2018 International Conference on Modeling, Simulation and Analysis (ICMSA 2018) ISBN: 978-1-60595-544-5
A Key-Value Store Based Data Center Resource Scheduling System
Qiao SUN
1, Chun-guang ZHANG
1, Qiong WANG
2, Lei SUN
1, Lan-mei FU
1,
Xiao TONG
1, Yi-peng SU
3, Zhi-dan LIN
4and Wan-tao LIU
3,*1Beijing GuoDianTong Network Technology Co., Ltd., Beijing, 100070, China
2State Grid Gansu Information & Telecommunication Company, Lan Zhou, 730050, China
3Institute of Information Engineering, Chinese Academy of Sciences, Beijing, 100093, China
4Luoyang Institute of Information Technology Industries, 471000, China
*Corresponding author
Keywords: Key-Value store, Resource scheduling, Data center.
Abstract. Efficiently scheduling resources in large scale data center is a key problem that distributed resource management systems face. In the cloud computing environment, the quantity of resources expand and the size of users raises dramatically. It brought up following challenges such as accessing to vast amount of resource information, handling of highly concurrent user requests, tremendous pressure of the system brought up by the update of the mass resources and so on. Traditional resource management systems based on centralized or hierarchical structure have pool expansibility and can’t satisfy the new large scale applications. And existing distributed resource scheduling methods (such as P2P routing based and DHTs based resource scheduling methods) can’t process user requests with high concurrency rate and high-frequency resource updates well enough. We propose a resource schedule model based on Key-Value Store. The model solves the problem of storing mass resources and efficiently accessing resource information using Key-Value Store. Distributed resource scheduling method based on range-partition can locate the appropriate resources rapidly and also reduce the cost of resource updates by extended invalid push protocol. The evaluation on data from Planetlab shows that, compared to current, and to improve the scheduling efficiency.
Introduction
The emerging cloud computing technology, integrating various network resources to achieve the unified management and scheduling, provides multiple services in a scalable way as needed via the network, which involves issues such as massive resource information storage and effective concurrent reading/writing, high concurrency user resource request, and high frequency resource updating.
Traditional resource management systems, which are generally based on various network topological structures (centralized topology, hierarchical topology, P2P topology, etc.), are vulnerable to many problems during both high concurrency scheduling and high frequency updating of massive resources. For example, the failure to support massive resource access and high concurrency user resource request can be attributed to their poor resource management system scalability. When P2P topology is adopted to process the user resource request, the system will first match the attributes of user request with resource attributes, then obtain the candidate resource collection, and return to user the proper resource collection selected by the resource selector. However, matching and selecting operations can be inevitably long in the conditions with large resource scale and high user request concurrency level. Moreover, consistency problems will arise due to the massigve resource updating.
designed by its scalable invalid push protocol based on interval migration alleviates the pressure of resource updating. Furthermore, interval partition plans are optimized to solve the “heat” interval scheduling problem in interval partition-based resource scheduling algorithm and thus improveresource scheduling efficiency.
Related Works
The resource scheduling in distributed environment has been receiveing abundant attention, and much progress has been made in the past decades[1-4], such as the small-scale efficient centralized scheduling, the coverage technique and selective routing technique in P2P network, and the DHTs-based resource indexing and discovery techniques (DGRID).
The current resource scheduling method adopts different topological structures as required by the Internet application, which can be roughly classified into centralized structure, hierarchical structure, structured and distributed structure, and unstructured and distributed structure.
Condor [5] is a typical resource management system based on centralized structure, whose resource pool manager receives the ClassAds from the resource owner agent (RAs) and user agent (CAs), selects a “proper” resource according to matchmaker’s matching protocol, and then distributes such resource to the user for job running support. The poor scalability of Condor renders the system to suffer long scheduling latency that is significantly limited by the central server throughputas well as single point failures.
Elmroth [7] proposes a hierarchical resource scheduling method based on resource agent and job submission system, which collects the resource information in virtue of Grid Laboratory Uniform Environment (GLUE) engineering. The Information Server stores the resource information and submits it to the Index Server for index structure construction. When the user request reaches the resource scheduling server, the Information Finder first scans each index server successively to find proper resource index, and then return the detailed resource information found via Information Server to the user. The hierarchical structure, which is characterized by hierarchical processing of user’s resource request, can relieve the pressure of master server to some extent. However, global resource scheduling is made difficult due to the existence of site autonomy, and the invalidation of information service node will also make the resource separate from the scheduling system.
