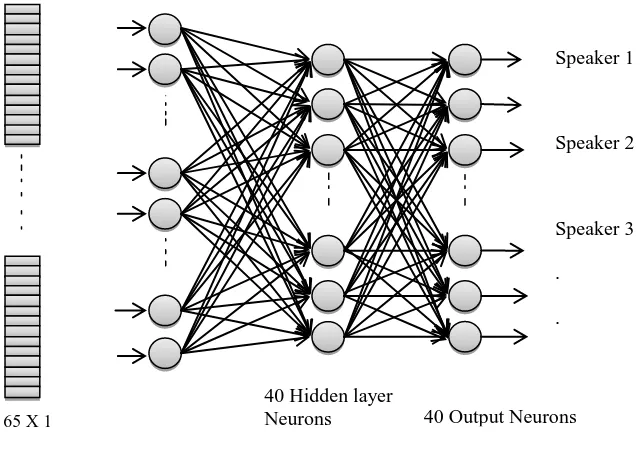
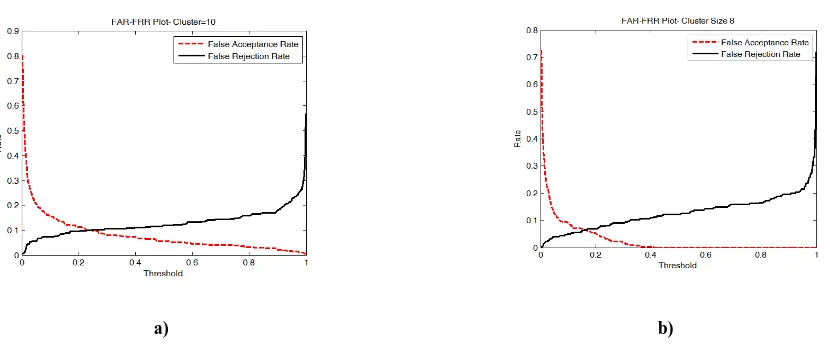
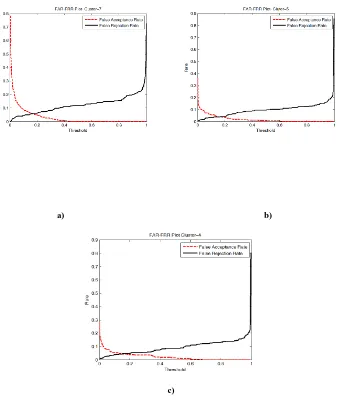
Text Dependent Speaker Recognition using MFCC features and BPANN
Full text
Figure
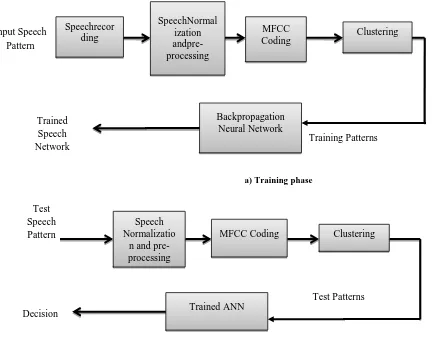
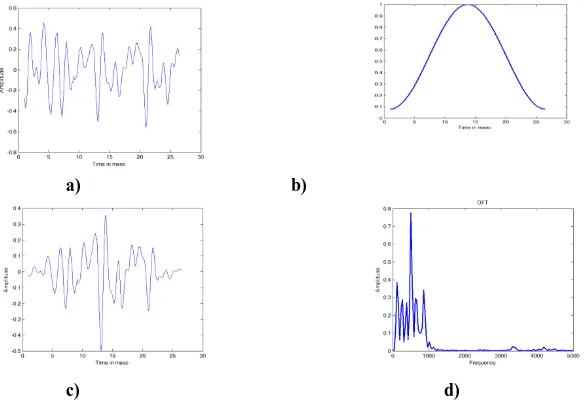
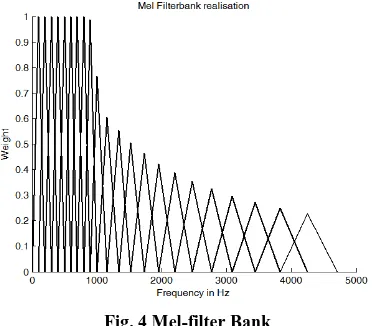
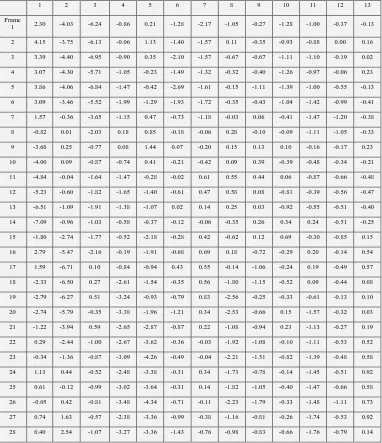
Related documents
Figure 4: Continuous Ranked Probability Skill Score versus lead time for the TIGGE-4 multi-model (solid line), for the contributing single-models itself (dotted
[34], the power resource allocation in the downlink of a CRN-aided IoT system is modeled as a constrained optimization problem, and then a solution method is accordingly presented by
• Coordinate evaluation of education programs • Participate in and lead research committees • Provide education on evidence-based practice. and
Our model constructs a piecewise constant representation (effectively a histogram) of the distribution of galaxy types and redshifts, the parameters of which are efficiently
Therefore, we model a P&I Club as an impulse control system in the sense that the total reserve of the Club is “reset” by an impulse premium control, so that insurance
– Example: flaw 1 gives external attacker access to unprivileged account on system; second flaw allows any user on that system to gain full privileges ⇒ any external attacker
3 – at the retail level, the quantity of milk delivered by major retailers. The hypothesis is that the degree of concentration and some agreements among players in the dairy
