A New Video Coding Approach Based on
Object-Extraction
Usama S. Mohammed
and Walaa M. Abd-Elhafiez
*Department of Electrical Engineering, Assiut University, Assiut 71516, Egypt, **Mathematical department,faculty of science,
Sohag University, Sohag, Egypt.
Abstract— This paper describes efficient object-based video coding schemes suitable for content-based multimedia streaming systems. Anew two video coding approaches are presented to study the effect of the object based motion estimation in video coding and the effect of the object based video coding on the compression quality, respectively. The first approach is based on a new motion estimation technique; based on arbitrary shaped-regions. The second approach is based on the video object extraction and a new motion estimation technique based on arbitrary shaped-regions. The proposed methods are applied on videos containing a variety of scenarios such as multiple objects undergoing occlusion, splitting, merging, entering and exiting, as well as a changing background. The simulation results are introduced in a comparison form with some of recent video coding method. For all the videos, the proposed approach displays higher Peak S ignal to Noise Ratio (PS NR) compared to other methods, and provides comparable or better compression than some of recent video coding techniques.
Index Term— Video coding; image segmentation; object extraction; MPEG-4; video object planes (VOPs); motion vectors estimation
I. INTRODUCTION
Video compression is an area of research that has received considerable attention over the last few decades. Various compression techniques have been used to store, transmit, and manipulate video data efficiently. Video compression is commonly achieved by removing redundancies in the frequency, spatial and temporal domains. Some video coding techniques, such as predictive coding, transform coding and vector quantization, treat the image/video as random signals and exploit their stochastic properties to achieve compression [4]. In general, video compression algorithms are at the heart of a digital media explosion, playing an important role in internet and multimedia applications, digital appliances, and handheld devices. Multimedia appliances are ubiquitous in every day life, encompassed by standards su ch as DVD [1], HDTV [2], and satellite broadcasting [3]. With even budget cell phones capable of playing and recording videos, these appliances continue to increase in pervasiveness. Virtually all video playback devices rely on compression techniques to minimize storage, transmission bandwidth, and overall cost. A. Hakeem, K. Shafique, and M. Shah [5] presented object -based video coding frame-work for videos obtained from a static camera. The system detects and tracks objects in the scene and learns the appearance model of each object online using incremental principal component analysis (IPCA). Each object is then coded using the coefficients of the most
significant principal components of its learned appearance space. However, this technique will be failed if the appearance space of an object cannot be represented by a small number of
principal components. Moreover, due to the smoothness in the transition between different poses and views of object in the video sequence, this technique provides accurate res ults. The object-based coding has the potential to provide a more accurate video representation at very low bit rates, and allows content-based functionalities such as object manipulation, indexing and retrieval. In the MPEG-4 standard [6], video coding is handled by the object unit, i.e. the video object plane (VOP). VOP represents one snap shot of an object in video. For each VOP, the motion, texture, and shape information is coded in separate bit streams. This allows separate modification and manipulation of each VOP, and supports the content-based functionality. For object-based video coding via MPEG-4, it is essential to have the video object in advance. However, most of the existing video clips are frame-based. Thus, video segmentation, which aims at the exact separation of moving objects from the background, becomes the foundation of content-based video coding. Even though the image/video segmentation problem has been studied for more than thirty years, it is still considered one of the most challenging image processing tasks, and demands creative solutions for major breakthrough. Recently, Yu Liu et.al [7] extends the lifting-based motion threading technique from the frame-based coding to the object-based coding, attracted by the unique advantages of the object-based coding. The boundary effects, which exist in spatial and temporal wavelet transforms due to the manner of object-based coding, are well suppressed by 3D shape adaptive discrete wavelet transform (3D SA-DWT) via the lifting implementation in a unified framework. Based on the proposed object-based motion threading technique, a 3D object-based scalable wavelet video coder is developed.
98410-0303 IJVIP NS-IJENS © December 2009 IJENS
I J E N S encoder and decoder by image segmentation. Segmented
region updating, which can obtain appropriate regions for motion compensated prediction, and a new bit assignment algorithm in prediction error coding are also developed.
