53 Copyright © TAETI
Improved SVM Classifier Incorporating Adaptive Condensed Instances
Based on Hybrid Continuous-Discrete Particle Swarm Optimization
Chun-Liang Lu
1,*, Tsun-Chen Lin
21Department of Applied Information and Multimedia, Ching Kuo Institute of Management and Health, Keelung, Taiwan.
2Department of Computer and Communication Engineering, Dahan Institute of Technology, Hualien, Taiwan.
Received 20 Sep 2016; received in revised form 24 Sep 2016; accepted 28 Sep 2016
Abstract
In recent years, support vector machine (SVM) based on empirical risk minimization is supervised learning model which has been successfully used in the classification and regression. The standard soft-margin SVM trains a classifier by solving an optimization problem to decide which instances of the training data set are support vectors. However, in many real applications, it is imperative to perform feature selection to detect which features are actually relevant. In order to further improve the performance, we propose the adaptive condensed instances (ACI) strategy based on the hybrid particle swarm optimization (HPSO) algorithm for the SVM classifier design. The basic idea of the proposed method is to adopt HPSO to simultaneously optimize the ACI and SVM kernel parameters for the classification accuracy enhancement. The numerical experiments on several UCI benchmark datasets are conducted to find the optimal parameters for building the SVM model. Experiment results show that the proposed framework can achieve better performance than other published methods in literature and provide a simple but subtle strategy to effectively improve the classification accuracy for SVM classifier.
Ke ywor ds: hybrid particle swarm optimization (HPSO), adaptive condensed instances (ACI), support vector machine (SVM)
1.
Introduction
Support vector machine (SVM) was originally proposed by Vapnik [1] which is a powerful classification method with state-of-the-art performance in machine learning theory, has drawn considerable attentions due to its high generalization ability for a wide range of applications including speaker recognition [2], bioinformatics [3] and text categorization [4]. In many pattern classification tasks, we are confronted with the problem that the input space is high dimensional and to find out the combination of original input features which contribute most to the classification is crucial. The computational cost of classification grows heavily with data dimension size, making feature selection an important issue for the SVM. The feature selection mechanism falls into three categories: filtering, wrapper, and embedded methods [5]. Filters generally involve a non-iterative computation on the original features, which can execute very fast, but not usually optimal since the learning algorithm are not taken into account. Wrapper methods usually achieve better results than filters since they are tuned to the specific interactions between the classifier with original feature set and very computationally intensive. Finally, unlike filters and wrappers, the embedded techniques simultaneously
de-termine features and classifier during the training process but the computational time is smaller than wrapper methods.
Feature selection problem is a challenging task because there can be complex interaction among features. Therefore, an exhaustive search is practically impossible, and the efficient global search technique is needed. Evolutionary computation (EC) are well known heuristic approaches global search ability such as simulated annealing (SA) [6], genetic algorithm (GA) [7], and particle swarm optimization (PSO) [8], have gained a lot of attention from researchers in the area. Compared with other EC algorithms such as SA and GA, PSO is computa-tionally less expensive and can converge more quickly. A GA-based feature selection method, which optimized both the feature selection and parameters for SVM, was proposed by Huang [9], and the authors pointed out that the algorithm may work superior to the conventional grid search method. How-ever, the treatment of these redundant or irrelevant instances is not taken into account in the classification procedure. In this paper, the effectively adaptive condensed instances (ACI) strategy that we previously published [7] is applied to decide which instances of the training data set are support vectors for coping with the problem mentioned above. Short communica-tions of the early stages of this work have appeared in [7]. Here we significantly extend our approach to account for the rele-vant instances selection during the SVM training process.
In order to further improve the classification performance, the ACI strategy based on the hybrid particle swarm optimiza-tion (HPSO) algorithm is proposed for the SVM classifier design. Several UCI benchmark datasets are conducted to validate the effectiveness and the experiment results show that the proposed framework can achieve better performance than other GA-based existing methods in literature. The remainder of this paper is organized as follows. Section 2 describes the related work including the basic PSO and SVM classifier. Section 3 illustrates particle representation, hybrid PSO with disturbance operation, ACI scheme and the proposed frame-work for the SVM classifier. Section 4 provides the experiment results, and conclusions are made in section 5.
2.
