The emergence of number and syntax units in LSTM language models
Full text
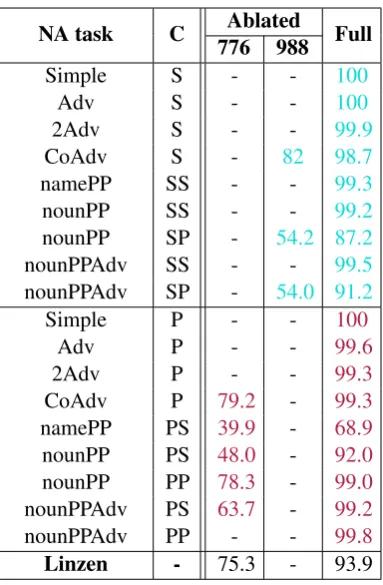
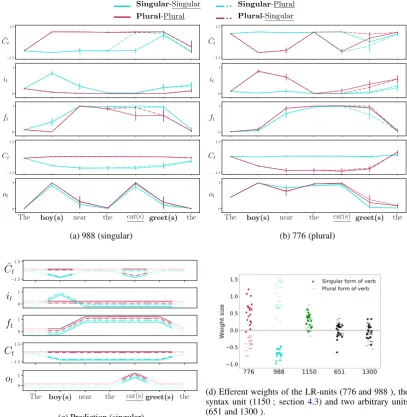
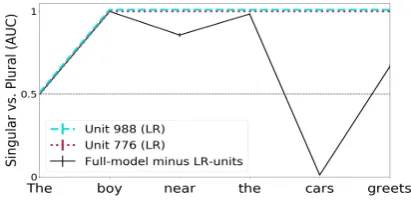
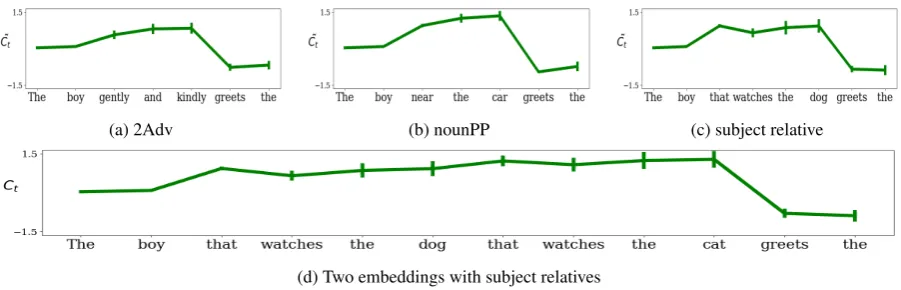
Figure
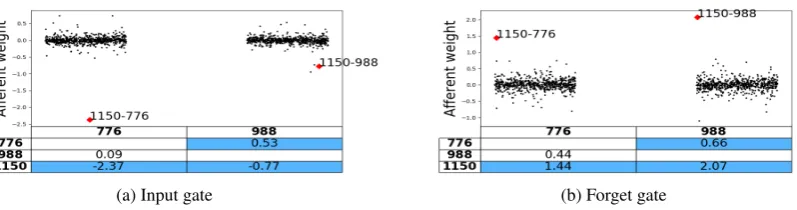
Related documents
In earlier days classical inventory model like Harris [1] assumes that the depletion of inventory is due to a constant demand rate. But subsequently, it was noticed that depletion
National Conference on Technical Vocational Education, Training and Skills Development: A Roadmap for Empowerment (Dec. 2008): Ministry of Human Resource Development, Department
The primary objective of this study was to evaluate whether the implementation of a ventilator care bundle in the PICU could simultaneously reduce the incidence of VAP and VAT
But that is Marx’s exact point in discussing the lower phase of communism: “Right can never be higher than the economic structure of society and its cultural development which
19% serve a county. Fourteen per cent of the centers provide service for adjoining states in addition to the states in which they are located; usually these adjoining states have
The objective of this study was to develop Fourier transform infrared (FTIR) spectroscopy in combination with multivariate calibration of partial least square (PLS) and
Standardization of herbal raw drugs include passport data of raw plant drugs, botanical authentification, microscopic & molecular examination, identification of
Maximum weight of the palletized load : 500kg. The heaviest palletized load always must be at the lower level of the pile. See Appendix 2 for palletizing of standard GALIA