II. OVERVIEW OF THE WORK
Even though many object-based video coding techniques has been proposed as reviewed before, we feel that the motion estimation technique in conjunction with the moving object extraction have not been exploited in reducing the bit rate while maintaining a reasonable quality. Our goal is to develop a fast objects extraction algorithms which exploit the spatio-temporal correlations in the video sequence in computationally simple way. Then, new video coding technique based on the extracted-object is provided. Instead of using the block matching motion estimation process, only the moving objects in the video sequence are used to estimate the motion vector. There are major differences between our work and the earlier effort, in the segmentation scheme employed and the motion estimation model. We use region grow based segmentation scheme, which appears to produce consistent segmentation results over a variety of natural images. Since it combines luminance and texture information for image segmentation, it is well suited to segment real world images. For motion estimation, we choose an affine model, and use hierarchical region-matching for accurate affine parameter estimation. This paper is organized as follows. Moving object segmentation is proposed in Section III. Section IV focuses on a new motion estimation technique based on arbitrary shaped -regions, followed by simulation results of this technique. In Section V, the proposed method is applied on videos containing a variety of scenarios such as multiple objects undergoing occlusion, splitting, merging, entering and exiting, as well as a changing background. Finally, concluding remarks are given in Section VI.
III. MOVING OBJECT EXTRACTION
The video object plane (VOP) generation becomes an essential task since MPEG-4 introduced its coding scheme that based on VOP. This leads to efficient coding with different bit rate for different VOP, hence different rate for displaying of different object.The process of segmentation is outside the scope of MPEG-4 standard. The automatic VOP generation can be classified into three dominant methods that proposed in the previous literatures: (1) change detection mask is used as temporal information; (2) the motion field is used as temporal information, (3) Combine the change detection mask with the motion field. The main drawback of the former is that only the occlusion zone associated with moving objects marked as changed instead of the whole moving object. Neri et. al. [8] used the higher order statistics (HOS) (4th order moments) for object segmentation by combining the HOS based motion information and HOS based change detection. Motion information is estimated using the frame differences. The displacement of pixel at site (x,y) is estimated by minimizing the sum of the absolute difference of the 4th order moment within block of size MxM centered on (x,y). The optimal
displacement extends to horizontal, vertical and diagonal neighboring sites. If the displacement is null the pixel is classified as stationary pixel, and the next one is examined. Otherwise, the algorithm repeats the search, sliding at each iteration of the frame difference pair (i.e. decreasing the lag k). If a displacement appears, the pixel is classified as moving pixel, and the process is applied to the next pixel. Pixels presenting null displacement are classified as background, even if their 4th order moment is greater than the threshold. The first drawback of this algorithm is that it will fail with the smoothing regions even if it is a fast motion because it does not used the spatial information. The second drawback is the estimated boundary of the moving objects is inaccurate. Yang et al. [9] used the classified motion vector (MV) in edge, foreground, background and noise MVs, to perform moving object segmentation. The labeling result is linked with an image consisting of the DC part of the DCT coefficients which are obtained from partly decoded I frames. Finally, an extra decoding step is performed on the regions around the edges of the estimated objects and edge information in the pixel domain is extracted for refinement. The execution speed of this method highly depends on the number of edges in the present image. Several possible combinations of the thresholds can result in different classifications, as such influencing the segmentation accuracy. Liu et al. [10] created a normalized and median filtered motion vector (MV) to perform moving object segmentation. Subsequently, a complex binary partition tree filtering is used to segment the MV field. The complexity of the partition tree increases drastically with a noisy MV field. Recently, Long et al. [11] created a MV field by accumulation over time and used a median filter to clean the field. Additionally, they created a feature vector based on the DCT coefficients to refine the MV field even further.
IV. THE PROPOSED METHOD a) Segmentation and moving region selection
Fast and robust video segmentation techniques are proposed in this section as following:
a-a) Objects extraction algorithm using rainfalling watershed transform approach
a-b) Objects extraction algorithm used fuzzy edge detection approach
In this method, a new algorithm with the objective to improve the perceptual quality of the extracted objects is proposed. This technique is motivated by the observation that the A fuzzy classifieris a system that accepts inputs that are either: (i) feature vectors; or (ii) vectors of fuzzy truths for the features to belong to various fuzzy set membership functions (FSMFs). It outputs fuzzy truths for the memberships of the input vector in the various classes. The class assigned to an input feature vector is the one with the maximum fuzzy truth given by the FSMFs. We usually require the maximum to exceed the second greatest fuzzy truth by a certain amount to yield a unique class membership (otherwise we can only say that the input feature vector belongs to each class with a particular fuzzy truth). The fuzzy edge detector is used to extract the edges in the video sequences [23]. It uses an extended Epanechnikov function as a fuzzy set membership function (FSMF) for each class where the class assigned to each pixel is the one with the greatest fuzzy truth of membership. This classification is done first, after which a competition is run as a second step to thin the edges. Like the Canny edge detector, the edge sensitivity of our competitive fuzzy edge detector (CFED) can be set from low to high by the user.
a-c) Objects extraction algorithm used region grow approach We proposed region grow algorithm with the objective to improve the perceptual quality of the extracted objects spatially in the presence of noise. The new algorithm is motivated by the observation that the region growing approach has received a considerable attention in the computer vision segment of the artificial intelligence community.
