revolutionising high
performance computing
With supermicro solutions
nvidia
®
tesla
®
gpus are revolutionizing
computing
The high performance computing (HPC) industry’s need for computation is increasing, as large and complex computational problems become commonplace across many industry segments. Traditional CPU technology, however, is no longer capable of scaling in performance sufficiently to address this demand.
The parallel processing capability of the GPU allows it to divide complex computing tasks into thousands of smaller tasks that can be run concurrently. This ability is enabling computational scientists and researchers to address some of the world’s most challenging computational problems up to several orders of magnitude faster.
Conventional CPU computing architecture can no longer support the growing HPC needs.
Source: Hennesse]y &Patteson, CAAQA, 4th Edition. 10000
1000
100
10
Perf
ormanc
e v
s V
AX
100x performance advantage
by 2021
25% year
52% year
20% year
CPU GPU
hybrid
computing
latest gpu superserver
®, superBlade
®and
nvidia
®maximus™ certified superWorkstation
solutions from supermicro
®accelerating research, scietific, engineering, computational finance
and design applications
1u superserver®
1027Gr-TQF
up to 4x gpus
2027Gr-TrF
up to 6x gpus
SBI-7127rG
up to 20x gpus
7047Gr-TrF
4x nvidia tesla gpus 1x nvidia Quadro gpu
2u superserver® 7u superBlade® superWorkstation
Super Micro Computer, Inc. (NASDAQ: SMCI), a global leader in high-performance, high-efficiency server technology and green computing, will showcase its latest graphics processing unit (GPU) enabled X9 server and workstation solutions at the NVIDIA GPU Technology Conference (GTC) May 14-17 in San Jose, CA. Supermicro®s GPU solutions
support Intel® Xeon® E5-2600 processors and feature
greater memory capacity (up to 256GB for servers and 512GB in workstations), higher performance I/O and connectivity with PCI-E 3.0, 10GbE and 4x QDr (40Gb) InfiniBand support (GPU SuperBlade) as well as innovative energy efficient power saving technologies. Supermicro X9 solutions also feature the highest density GPU computing available today. The non-blocking architecture supports 4 GPUs per 1U in a standard, short depth 32”, rack chassis. The SuperBlade can fit 30 GPUs in 7U- another industry
These select GPU enabled servers and workstations are a sampling of Supermicro’s vast array of GPU solutions. Visit us at the San Jose McEnery Convention Center, May 14-17 in GTC Booth #75 to see Supermicro’s latest GPU products. For a complete look at Supermicro’s extensive line of high
performance, high efficiency GPU solutions, visit
www.supermicro.com/GPU or go to
www.supermicro.com/SuperWorkstations to keep up with Supermicro’s evolving line of NVIDIA Maximus powered SuperWorkstations.
first from Supermicro®. Combined with the latest
GPUs based on NVIDIA Kepler architecture, the X9 platform offers industry professionals one of the most powerful, accelerated and ‘green’ computing solutions available on the market.
“Supermicro® is transforming the high performance
computing landscape with our advanced, high-density GPU server and workstation platforms,” said Charles Liang, President and CEO of Supermicro®.
“At GTC, we are showcasing our new generation X9 SuperServer®, SuperBladeTM and latest NVIDIA
Maximus certified SuperWorkstation systems which deliver groundbreaking performance, reliability, scalability and efficiency. Our expanding lines of GPU-based computing solutions empower scientists, engineers, designers and many other professionals with the most cost-effective access to supercomputing performance.”
NVIDIA® TESLATM / HybrID coMpuTINg SoLuTIoNS 2010
SUPE
r
W
ork
St
Ation
S
superWorkstations
server grade performance for multimedia,
engineering, and scientific applications
performance. efficiency.
expandaBility. reliaBility
• Optimized Solutions:
Video Editing, Digital Content Creation, MCAD, CAE, Financial, SW Development, Scientific, Oil and Gas
• Whisper-Quiet 21dB Acoustics models
• Up to Redundant Platinum Level (95%+) Digital
Power Supplies
• Best Value for your IT Investment
• Up to 512 GB DDR3 memory and 8 Hot-Swap HDDs • Up to 5 GPUs supported with PCI-E 3.0
• Server-Grade Design for 24x7 Operation
The 7047Gr-TrF is Supermicro’s latest high-end, enterprise-class X9 SuperWorkstation, with NVIDIA Maximus certification. This system accelerates
design and visualization tasks with an NVIDIA Quadro
GPU, while providing dedicated processing power for simultaneous compute intensive tasks such as simulation and rendering with up to four NVIDIA Tesla C2075 GPUs. The upcoming 7047Gr-TPrF SuperWorkstation supports passively cooled GPUs making it ideal for high performance trading (HPT) applications. X9 systems feature dual Intel® Xeon® E5-2600 family processors, maximized memory and
non-blocking native PCI-E 3.0 configurations along
with redundant Platinum level high-efficiency (94%+)
power supplies.
www.supermicro.com/SuperWorkstations
7047gr-trf
• NVIDIA® Maximus™ Certified supporting NVIDIA®
Quadro® and up to 4 NVIDIA® Tesla® for real-time
3D design, visualization, simulation and accelerated
rendering
• GPU Server for Mission-critical applications, enterprise
server, large database, e-business, on-line transaction processing, oil & gas, medical applications
• Dual Intel® Xeon® processor E5-2600 family; Socket r
(LGA 2011)
• 8 Hot-swap 3.5“ SATA HDD Bays, 3x 5.25“ peripheral
drive bays, 1x 3.5“ fixed drive bay
• 16 DIMMs support up to 512GB DDR3 1600MHz reg.
