Learning Indonesian Chinese Lexicon with Bilingual Word Embedding Models and Monolingual Signals
6
0
0
Full text
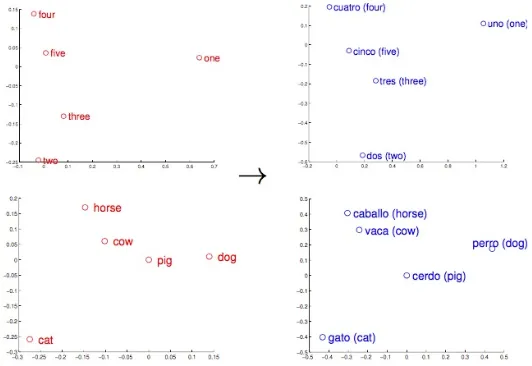
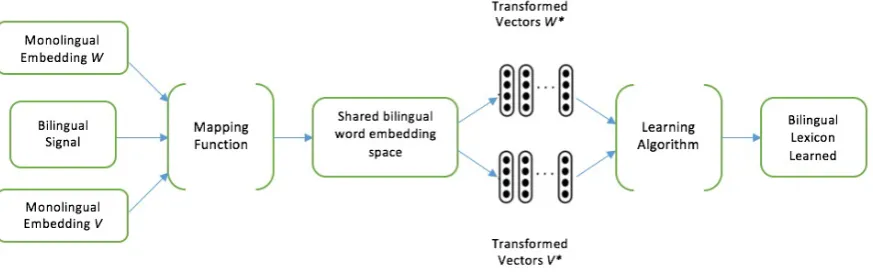
Figure
Related documents