With this approach, it begins by dividing an image into many tiny regions. These initial regions may be small neighborhoods or even single pixels. In each region, suitable defined properties that reflect membership in an object are computed. The properties that distinguish the pixels inside the different objects might include average gray level, texture, or color information. Thus, the first step assigns to each region a set of parameters whose values reflect the object to which they belong. Next, all boundaries between regions are examined. A measure of boundary strength is computed utilizing the difference of the averaged properties of the adjacent regions. A given boundary is strong if the properties differ significantly on either side that boundary, and it is weak if they do not. Strong boundaries are allowed to stand, while weak boundaries are dissolved and the adjacent regions are merged. The process is iterated by alternately re-computing the object membership properties for the enlarged regions and then dissolving weak boundaries. The region-merging process is continued until a point is reached where no boun daries are weak enough to be dissolved. Then image segmentation is completed. Monitoring this procedure gives us an impression of regions in the interior of object growing until their boundaries correspond with the edges of the object.
The algorithm of object extraction can be summarized in the following steps:
1- Automatic background estimation background estimation can be expressed by the differentiation of the approximation of the first N frames in the second layer in the wavelet domain. The differentiation is performed by subtracting the current frame from each of the other frames and threshold T1 is used to generate an initial mask for each subtraction. This operation can be written as follows: otherwise 0 l k T1 j) (i, x j) (i, x if 1 j) (i,
mask_df k l
k
(1)
The results are averaged for each pixel over these initial masks and a certain threshold T2 is used to generate the second mask; hence we can obtain a rough still background. otherwise 0 T2 j)) sk_df(i, average(ma if 1 j)
mask_bg(i, (2)
where mask_dfk(i,j) is the mask resulting from the
difference between ith frame and (i+k)th frame at index (i,j) and mask_bg(i,j) is the mask that representing the binary values 0 for background and 1 for foreground. Note that, this background must be scaled.
2- Background subtraction the background estimated in the previous step is used to extract the object by subtracting the background from the current frame and threshold the absolute of the difference with threshold T3 to get the mask no. 1 as follows:
otherwise 0 3 T ) j , i ( f ) i , i ( bg 1 ) j , i ( 1 _
mask (3)
where mask_1(i,j) is the first mask for extracting the object, it results from the current frame f(i,j) and the estimated background bg(i,j).
3- Motion information extraction using one from the above methods (rainfalling watershed, region grow or fuzzy) for the consequent frame to get the mask no.2.
4- Combine the two masks using a simple logic function to combine the two masks and get the final mask.
5- Then morphological filter is added with size (5×5).
It is clear that, this object-extraction algorithm depends mainly on the threshold values. The threshold values in this algorithm are automatically obtained using the maximum cross -entropy methods [12]. This technique can be described as follows : assume that the foreground and background probability mass function (pmf) is expressed as pf(g), 0≤ g ≤T, and pb(g), T+1≤
g ≤G, respectively where G is the maximum gray level, T is the threshold. The foreground and background area probabilities are calculated as:
T 0 g ff(T) P p(g)
P ,
G 1 T g b
b(T) P p(g)
P (4)
Then, the Shannon entropy parametrically depends upon the threshold T for the foreground and the background is formulated as:
T 0 g f ff(T) P(g)logP(g)
H , H (T) P(g)logPb(g)
G 1 T g b b
(5)
The sum of these two entropy can be expressed by H(T)=Hf(T)+Hb(T).
98410-0303 IJVIP NS-IJENS © December 2009 IJENS
I J E N S entropy be maximum, which can be formulated by: Topt=arg
max [Hf(T)+Hb(T)].
b) Region-based coding approach
In proposed method, we explored modification of the quantized video sequence based on pre-processing (object extraction). The modification will be done after the quantization step. The video sequence is subdivided into a block of pixels and then these blocks is classified into edge and non-edge blocks. For each block we shall keep a certain number of NxN blocks in the top left hand corner and multiplied the rest of our DCT coefficients with 0. This would simplify the coding process and reduce the bit-rate, but the quality of the compressed frame will be reduced. This ―mask‖ matrix determined what dimension of the upper left -hand corner of quantized DCT coefficients would be kept and the rest of the coefficients multiplied by 0.