ECC memory
• 4 (x16) PCI-E 3.0 (support 4 double width GPU cards), 2 (x8) PCI-E 3.0 (1 in x16), and 1 (x4) PCI-E 2.0 (in x8)
slot
• I/O ports: 2 GbE, 1 Video, 1 COM/Serial, 9 USB 2.0 • System management: Built-in Server management
tool (IPMI 2.0, KVM/media over LAN) with dedicated LAN port
• 4 Hot-swap PWM cooling fans and 2 Hot-swap rear
fans
H
ybrid
Com
PU
tin
G
high performance gpu servers
the foundation of a flexiBle and efficient hpc &
data center deployment
Brains, Brains and more Brains!!!
X9 SuperServers which provide a wide rangeof configurations targeting high performance computing (HPC) applications. Systems include the 1027Gr-TQF offering up to 4 double-width GPUs in 1U for maximum compute density in a compact 32” short depth, standard rack mount format. The 2U 2027Gr-TrF supports up to 6 GPUs and is ideal for scalable, high performance computing clusters
in scientific research fields with a 2027Gr-TrFT model available supporting dual-port 10GBase-T for increased bandwidth and reduced latency. The GPU SuperBlade SBI-7127rG packs the industry’s highest compute density of 30 GPUs in 7U delivering ultimate processing performance for applications such as oil and gas exploration.
Professor Wu Feng of Virginia Tech‘s Synergy Laboratory is the main Brain behind VT‘s latest and greatest Supercomputer, HokieSpeed. HokieSpeed is a Supermicro supercluster of SuperServer®
2026GT-TrFs with thousands of CPU/GPU cores or „brains“.
In Nov. 2011, HokieSpeed ranked 11th for energy efficiency on the Green500 List and 96th on the world‘s fastest supercomputing Top500 List. Dr. Feng‘s Supermicro powered HokieSpeed boasts single-precision peak of 455 teraflops, or 455 trillion operations per second, and a double-precision peak of 240 teraflops, or 240 trillion operations per second.
2027gr-trft / 2027gr-trf (-fm475/-fm409)
• GPU Server, Mission-critical app., enterprise server,
large database, e-business, on-line transaction processing, oil & gas, medical app.
• Dual Intel® Xeon® processor E5-2600 family; Socket r
(LGA 2011)
• 10 Hot-swap 2.5“ SATA HDD Bays (4 SATA2, 6 SATA3) • 8 DIMMs support up to 256GB DDR3 1600MHz reg. ECC
memory
• 4 (x16) PCI-E 3.0 (support 4 double width GPU cards), 1 (x8) PCI-E 3.0 (in x16), and 1 (x4) PCI-E 2.0 (in x16) slots • I/O ports: 2 GbE/10GBase-T (TRFT), 1 Video, 1 COM/
Serial, 2 USB 2.0
• 5 heavy duty fans w/ optimal fan speed control • 1800W Redundant Platinum Level Power Supplies • „-FM475/409“: 4x NVIDIA M2075/M2090 GPU cards
integrated
* use your phone, smartphone or tablet pc with Qr reader software to read the Qr code.
Watch video*:
superservers in action:
NVIDIA® TESLATM / HybrID coMpuTINg SoLuTIoNS 2010
Hi
GH
P
Erf
orm
An
CE
GPU
SE
r
VE
r
S
superservers
1017gr-tf (-fm275/-fm209)
• GPU Server, Mission-critical app., enterprise server,
oil & gas, financial, 3D rendering, chemistry, HPC
• Single Intel® Xeon® processor E5-2600 family; Socket r
(LGA 2011)
• 6 Hot-swap 2.5“ SATA HDD Bays
• 8 DIMMs support up to 256GB DDR3 1600MHz reg. ECC
memory
• 2 (x16) PCI-E 3.0 (for 2 GPU cards) and 1 (x8) PCI-E 3.0 slot • I/O ports: 2 GbE, 1 Video, 2 USB 2.0
• 8 counter rotating fans w/ optimal fan speed control • 1400W Platinum Level Power Supply w/ Digital Switching • „-FM175/109“: 1x NVIDIA M2075/M2090 GPU card
integrated
• „-FM275/209“: 2x NVIDIA M2075/M2090 GPU cards
integrated
5017gr-tf (-fm275/-fm209)
• GPU Server, Mission-critical app., enterprise server,
oil & gas, financial, 3D rendering, chemistry, HPC
• Single Intel® Xeon® processor E5-2600 family; Socket r
(LGA 2011)
• 3 Hot-swap 3.5“ SATA HDD Bays
• 8 DIMMs support up to 256GB DDR3 1600MHz reg. ECC
memory
