, no. 1, pp. 38-61.
[6] Wang.L, Wijesekera.D, and Jajodia.S, 2004, “Cardinality-Based Inference Control in Data Cubes,” J. Computer Security, vol. 12, no. 5, pp. 655-692.
[7] Wenke Lee, Salvatore J. Stolfo, Philip K. Chan, Eleazar Eskin, Wei Fan, Matthew Miller, Shlomo Hershkop and Junxin Zhang. . June 2001,“Real Time Data Mining-based Intrusion Detection.” Proceedings of DISCEX II.
[8] Yu Chen and Wesley W. Chu, 2006. “Database Security Protection via Inference Detection.” IEEE International Conference on Intelligence and Security Informatics.
[9] Zhang.N and Zhao.W, Apr. 2007, “Privacy-Preserving Data Mining Systems,” Computer, vol. 40, no. 4, pp. 52-58.
[10] Zhang.N and Zhao.W,and J. Chen, 2004, “Cardinality-Based Inference Control in OLAP Systems: An Information Theoretic Approach,” Proc. Seventh ACM Int’l Workshop Data Warehousing and OLAP, pp. 59-64. [11] Zhang.N and Zhao.W, 2009, “An Information-Theoretic Approach for Privacy Protection in OLAP Systems,” Technical Report TRGWU- CS-09-003, Dept. of Computer Science, George Washington Univ.