In this work, the video coding approach is presented to study the effect of the object based video coding and the object based motion estimation in video coding on the bit-rate and the compression quality. In the proposed method, the non-edge blocks (insignificant regions) are compressed using the DC coefficient only and all significant coefficients are used for the edge blocks (significant regions). The object can then be encoded and transmitted with better quality than the rest of the video.
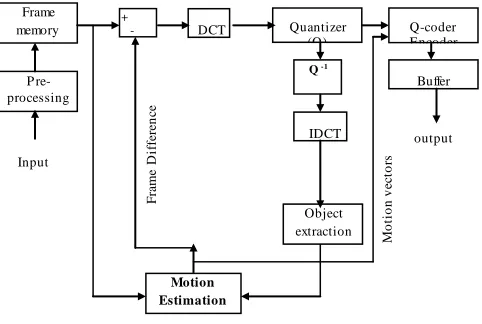
Fig. 1 and 2 show a block diagram of the proposed methods encoder. The main blocks in these diagrams are the DCT transformation, DCT coefficients quantization, motion estimation, Object extraction, and the Q-coder. These stages are all lossless operations except quantization, which is the source of error in the reconstructed frames.
Fig. 1. Block diagram of the object-based motion field for video coding encoder.
c) Anew Motion estimation technique based on arbitrary shaped-regions
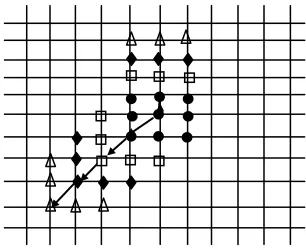
The Block-Matching Motion Estimation algorithm is attractive from the point of view of bit rate and reduction of the operation per second. However; like other block based algorithms it has the blocking artifacts problem, which is a result of error assumption of the constant motion vector within blocks. We aim to overcome the drawback in the block based motion estimation algorithms and increase the reliability of the motion vector in the same time. This can be performed by choosing the shape of the block arbitrarily depending on the moving regions in the current frame which can be provided by spatio-temporal region growth method. We shall introduce this new algorithm under the name of arbitrary shaped -region algorithm (ASRA). The proposed algorithm is compared with some of the well known block matching algorithms. Not only the PSNR is increased but also the bit rate will be reduced, since all the background regions will have (0,0) motion vectors. The segmentation information is not transmitted to the receiver since all pixels in the non-moving regions will be transmitted with zero motion vectors. The proposed motion estimation method is based on a center biased search, moving objects extraction, and the extracted moving -object. The extracted moving-object in Section IV will be used in the moving segment matching process. The center biased search algorithm is performed in four steps, and is applied only on the moving regions of the segmented objects. The segment matching process is shown in Fig.3. These steps can be described as follows:
Step 1: the eight searching points around the current point are checked to determine the minimum mean absolute difference (MAD) location, as shown in Fig. 4.a.
Step 2: move to the point with the minimum distortion. The searching pattern in this step depends on the position of the previous minimum distortion.
a) if the previous minimum point is located at the corner of the previous search area, five points are picked, as shown in Fig. 4.b. the arrow shows the best matching point.
Frame memory
+ -
P re- processing
Quantizer (Q)
Q-1
IDCT
Object extraction
Q-coder Encoder
Buffer
Input
output
Motion Estimation
Mo
ti
o
n
v
ect
o
rs
Frame
D
ifferen
ce
Frame memory
P re- processing
Quantizer (Q)
Q-1
IDCT
Using obj ect extraction
Q-coder Encoder
Buffer
Input
output
Motion Estimation
M
o
ti
o
n
v
e
c
to
rs
Obj ect extraction
+
- DCT
F
ra
m
e
D
if
fe
re
n
c
e
Fig. 2. Block diagram of the video coding approach based on object -extraction encoder.
b) if the previous minimum distortion point is located at the middle of the horizontal or vertical axis, three additional checking points are picked, as shown in Fig. 4.c Locate the point with the minimum distortion.
Step 3 and step 4 are the same as step 2. For all four steps the step size is maintained at 1.