In P2P network, there are two resource scheduling modes, namely the routing transmission mode and the DHT method-based mode. In the routing transmission mode, each site receives the user request, and routes the user request to the neighbor node for resource finding until the user-requested resource is found. There are two routing modes for resource finding, namely the flooding routing mode [8] and the selective routing mode [9]. In the flooding routing mode, the research request is flooded to all neighbor nodes according to TTL [10] mechanism, which, however, is selective based on judgment criteria (random walk, learning mode, best neighbor node, etc) in the selective routing mode.
To deal with the network communication overhead that occur in the P2P routing-based resource scheduling method, it is critical and urgent to implement research on DHTs-based structured and distributed resource scheduling method. SWORD [11], the scalable resource scheduling service deployed on PlanetLab and supporting wide-area distributed system, can find a set of machines meeting the request of user-defined constraints in static and dynamic node environments, during which attribute tuples in the DHT storage system are used. The searching of attribute constraint
{A, op, value} is implemented by first projecting attribute A to corresponding DHT node, and then
finding the attribute meeting constraints and its corresponding resource according to the query interval. The structured and distributed structure can balance the system load well, but additional projecting overhead can also be caused. In addition, high updating frequency might result in a large overhead of maintainance resource information updating in DHTs.
frequency updating problem of dynamic resources in the distributed environment.
Key-Value Store-Based Resource Scheduling Model
This section mainly introduces the Key-Value Store-based resource scheduling system model, mainly including the system structure, data mode, and resource management and scheduling process. (More constraints can be defined to reduce the network overhead, such as the integration of multiple virtual machines on one physical machine and that of multiple physical machines in one cluster as possible.).
Structure of Key-Value Store-Based Resource Scheduling System
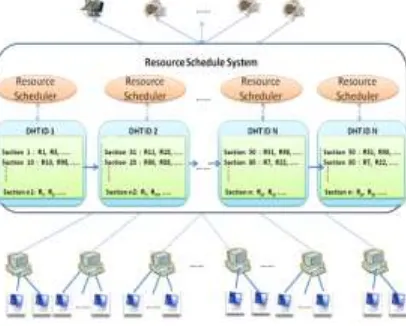
As shown in Figure 1, this structure includes three main entities, namely user, resource and resource scheduling system.
(1) User: the user submits resource request and releases the occupied resource to the resource management system.
(2) Resource scheduling system: the resource scheduling system mainly includes the Key-Value Store constituted by DHT nodes and the resource scheduler deployed on DHTs nodes.
[image:3.595.195.398.346.509.2](3) Monitor: the monitor is used to monitor the information of various resources and the statistical information of resource collection (physical node, cluster, data center, etc.), and to complete the resource scheduling and updating operation together with the resource scheduler.
Figure 1. Architecture of Key-Value Store-Based resource scheduling system.
Data Model
The data model is described in this section. (1) Resource description and storage
The model consists of four main components: virtual machine, physical node, cluster, and data center. Resource R of single virtual machine includes three main attributes, which are free CPU (represented by core number), free memory (GB) and free hard disk (GB), as well as three position attributes, namely the physical node, cluster and corresponding data center. It can be simply expressed as R={ [FCPU, FMemory, FDisk ], [DC, Cluster, PN] }, where FCPU, FMemory and FDisk represent free CPU (represented by core number), free memory (GB) and free hard disk (GB), respectively, while DC, Cluster and PN data center, cluster and physical node that R belongs to. The physical node contains several virtual machines, the cluster several physical nodes, and the data center several clusters.
IA=FA(VA) is a logical index of basic attribute A of resource R (where VA represents the value of
attribute A, fA is the mapping rule of attribute A). ICPU, IMEM and IDISK are logical index of ACPU,
AMEM, ADISK, respectively. The joint logical index of resource R can be computed as JRIR=F(ICPU,
IMEM, IDISK). In the model, the actual physical information of resources is stored in the monitor,
(2) Query format
Table 1 shows a sample of query. For the ease of description, intervals are used to represent the upper and lower limits of each attribute requested by the user. For example, the request in Table 1 is described as “request of a cluster that consists of four machines, and the core number of free CPU in each machine shall 2 to 4, with free memory no more than 2G and free hard disk of 100G to 200G”. The user can define the type (e.g. the virtual machine, physical node, cluster, or data center) of request resource in the request description, and the user can also define the constraint conditions of each attribute of the virtual machine resource. When multiple virtual machines are requsted, the system trys to integrate the virtual machine resource of the same physical node, cluster, or data center according to the statistic information of the physical node, cluster and data center, and then returns such resource to the user.