• 2 (x16) PCI-E 3.0 (for 2 GPU cards) and 1 (x8) PCI-E 3.0
(for IB card)
• I/O ports: 2 GbE, 1 Video, 2 USB 2.0
• 8 counter rotating fans w/ optimal fan speed control • 1400W Platinum Level Power Supply w/ Digital Switching • „-FM175/109“: 1x NVIDIA M2075/M2090 GPU card
integrated
• „-FM275/209“: 2x NVIDIA M2075/M2090 GPU cards
integrated
1027gr-trft/1027gr-trf (-fm375/-fm309) /
1027gr-tsf
• GPU Server, Mission-critical app., enterprise server,
oil & gas, financial, 3D rendering, chemistry, HPC
• Dual Intel® Xeon® processor E5-2600 family; Socket r
(LGA 2011)
• 4 Hot-swap 2.5“ SATA2/3 HDD Bays
• 8 DIMMs support up to 256GB DDR3 1600MHz reg. ECC
memory
• 3 (x16) PCI-E 3.0 and 1 (x8) PCI-E 3.0 (in x16) slots • I/O ports: 2 GbE/10GBase-T (TRFT), 1 Video, 1 COM/
Serial, 2 USB 2.0
• 10 heavy duty fans w/ optimal fan speed control • 1800W Redundant Platinum Level Power Supplies (TRF) • 1800W Platinum Level Power Supply (TSF)
• „-FM375/309“: 3x NVIDIA M2075/M2090 GPU cards
SUPE
rbl
Ad
E
Sol
U
tion
S
gpu superBlade
®solutions
sBi-7126tg
• Up to 20 GPU + 20 CPU per 7U!
• Up to 2 Tesla M2090/M2070Q/M2070/2050 GPU • Up to 2 Intel® Xeon® 5600/5500 series processors
• Up to 96GB DDR3 1333/1066 ECC DIMM • 1 internal SATA Disk-On-Module • 1 USB flash drive
• 2 PCI-E 2.0 x16 or 2 PCI-2.0 x8 or 2 PCI-2.0 x8
(Full-height/ maximum length 9.75“)
• Onboard BMC for IPMI 2.0 support - KVM over IP, remote
Virtual Media
• Dual IOH per blade
• Dual 40Gb InfiniBand or 10Gb Ethernet supported via optional mezzanine card
• Dual-port Gigabit Ethernet NIC • Redundant GBX connectors
sBi-7127rg
• Up to 120 GPU + 120 CPU per 42U Rack!
• Up to 2 Tesla M2090/M2075/M2070Q/M2070/2050 GPU • Up to 2 Intel® Xeon® E5-2600 series processors
• Up to 256GB DDR3 1600/1333/1066 ECC DIMM • 1 internal SATA Disk-On-Module
• 1 USB flash drive
• 2 PCI-E 2.0 x16 Full-heigh Full-length Expansion Slots • Onboard BMC for IPMI 2.0 support - KVM over IP, remote
Virtual Media
• 4x QDR (40Gb) InfiniBand or 10Gb Ethernet supported via optional mezzanine card
• Dual-port Gigabit Ethernet NIC
space optimization
When housed within a 19” EIA-310D industry-standard 42U rack, SuperBlade® servers reduce server footprint in
the datacenter. Power, cooling and networking devices are removed from each individual server and positioned to the rear of the chassis thereby reducing the required amount of space while increasing flexibility to meet changing business demands. Up to twenty DP blade nodes can be installed in a 7U chassis. Compared to the rack space required by twenty individual 1U servers, the SuperBlade® provides over 65% space savings.
Supermicro® offers GPU blade solutions optimized
for HPC applications, low-noise blade solutions for offices and SMB as well as personal supercomputing
applications. With acoustically optimized thermal and
cooling technologies it achieves < 50dB with 10 DP server blades and features 100-240VAC, Platinum
Level high-efficiency (94%+), N+1 redundant power
supplies.
access the poWer of gpu computing With off-the-shelf,
ready to deploy tesla gpu cluster
turnkey preconfigured
gpu clusters
ready-to-use solutions
for science and research
These preconfigured solutions from Supermicro and NVIDIA provide a powerful tool for researchers and scientists to advance their science through faster simulations. GPU Test Drive is the easiest way to start using GPUs that offer supercomputing scale HPC performance at substantially lower costs and power.
Experience a significant performance increase in a wide range of applications from various scientific domains. Supercharge your research with preconfigured Tesla
GPU cluster today!