Fig.5 illustrates the minimum path and maximum path in the proposed searching algorithm. It is clear that the searching algorithm requires for worst case 24 searching points and for the minimum path requires 18 searching points. The maximum displacement is ±4 in level 1 of the wavelet domain, i.e., it is scaled to ±8 in the pixel domain. It worth remembering that, the search is carried only for the moving segments. Table I shows a comparison between the number of searching points of the proposed search algorithm and some of the traditional algorithms. It is clear that the proposed algorithm requires searching fewer points than the most famous algorithms (Full search (FS), Three step search (TSS) [13], and four step search (4SS) [14]), but more than some other fast algorithms (center-biased orthogonal search algorithm (CBOSA) [15], orthogonal search algorithm (OSA) [16], the Two-dimensional logarithmic search (TDL) [17], and the cross search algorithm (CSA) [18]). However, the proposed technique will use the moving regions only.
TABLE I
COMPARISON BET WEEN THE NUMBERS OF SEARCHING POINT S. Searching
algorithm ASRA FS TSS 4SS TDL OSA CBOSA CSA
Num ber of search
points 18:24 225 25 19:27 13:17 13 9:15 17
IV. SIM ULATION RESULTS
The performance of the proposed technique is introduced in this section. The proposed algorithm has been applied to the luminance component of Akiyo, Mthr_do tr, Grandma, salesman and Claire image sequences with a QCIF format. 150 frames of these sequences are tested. The frame rate is 25 frame/s, i.e., every 9 and 25 original frame is coded. To ensure the robustness of the proposed algorithm (PRA) the results are compared with the other different methods that are coding a frame without ROI (WRA), region-based video coding algorithm (RB) [20] and the conventional block-based method (CB) similar to RM8 [21]. The conventional method consists of block-based motion compensation (MC) and DCT. For the MC, a three-step vector search is used within – 15~ +15 pixels with a 16 x 16 block.
The comparison is based on the subjective test, showing the reconstructed frames side by side with the original frames (visual results), and the quality measurement (PSNR between the reconstructed frames and the original frames).
Also, the average PSNR for all frames in the video is given
by
F
i 1PSNRi
F 1
PSNRav , where F the frame number.
The summary of results of the different compres sion methods is shown in table II and III the average PSNR value is kept the same for PRA and WRA compression. The bit rate is reduced, since all the background regions will have (0, 0) motion vector. The performance of our object-based video compression method depends upon the size of the object. The difference image for our method will be small compared to the WRA method, thus the compression depends upon the number of background regions. If the number of background regions is small then the compression will be almost the same as WRA.
If the number of background regions is large then our method will have better compression compared to WRA as shown in table II and III.
Results of object-based motion field for video coding When fuzzy or rainfalling watershed schemes are used, the proposed algorithm motion field (PAMF) and a method that are coding a frame without ROI (WRA) will use the three step search (TSS), non-overlapped blocks and block size (16×16). The summary of results of the different compression methods is shown in table II. The average PSNR value is kept the same for object-based. The bit rate is reduced, since all the background blocks will have (0, 0) motion vector. The performance of our object-based motion field video compression method depends upon the size of the object. The difference image for our method will be small compared to the WRA method, thus the compression depends upon the number of background blocks. If the number of background blocks is small then the compression will be almost the same as WRA. Fig. 5. T wo different search paths of the proposed algorithm.
Fig. 4. Main steps in the center biased search.
(a) (b) (c)
Motion vector
98410-0303 IJVIP NS-IJENS © December 2009 IJENS
I J E N S a
b
c
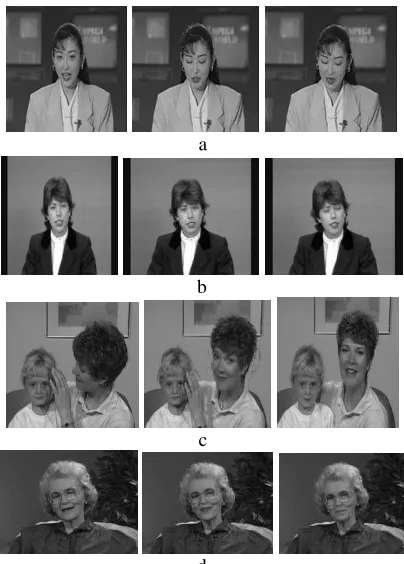
d
Fig. 6. T he results 4th, 11th and 19th frames when using fuzzy method for object extraction for Akiyo, Claire, Mthr_dotr and Grandma sequence,
respectively.
a
b
c
d
Fig. 7. T he results 4th, 11th and 19th frames when using watershed method for object extraction for Akiyo, Claire, Mthr_dotr and Grandma sequence,
respectively.