Table 1. Sample XML query.
(3) Resource update model
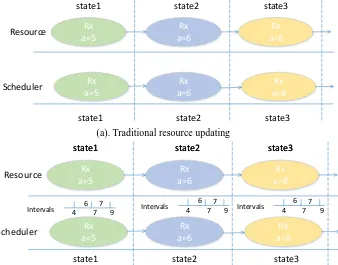
Traditional resource updating method requires to update the resource information frequently along with the dynamic change of resource attribute (see Figure 2 (a)). In this context, the resource update mode based on interval migration via extended invalid push protocol is proposed. For instance, updating is only required when the attribute value of resource exceeds the partitioned interval it belongs to (see Figure 2 (b)). In Figure 2, when resource Rx transits from status 1 to status 3, the value of attribute a changes twice, and traditional resource management system requires to change the value of attribute a twice. However, in extended invalid push protocol, the number of logical interval is only to be updated once, which will be more efficient when solving the updating problem of high frequency dynamic resources.
Rx a=5
Rx a=6
Rx a=8
Rx a=5
Rx a=6
Rx a=8
state1 state2 state3
Resource
Scheduler
state1 state2 state3
(a). Traditional resource updating
Rx a=5
Rx a=6
Rx a=8
Rx a=5
Rx a=6
Rx a=8
state1 state2 state3
Resource
Scheduler
state1 state2 state3
6
state1 state2 state3
7
4 7 9
Intervals
6 7
4 7 9
Intervals Intervals 4 6 77 9
[image:4.595.134.472.486.751.2](b). Resource updating in extended invalid push protocol
Resource Management and Scheduling Process
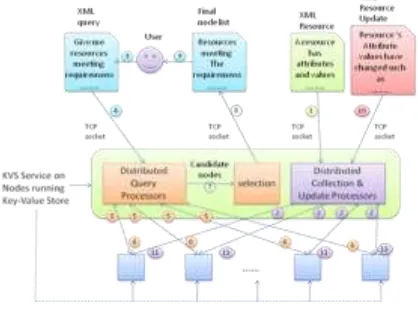
[image:5.595.194.403.138.293.2]The system structure chart and system data pattern of the Key-Value Store-Based resource scheduling model have been introduced in the previous part, and the specific resource management and scheduling process are as shown in Figure 3.
Figure 3. Schematic diagram of resource management and scheduling.
In the schematic diagram, Step 1 is to use the monitor to submit the collected resource information to the resource management system via TCP Socket. Step 2 is to establish the index for the resource using the Distributed Collection & Update Processors in the resource management system according to the above-mentioned resource storage rule, and then the index is saved and transmissed to the Key-Value Store. Step 3 is the submission of the resource request by the user to the resource management system after pre-processing via TCP Socket in Step 4. Then comes Step 5, which is to parse the user request through Distributed Query Processors, and to find the index of corresponding resource or resource collection in Key-Value Store according to the query rule. When the found resource collection exceeds the user requirement, the selection in Step 7 is used to select the resource required by the user, and then the resulted final node list is returned to the user via TCP Socket, as shown in Steps 8 and 9 (Figure 3). The index structure will be updated accordingly during resource scheduling completed by the monitor and the scheduler, and the resource will also be updated dynamically. Step 10 is the submission of the resource updating information to the resource management system via TCP Socket, after which Distributed Collection & Update Processors will receive the resource updating information uploaded by the monitor, and change the relevant information in Key-Value Store via Step 11.
Resource Scheduling Algorithm Based on Interval Partition
This section will introduce the resource scheduling algorithm based on interval partition and its optimized plan in details.
Hash-based Resource Interval Partition
For three basic attributes of resource (free CPU, free memory and free hard disk capacity), this study respectively uses Hash rule HashCPU(), HashMemory() and HashDisk() for logical mapping. When
the domain range of resource attribute value is known, the rule of logical mapping can be described as follows: attribute A (A is free CPU, free memory, or free hard disk capacity) is divided into N sections, and thus for any Aj, j∈[1,N-1], where j is an integer, Aj∈[Amin,Amax], Aj<Aj+1, A0=Amin,
AN=Amax; TA={ [Aj, Aj+1] | j∈[0,N-1]} serves as a differentiation of attribute A, while BA={Aj | j
∈ [0,N]} acts as the collection of division boundary of free memory.