Related work
54 Copyright © TAETI Copyright © TAETI Copyright © TAETI
Copyright © TAETI Copyright © TAETI
than other evolutionary algorithms. During the optimiza-tion procedure, particles communicate good posioptimiza-tions to each other and adjust position according to their history experience and the neighboring particles. The basic con-cept of the PSO algorithm is illustrated as follow:
1
1 1 2 2
( )
( )
k k k k
id id id id
k k
id id v w v c r pb x
c r gb x
(1)
1 1
k k k
id id id
x v x (2)
whered1,2,...,D, i1,2,...,N, and D is the dimension of
the search space, N is the population size, k is the iterative times; k
id
v is the i-th particle velocity, xidk is the current particle solution, the i-th particle position is updated by equation (2).
k id
pb is the i-th particle best (pbest) solution achieved so far;
k id
gb is the global best (gbest) solution obtained by any particle
in the population; r1and r2 are random values in the range
[0,1] for denoting remembrance ability. Both of c1andc2 are
learning factors, w is inertia factor. A large inertia weight
facilitates global exploration, while a small one tends to local exploration. Generally, the value of each component in V can be clamped to the range [−Vmax,Vmax] for controlling
exces-sive roaming of the particle outside the search space. The PSO procedure is organized in the following sequence of steps. Step 1: Initialize: Randomly generating initial particles. Step 2: Fitness evaluation: Calculate the fitness values of each particle in the population.
Step 3: Update: Compare fitness values of each particle to update the velocity and position by using equation (1) and (2). Step 4: Termination criterion: Repeat the Step 2 to Step 3 until the number of iteration reaches the pre-defined maximum number or a termination criterion is satisfied, and the best solution gbestis displayed.
2.2. Support vector machine (SVM) classifier
Support vector machine (SVM) have drawn much atten-tion due to their good performance and solid theoretical foun-dations [11]. The main concepts of SVM are to first transform input data into a higher dimensional space by means of a kernel function and then to find an optimal separating hyper-plane between the two data sets. A practical difficulty of using SVM is the selection of parameters such as the penalty parameter C
of the error term and the kernel parameter in RBF kernel function. The appropriate choice of parameters is to get the better generalization performance. The description of SVM is as follows. Given a set of training data ( , , )x1 xp with cor-responding class labels ( , , )y1 yp and yi { 1, 1}. The SVM attempts to find a decision surface f x( ), to jointly maximize the margin between the two classes and minimize the classification error on the training set.
1
( ) p ( , )
i i i
i
f x
y K x x b (3)where Kis a kernel function, iis the Lagrange multiplier corresponding to the i-th training data xiand bis the bias. The simple kernel is the inner product function K x x( , )ˆ x x,ˆ
which produces the linear decision boundaries. Nonlinear kernel function maps data points to a high-dimensional feature space as linear decision spaces. Two commonly used kernels are the polynomial kernel Kp( , )x xˆ and the radial basis func-tion (RBF) kernelK x xr( , )ˆ . The integer polynomial order in Kpand the width factor in Kr are hyper-parameters
which are tuned to a specific classification problem.
ˆ ˆ
( , ) 1 ,
p
K x x x x (4)
2
ˆ
ˆ
( , ) x x
r
K x x e (5)
3.
Method
Since the optimal hyper-plane obtained by the SVM de-pends on only a small part of the data points (support vectors), it may become sensitive to noises or outliers in the training set. In this section, the ACI scheme based on hybrid PSO (HPSO) is proposed to tackle feature selection, condensed instances extraction and parameters setting simultaneously for SVM. The particle representation, fitness definition, disturbance strategy for PSO operation, ACI scheme and the proposed hybrid framework for SVM are described as follows.
3.1. Particle representation
This study used the RBF kernel function for the SVM classifier to implement our proposed method. The RBF kernel function requires two parameters Cand should be set.
Us-ing the adaptively condensed instance rate for ACI scheme and the RBF kernel for SVM, these three parameterscond,C , and features used as input attributes must be optimized simul-taneously for our proposed hybrid system. The particle, there-fore, is comprised of four parts, cond , C , are the contin-uous variables and the features mask are the discrete variables. Table 1 shows the particle representation of our design.
Table 1 The hybrid particle representation
As shown in Table 1, the representation of particle i with dimension ofnf 3, where nf is the number of features that
varies from different datasets, xi,1~xi n,f are the features mask,
, f 1 i n
x indicates the parameter valuecond, xi n,f2 represents the
parameter value C and xi n, f3 denotes the parameter value .