On the other hand, if the number of background blocks is large then our methods will have better compression compared to WRA as shown in table II. The performance of the proposed method of video coding:
When fuzzy used: The bit rates of the proposed method and WRA are compared, and our method outperforms the WRA by a factor ranging from 2.84 to 22.91kbps (see table II). When watershed used: The bit rates of the two methods are compared, and our method outperforms the WRA by a factor ranging from 3.26 to 22.69 kbps (see table II).
TABLE II
PSNRAV COMPARISON OF OBJECT -BASED COMPRESSION (USING FUZZY AND WATERSHED) AND USING ARBIT RARY SHAPED WITH
WRA (GOF=9)
video Akiyo Mather_Dot GrandMa Claire SALESMAN
WRA
P SNRav 35.5821 34.1612 34.511 37.1204 32.6822
Total bits_25fps (kbps)
214.458 480.032 427.115 282.737 397.492
P AMF using Fuzzy
P SNRav 35.5818 34.2361 34.6106 37.2602 32.7265
Total bits_25fps (kbps)
208.262 416.562 304.434 204.234 281.878
P AMF using watershed
P SNRav 35.5808 33.965 34.5907 37.2237 32.7214
Total bits_25fps (kbps)
207.149 405.622 304.478 194.179 282.684
P AMF using arbitrary -shaped
P SNRav 35.4431 34.1183 35.2625 37.115 32.681
Total bits_25fps (kbps)
152.682 376.301 233.093 152.023 232.542
When arbitrary shaped moving regions used: it is clear that the proposed algorithm is more robust and gives better performance than the block based algorithm. The bit rates of the three methods are compared, and our method outperforms the WRA by a factor ranging from 16.38 to 34.91 kbps, and our method outperforms the proposed method when used watershed and fuzzy by a factor ranging from 8.19 to 12.61 kbps and 19.45 to 19.28 kbps, respectively.
The proposed method that used arbitrary shaped algorithm with Akiyo, Claire and Grandma video sequence provides an improvement of 2 dB (from 0.95 to 2.51 dB). The proposed method that used arbitrary shaped prov ides a small improvement (on the average) in the case of the "Mthr_dotr" sequence. The slow motion and the small area of the moving regions are the main reason of this result. We observed that the proposed method that used arbitrary shaped algorithm provides better performance in comparison with the WRA algorithm. It supports our claim that the arbitrary shaped -regions motion estimation can be effectively used instead of the motion estimation techniques for low bit rate video coding. Fig.8 shows the perceptual quality of Sample frames from the tested video sequence when using fuzzy method for object extraction. The perceptual quality of Sample frames from the tested video sequence when using watershed method for object extraction, show in Fig.9.
moving regions used. These reconstructed frames are shown in Fig. 10, for the different video sequence.
a
b
c
d
Fig. 8. the reconstructed 5th, 15th and 60th frames of Akiyo, Claire, Mthr_dotr and Grandma video sequence from the proposed algorithm when using fuzzy.
a
b
c
d
Fig. 9. the reconstructed 5th, 15th and 60th frames of Akiyo, Claire, Mthr_dotr and Grandma video sequence from the proposed algorithm when using
watershed.
a
b
c
d
Fig. 10. the reconstructed 5th, 15th and 60th frames of Akiyo, Claire, Mthr_dotr and Grandma video sequence from the proposed algorithm wh en using
arbitrary shaped moving regions.
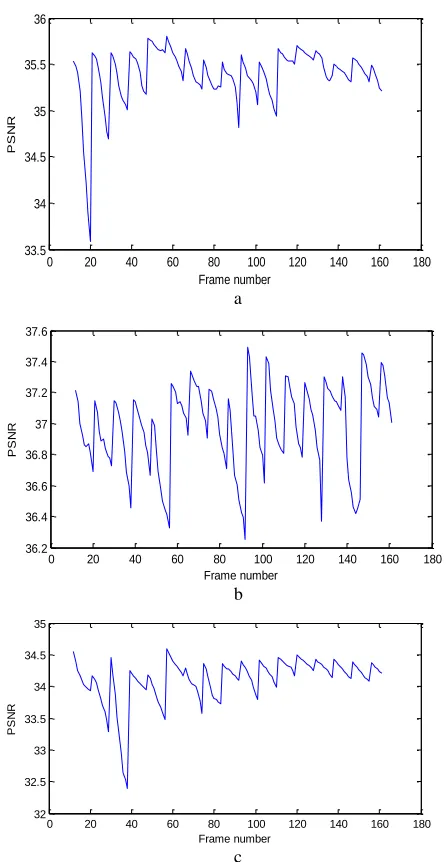
Results of video coding approach based on object-extraction It is clear that the proposed algorithm is more robust and gives better performance than coding a frame without ROI algorithm. The bit rate of our method outperforms the WRA by a factor ranging from 16.38 to 34.91 kbps. Fig. 11 shows the PSNR versus frame number curves for the Akiyo sequence, Claire sequence and the Mthr_dotr sequence.