For resource R = { <CPU, VCPU>, <Memory, VMem>, <Disk, VDisk> }, logical mapping is applied
CPU CPU
Memory Mem
Disk Disk
Hash (V ) i,i [1, M];
Hash (V ) j, j [1, N];
Hash (V ) k, k [1, P];
Thus, the partition interval i _ j _ k index corresponding to the resource can be obtained, and it is
found that different partition interval indexes can be acquired for different resources after mapping of interval partition.
When Q = { <CPU, OCPU, QVCPU>, <Memory, OMem, QVMem>, <Disk, ODisk, QVDisk> } is
queried, the same Hash mapping rule will be adopted
CPU CPU
Memory Mem
Disk Disk
Hash (QV ) i,i [1, M]; Hash (QV ) j, j [1, N];
Hash (QV ) k, k [1, P];
When i OCPU i '& j OMem j' & k ODisk k ' is satisfied, query Q will match with
resource R successfully.
Scheduling Algorithm Based on Interval Partition
In 2.3, the basic format of resource query is introduced. In the conditions with multiple virtual machines as requested by the user as well as different attribute requirements for each virtual machine, the request can be divided into multiple sub-requests as shown in Table 1, and the constraint rule on resource attribute in the sub-request is the same. In this context, the basic idea of scheduling algorithm based on interval partition can be described as follows:
(1) Various attributes and their constraint conditions in the resource request query are first analyzed, followed by application of interval mapping on the constraint upper and lower limits of various attributes according to corresponding rules. Then, indexes of corresponding upper and lower limit intervals under different attribute constraint conditions can be obtained, as shown in Lines 1-4 in the Algorithm 1.
(2) The type of user request is judged, as shown in Line 5 in Algorithm 1. The user can request single virtual machine, physical node, cluster, or data center; for different request types, the scheduler can find the resource index meeting the user demand in different index modules of Key-Value Store.
(3) Based on the results obtained in Steps (1) and (2), it is easy to rapidly confirm the joint interval index set JRIS (Line 6, Algorithm 1) corresponding to the resource required by the user, and select proper joint interval index JRI (Line 7, Algorithm 1) from JRIS according to certain rule.
(4) The resource list corresponding to JRI index is then obtained from Key-Value Store, from which a random ResourceID (Line 8 & 9, Algorithm 1) is selected.
(5) Then comes the inding of the MonitorID of management ResourceID, associated with request sending to the monitor and subsequent acquirement of the actual information of physical resource. The monitor will integrate the user-demanded virtual machine resource set according to the query content, and return it to the scheduler (See Lines 10 and 11 in Algorithm 1).
Algorithm 1: Range-Based Schedule Algorithm Input: query, KVS:Key-Value Store, XMLA:XML Analyzer
1 Attr_Cons_Map XMLA .Get_Attr_and_Cons (query) 2 foreach Attribute A ∈ Attr_Cons_Map.KeySet() do
3 [bottom, top] Hash( Attr.type,
Attr_Cons_Map.get(A) ) 4 ConstrainsMap.put(Attr, [bottom, top])
5 SchedulerType XMLA .Get_SchedulerRule(query) 6 JRIS GetIndexSet(ConstrainsMap, SchedulerType) 7 JRI SelectRightJRI(JRIS)
8 ListOfResourceID KVS.get(JRI)
9 ResourceID ListOfResourceID.RandomSelect() 10 MonitorID KVS.getMonitor(ResourceID)
11 ResourceSet Monitor( MonitorID).Integrate(query) 12 UpdateResource(ResourceSet)
13 QueryRecord.put(query, ResourceSet)
In Step 7 of algorithm 1, proper joint interval index is selected from the joint interval index set, and the problem during this process is the transferring of the user request to other intervals to avoid “heat” interval scheduling in the concurrent scheduling when the user requests gather in certain interval over a period of time. This study adopts the interval selecting method that is similar to LFU
herein, and provides the defined access heat
N RAF
T
at first, where N stands for the user request number during T, and T stands for the time period (set constant). The interval selectivity factor is defined as
T
RAF M
, where RAF stands for the access heat of interval, and MT for the quantity of