Fitness function F is the guide of HPSO operation to maximize the classification accuracy and minimize the number of selected features. Accis the SVM classification accuracy, fi denotes the feature mask which 1 represents the feature i is selected and 0 indicates that feature i is not selected. Thus, the particles with high classification accuracy and a small number of features produce a high fitness value and affect particle’s positions on the next iteration. Considering the tradeoff be-tween the classification accuracy and selected feature number, these two weight w1 and w2 values can be adjusted according
55 Copyright © TAETI
1
1 2
1
f
n i i
F w Acc w f
(6)3.2. PSO with disturbance operation
In the discrete PSO, the particle’s personal best and global best is updated as in continuous value. The major different between discrete PSO with continuous version is that velocities of the particles are rather defined in terms of probabilities that a bit whether change to one. By this definition, a velocity must be restricted within the range[Vmin,Vmax]. This can be accom-plished by a sigmoid function ( )S v , and the new particle posi-tion is calculated using the following rule:
If 1
min max
( , )
k id
v V V then k1 max(min( max, k1), min)
id id
v V v V , where
1
1 1
( )
1 k
id
k
id v
S v
e
(7)
If ( ) ( k1) id
rand S v , then k 1 1 id
x ; else k1 0 id
x .
The function S v( )id is a sigmoid limiting transformation and rand( ) is a random number selected from a uniform distribution in [0, 1]. Note that the discrete PSO is susceptible to a sigmoid function ( )S v saturation which occurs when ve-locity values are either too large or too small. For a veve-locity of zero, it is a probability of 50% for the bit to flip.
According to the searching behavior of PSO, the gbest value will be an important clue in leading particles to the global optimal solution. It is unavoidable for the solution to fall into the local minimum while particles try to find better solutions. In order to allow the solution exploration in the area to produce more potential solutions, a mutation-like disturbance operation is inserted between Eq. (1) and Eq. (2). The disturbance oper-ation random selects k dimensions (1
k
problem dimen-sions) of m particles (1
m
particle numbers) to put Gauss-ian noise into their moving vectors (velocities). The disturb-ance operation will affect particles moving toward to unex-pected direction in selected dimensions but not previous expe-rience. It will lead particle jump out from local search and further can explore more diversity of searching space.3.3. Adaptive condensed instances (ACI) scheme
The effectively ACI scheme that we previously published in [7] is extended to decide which instances of the training data set are support vectors. The adaptively condensed instances coefficient in the data reduced process is flexible to edit out noisy samples, reduce the superfluous data points and make the SVM less sensitive to noises and outliners. The adaptively condensed instances coefficientcond[0,1] is defined as the ratio of the selected number of condensed instances to overall dataset. The ACI scheme is described as follows.
Step 1: Initialize: Randomly generating initial instance set. Step 2: Condense: To decide whether all samples have been achieved the user defined thresholdcond. If so, terminate the process; otherwise, go to Step 3.
Step 3: Extend: If there are any un-condensed instances, using the nearest neighbor voting to renew the condensed instances; otherwise, no more new data is joined and go to Step 2.
3.4. The proposed framework for SVM classifier
Based on the particle representation, fitness definition, PSO with disturbance operation and ACI scheme mentioned above, details of the proposed hybrid framework for SVM procedure from step 1 to step 9 are described as follows. Step 1: Data preparation
Given a dataset D is considered using the 10 fold cross
validation to split the data into 10 groups. Each group contains training and testing sets. The training and testing sets are rep-resented as DtrainandDtest, respectively.
Step 2: Hybrid PSO initialization and parameters setting Set the PSO parameters including the number of iterations, number of particles, velocity, particle dimension, disturbance rate, and weight for fitness. Generate initial hybrid particles comprised of the features mask,cond, C and .
Step 3: Condensed instances selection via the ACI scheme According to the condensed instances coefficientcond rep-resented in the particle and calculated from Step 2, when all the condensed instances are computed, the nearest neighbor voting is used to renew the condensed instances set.
Step 4: Feature scaling
Feature scaling is to properly reveal the interactions be-tween features and to avoid attributes in greater numeric ranges dominating those in smaller numeric ranges. Normalization by Eq. (8) can be linearly scaled to range [-1, +1] or [0, 1], where
( )
j i
A x is the original attribute value of feature
x
i, A x'j( )i is scaled value, maxjand minj correspond to the maximum andminimum values for Aj over all samples.
'( ) ( ) min ,
max min
j i j
j i
j j
A x
A x i
(8)
Step 5: Feature selection
According to the feature mask, which is represented in the particle from Step 2, is to select input features for training set
train
D and testing setDtest. The selected features subset can be denoted as Df_train andDf_test, respectively.
Step 6: To train and test for SVM classifier
For the parameterscond, C and which are represented in the particle, to train the SVM classifier on the training da-tasetDf_train, then the classification accuracy
A
cc for SVM onthe testing dataset Df_test can be evaluated.