TABLE III
PSNRAV COMPARISON OF OBJECT -BASED COMPRESSION USING ARBIT RARY SHAPED WIT H WRA (25FPS)
video Akiyo Mather
_Dot
Grand
Ma Claire
SALES MAN
WRA (Gof=9)
PSNRav 35.58 34.161 34.51 37.120 32.682 T otal bits
(kbps) 214.4 480.03 427.1 282.73 397.49
PRA (Gof=9)
PSNRav 35.38 34.110 34.56 36.982 32.671 T otal bits
(kbps) 151.1 374.77 231.6 151.88 230.23
PRA (Gof=25)
PSNRav 34.92 33.524 34.30 36.576 32.450
T otal bits
98410-0303 IJVIP NS-IJENS © December 2009 IJENS
I J E N S
a
b
c
Fig. 11. the plot of the PSNR as a function of frame number (a) AKIYO, (b) Claire and (c) MT HR_DOT R (Gof=9)
The quality of the reconstructed frames is used to indicate the performance of the proposed algorithm. These reconstructed frames are shown in Fig. 12, for the different video sequence.
TABLE IV
AVERAGE PSNRFOR THE DECODED PICTURES
Proposed method
(PRA)
RB CB
Miss
America 35.687 dB 34.20 dB 33.54 dB Claire 32.0426 dB 31.43 dB 30.85 dB
Table IV shows average PSNR for bit-rate 9.6 kbps, frame rate 7.5 frame/sec, for all the encoded frames (Miss America 37 frames and Claire 123 frames). The PSNR for the proposed method improved in average by (0.6-2.14) dB for both test
sequences. This is due to the improvement in motion compensated prediction efficiency of the proposed method.
a
b
c
d
Fig. 12. the reconstructed 15th, 25th and 70th frames of Akiyo, Claire, Mthr_dotr and Grandma video sequence from the proposed algorithm.
(Gof=9)
V. CONCLUSION
Compression schemes play a key role in the proliferation of multimedia applications and the digital media explosion. In this paper, we have presented a new two techniques, one for the video coding based on object extraction and another for the video coding which motion estimation based on object extraction. The performance comparison of these techniques with other technique is conducted. It has been demonstrated that the proposed coding scheme improves the compression efficiency with good quality and with very low bit rate. The performance evaluation of using these two techniques with different video is discussed in this work.
REFERENCES
[1] J. T aylor, Standards: DVD-video: multimedia for the masses, IEEE MultiMedia, 6(3), July–September 1999.
[2] Implementation Guidelines for the use of MPEG-2 Systems, Video and Audio in Satellite, Cable and T errestrial Broadcasting Applications, ET SI ET R 154, Revision 2, 2000.
[3] L. William Butterworth, Architecture of the first US direct broadcast satellite system, In Proceedings of the IEEE National T elesystems Conference, 1994.
[4] K. Aizawa and T . Huang, Model Based Image Coding: Advanced Video Coding T echniques for Very Low Bit -Rate Applications, In Proceedings of the IEEE, 83(2), pp.259-271, 1995.
0 20 40 60 80 100 120 140 160 180
33.5 34 34.5 35 35.5 36
Frame number
P
S
N
R
0 20 40 60 80 100 120 140 160 180
36.2 36.4 36.6 36.8 37 37.2 37.4 37.6
Frame number
P
S
N
R
0 20 40 60 80 100 120 140 160 180
32 32.5 33 33.5 34 34.5 35
Frame number
P
S
N
[5] A. Hakeem, K. Shafique, and M. Shah, An Object -based Video Coding Framework for Video Sequences Obtained from Static Cameras, International Multimedia Conference, Singapore, pp. 608 – 617, 2005. [6] ― Information T echnology - Coding of Audio-Visual Objects: Visual,"
Doc.ISO/IEC 14496-2 Final Committee Draft, (1998)
[7] Y. Liu , F. Wu , and K. Ngi Ngan, 3D Object -based Scalable Wavelet Video Coding with Boundary Effect Suppression, IEEE International Symposium on Volume , Issue , 27(30), pp. 1755 – 1758, May 2007. [8] A. Neri, S. Colonnese, G. Russo, and P. T alone, Automatic Moving Object And Background Separation, Signal Processing, 66(2), pp. 219 -232, Apr.1998.