42
tflops
10
tflops
20
tflops
gpu nodes: 4
cpu: 2x Westmere X5650 2.66GHz
memory: 24 GB per node
default gpu/node: 2x M2090
network cards/node: 1x InfiniBand
storage/node: 2x 500GB HDD (1TB/Node)
srs-14urks-gpus-11
gpu nodes: 8 + 1 Head node
cpu: 2x Westmere X5650 2.66GHz
memory: 48 GB per node default gpu/node: 2x M2090
network cards/node: 1x InfiniBand
storage/node: 2x 500GB HDD (1TB/Node)
srs-14urks-gpus-12
gpu nodes: 16 + 1 Head node
cpu: 2x Westmere X5650 2.66GHz
memory: 48 GB per node default gpu/node: 2x M2090
network cards/node: 1x InfiniBand
storage/node: 2x 1TB HDD (2TB/ Node)
hybrid
computing
tesla k10 gpu computing accelerator ― Optimizedfor single precision applications, the Tesla K10 is a throughput monster based on the ultra-efficient Tesla Kepler. The accelerator board features two Tesla Kepler and delivers up to 2x the performance for single precision applications compared to the previous generation Fermi-based Tesla M2090 in the same power envelope. With an aggregate performance of
4.58 teraflop peak single precision and 320 gigabytes
per second memory bandwidth for both GPUs put together, the Tesla
K10 is optimized for
computations in seismic, signal, image processing, and video analytics.
tesla k20 gpu computing accelerator ― Designed for double precision applications and the broader supercomputing market, the Tesla K20 delivers 3x the double precision performance compared to the previous generation Fermi-based Tesla M2090, in the same power envelope. Tesla K20 features a single Tesla Kepler that includes the Dynamic Parallelism and Hyper-Q features. With more than one teraflop peak double precision performance, the Tesla K20 is ideal for a wide range of high performance computing
workloads including climate and weather modeling, CFD, CAE, computational physics, biochemistry simulations, and computational finance.
technical specifications
TESLA K102 TESLA K20
Peak double precision floating point
performance (board) 0.19 teraflops To be announced Peak single precision floating point
performance (board) 4.58 teraflops To be announced
Number of GPUs 2 x GK104s 1 x GK110
CUDA cores 2 x 1536 To be announced
Memory size per board (GDDR5) 8 GB To be announced
Memory bandwidth for board (ECC off)3 320 GBytes/sec To be announced
GPU Computing Applications Seismic, Image, Signal Processing,
Video analytics
CFD, CAE, Financial computing, Computational chemistry and Physics, Data analytics, Satellite imaging, Weather modeling
Architecture Features SMX SMX, Dynamic Parallelism, Hyper-Q
System Servers only Servers and Workstations.
Available May 2012 Q4 2012
1 products and availability is subject to confirmation
2 Tesla K10 specifications are shown as aggregate of two GPUs.
3 With ECC on, 12.5% of the GPU memory is used for ECC bits. So, for example, 6 GB total memory yields 5.25 GB of user
supermicro is committed
to support
Tesla® Kepler ― World’s fastest and most power
efficient x86 accelerator
With the launch of Fermi GPU in 2009, NVIDIA ushered in a new era in the high performance computing (HPC) industry based on a hybrid computing model where CPUs and GPUs work together to solve computationally-intensive workloads. And in just a couple of years, NVIDIA Fermi GPUs powers some of the fastest supercomputers in the world as well as tens of thousands of research clusters globally. Now, with the new Tesla Kepler, NVIDIA raises the bar for the HPC industry, yet again.
Comprised of 7.1 billion transistors, the Tesla Kepler is an engineering marvel created to address the most daunting challenges in HPC. Kepler is designed from the ground
up to maximize computational performance with superior
power efficiency. The architecture has innovations that make hybrid computing dramatically easier, applicable to a broader set of applications, and more accessible. Tesla Kepler is a computational workhorse with teraflops of integer, single precision, and double precision performance and the highest memory bandwidth. The first GK110 based product will be the Tesla K20 GPU computing accelerator.
Let us quickly summarize three of the most important
features in the Tesla Kepler: SMX, Dynamic Parallelism, and Hyper-Q. For further details on additional
fastest, most efficient hpc architecture
architectural features, please refer to the Kepler GK110 whitepaper.
smx — next generation
streaming multiprocessor
At the heart of the Tesla Kepler is the new SMX unit, which comprises of several architectural innovations that make it not only the most powerful Streaming Multiprocessor (SM) we’ve ever built but also the most programmable and power-efficient.
dynamic parallelism —
creating Work on-the-fly
One of the overarching goals in designing the Kepler GK110 architecture was to make it easier for developers to more easily take advantage of the immense parallel processing capability of the GPU.
To this end, the new Dynamic Parallelism feature enables the Tesla Kepler to dynamically spawn new threads by adapting to the data without going back to the host CPU. This effectively allows more of a program to be run directly on the GPU, as kernels now have the ability to independently launch additional workloads as needed. Any kernel can launch another kernel and can create the necessary streams, events, and dependencies needed to process additional work without the need for host CPU interaction. This simplified programming model is
easier to create, optimize, and maintain. It also creates
a programmer friendly environment by maintaining the same syntax for GPU launched workloads as traditional CPU kernel launches.
Dynamic Parallelism broadens what applications can now accomplish with GPUs in various disciplines.
Applications can launch small and medium sized
parallel workloads dynamically where it was too expensive to do so previously.
