Efficient Recognition of Facial Expressions using
Atlas Construction and Sparse Representation
Athira S Varma Hema S Mahesh
PG Student Assistant Professor
Department of Electronics & Communication Engineering Department of Electronics & Communication Engineering Marian Engineering College, Trivandrum, India Marian Engineering College, Trivandrum, India
Abstract
Facial expression recognition has many real world applications, which include human machine interaction, medical applications, and human psychology. If a set of query images are given, the exact expression type such as anger, disgust, happiness, fear, sorrow, or surprise is recognized. This facial expression recognition is formulated as a longitudinal groupwise registration. There are mainly two steps that are used which are: Atlas construction method and Sparse representation method. A diffeomorphic growth model describes the various facial feature movements. Sparse groupwise registration method suppresses the changes due to interfacial movements. Image appearance information in spatial domain and topological evolution information in temporal domain are used for recognition. This method can be evaluated in Cohn-Kanade database.
Keywords: Diffeomorphic Growth, Sprse Groupwise Registration, Topological Evolution
________________________________________________________________________________________________________
I. INTRODUCTION
Humans display their emotional state through facial expressions. A human can detect face and recognise the facial expressions without any effort. But for a machine or in a computer vision it is difficult. Mehrabian [1] says 7% of human communication information is communicated by linguistic languages wide range of applications (verbal part), 38% by paralanguage (vocal part) and 55% by facial expression. Thus, facial expressions are the most important information for emotional perception in face to face communication. Automatic recognition of facial expression recognition is an interesting and challenging problem. Automatic recognition of facial expression has wide range of application in areas such as human computer interaction (HCI), emotion analysis, psychological area, virtual reality, video- conferencing, indexing and retrieval of image and video database, image understanding and synthetic face animation. In this paper and most systems of recognition for facial expression can be divided into three phases (1) face detection (2) feature extraction (3) classification. Detect the face from image is first important phase is the mechanism for extracting the facial features from the facial image. The extracted facial features are either geometric feature such as the shapes of the facial components (eyes, mouth, etc). And location of facial characteristic points or appearance features representing the texture of the facial skin in specific facial areas including wrinkles, bulges, and furrows. Appearance based features are learned image filters. The final phase is the classifier , which will classify the image into the set of defined expressions .There are six universally recognized expressions Angry, Disgust, Fear, Happy, Sad and Surprise.
II. RELATED WORK
Study of facial expressions dates back to 1649, when John Bulwer has written a detailed note on the various expressions and movement of head muscles in his book “Pathomyotomia“. In 19th century, one of the most important works on facial expression analysis that has a direct relationship to the modern day science of automatic facial expression recognition was the work done by Charles Darwin. In 1872, Darwin [2] wrote a treatise that established the general principles of expression and the means of expressions in both humans and animals. Since the mid of 1970s, different approaches are proposed for facial expression analysis from either static facial images or image sequences. In 1978, Ekman [3] defined a new scheme for describing facial movements. This was called Facial Action Coding Scheme (FACS). FACS combines 64 basic Action Units (AU) and a combination of AU’s represents movement of facial muscles and tells information about face expressions. By the mid of 1990s, facial motion analysis has been used by researchers for automatic facial data extraction. Existing approaches for facial expression recognition systems can be divided into three categories, based on how features are extracted from an image for classification. The categories are geometric-based, appearance-based, and hybrid-based.
Conventional Methods for Facial Expression Recognition
(IJSTE/ Volume 3 / Issue 09 / 074)
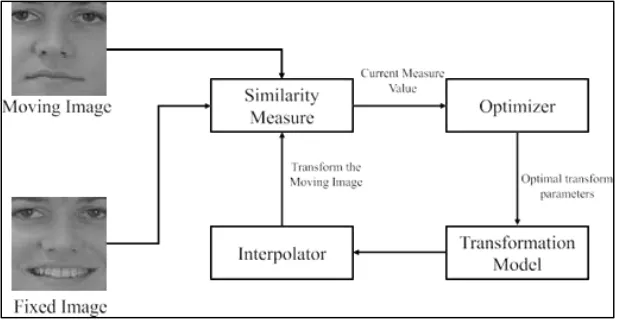
Fig. 1: A flow chart for pairwise image registration
Appearance based methods extract image intensities from facial images to characterize facial expressions Motion based methods model spatial-temporal evolution process of facial expressions, developed in virtue of image registration techniques. The recognition performance of motion based methods depended on face alignment methods used. Many advanced techniques have been proposed for face alignment, like the supervised descent method developed by Xing and De la Torre, the parameterized kernel principal component analysis based alignment method proposed by De la Torre and Nguyen, the FFT-based scale invariant image registration method proposed by Tzimiropoulos et al. [30], and the explicit shape regression FFT-based face alignment method proposed by Cao et al.