[9] G. Yang, S. Yu, Z. Zhang, Robust moving object segmentation in the compressed domain for H.264 video stream, Proceedings of the Picture Coding Symposium, 2006
[10] Z. Liu, Z. Zhang, L. Shen, Moving object segmentation in the H.264 compressed domain, Optical Engineering, Vol. 46, number 1, pp. 017003, 2007.
[11] L. Long, F. Xingle, J. Ruirui, D. Yi, A Moving Object Segmentation in MPEG Compressed Domain Based on Motion Vectors and DCT Coefficients, Proceedings of the Congress on Image and Signal Processing, pp. 605-609, 2008.
[12] B. Sankur, and M. Sezgin, Image thresholding techniques: A survey over categories, Pattern Recognition, 2001.
[13] T . Kago, K. Iinuma, A. Hirano, Y. Iijima, and T . Ishiguro, Motion compensated interframe coding for video conferencing, in Proc. Nat: T elecommun. Conf., New Orleans, LA, Nov.29-Dec.3, pp. G5.3.1-5.3.5, 1981.
[14] P. Lai-Man and M. Wing-Chung, A novel four-step search algorithm for fast block motion estimation, IEEE T rans. Circuits and systems for video technology, 6(3), pp. 313-317, Jun. 1996.
[15] L. M. Po and W. C. Ma, A new center-biased search algorithm for block motion estimation, Proceeding ICIP95, vol. I, pp. 410-413, Dec. 1995. [16] A. Puri, H. M. Hang, and D. L. Schilling, An efficient block-matching algorithm for motion compensated coding, Proceeding of the IEEE ICASSP, pp.25.4.1-25.4.4, May 1987.
[17] J. R. Jain and A. K. Jain, Displacement measurement and its application in interframe image coding, IEEE Trans. Commun., vol. Com -29, pp. 1799-1808, Dec. 1981.
[18] M. Ghanbari, T he cross-search algorithm for motion estimation, IEEE T rans. Comm., 38(7), pp. 950-953, July 1990.
[19] Ming-Chieh C., Mei-Juan C., Chia-Hung Y., Jyong-An J., ― Region-of-interest video coding based on rate and distort ion variations for H.263+‖,Signal Processing: Image Communication 23, pp.127 –142, 2008.
[20] Yutaka Y., Y. Miyamoto, Mutsumi O., ―Very low bit rate video coding using arbitrarily shaped region-based motion compensation‖, IEEE T ransactions On Circuits and systems for video technology, Vol. 5, No. 6, pp.500-507, Dec. 1995.
[21] CCIlT SGXV Working Party XV/4 Special Group on Coding for Visual T elephony, ―Description of Reference model 8 (RMS),‖ Document #525, June 9, 1989.
[22] P. De Smet and D. De Vleschauwer, Performance and scalability of highly optimized rainfalling watershed algorithm, Proc. Int. Conf. on Image Science, Systems and T echnology, CISST ’98, Las Vegas, NV, USA, pp. 266-273, July 1998.
[23] L. R. Liang and G. Looney Carl, Competitive fuzzy edge detection, Applied Soft Computing, vol. 3, pp. 123-137, 2003.
Usama S . Mohammed. received his B.Sc. M . Sc. degrees from Assiut University, in 1985 and 1993, respectively, and his Ph.D. degree from Czech Technical University in Prague, Czech Republic, in 2000. From February 1997 to July 2000, he was research assistant in the Department of Telecommunications Technology at the Czech Technical University in Prague, Czech Republic. From November 2001 to April 2002, he was a post Doctoral Fellow with the Faculty of Engineering, Czech Technical University in Prague, Czech Republic. Since February 2006, he has been an Associated Professor with the Faculty of Engineering, Assiut University. He authored and co-authored more than 55 scientific papers. His research interests
include image coding, speech coding, telecommunication technology, statistical signal processing, blind signal separation, wireless network and video coding.