WHITE PAPER
Choosing an Enterprise-Class
Deduplication Technology
10 Key Questions to Ask Your
Deduplication Vendor
400 Nickerson Road, Marlborough, MA 01752 | P: 866.Sepaton or 508.490.7900 | F: 508.490.7908 | www.Sepaton.com Copyright 2012. Sepaton, Inc. All rights reserved.
Sepaton, S2100, DeltaStor, DeltaRemote, and SRE are registered trademarks and ContentAware, Secure Erasure, and DeltaScale are trademarks of Sepaton, Inc. Other product and company names mentioned herein are or may be trademarks and/or registered trademarks of their respective companies. 10-121v2
Deduplication Specifically Designed for Enterprises
The volume of data generated by most companies has grown at such an explosive rate that many data centers have simply run out of space, power, cooling, and storage capacity to handle it. In large enterprise organizations, the sheer volume and variety of data to be
protected requires a level of performance and scalability that few data protection technologies can deliver. Fundamental issues of insufficient capacity are being compounded by
increasingly stringent regulatory requirements and business initiatives demanding higher service levels, longer online retention times, and higher levels of data protection. For small to medium-sized organizations there are several deduplication technologies available that can meet their needs. However, for large enterprise organizations with “big data” environments to protect, these deduplication technologies fall short. Understanding the strengths and weaknesses of deduplication technologies can help you choose a solution that best meets the needs of your large enterprise data protection environment. At a minimum, an enterprise deduplication technology should:
• Allow high-performance backup, replication, and recovery
• Reduce capacity requirements to avoid the need for data center build-out and stay within power consumption limits
• Meet service level agreements and regulatory requirements for fast data recovery by keeping more data online longer
• Minimize WAN usage and end-user disruption by completing backups within backup windows
• Control the cost of adding capacity and performance by avoiding technologies that require complete “forklift” upgrades to scale
• Ensure data integrity throughout backup, retention, and restore processes • Minimize downtime while meeting all regulatory requirements.
• Provide a view into the backup, deduplication, and replication efficiency at a granular level.
• Support data centers that are using more than one backup application (e.g., Symantec NetBackup, IBM TSM, etc.) and backup protocol (e.g., Fibre Channel, 1 and 10 GB Ethernet).
• Deduplicate data from large databases (Oracle, SAP, SQL Server), and from analytical tools used to manage big data environments efficiently.
400 Nickerson Road, Marlborough, MA 01752 | P: 866.Sepaton or 508.490.7900 | F: 508.490.7908 | www.Sepaton.com | Page 2
Choosing the Right Deduplication for Your Environment
There are several different types of deduplication technologies to choose from. Some are better suited to departments and small to medium-sized enterprises (SMEs); others are optimized for enterprise use and “big data” backup environments. Consider the strengths and drawbacks of each of these technologies to choose the solution that best meets your
requirements. Ten key questions are provided on page 4 to help IT managers determine whether a deduplication technology can meet the needs of a large enterprise data center.
Deduplication Technologies
Understanding the distinctions between each category of deduplication technology is essential for choosing the most appropriate one for the specific environment. All
deduplication technologies compare the data in each backup set to data in a baseline data set to identify duplication. New data is stored and duplicate data is replaced with a pointer to a single reference copy. The key distinctions among deduplication technologies are as follows:
Source vs Target Deduplication
The first distinction refers to where the deduplication process is performed. Source
deduplication is typically performed either on the backup media server or on individual client systems (desktops and servers) to reduce the amount of data sent to the target, but it may also be performed before data is sent to backup media servers. The client system may leverage the file system to locate just those files that have changed since the previous backup or it may compute hashes to describe every file. Target deduplication is used to process larger data volumes. Target-based deduplication can be performed inline, post process, or concurrently.
Inline, Post Process, and Concurrent Deduplication
The second distinction refers to when the deduplication is performed relative to the backup data being written to the target disk. Deduplication may be performed inline before it is sent to the target, it may be performed as a post process after the backup reaches the target, or it may be performed concurrently along with data ingest to the target. Source deduplication is typically performed inline. Target deduplication may be performed inline, post process, or concurrently. In post-processing systems, the goal is to ingest and protect the backups at the maximum possible speed, minimizing the time to safety. Some systems back up data to disk, and then post process deduplication in discrete steps. While this improves the backup time, it slows completion of deduplication, replication, and restore processes. In contrast,
concurrent post processing performs backup, deduplication, replication, and restore
operations concurrently, load balancing these operations across multiple nodes, if necessary. This process results in an optimal balance of time to safety and capacity reduction.
