© 2017 IJSRST | Volume 3 | Issue 8 | Print ISSN: 2395-6011 | Online ISSN: 2395-602X Themed Section: Science and Technology
K-Means Clustering Algorithm to Search into the Documents Containing
Natural Language
Anusha Medavaka
Software Programmer, Seven Hills IT Solutions LLC, NJ
ABSTRACT
The time invested by customers are practically two or even more hrs looking for papers that produces the opportunity to make a search engine to improve and precision in the outcomes. The suggested work is to arrange research documents, making use of a database of understanding related with the subjects of programs, data sources and also running systems. Utilizing Clustering strategy the database is produced for the required search. There are countless clustering algorithms such as ordered clustering, self- organizing maps, K means clustering and so forth. In this paper, we recommend a clustering algorithm that search right into the files with all-natural language contained and get the best words of their content to develop a database knowledge that the first step to obtain the desired knowledge. We applied the system utilizing the K-means clustering algorithm. Furthermore the future work makes use of the search engine to make searches categorize the info introduced by the last customer as well as browsing in the precise cluster Recent obstacles in details retrieval relate to details in socials media and also rich media web content. In those situations, the web content is connected with multilingual, customer generated aspects and also content, scalability, toughness as well as resilience to mistakes. The graphical version learns is likely a prospect term is to be an element term as well as how most likely two terms are to be grouped with each other in a query aspect, as well as catches the dependences between the two elements. Recommended system boosted the previous work to stay clear of duplication of similar website by web page parsing as well as contrast of page content. We propose a clustering algorithm is properly leverage both sensations to immediately extract the major subtopics of queries where each subtopic is represented by a cluster having a number of Links and also key phrases. Additionally fast and also reliable indexing as well as looking solutions are required, in order to range electronic material distribution and video clip as needed, where big amount of queries and content associated tasks are performed by individuals. To estimate the size of a surprise database, on instinctive idea is to execute fall tasting.
Keywords : Semantic Class Extraction, QD miner, Clustering.
I.
INTRODUCTION
Recognizing the search intent of individuals is necessary for pleasing an individual's search requires it best stand for query intent is still a recurring research study issue. One consensus in the researchers is that the intents of queries is characterized along multiple measurements [1] The intents of a query is represented by its search objectives, such as educational, navigational, and transactional [2] We
information structure of left-deep-tree as well as specify the idea of designated query to create an injective mapping from tuples to queries supported by the internet user interface [5] Normally, there is a demand of devices for metadata extraction, schemas and also metadata mapping rules as well as devices, multilingual metadata and also content translation and also accreditation. Details retrieval (IR) systems are required to offer systematic responses relative to typos or inflexions, and also need to be effective enough while arranging massive result listings [6] Context Resemblance Model, in which we design the filtered resemblance between each pair of item. Web link category recommends individual passion content mining in various elements like shopping, education, searching [7].
II.
RELATED WORK
The subjects subtopics of a query are represented by a variety of queries or Links. Subjects is usually extra coarse-grained and cover several queries, while subtopics are extra fine-grained and also related to a certain query [8] Mining topics from search log data has been intensively studied Click-through bipartite graph data is used for clustering queries as well as Links. Specifically queries which share the exact same clicked URLs are taken into consideration similar. Methods for executing the task have actually been suggested [9] Suggested carrying out clustering on a click-through bipartite chart as well as checking out the gotten clusters as topics covering numerous queries author represents query facets to recognize customer interest for search in diversity [10] Investigated design creates subtopics based on query elements as well as recommended faceted diversity strategies. Each aspect includes a team of words or phrases removed from search results page [11] Faceted search is a technique for accessing info arranged according to a faceted category system, acceding individuals to digest, assess and browse via multidimensional data. It is new made use of in
e-commerce and virtual libraries [6] Faceted search is similar to query facet extraction in that both of them use collections of coordinate terms to represent various facets of a query [12] The Deep Internet is additionally believed to be the greatest resource of structured data on the internet and thus accessing its materials has actually been a long standing obstacle in the data administration community.Over the previous couple of years they have developed a system that subjected web content from the Deep Internet to web-search customers of Google.com [13].
III.