Figure 1: SMX: 192 CUDA cores, 32 Special Function Units (SFU), and 32 Load/Store units (LD/ST)
CONTROL LOGIC CONTROL LOGIC
SM
FERMI
32 CORES 192 CORES
SMX
KEPLER
3X
PERF/WATTnvidia
®
tesla
®
kepler
..
nV
idi
A®
tES
lA
®
kEP
lE
r
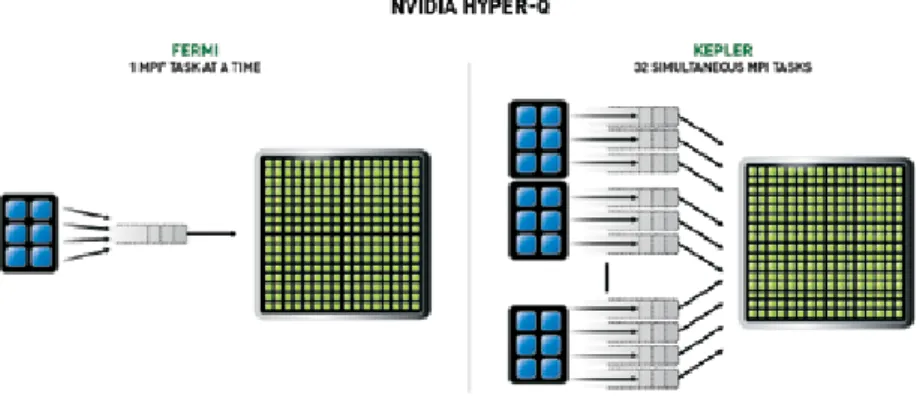
hyper-Q — maximizing the gpu resources
Hyper-Q enables multiple CPU cores to launch work on a single GPU simultaneously, thereby dramaticallyincreasing GPU utilization and slashing CPU idle times.
This feature increases the total number of connections between the host and the the Tesla Kepler by allowing 32 simultaneous, hardware managed connections, compared to the single connection available with Fermi. Hyper-Q is a flexible solution that allows connections for both CUDA streams and Message Passing Interface (MPI) processes, or even threads from within a process. Existing applications that were previously limited by false dependencies can see up to a 32x performance increase without changing any existing code.
Hyper-Q offers significant benefits for use in MPI-based parallel computer systems. Legacy MPI-MPI-based algorithms were often created to run on multi-core CPU-based systems. Because the workload that could be efficiently handled by CPU-based systems is generally smaller than that available using GPUs, the amount of work passed in each MPI process is generally insufficient to fully occupy the GPU processor.
While it has always been possible to issue multiple MPI processes to concurrently run on the GPU, these processes could become bottlenecked by false dependencies, forcing the GPU to operate below peak efficiency. Hyper-Q removes false dependency bottlenecks and dramatically increases speed at which MPI processes can be moved from the system CPU(s) to the GPU for processing.
Hyper-Q promises to be a performance boost for MPI applications.
conclusion
Tesla Kepler is engineered to deliver ground-breaking performance with superior power efficiency while making GPUs easier than ever to use. SMX, Dynamic Parallelism, and Hyper-Q are three important innovations in the Tesla Kepler to bring these benefits to reality for our customers. For further details on additional architectural features, please refer to the Kepler GK110 whitepaper at
www.nvidia.com/kepler
CPU GPU CPU GPU
DYNAMIC PARALLELISM
Figure 3: Hyper-Q allows all streams to run concurrently using a separate work queue. In the Fermi model, concurrency was limited due to intra-stream dependencies caused by the single hardware work queue.
Figure 2: Without Dynamic Parallelism, the CPU launches every kernel onto the GPU. With the new feature, Tesla Kepler can now launch nested kernels, eliminating the need to communicate with the CPU.
CUDA architecture has the industry’s most robust language and API support for GPU computing
developers, including C, C++, OpenCL, DirectCompute,
and Fortran. NVIDIA Parallel Nsight, a fully integrated development environment for Microsoft Visual Studio is also available. Used by more than six million developers worldwide, Visual Studio is one of the world’s most popular development environments for Windows-based applications and services. Adding functionality specifically for GPU computing developers, Parallel Nsight makes the power of the GPU more accessible than ever before. The latest version - CUDA 4.0 has seen a host of new exciting features to make parallel computing easier. Among them the ability to relieve bus traffic by enabling GPU to GPU direct communications.
cuda
integrated development environment
research &
education liBraries
tools & partners all major
platforms
mathematical packages languages
& apis consultants, training, &
certification
programming environment
for gpu computing
nvidia’s cuda
Order personalized CUDA education course at:
www.parallel-computing.pro
* use your phone, smartphone or tablet pc with Qr reader software to read the Qr code.
Watch video*:
pgi accelerator, technical presentation at sc11
accelerate your code easily
With openacc directives
get 2x speed-up in 4 Weeks or less
Accelerate your code with directives and tap into the hundreds of computing cores in GPUs. With directives, you simply insert compiler hints into your code and the compiler will automatically map compute-intensive portions of your code to the GPU.
By starting with a free, 30-day trial of PGI directives today, you are working on the technology that is the foundation of the OpenACC directives standard. OpenACC is:
• easy: simply insert hints in your codebase
• open: run the single codebase on either the CPU or GPU
• powerful: tap into the power of GPUs within hours
openacc directives
The OpenACC Application Program Interface describes a collection of compiler directives to specify loops and
regions of code in standard C, C++ and Fortran to be
offloaded from a host CPU to an attached accelerator, providing portability across operating systems, host CPUs and accelerators.