resources within time period T. Thus, for any interval S JointRangeIndexSet, and
s S
s S S
T T
RAF N
M T * M
becomes the selectivity weight of interval S. Assuming that s is
infinite when S T
M =0, the formula of interval selectivity can be written as:
s i
Select _ Range {S | min( ) ,iJoint RangeInd xe Set}
Algorithm 2: SelectRightJRI Algorithm
Input: JRIS, KVS:Key-Value Store, T: time unit
1 deta∞, candidateJRI null; 2 foreach JRI ∈ JRIS do
3 ListOfResourceID KVS.get(JRI) 4 size ListOfResourceID.size() 5 count KVS.getAccessCount(JRI) 6 cur_deta count/(T*size)
7 if curdeta < deta then 8 deta curdeta 9 candidateJRI JRI
10 KVS.getAccessCount(candidateJRI )++ 11 return candidateJRI
Experiment Results
Experiment Settings
The Key-Value Store-Based Resource Management and Scheduling System proposed in this paper is deployed and operated in the distributed cluster environment, and such cluster consists of 20 machines, with 1 GHz basic frequency, 8-core, and 8G memory. During system deployment, 8 machines are used to deploy Key-Value Store and the resource scheduling service, 8 machines to simulate the monitor, and additional 4 machines to simulate the client and operation control terminal. The experiment measurements mainly include:
(1) Query Process Throughput (QPT for short),
Query N QPT
T
, where T represents the unit time,
and NQuery represents the total processed query amount within T.
(2) Update Throughput (UT for short), NUpdate UT
T
, where T represents the unit time, and NUpdate
represents the total processed resource updating amount within T.
(3) Scheduling latency: the scheduling latency reflects the time latency of system required for processing the user query request, including the queue-up time of user request, schedule processing time and result returning time.
In this paper, the historically recorded data of the open global test platform PlanetLab1 is used to simulate the massive virtual machine resources and user query requests. Currently, the PlanetLab network consists of more than 1,000 nodes distributed globally, and CoMon2 can be used to monitor node information of PlanetLab. Three kinds of main information are selected from the node information monitored by CoMon, namely the number of CPU cores, available hard disk (GB), and available memory (GB). 3-month node record information of PlanetLab is collected from November, 2010 to January, 2011 to simulate the resource generation information and resource updating information.
Experiment Results and Analysis
nodes used to store the resource information, one of which serves as the center server, and there are another 8 nodes to simulate dynamic resource information monitoring, and all resource query requests and resource updating will be submitted to the center server for processing. Then, experimental tests are tested on each performance factor of system, and results are analyzed, as elaborated in the following part.
Query Throughput
Given that the throughput of the Key-Value Store-Based Resource Management and Scheduling System depends on the number of DHT nodes as well as the scale and update frequency of resource, and that the throughput of the traditional centralized resource scheduling methods also depends on the scale and update frequency of resource, three experiments are performed to test the performance of the Key-Value Store-Based Resource Management and Scheduling System, and to verify its advantages compared to the traditional centralized resource scheduling system.
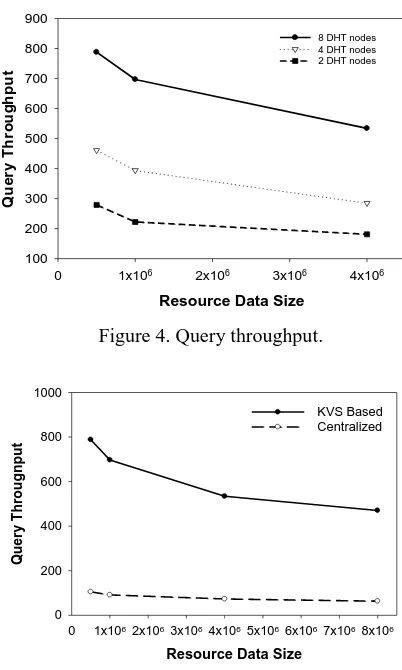
The first experiment mainly studies the relationship between the throughput of the Key-Value Store-Based Resource Management and Scheduling System and the number of DHT nodes (8, 4 and 2), and also investigates the influence of various resource scales (500,000, 1 million and 4 million) on the throughput of the scheduling system. It can be seen from Figure 4 that: (1) with the same resource scale and at the same resource update frequency, the query throughput increases with the number of DHT nodes which constitutes the Key-Value Store, but not linearly; (2) the query throughput decreases while the resource scale increases.