SYSTEM ARCHITECTURE
Query facet mining from big searchable data is difficult task. This system change facet mining job with the assistance of all-natural language processing for HTML kind data.Methods for utilizing an individual click behavior in different searches have actually been established [15] The exploitation of the prefix and suffix relationship in queries is thought about in the previous job. In our job not only utilize the prefix as well as suffix relationship between queries, however likewise the clicked Links of the queries and our objective is to conduct query subtopic mining [14].
IV.
PROPOSED APPROACH
Search results page clustering tries to cluster the search engine result according to semantic courses, topics. The clicked Links after looking with the initial query and also the increased queries model to represent the same subtopic [16] This is sensation of subtopic explanation by additional keyword phrase. Further much more variety of concealed data sources does not publicize their complete dimensions, while such info is useful to the public as an economic sign for keeping an eye on product growth [17].
A.
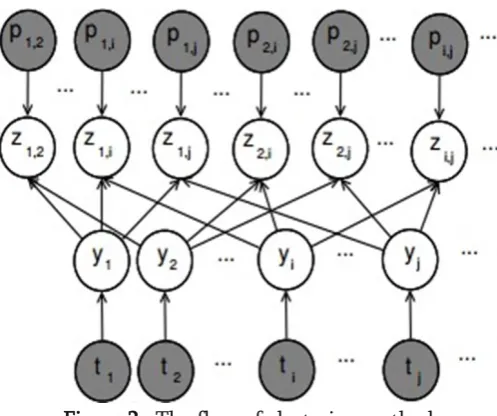
GRAPHICALMODELWe define all the variables in our graphical model. Let
Y = {yi}, where yi= 1{ti∈TF } is a label indicating
whether a list item ti is a facet term. Here 1{·} is an indicator function which takes on a value of 1 if its
argument is true, and 0 otherwise. pi,jdenotes the list
items pair (ti, tj ), and PL = {pi,j|pi,j = (ti, tj ), ti, tj∈ TL,
ti6= tj} denotes all the items pairs in TL. Let Z = {zi,j},
where zi,j= 1{∃F ∈ F, tititi∈ F ∧tj∈ F} is a label indicates
[19] whether the corresponding item pair pi,jshould be
grouped together in a query facet. The vertices in our
graphical model are V = TL ∪ PL ∪ Y ∪ Z. Note that
the list items TL, and item pairs PL are always observed.
The algorithm is summarized it refines the element terms in reducing order of P( t). For each aspect term staying in the pool, it develops a cluster by iteratively consisting of the facet term that is closest to the cluster, till the diameter of the cluster surpasses the
threshold dmax [18].
1) Algorithm: WQT for clustering facet term used
inQF-I
Input:TF P (t), df (F, t), dia (F), dmax
Output: F = {F} 1: Tpool← F
2: repeat
3: t ← arg maxt∈TpoolP(t) 4: F ← {t}
5: iteratively include facet term t 0 ∈ Tpool that is
closest to F, according to df (F, t0 ), until the diameter of the cluster, dia(F), surpasses the threshold dmax.
6: F ← F ∪ {F}, Tpool ← Tpool − F
7: until Tpool is empty 8: return F
B.
CLUSTERING METHODClustering approach to mine subtopics of queries leveraging the two sensations and search log data.We construct an index to save all the queries and also their clicked URLs. Incorrect expanded queries are after that trimmed from the index. In the clustering stage, the URLs connected with a query as well as its increased queries are grouped right into clusters, each representing one subtopic [19].
C.
IndexingFigure 2 : The flow of clustering method
indexed in a daddy node and also kid nodes respectively [20] With the prefix treein the suffix tree query 'Q' and its broadened queries 'W+Q' are indexed as a papa node and also youngster nodes respectively
Figure 3 : The data structures to index search logs
2) Clustering
We conduct clustering on the clicked Links of each query and its broadened queries. Because all the queries are indexed in the trees, the clustering is performed in your area and also recursively on the trees. The clustering of clicked URLs is guided by the two phenomena. After clustering, each group of clustered Links is taken as one subtopic of the query in the papa node [21].