Hash vs. ContentAware™ Deduplication
The third distinction refers to the methodology used to identify data as duplicate. Hash-based technologies analyze segments of data as they are backed up and assign a unique identifier
called a hash to each segment. Most of these technologies use an algorithm that computes a cryptographic hash value from a fixed or variable segment of data in the backup stream, independent of the data type. The hashes are stored in an index. As each backup is performed, the hashes of incoming data are compared to those in the index. If the hash already exists, the incoming data is replaced with a pointer to the hash. Some source
deduplication approaches work on chunks of data rather than on entire files, where a chunk is some multiple of the block size used on the target.
ContentAware deduplication reads metadata from the incoming data stream and uses a unique process to identify duplicate data at the byte level. Table 1 compares deduplication technologies.
Backward vs Forward Referencing
The fourth distinction refers to the way data is identified and tracked as duplicate in the backup. Deduplication technologies all compare incoming data to a baseline or reference data set to identify duplicates. Hash-based technologies, whether they are inline or post-processed, use the first (oldest) backup as the baseline. Every new backup is compared against it and duplicate data in the latest backup is replaced with pointers back to the older baseline data.
In contrast, concurrent, ContentAware deduplication technologies use the most recent backup as the baseline and replace pointers in older data with pointers forward to it. Each new backup replaces the previous one as the baseline and pointers are refreshed to point forward to it in older backups. With this methodology, the system maintains a full, intact copy of the most recent backup for immediate restores.
The questions on the following pages can help IT managers ensure that they choose a deduplication technology that can meet the specific needs of large enterprises.
400 Nickerson Road, Marlborough, MA 01752 | P: 866.Sepaton or 508.490.7900 | F: 508.490.7908 | www.Sepaton.com | Page 4
10 Key Questions to Ask Your Deduplication Vendor
1. What impact will deduplication have on backup performance – both now and over time?
High performance is essential to large enterprises that need to move massive data volumes to the safety of a backup environment within a finite backup window. Inline deduplication, whether it is performed at the source or at the target, is not recommended for large data volumes because it can cause bottlenecks that degrade ingest performance for a number of reasons. First, inline deduplication systems cannot be scaled across multiple processors. All backup and deduplication processing has to be performed on a single node1.If a restore request is processed during deduplication, the restore also has to be performed on the single node. Performance is not only slowed, it is unpredictable. If a company has backup volume and data protection requirements that need the performance of multiple nodes, the IT staff has to divide the backup onto multiple separate systems. Data is not deduplicated among the individual systems, creating an inherently less efficient capacity optimization environment. Second, because hash calculations and lookups take time, data ingestion in inline/hash-based system can be slower, therefore reducing the backup throughput of the device. This bottleneck worsens over time, as the index table grows, and more data in the index needs to be located and compared. The benefit of the hash-based approach is that in a steady-state condition where there is a small rate of change between successive backups (typically < 5 percent); only the new data is written to disk. The performance of these systems is
constrained by both the index lookup speed and the storage subsystem, which is optimized for a relatively low write throughput.
As the index size grows larger than available memory, the index must be paged to/from disk, resulting in lower performance. A new full backup (due to a new server being added to the backup mix) will result in rapid index updates combined with maximum write requests, resulting in extremely low performance.
Third, hash-based inline technologies perform a very CPU-intensive process called
“housecleaning”. During this process, which can take as long as 12 hours nightly, the system “cleans” and organizes the hash index and actually reclaims the capacity gained through deduplication in a “batch process.” As a result, administrators need to carefully plan and schedule cleaning windows or delay backups until capacity becomes available.
ContentAware deduplication systems can scale both capacity and performance. They backup data at wire speed and perform the analysis, comparison, deduplication, and capacity
reclamation processes concurrently. Although this method needs slightly more capacity, its performance and capacity can be scaled easily to backup and deduplicate petabytes of data on a single appliance without degrading performance. Capacity reclamation is continuous and automatic without CPU- housekeeping processes or the need for complex scheduling.
1
Some vendors sell two-node clustered systems, but they do not support the same connectivity and features of their single-node products. In the case of one vendor, a failure of either node renders the entire system unavailable.
2. Will deduplication degrade my restore performance?
Understand the time required to restore files that were backed within the previous 30 days (the most common category of restore request). As described in Backward vs Forward Referencing above, hash-based deduplication typically uses backward referencing. Forward referencing delivers faster time to recovery for the most frequently needed data. (According to analysts, 90 percent of recovery requests are for data that is less than 30 days old.) Forward referencing technologies keep the last backup available for instant restore and tape vaulting with no need to find and replace pointers with baseline data.