The directives and programming model defined in this document allow programmers to create
high-level host+accelerator programs without the need to explicitly initialize the accelerator, manage data or
program transfers between the host and accelerator, or initiate accelerator startup and shutdown.
hybrid
computing
What is gpu computingGPU computing is the use of a GPU (graphics processing unit) to do general purpose scientific and engineering comp
history of gpu computing
Graphics chips started as fixed function graphics pipelines. Over the years, these graphics chips became increasingly programmab
relativ
e
perf
ormanc
e
sc
al
e
(normalized ns/da
y)
1,5
1,0
0,5
192 Quad-core cpus 2 Quad-core cpus + 4 gpus 50% Faster
with GPUs
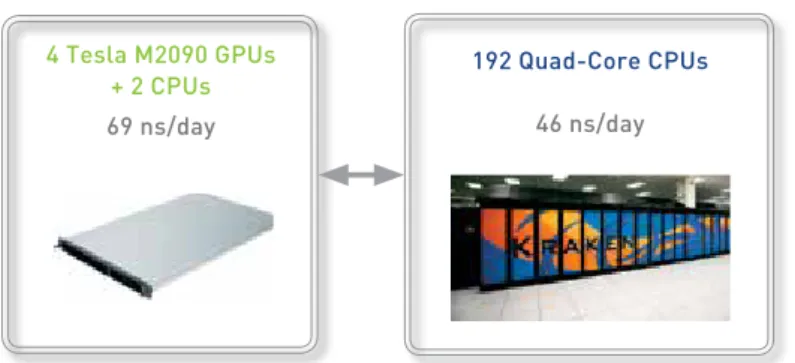
JAC NVE Benchmark
(left) 192 Quad-Core CPUs simulation run on Kraken Supercomputer (right) Simulation 2 Intel Xeon Quad-Core CPUs and 4 Tesla M2090 GPUs
gpu acceleration in life sciences
tesla
®Bio WorkBench
The NVIDIA Tesla Bio Workbench enables biophysicists and computational chemists to push the boundaries of life sciences research. It turns a standard PC into a “computational laboratory” capable of running complex bioscience codes, in fields such as drug discovery and DNA sequencing, more than 10-20 times faster through the use of NVIDIA Tesla GPUs.
It consists of bioscience applications; a community site for downloading, discussing, and viewing the results of these applications; and GPU-based platforms.
Complex molecular simulations that had been only possible using supercomputing resources can now
be run on an individual workstation, optimizing the
scientific workflow and accelerating the pace of research. These simulations can also be scaled up to GPU-based clusters of servers to simulate large molecules and systems that would have otherwise required a supercomputer.
Applications that are accelerated on GPUs include:
• Molecular Dynamics &
Quantum chemistry
AMBEr, GrOMACS, HOOMD, LAMMPS, NAMD, TeraChem (Quantum Chemistry), VMD
• Bio informatics
BLASTP, EC,
MEME, CUDASW++
Waterman), GPU-HMMEr, MUMmerGPU
For more information, visit:
NVIDIA® TESLATM / HybrID coMpuTINg SoLuTIoNS 2010
192 Quad-core cpus
46 ns/day
4 tesla m2090 gpus + 2 cpus
69 ns/day
amBer: node processing comparison
gromacs
GrOMACS is a molecular dynamics package designed primarily for simulation of biochemical molecules like proteins, lipids, and nucleic acids that have a lot complicated bonded interactions. The CUDA port of GrOMACS enabling GPU acceleration supports Particle-Mesh-Ewald (PME), arbitrary forms of
non-bonded interactions, and implicit solvent Generalized
Born methods.
Workstation • 4xTesla C2070
• Dual-socket Quad-core CPU • 24 GB System Memory Server • Up to 8x Tesla M2090s in cluster • Dual-socket Quad-core CPU per node • 128 GB System Memory
recommended hardWare configuration
server
• 8x Tesla M2090
• Dual-socket Quad-core CPU • 128 GB System Memory
amBer
researchers today are solving the world’s most challenging and important problems. From cancer research to drugs for AIDS, computational research is bottlenecked by simulation cycles per day. More simulations mean faster time to discovery. To tackle these difficult challenges, researchers frequently rely on national supercomputers for computer simulations of their models. GPUs offer every researcher supercomputer-like performance in their own office. Benchmarks have shown four Tesla M2090 GPUs significantly outperforming the existing world record on CPU-only supercomputers.
GPU
A
CCE
lE
r
Ation
in
l
if
E S
Ci
En
CES
Figure 4: Absolute performance of GrOMACS running CUDA- and SSE-accelerated non-bonded kernels with PME on 3-12 CPU cores and 1-4 GPUs. Simulations with cubic and truncated dodecahedron cells, pressure coupling, as well as virtual interaction sites enabling 5 fs are shown.