Image registration through diffeomorphic method
Image registration transforms a set of images obtained from different space, time or imaging protocols into a common coordinate system. Image registration can be formulated as an optimization problem. The diffeomorphic transformation is used due to its excellent properties, such as topology preservation and reversibility [15]. These properties are required to model facial feature movements and suppress registration errors. The definition of diffeomorphic transformation is: Given two manifolds ϒ1 and ϒ2, and a mapping function F : ϒ1 → ϒ2, F is a diffeomorphic transformation if it is differentiable and its inverse mapping F −1: ϒ2 → ϒ1 is also differentiable. F is a Cξ diffeomorphic transformation if F and F −1 are ξ times differentiable. For a registration , F is often built in an infinite-dimensional manifold [15].
Groupwise Image Registration
As facial expression process is topologically preserved and reversible, and can be considered as a diffeomorphic transformation of facial muscles. The diffeomorphic transformation during the evolution process of facial expression can be used to reconstruct facial feature movements and further guide the recognition task. Given P facial expression images I1, . . . , IP , select one image as the template, then register the remaining P − 1 images to the template by applying P −1 pairwise registration.
Fig. 2: Illustration of diffeomorphic groupwise registration
a vector and is considered as the positive y-axis. We start by computing the OF of a given video based on both brightness and gradient constancy assumption, combined with a discontinuity-preserving spatio-temporal smoothness constraint
III. PROPOSED METHOD
Extreme Sparse Learning (ESL)
A dictionary-based classification method called Extreme Sparse Learning (ESL) to recognize facial emotions in natural situations. Discriminative power of Extreme Learning Machine (ELM) with the reconstruction capability of sparse representation. The key motivation behind the use of sparse representation is its inherent ability to reconstruct the original signals from noisy and imperfect samples based on a learned dictionary [2]. By simultaneously learning a dictionary for sparse representation and a classification model, the proposed ESL algorithm is able to implicitly handle illumination and occlusion changes.
Separating the classifier training from dictionary learning may lead to a scenario where the learned dictionary is not optimal for the classification task. The dictionary is jointly learned and the classification model for better performance. Learning a discriminative dictionary for sparse representation can be accomplished by solving the following optimization problem:
min
Ɛt ( X,D,β) Ɛt (X,D, β, Y,Z), where Ɛt (X,D, β, Y,Z) = (Ɛr + γ1Ɛc + γ2vƐs ),
Ɛr (X,D, Y) = ǁY − DXǁ Ɛc (X, β, Y,Z) = ǁH(X)β − Zǁ
+ ǁβǁ Ɛc (X) = ǁXǁ1
In the above equation, Ɛt represents the overall objective function, Ɛr measures the reconstruction error, Ɛc represents the ELM optimization constraints, and Ɛs represents the sparsity constraint.
IV. EXPERIMENT
Experiments on the Extended Cohn-Kanade Database
The extended Cohn-Kanade (CK+) database includes 593 facial expression s from 123 subjects. 325 sequences from 118 subjects are selected where each sequence is categorized to one of the seven basic expressions: anger, contempt, disgust, fear, happy, sadness and surprise. Each image in the facial expression sequence has a resolution of 240×210.The eye positions in the first frame of each sequence were labelled manually. These positions were used to determine the facial area for the whole sequence and to normalize facial images. In all experiments N = 12 is used as the number of time points
V. RESULT
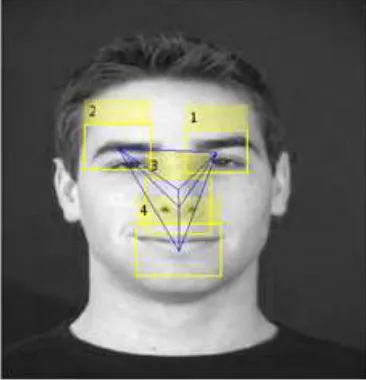
For the facial feature extraction process, the nose has been considered as the origin and the distance from nose to the eyes and lip edges has been found. The expressions are taken from Cohn Kanade database and the atlas for each expression type is constructed
(IJSTE/ Volume 3 / Issue 09 / 074)
The facial feature extraction extracts various facial features from the input image.
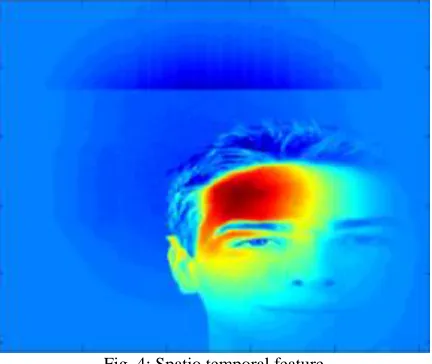
Fig. 4: Spatio temporal feature
Our method has been extensively evaluated on five dynamic facial expression recognition databases. The experimental results show that this method consistently achieves higher recognition rates than other compared methods. One limitation of the proposed method is that it is still not robust enough to overcome challenges of strong illumination changes. One possible solution is to use complex image matching metrics in the LDDMM framework, such as localized correlation coefficient and localized mutual information which have some degrees of robustness against illumination changes. This is one possible future direction for this study.