3. How will you scale capacity and performance as your environment grows?
Calculate how much data you will be able to store on a single backup system with
deduplication given your specific deduplication ratios, policies, and data types. Understand the implications of exceeding that capacity in terms of administrative complexity, capital expense, and disruption to your environment.
Some deduplication technologies, particularly those that are performed in-line, cannot easily scale. To perform backups fast enough to stay within your backup window, you need to add multiple independently managed appliances. Overall efficiency of deduplication is reduced because the data comparisons that identify duplicate data are only performed within individual devices. Many deduplication solutions top out at backup rates of 800 Gb/hr. per appliance. At this rate, to backup 10 TB of data in an eight-hour backup window, you would need numerous appliances. That would add significant complexity and require you to modify backup infrastructure/policies. As your data grows, more appliances need to be deployed and managed. This creates “silos of deduplication” and a management challenge. Overall
efficiency of deduplication is also dramatically reduced because the data comparisons that identify duplicate data are only performed within individual devices. Truly enterprise-class ContentAware deduplication solutions can backup data as fast as 43.2 TB/hr. and handle petabytes of data in a single appliance.
4. Can you efficiently deduplicate large multiplexed, multi-streamed databases (e.g., Oracle, SAP, SQL Server)?
Deduplication technologies face the challenge of delivering more granular comparisons of data without slowing the backup process. In large enterprises with massive data volumes, the more closely that data is examined, the more CPU resources are required to deduplicate it. Inline deduplication technologies cannot afford to examine data in sections smaller than 8 KB because doing so would severely slow backup performance and increase the size of the hash table index. This granularity of comparison is particularly important in deduplicating large databases, such as Oracle, SAP, and Exchange, as well as analytical tools used to manage big data environments that store data in segments of 8 KB or smaller. For these critical applications, a large volume of duplicate data is completely unidentified by inline solutions. ContentAware technology, however, performs byte-level comparison, enabling it to deliver significantly greater deduplication efficiency in large data base environments.
400 Nickerson Road, Marlborough, MA 01752 | P: 866.Sepaton or 508.490.7900 | F: 508.490.7908 | www.Sepaton.com | Page 6 5. How efficient is your deduplication technology in progressive incremental backup
environments such as Tivoli Storage Manager (TSM) and in NetBackup OST?
Inline solutions are also are inefficient in deduplicating non-file backups, TSM progressive incremental backups, and backups from applications that fragment their data, such as NetWorker, HP Data Protector, and Symantec OST. ContentAware deduplication technology uses the metadata from these backup applications to identify the areas of data that are likely to contain duplicate data. As described in question #4 above, they perform a byte-level comparison of data for optimal capacity reduction.
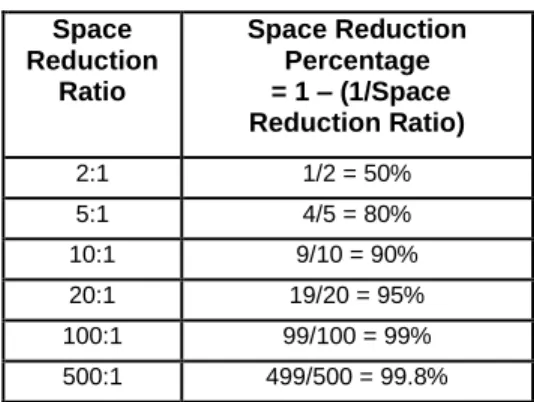
6. What are realistic expectations for capacity reduction?
The efficiency of a deduplication solution to remove duplicate data determines how much space can be saved. However, if there are no duplicate copies of data in the backup, there can be no space savings. Some data types and application environments typically contain more duplicate copies than others. Data deduplication ratios can vary widely depending on a number of factors, from type of data to frequency of data change and retention period. Although many deduplication vendors claim very high deduplication ratios, these ratios assume a 1 percent data change rate and that datasets are the typical mix of data type found in SMB companies. Capacity reduction savings are summarized in Table 1. Note that a 5:1 ratio reduces storage needs by 80 percent and yields tremendous cost savings. However, there is only a 10 percent difference between a 5:1 and a 10:1 reduction ratio. The bulk of actual capacity savings is between a 2:1 and 5:1 deduplication ratio. The amount of duplicate data in a specific environment is also determined by a number of factors, such as:
• Data type. Unstructured, semi-structured, and structured data each result in different deduplication results as follows.