3) Algorithm
We utilize an agglomerative clustering algorithm to carry out clustering. The algorithm has the benefit of ease of execution. One can also think about utilizing
various other clustering algorithms. The particular algorithm is as adheres to:
Step 1: Select one URL and also develop a new cluster including the LINK.
Step 2: Select the next URL ui, and also make a resemblance contrast between the URL as well as all the Links in the existing clusters. If the similarity between LINK ui and URL uj in one of the clusters is
larger than threshold θ, after that relocate ui right into
the cluster [22]
Step 3: Finish when all the Links are processed.
4) SEARCHING
The goal of the looking solution is accessibility the individuals to quickly find as well as arrange each kind of material in the ECLAP site, and to fine-tune their queries for an extra thorough result filtering, through a rapid search interface, robust with respect to mistyping; high granularity of information has to be used to the users.
Improving of Terms is configurable on the site. This enabled us to tune and also worry the significance of certain metadata. Increasing as well as weighting of metadata are much better tuned when the website is more booming with considerable components. Each area of the ECLAP file structure is enhanced with its predefined worth at query time [23] Faceted search is triggered on the results of both simple frontal search as well as advanced search. Each faceted term is indexed un- tokenized in the ECLAP index, to accomplish a faceting count based upon thewhole facet. Drupe solution component prior to providing. The individual can choose or remove any kind of facet in any type of order to refine the search a search filter, and carries out once again the search query with or without it. Pertinent facets consist of:
B. Technical: duration, video clip high quality, gadget, author resource metadata language and also uploadtime
C. Group, taxonomy: style, historical period, performing arts, coded subject
These facets can be conditional. As an example, locations and also days, various for each and every historical duration, can be added [24].
5) V.SEARCH RESULTS
Search results page are noted by importance in descending order this means that the initial record is the most appropriate with respect to the query. The relevance is based upon the incident of the query term in the indexed record fields a higher variety of term's incidents give a greater rating for the document. Each outcome thing is presented with a thumbnail, pertinent metadata ranking, importance rating and also number of accessibilities; data exists in the very same language selected by the user amongst the offered portal localizations.
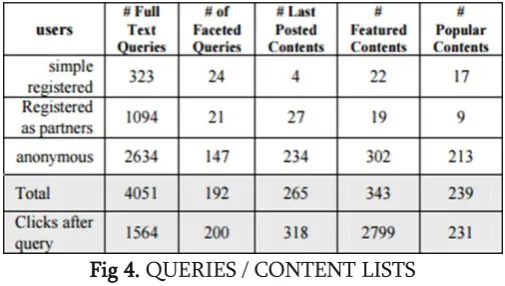
Fig 4. QUERIES / CONTENT LISTS
It can be noted that after a query on the website, the 92.65% search engine result clicks were carried out in the first page (very first 10 results). 42.27% of clicks on search results have actually been executed to the initial suggested result. The second has actually obtained only the 14% clicks.
Figure 5. Clicks order distribution (first page results and a part fo the second)
V.
CONCLUSION
indexing the available report bynaiveBayes classifiers. We have developed a clustering algorithm and also effectively and successfully mine query subtopics on the basis of both sensations. We have examined the efficiency of the proposed models. Lastly, our approach is employed search log data, which is additionally a drawback for most log mining algorithms to apply the strategy in tail queries is also an issue we need to think about.
VI.
REFERENCES
[1]. O. Ben-Yitzhak, N. Golbandi, N. Har’El, R. Lempel, A. Neumann, S. Ofek- Koifman, D. Sheinwald, E. Shekita,B. Sznajder, and S. Yogev, “Beyond basic faceted search,” in Proceedings of WSDM ’08,2008.
[2]. A. Z. Broder. A taxonomy of web search. Sigir Forum, 36:3–10,2002.
[3]. N. Bansal, A. Blum, and S. Chawla. Correlation clustering. In MACHINE LEARNING, pages 238–247,2002.
[4]. C. Carpineto, S. Osi'nski, G. Romano, and D. Weiss.A survey of web clustering engines.ACM Comput.Surv., 41(3):17:1– 17:38, July2009. [5]. G. Gorbil and E. Gelenbe, "Resilience and
security of opportunistic communications for emergency evacuation,'' in Proc. 7th ACM Workshop Perform. Monitor. Meas. Heterogeneous Wireless Wired Netw. (PM2HW2N), Oct. 2012, pp. 115_124.