Step 7: Fitness evaluation
For each particle, the fitness value is to be calculated by the Eq. (6). The optimal fitness value can be stored on the evolu-tion process of PSO to search for the better fitness of particle in the next particles evolution procedure.
Step 8: Termination criteria
56 Copyright © TAETI Copyright © TAETI Copyright © TAETI
Copyright © TAETI Copyright © TAETI
Step 9: Hybrid PSO operation
In the evolution process, discrete-valued and continu-ous-valued dimension of HPSO with the disturbance operator continued to be applied for searching better particle solutions.
4.
Experiment results
4.1. Dataset and system description
To measure the performance of the developed hybrid framework, several real benchmark datasets in Table 2 are conducted to verify the effectiveness of performance. These
Table 2 The UCI benchmark datasets [7]
datasets are partitioned using the 10-fold cross validation. Our implementation platform was implemented on Matlab 2013, by extending the LIBSVM which is originally designed by Chang and Lin [12]. Through initial experiment, the parameter values of the PSO were set as follows. The swarm size is set to 100 particles. The searching ranges of continuous type dimen-sion parameters are: cond[0,1] ,
2 4
[10 ,10 ] C and
4 4
[10 ,10 ]
. The discrete type particle for features mask, we
set [Vmin,Vmax] [ 6,6] , which yields a range of [0.9975,0.0025] using the sigmoid limiting transformation by Eq. (7). Both the cognition learning factor
c
1 and the sociallearning factor
c
2 are set to 2. The disturbance rate is 0.05, andthe number of generation is 500. The inertia weight factor
min 0.4
w and wmax 0.9. The linearly decreasing inertia
weight is set as Eq. (9), where inowis the current iteration and
max
i is the pre-defined maximum iteration. According to the
fitness function defined by Eq. (6), set the accuracy’s weight
1 0.8
w and the feature’s weightw2 0.2.
max max min
max
( )
now
i
w w w w
i
(9)
Table 3 The parameters setting for PSO and GA
In [9], the authors presented the GA-based method without ACI mechanism for searching the bestC, , and features subset. The existing GA-SVM method without ACI scheme deals solely with feature selection and parameters optimization by means of genetic algorithm, and the treatment of these redundant or noisy instances in a classificationprocess did not be taken into account. Our proposed hybrid framework has been tested fairly extensively and compared with these ap-proaches including both GA-SVM and PSO-SVM apap-proaches without ACI mechanism. Furthermore, the comparison of PSO and GA technique with the ACI scheme for SVM is also pre-sented. While applying GA algorithm, a number of parameters are required to be specified. The two algorithms (both PSO and GA) are run for the same number of fitness function evalua-tions. Table 3 summarized the parameters used for PSO and GA technique. The empirical results are reported in section 4.2.
4.2. Result and comparison
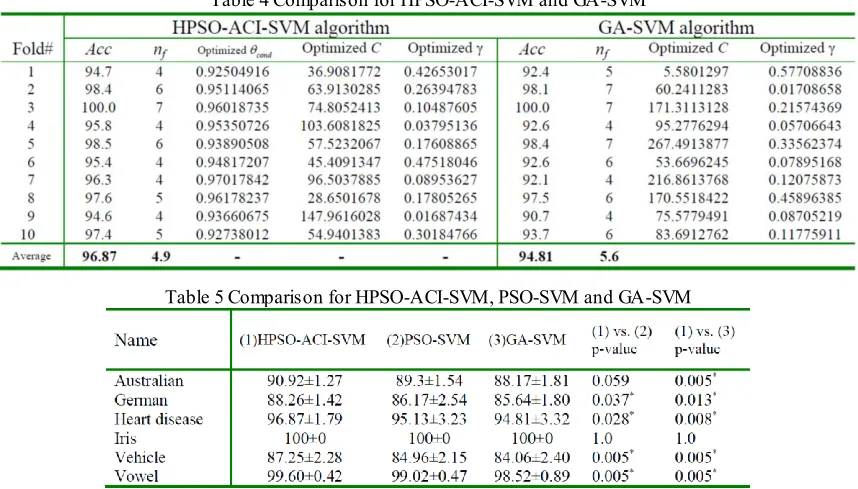
The results obtained by the developed HPSO-ACI-SVM approach are compared with those of GA-SVM proposed by Huang et al. [9] without ACI scheme. Taking the Heart disease dataset, for example, the classification accuracyAcc, number of selected featuresnf , and the best parameterscond, C, for each fold are shown in Table 4. For the HPSO-ACI-SVM method, average classification accuracy rate is 96.87%, and average number of features is 4.9. For the GA-SVM without ACI approach, its average classification accuracy rate is only 94.81%, and average number of features is 5.6.