-Unstructured data files. File data such as Microsoft Word, PowerPoint, or Excel files created by office workers often contain redundant data and are frequently distributed or copied.
-Semi-structured and structured data types.
Data created by specific business applications that ensure that operations can be run on a day-to-day basis. For example, Microsoft Exchange for email and Oracle for a transactional database clearly fall into the “must protect” category and require frequent backup.
• Frequency of data change. The less frequently that data is modified the greater the chance that copies of that data will contain duplicate data. The data deduplication ratio will be higher when the change rate is lower. This also implies that a higher data deduplication ratio should be expected as the percentage of reference data to total active data
increases, because reference data is not changed.
• Retention period. A longer retention period increases the likelihood that duplicate data will be found. Assume a retention window of 90 days and an internal process by which full backups are performed weekly. In this example, the initial full backup will only be
deduplicated against itself and will result in a small reduction in storage footprint. When the subsequent full weekly backup for week 2 is performed, only the unique data that has been changed will be stored. When the full backup for week 8 is performed, it will be compared against all the unique data for weeks 1, 2, 3, 4, 5, 6, and 7, which increases the chances that duplicate data will be found.
Table 1: Reduction Ratio Comparison Space
Reduction Ratio
Space Reduction Percentage = 1 – (1/Space Reduction Ratio)
2:1 1/2 = 50%
5:1 4/5 = 80%
10:1 9/10 = 90%
20:1 19/20 = 95%
100:1 99/100 = 99%
• Single vs. multiple pools. Some data protection platforms allow you to separate data into discrete storage pools for increased effectiveness for specific data types. For example, a storage pool can be created for all Exchange data. Deduplication will compare a new backup to the previous Exchange data backup, resulting in a much higher reduction ratio than without storage pools, where the same policy and rules are applied across all data, regardless of type.
Rather than pushing for higher generic ratios, a more effective strategy is to choose a solution that guarantees the ability to move data to safety within backup windows while also providing efficient deduplication. Concurrent processing and deterministic ingest rate, deduplication, and replication are key enablers to an enterprise environment.
7. Can administrators monitor backup, deduplication, replication, and restore enterprise-wide?
Deduplication technologies that do not scale, force IT managers to separate backup operations onto multiple independent systems, each of which has to be managed and optimized separately. Scalable, ContentAware deduplication systems enable administrators to monitor and manage the precise status of data as it passes through backup, deduplication, replication and restore and archive operations. This holistic view of the data protection environment enables them to manage more data per administrator, fine tune the backup environment for optimal efficiency, and to plan accurately for future performance and capacity requirements.
8. Can your deduplication help reduce replication bandwidth requirements for large enterprise data volumes?
Some inline deduplication technologies enable companies to replicate data across a WAN efficiently. However, these inline solutions cannot handle large data volumes efficiently and do not enable efficient restore times. ContentAware deduplication works in conjunction with replication software to reduce bandwidth requirements by as much as 97 percent.
9. Can I “tune” the deduplication to meet my needs?
Enterprise data protection environments may have data types that have special deduplication requirements. For example, IT manager may not want to deduplicate some volumes of backup data for regulatory compliance purposes. Or, they may not want to waste processing cycles on image data or other data that is unlikely to contain duplicates. Hash-based
deduplication technologies are “all or nothing” and are capable of performing only one level of deduplication comparison. ContentAware solutions enable IT managers to choose the
volumes of data that they want to deduplicate by server, backup application, and by data volume. They also automatically detect the type of data being backed-up automatically perform the method of deduplication that is most efficient for that data type.
400 Nickerson Road, Marlborough, MA 01752 | P: 866.Sepaton or 508.490.7900 | F: 508.490.7908 | www.Sepaton.com | Page 8
Conclusion
For large enterprises with massive data volumes, inline deduplication (at the source or target) cannot provide sufficient time to safety, capacity reduction efficiency, or replication bandwidth optimization to be practical or cost-efficient. The Sepaton DeltaStor® data deduplication software was designed with a variety of advanced features to specifically address the needs of large enterprises. DeltaStor delivers the fastest, most efficient, and most cost-effective way for enterprises to back up, deduplicate, replicate, and restore large data volumes.
DeltaStor’s innovative, enterprise-class features include concurrent processing, which enables Sepaton products to back up petabytes of data within stringent backup windows while providing fast, efficient deduplication processing. Concurrent processing also enables DeltaStor to take advantage of Sepaton’s unique grid architecture to leverage the processing power of up to eight nodes to perform backup, deduplication, replication, and restore
simultaneously at the industry’s highest rates.