29 .3 8.9 45 .6 16 .0 72. 4 28. 4 28 .5 8.7 44 .8 15 .6 70. 4 27 .7 12 .1 36 .7 49 .7 21. 9 85 .7 34 .4 83 .9 26 .9 11 4. 9 47 .5 16 5. 8 74 .4 cubic 0 20 40 60 80 100 120 140 160 180 3t+c2075 3t 6t+2xc2075 6t 12t+4xc2075 12t ns /d ay cubic
GPU
tES
t
d
ri
VE
learn more and order today at:
www.nvidia.eu/cluster
amBer and namd 5x faster
take a free and easy test drive today
run your molecular dynamics simulation 5x faster. Take a free test drive on a remotely-hosted cluster loaded with the latest GPU-accelerated applications such as AMBEr and NAMD
and accelerate your results. Simply log on and run your application as usual, no GPU programming expertise required. Try it now and see how you can reduce simulation time from days to hours.
amBer cpu vs. gpu performance
ns/
d
ay (
h
igher is Bett
er)
5 4 3 2 1 0
2 nodes 4 nodes
cellulose npt – up to 3.5x faster
Benchmarks for AMBEr were generated with the following config -1 Node includes: Dual Tesla M2090 GPU (6GB), Dual Intel 6-core X5670 (2.93 GHz), AMBER 11 + Bugfix17, CUDA 4.0, ECC off.
3.00
0.66
1.20 3.96
2.04 4.56
1 node Сpu only cpu + gpu
namd cpu vs. gpu performance
ns/
d
ay (
h
igher is Bett
er)
1.0
0.8 0.6
0.4 0.2
0
2 nodes 4 nodes
stmv – up to 6.5x faster
Benchmarks for NAMD were generated with the following config -1 Node includes: Dual Tesla M2090 GPU (6GB), Dual Intel 4-core Xeon
(2.4 GHz), NAMD 2.8, CUDA 4.0, ECC On.
0.30
0.04 0.08
0.54
0.16 1.04
1 node Сpu only cpu + gpu
try the tesla gpu test drive today!
step
1
register
step
3
run your application and get faster results
upload your data
With ANSYS® Mechanical™ 14.0 and NVIDIA®
Professional GPUs, you can:
• Improve product quality with 2x more design
simulations
• Accelerate time-to-market by reducing engineering
cycles
• Develop high fidelity models with practical solution
times
How much more could you accomplish if simulation times could be reduced from one day to just a few hours? As an engineer, you depend on ANSYS Mechanical to design high quality products efficiently. To get the most out of ANSYS Mechanical 14.0, simply upgrade your Quadro GPU or add a Tesla GPU to your workstation, or configure a server with Tesla GPUs, and instantly unlock the highest levels of ANSYS simulation performance.
future directions
As GPU computing trends evolve, ANSYS will continue to enhance its offerings as necessary for a variety of simulation products. Certainly, performance improvements will continue as GPUs become computationally more powerful and extend their functionality to other areas of ANSYS software.
gpu accelerated engineering
ansys: supercomputing from your Workstation
With nvidia tesla gpu
What can product engineers achieve if a single
simulation run-time reduced from 48 hours to 3
hours? CST Microwave Studio is one of the most widely used electromagnetic simulation software and some of the largest customers in the world today are leveraging GPUs to introduce their products to market faster and with more confidence in the fidelity of the product design.
20x faster simulations With gpus
design superior products
With cst microWave studio
recommended tesla configurations
Workstation • 4x Tesla C2070
• Dual-socket Quad-core CPU • 48 GB System Memory
server
• 4x Tesla M2090
• Dual-socket Quad-core CPU • 48 GB System Memory
relativ
e
perf
ormanc
e v
s
cpu
25
20
15
10
5
0
2x cpu 2x cpu + 1x c2070
2x cpu + 4x c2070 9x faster with
tesla gpu
23x faster with tesla gpus
Benchmark: BGA models, 2M to 128M mesh models. CST MWS, transient solver.
CPU: 2x Intel Xeon X5620.
Single GPU run only on 50M mesh model.
A new feature in ANSYS Mechanical
leverages graphics processing units to
significantly lower solution times for large
analysis problem sizes.”
By Jeff Beisheim, Senior Software Developer, ANSYS, Inc.
• Nastran direct equation solver is GPU accelerated
– Real, symmetric sparse direct factorization
– Handles very large fronts with minimal use of pinned host memory
– Impacts SOL101, SOL400 that are dominated by
MSCLDL factorization times
– More of Nastran (SOL108, SOL111) will be moved
to GPU in stages
• Support of multi-GPU and for both Linux and Windows
– With DMP> 1, multiple fronts are factorized
concurrently on multiple GPUs; 1 GPU per matrix domain
– NVIDIA GPUs include Tesla 20-series and Quadro 6000
– CUDA 4.0 and above
msc nastran, marc
5x performance Boost With single gpu over single core,
>1.5x With 2 gpus over 8 core
gpu acceleration in computer aided engineering
simulia aBaQus / standard
reduce engineering simulation times in half
As products get more complex, the task of innovating with more confidence has been ever increasingly difficult for product engineers. Engineers rely on Abaqus to understand behavior of complex assembly or of new materials.