[6]. T. Taleb and A. Kunz, "Machine type communications in 3GPP networks: Potential, challenges, and solutions,'' IEEE Commun. Mag., vol. 50, no. 3, pp. 178_184, Mar.2012. [7]. A. Z. Broder, M. Fontoura, E. Gabrilovich, A.
Joshi, V. Josifovski, and T. Zhang.Robust classification of rare queries using web knowledge. In Proceedings of SIGIR’07, pages 231–238,2007.
[8]. M. Burt and C. L. Liew.Searching with clustering: An investigation into the effects on
users’ search experience andsatisfaction.
[9]. Anusha Medavaka, P. Shireesha, “A Survey on
TraffiCop Android Application” in “Journal of Advances in Science and Technology”, Vol. 14, Issue No. 2, September-2017 ISSN : 2230-9659] [10]. Anusha Medavaka, Dr. P. Niranjan, P.
Shireesha, “USER SPECIFIC SEARCH
HISTORIES AND ORGANIZING PROBLEMS”
in “International Journal of Advanced
Computer Technology (IJACT)”, Vol. 3, Issue No. 6 , 2014ISSN : 2319-7900]
[11]. Yeshwanth Rao Bhandayker , “Artificial Intelligence and Big Data for Computer Cyber Security systems” in “Journal of Advances in Science and Technology”, Vol. 12, Issue No. 24, November-2016 ISSN : 2230-9659]
[12]. Sugandhi Maheshwaram, “A Comprehensive Review on the Implementation of Big Data
Solutions” in “International Journal of
Information Technology and Management”,
Vol. XI, Issue No. XVII, November-2016 ISSN : 2249-4510]
[13]. Sugandhi Maheshwaram , “An Overview of Open Research Issues in Big Data Analytics” in “Journal of Advances in Science and
Technology”, Vol. 14, Issue No. 2, Septe
mber-2017 ISSN : 2230-9659]
[14]. Yeshwanth Rao Bhandayker, “Security Mechanisms for Providing Security to the
Network” in “International Journal of
Information Technology and Management”, Vol. 12, Issue No. 1, February-2017, ISSN : 2249-4510]
[15]. Sriramoju Ajay Babu, Dr. S. Shoban Babu, “Improving Quality of Content Based Image Retrieval with Graph Based Ranking” in “International Journal of Research and
Applications”, Volume 1, Issue 1, Jan-Mar 2014
[16]. Dr. Shoban Babu Sriramoju, Ramesh Gadde, “A Ranking Model Framework for Multiple Vertical Search Domains” in “International Journal of Research and Applications” Vol 1, Issue 1,Jan-Mar 2014 ISSN : 2349-0020 ]. [17]. Mounika Reddy, Avula Deepak, Ekkati Kalyani
Dharavath, Kranthi Gande, Shoban Sriramoju,
“Risk-Aware Response Answer for Mitigating
Painter Routing Attacks” in “International Journal of Information Technology and Management”, Volume VI, Issue I, Feb 2014 ISSN : 2249-4510 ]
[18]. Anusha Medavaka, P. Shireesha, “Analysis and Usage of Spam Detection Method in Mail Filtering System” in “International Journal of Information Technology and Management”, Vol. 12, Issue No. 1, February-2017 ISSN : 2249-4510]
[19]. Anusha Medavaka, P. Shireesha, “Review on Secure Routing Protocols in MANETs” in
“International Journal of Information
Technology and Management”, Vol. VIII, Issue No. XII, May-2015 ISSN : 2249-4510]
[20]. Anusha Medavaka, P. Shireesha, “Classification Techniques for Improving Efficiency and Effectiveness of Hierarchical Clustering for the
Given Data Set” in “International Journal of
Information Technology and Management”, Vol. X, Issue No. XV, May-2016 ISSN : 2249-4510]
[21]. Anusha Medavaka , P. Shireesha, “Optimal framework to Wireless Rechargeable Sensor Network based Joint Spatial of the Mobile
Node” in “Journal of Advances in Science and
Technology”, Vol. XI, Issue No. XXII, May
-2016 ISSN : 2230-9659]