Resource Data Size
0 1x106 2x106 3x106 4x106
Q
u
e
ry
T
h
ro
u
g
h
p
u
t
100 200 300 400 500 600 700 800 900
8 DHT nodes 4 DHT nodes 2 DHT nodes
[image:9.595.192.393.354.689.2]
Figure 4. Query throughput.
Resource Data Size
0 1x1062x1063x1064x1065x1066x1067x1068x106
Query
T
hrou
gn
pu
t
0 200 400 600 800 1000
KVS Based Centralized
Figure 5. Comparison between distributed and centralized resource scheduling methods.
[image:9.595.193.397.360.512.2]The third experiment explores the influence of resource update frequency on the system's query throughput. In this experiment, 8-node Key-Value Store-Based Resource Management and Scheduling System is used, with referrence to the simulation by the centralized resource scheduling system (using 8 nodes to store the resource information). During the experiment, 4 million resources, 100,000 resource update messages and 10,000 query requests, are respectively used to verify the influence of different frequencies (20 ms, 15 ms, 10 ms) of resource updating on the system query throughput. The results are shown in Figure 6, which indicate that throughputs of both systems increase with the decrease of the resource update frequency. At the same time, the influence of resource update frequency on the efficiency of the centralized resource scheduling system is more significant. When changing the update interval from 20 ms to 10 ms, the query throughput decreases by 31.5%, while the query throughput of the Key-Value Store-Based Resource Management and Scheduling System only decreases by 19.1%.
Update Throughput
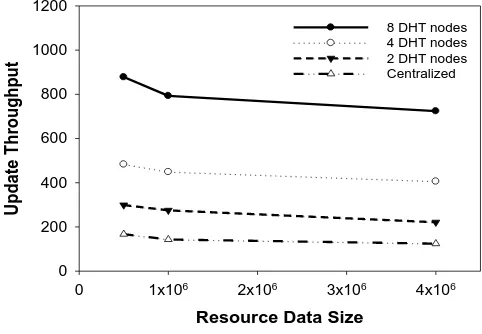
The update throughput reflects the system’s capability of processing the resource updating. This study mainly studies the relationship between the update throughput and the resource scales. During the experiment, resource update throughputs in 500,000, 1 million and 4 million resource scales are respectively tested. Moreover, update throughputs of 8-node, 4-node and 2-node Key-Value Store-Based Resource Management and Scheduling System are respectively analyzed for different resource scales. In addition, the centralized scheduling mechanism is simulated to study the update throughput of the centralized resource scheduling method, as shown in Figure 8.
Update Interval(ms)
10 15 20
Qu
ery
T
h
ro
u
g
n
p
u
t
0 100 200 300 400 500 600
[image:10.595.184.411.375.535.2]KVS Based Centralized
Figure 6. The influence of resource update frequency on the system throughput.
Resource Data Size
0 1x106 2x106 3x106 4x106
Upd
ate
T
hrou
gh
pu
t
0 200 400 600 800 1000 1200
8 DHT nodes 4 DHT nodes 2 DHT nodes Centralized
Figure 7. Update throughput.
[image:10.595.172.413.578.745.2]expansibility. The experiment results indicate that the update throughput of the Key-Value Store-Based resource scheduling method depends on the number of DHT nodes which constitute the Key-Value Store. The larger number of DHT nodes contributes to the larger update throughput of the system.
Latency(ms)
0 500 1000 1500 2000
Percent (% ) 0 10 20 30 40 50 60 70 80 90 100
8 DHT nodes 4 DHT nodes 2 DHT nodes Centralized
L a t e n c y ( m s )
0 500 1000 1500 2000
Percent (% ) 0 10 20 30 40 50 60 70 80 90 100
2 DHT nodes Cenralized 4 DHT nodes 8 DHT nodes
L a t e n c y ( m s )
0 500 1000 1500 2000
Per cen t( % ) 0 10 20 30 40 50 60 70 80 90 100 centralized 8 DHT nodes 2 DHT nodes 4 DHT nodes
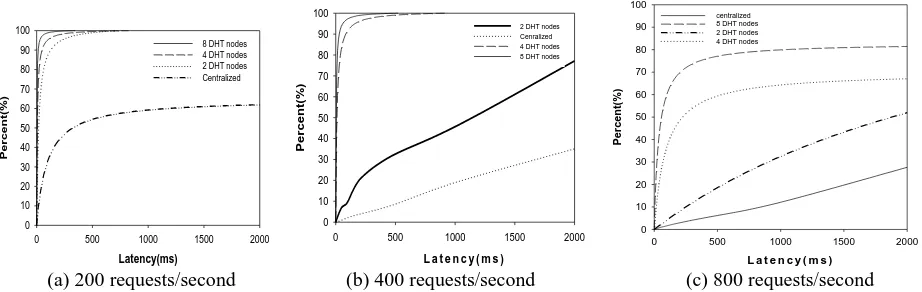
[image:11.595.68.529.137.283.2](a) 200 requests/second (b) 400 requests/second (c) 800 requests/second
Figure 8. The influence of different query request frequencies on the scheduling latency.