With GPUs, engineers can run Abaqus simulations twice as fast. A leading car manufacturer, NVIDIA customer, reduced the simulation time of an engine model from 90 minutes to 44 minutes with GPUs. Faster simulations enable designers to simulate more scenarios to achieve, for example, a more fuel efficient engine.
speed up v
s.
cpu
onl
y
number of equations (millions)
1,5 1,5 3,0 3,4 3,8
1,9
1,8
1,7 1,6 1,5 1,4 1,3 1,2 1,1 1
abaqus 6.12 multi gpu execution 24 core 2 host, 48 gB memory per host
1 GPU/Host 2 GPUs/Host
speed up
* fs0= NVIDIA PSG cluster node
2.2 TB SATA 5-way striped rAID Linux, 96GB memory,Tesla C2050, Nehalem 2.27ghz 7
6 5 4 3 2 1
0 3.4m dof; fs0; total 3.4m dof; fs0; solver
sol101, 3.4m dof
1 Core 1 GPU + 1 Core 2 GPU + 2 Core
(DMP=2) 4 Core (SMP) 8 Core (DMP=2)
4.6x 5.6x
1.6x
1.8x
GPU
A
CCE
lE
r
At
Ed
En
G
in
EE
rin
visualize and simulate
at the same time on a single system
nvidia
®maximus™ technology
Engineers, designers, and content creation professionals are constantly being challenged to find new ways to explore and validate more ideas — faster. This often involves creating content with both visual design and physical simulation demands. For example, designing a car or creating a digital film character and understanding how air flows over the car or the character‘s clothing moves in an action scene.
Unfortunately, the design and simulation processes have often been disjointed, occurring on different systems or at different times.
introducing nvidia maximus
NVIDIA Maximus-powered workstations solve
this challenge by combining the visualization and
interactive design capability of NVIDIA Quadro GPUs and the high-performance computing power of NVIDIA Tesla GPUs into a single workstation. Tesla companion processors automatically perform the heavy lifting of photorealistic rendering or engineering simulation computation. This frees up CPU resources for the work they‘re best suited for – I/O, running the operating system and multi-tasking – and also allows the Quadro GPU to be dedicated to powering rich, full-performance, interactive design.
reinventing the WorkfloW
With Maximus, engineers, designers and content creation professionals can continue to remain productive and work with maximum complexity in real-time.
traditional workstation
nvidia® maximus™ workstation
design simulate (cpu)
design design 2 design 3 design 4
+
faster iterations = faster time to market
+
+
+
simulate (gpu) simulate (gpu) simulate (gpu) simulate (gpu)
* use your phone, smartphone or tablet pc with Qr reader software to read the Qr code.
Watch video*:
nvidia maximus technology helps drive
nV
idi
A
®
mAX
im
US
™
tECH
nol
o
Gy
simulation analysis
and cad
photorealistic rendering
and cad
ray tracing With catia
live rendering
fast, fluid editing
With premiere pro
With Maximus technology, you can perform simultaneous structural or fluid dynamics analysis with applications such as ANSYS while running your design application, including SolidWorks and PTC Creo. For more information, visit
www.nvidia.co.uk/object/tesla-ansys-accelerations-uk
For more information, visit
www.nvidia.co.uk/object/ quadro-3ds-max-uk
For more information, visit
www.nvidia.co.uk/object/ quadro-catia-uk
For more information, visit
www.nvidia.co.uk/object/adobe_ PremiereproCS5_uk
With Maximus technology, you can perform rapid photorealistic rendering of your designs in applications such as 3ds Max or Bunkspeed while still using your system for other work.
With Maximus technology, photorealistic rendering is interactive. And it allows you to simultaneously run other applications without bogging down your system.
With Maximus technology, you can relieve the pressure of getting more done in less time.
faster simulations, more joB instances
relative Performance Scale vs 2 CPU Cores
8 cpu cores + tesla c2075
8 CPU Cores
2 CPU Cores
relative Performance 0 1 2 3 4 5
maximus performance for 3ds max 2012 With iray Relative Performance Scale vs 8 CPU Cores
tesla c2075 + Quadro 6000 tesla c2075 + Quadro 5000 tesla c2075 + Quadro 4000 tesla c2075 + Quadro 2000
Quadro 2000 8 CPU Cores
relative Performance 0 1 2 3 4 5 6 7 8 9 10
adoBe premiere pro price/performance*
Adobe Mercury Playback Engine (MPE)
tesla c2075 + Quadro 2000 Quadro 6000 Quadro 5000 Quadro 4000
Quadro 2000 8 CPU Cores % Value Increase
* Adobe Premier Pro results obtained from 5 layers 6 effects per layer output to H.264 on a Dell T7500, 48 GB, Windows 7 at 1440 x 1080 resolution. Price performance calculated using cost per system and number of clips possible per hour.
0 100 200 300 400 500 600
maximus performance for catia live rendering Relative Performance Scale vs 8 CPU Cores
tesla c2075 + Quadro 6000 tesla c2075 + Quadro 4000
Quadro 4000 8 CPU Cores
© 2012 nVidiA Corporation. All rights reserved. nVidiA, the nVidiA logo, nVidiA tesla, CUdA, Gigathread, Parallel dataCache and Parallel nSight are trademarks and/or registered trademarks of nVidiA Corporation. All company and product names are trademarks or