VI. CONCLUSION
In this paper, a new way to tackle the dynamic facial expression recognition problem is proposed. The method mainly consists of two stages, atlas construction stage and recognition stage. In the atlas construction stage, longitudinal atlas of different facial expressions are constructed based on sparse representation groupwise registration. The constructed atlas can capture overall facial appearance movements for a certain expression. In the recognition stage, both the image appearance and temporal information are considered and integrated by diffeomorphic registration and sparse representation. The experimental results show that this method consistently achieves higher recognition rates than other compared methods. The limitation of the proposed method is that it is still not robust enough to overcome challenges of strong illumination changes. The main reason is that the LDDMM registration algorithm used in this paper may not compensate strong illumination changes. One possible solution is to use complex image matching metrics in the LDDMM framework, such as localized correlation coefficient and localized mutual information which have some degrees of robustness against illumination changes. This is one possible future direction for this study.
ACKNOWLEDGEMENT
I also acknowledge my gratitude to all other faculty members of the Department of Electronics and Communication Engineering.
REFERENCES
[1] B. Fasel and J. Luettin, “Automatic facial expression analysis: A survey,” Pattern Recognit., vol. 36, pp. 259–275, Jan. 2003.
[2] Z. Zeng, M. Pantic, G. I. Roisman, and T. S. Huang, “A survey of affect recognition methods: Audio, visual, and spontaneous expressions,” IEEE Trans. Pattern Anal.Mach. Intell., vol. 31, no. 1, pp. 39–58, Jan. 2009.
[3] M. S. Bartlett, G. Littlewort, M. Frank, C. Lainscsek, I. Fasel, and J. Movellan, “Recognizing facial expression: machine learning and application to spontaneous behavior,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., Jun. 2005, pp. 568–573.
[4] T. Ojala, M. Pietikäinen, and T. Mäenpää, “Multiresolution gray-scale and rotation invariant texture classification with local binary patterns,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 24, no. 7, pp. 971–987, Jul. 2002.
[5] S. Lucey, A. B. Ashraf, and J. F. Cohn, “Investigating spontaneous facial action recognition through aam representations of the face,” in Face Recognition. Mammendorf, Germany: Pro Literatur Verlag, 2007, pp. 275–286.
[6] E. G. Learned-Miller, “Data driven image models through continuous joint alignment,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 28, no. 2, pp. 236– 250, Feb. 2006.
[7] G. Zhao and M. Pietikäinen, “Dynamic texture recognition using local binary patterns with an application to facial expressions,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 29, no. 6, pp. 915–928, Jun. 2007..
[8] L. Cohen, N. Sebe, A. Garg, L. S. Chen, and T. S. Huang, “Facial expression recognition from video sequences: Temporal and static modeling,” Comput. Vis. Image Understand., vol. 91, pp. 160–187, Jul. 2003.
[10] S. Koelstra, M. Pantic, and I. Patras, “A dynamic texture-based approach to recognition of facial actions and their temporal models,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 11, pp. 1940–1954, Nov. 2010.
[11] A. Ramirez and O. Chae, “Spatiotemporal directional number transi- tional graph for dynamic texture recognition,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 37, no. 10, pp. 2146–2152, Oct. 2015.
[12] H. Fang et al., “Facial expression recognition in dynamic sequences: An integrated approach,” Pattern Recognit., vol. 47, no. 3, pp. 1271– 1281, 2014.
[13] L. Zhong, Q. Liu, P. Yang, B. Liu, J. Huang, and D. N. Metaxas, “Learning active facial patches for expression analysis,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis.Pattern Recognit., Jun. 2012, pp. 2562–2569.
[14] Z. Wang, S. Wang, and Q. Ji, “Capturing complex spatio-temporal rela- tions among facial muscles for facial expression recognition,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., Jun. 2013, pp. 3422–3429.
[15] M. F. Beg, M. I. Miller, A. Trouvé, and L. Younes, “Computing large deformation metric mappings via geodesic flows of diffeomorphisms,” Int. J. Comput. Vis., vol. 61, no. 2, pp. 139–157, 2005.
[16] S. Yousefi, P. Minh, N. Kehtarnavaz, and C. Yan, “Facial expression recognition based on diffeomorphic matching,” in Proc. 17th IEEE Int. Conf. Image Process.,Sep. 2010, pp. 4549–4552.
[17] Y. Guo, G. Zhao, and M. Pietikäinen, “Dynamic facial expression recognition using longitudinal facial expression atlases,” in Proc. 12th Eur. Conf. Comput. Vis., 2012, pp. 631–644.
[18] Y. Chang, C. Hu, R. Feris, and M. Turk, “Manifold based analysis of facial expression,” Image Vis. Comput., vol. 24, no. 6, pp. 605–614, 2006.
[19] M. Pantic and I. Patras, “Dynamics of facial expression: Recognition of facial actions and their temporal segments from face profile image sequences,” IEEE Trans. Syst., Man, Cybern. B, Cybern., vol. 36, no. 2, pp. 433–449, Apr. 2006.