DeltaStor was also designed with unique forward referencing pointers to enable instant restores of the most recently backed up and most recently replicated data for optimal business continuity and RTOs. This feature also enables the industry’s most efficient tape vaulting by eliminating the need to “reconstitute” deduplicated data before it is written to tape. Automated transparent space reclamation saves administration time and frees capacity faster by reclaiming space continuously. Administrators no longer need to plan and schedule cleaning windows or delay backups until capacity becomes available.
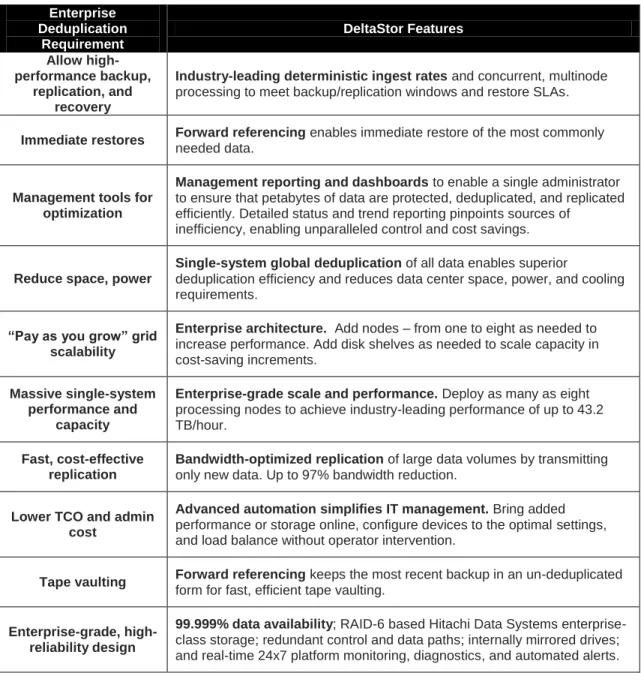
Because enterprises rely on large, complex databases such as Oracle and SAP to run critical business operations, Sepaton designed DeltaStor to examine data in sub-8 KB increments used in these systems. Patented technologies enable DeltaStor to examine data at a more granular level and to find duplicate data more efficiently than does any other deduplication technology. As a result, Sepaton delivers the most efficient capacity reduction in the industry. As demonstrated in several use case scenarios, many of the world’s largest enterprises have standardized on Sepaton S2100 data protection products with DeltaStor. Sepaton delivers the only products with performance, scalability, single-system capacity, deduplication efficiency, and advanced automation needed in today’s large enterprise data protection environments. The enterprise-class features of Sepaton products are summarized in Table 2 on the next page.
Table 2: DeltaStor Features Specifically Designed for Large Enterprises Enterprise Deduplication Requirement DeltaStor Features Allow high-performance backup, replication, and recovery
Industry-leading deterministic ingest rates and concurrent, multinode processing to meet backup/replication windows and restore SLAs.
Immediate restores Forward referencing enables immediate restore of the most commonly
needed data.
Management tools for optimization
Management reporting and dashboards to enable a single administrator
to ensure that petabytes of data are protected, deduplicated, and replicated efficiently. Detailed status and trend reporting pinpoints sources of
inefficiency, enabling unparalleled control and cost savings.
Reduce space, power
Single-system global deduplication of all data enables superior
deduplication efficiency and reduces data center space, power, and cooling requirements.
“Pay as you grow” grid scalability
Enterprise architecture. Add nodes – from one to eight as needed to
increase performance. Add disk shelves as needed to scale capacity in cost-saving increments.
Massive single-system performance and
capacity
Enterprise-grade scale and performance. Deploy as many as eight
processing nodes to achieve industry-leading performance of up to 43.2 TB/hour.
Fast, cost-effective replication
Bandwidth-optimized replication of large data volumes by transmitting only new data. Up to 97% bandwidth reduction.
Lower TCO and admin cost
Advanced automation simplifies IT management. Bring added
performance or storage online, configure devices to the optimal settings, and load balance without operator intervention.
Tape vaulting Forward referencing keeps the most recent backup in an un-deduplicated
form for fast, efficient tape vaulting.
Enterprise-grade, high-reliability design
99.999% data availability; RAID-6 based Hitachi Data Systems
enterprise-class storage; redundant control and data paths; internally mirrored drives; and real-time 24x7 platform monitoring, diagnostics, and automated alerts.