Scheduling Latency
The resource scheduling latency is directly related to the system’s resource scheduling performance. In case of high concurrency user requests, when the system’s query throughput is small, the user request will be waiting in the queue, and the latency from submitting request to obtaining results will be very long. The number of resources is set to 1 million in this experiment, and the number of user queries is 10,000. The user queries are divided into three groups for tests based on the frequency of 200 queries/second, 400 queries/second and 800 queries/second. Figures 8 (a), (b) and (c) respectively display the latencies of resource scheduling at the frequency of 200 queries/second, 400 queries/second and 800 queries/second, which suggest that the average scheduling latency decreases with the increase of the number of nodes which constitute the Key-Value Store. In addition, the system's scheduling latency increases with the increasing of user request frequency, which can be probably due to the fact that with a certain system throughput, the user's request will be waiting for processing in the queue if the user request frequency exceeds the system throughput, which leads to increasing scheduling latency. The results also indicate that the Key-Value Store-Based resource scheduling method is much better than the centralized resource scheduling method.
Conclusion
latency. In addition, after optimizing the resource interval partition, the system's query throughput increases by about 10%, and the average query latency improves by about 30%.
The Key-Value Store-Based resource scheduling method presented herein is to be further improved. It has been found through monitoring in the experiment that the maximum memory occupancy rate of DHT nodes is 30%, while the maximum CPU occupancy rate is 20%. Therefore, taking full advantage of DHT nodes can further improve the system's throughput. The current interval partition optimization method is static, and further attention will be paid to dynamically adjust the interval partition rules in the resource scheduling process so as to improve the resource scheduling performance.
Acknowledgement
This research was financially supported by Science and Technology Project of the State Grid Corporation of China (SGGSXT00YJJS1600102) and the State Grid Information & Telecommunication Group Co., Ltd. (SGITG0000KXJS2016040).
Reference
[1] A. Bharambe, M. Agrawal, and S. Seshan. Mercury: Supporting Scalable Multi-Attribute Range Queries. Technical report, Carnegie Mellon University, January 2004. Revised version to appear in ACM SIGCOMM 2004.
[2] A. Iamnitchi and I. Foster. On Fully Decentralized Resource Discovery in Grid Environments. In Proceedings of the International Workshop on Grid Computing, November 2001.
[3] K. Czajkowski, S. Fitzgerald, I. Foster, and C. Kesselman. Grid information services for distributed resource sharing, 2001.
[4] R. van Renesse, K. Birman, and W. Vogels. Astrolabe: A Robust and Scalable Technology for Distributed System Monitoring, Management, and Data Mining. 21(2):164-206, May 2003.
[5] M. J. Litzkow and M. Livny. Experience with the Condor Distributed Batch System. IEEE Workshop on Experimental Distributed Systems, 1990.
[6] Kaur, D. and J. Sengupta ‘Resource Discovery in Web-Services Based Grids’, in Proceedings of World Academy of Science, Engineering and Technology 2007, p. 284-288.
[7] Elmroth, E. and J. Tordsson (2005) ‘An interoperable, standards-based grid resource broker and job submission service’, in First International Conference on e-Science and Grid Computing, p.212-220.
[8] Gnutella. http://www.gnutella.com.
[9] A. Iamnitchi, I. Foster, and D. C. Nurmi. A peer-to-peer approach to resource discovery in grid environments. In IEEE HPDC, 2002.
[10] Wang C., Li B: Peer-to-peer overlay networks: A suvey.
http://comp.uark.edu/cgwang/Papers/TR-P2P.pdf,2003