Table 4 Comparison for HPSO-ACI-SVM and GA-SVM
57 Copyright © TAETI Table 5 shows the summary results for the average
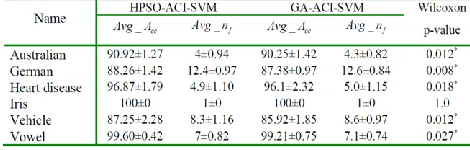
classi-fication accuracy rate of the HPSO-ACI-SVM hybrid frame-work and PSO-SVM, GA-SVM without ACI method on six UCI datasets. In Table 5, the classification accuracy rate is represented as the form of ‘average
standard deviation’. To highlight the advantage, we used the non-parametric Wilcoxon signed rank test for all of the datasets. In Table 5, the p-values of HPSO-ACI-SVM versus PSO-SVM and GA-SVM are smaller than the statistical significance level of 0.05 except Iris dataset. That is to say, the developed HPSO-ACI-SVM yields higher classification accuracy rate across different datasets to enhance the performance for the SVM.Further, under our proposed hybrid framework with ACI mechanism, the performance of both PSO and GA optimiza-tion techniques in terms of the average classificaoptimiza-tion accuracy rate Avg_Accand the average number of selected features
_ f
Avg n is compared. In Table 6, the HPSO exhibits slightly higher classification accuracy and fewer selected features than GA. It is observed that, from an evolutionary point of view, the performance of the HPSO is better than GA. However, the results indicate that both PSO and GA algorithms can be used in optimizing the parameters under our developed hybrid framework to effectively improve the classification accuracy for SVM classifier design.
Table 6 Comparison for HPSO-ACI-SVM and GA-ACI-SVM
5.
Conclusion
For SVM classifier, it is imperative to perform feature se-lection to detect which features are actually relevant. In this study, the effectively adaptive condensed instances (ACI) strategy is applied to decide which instances of the training data set are support vectors. Furthermore, we propose the ACI scheme based on the hybrid particle swarm optimization (HPSO) algorithm to simultaneously optimize the condensed instances and SVM kernel parameters for the classification accuracy enhancement. Several UCI benchmark datasets are conducted to validate the effectiveness of the proposed method, and the experiment results show that the proposed hybrid framework can achieve better performance than other existing methods in literature. Investigating more large scale dataset as well as combining other heuristic algorithm for hybrid system may be interesting future work.
References
[1] V. N. Vapnik, "An overview of statistical learning theo-ry," IEEE Transactions on Neural Networks, vol. 10, pp. 988-999, 1999.
[2] I. J. Ding, C. T. Yen, and D. C. Ou "A method to inte-grate GMM, SVM and DTW for speaker recognition," International Journal of Engineering and Technology Innovation, vol. 4, pp. 38-47, 2014.
[3] R. Kothandan and S. Biswas, "Identifying microRNAs involved in cancer pathway using support vector ma-chines," Computational Biology and Chemistry, vol. 55, pp. 31-36, Apr. 2015.
[4] B. Ramesh and J. G. R. Sathiaseelan, "An advanced multi class instance selection based support vector ma-chine for text classification," Procedia Computer Science, vol. 57, pp. 1124-1130, 2015.
[5] X. Zhang, G. Wu, Z. Dong and C. Crawford, "Embed-ded feature-selection support vector machine for driving pattern recognition," Journal of the Franklin Institute, vol. 352, pp. 669-685, 2015.
[6] S.W. Lin, Z. J. Lee, S. C. Chen and T. Y. Tseng, "Pa-rameter determination of support vector machine and feature selection using simulated annealing approach," Applied Soft Computing, vol. 8, pp. 1505-1512, 2008. [7] C. L. Lu, I. F. Chung and T. C. Lin, "The hybrid
dy-namic prototype construction and parameter optimiza-tion with genetic algorithm for support vector machine," International Journal of Engineering and Technology Innovation, vol. 5, pp. 220-232, 2015.
[8] B. Sahu and D. Mishra, "A novel feature selection algo-rithm using particle swarm optimization for cancer mi-croarray data," Procedia Engineering, vol. 38, pp. 27-31, 2012.
[9] C. L. Huang and C. J. Wang, "A GA-based feature se-lection and parameters optimization for support vector machines," Expert systems with applications, vol. 31, pp. 231-240, 2006
[10]J. Kennedy and R. C. Eberhart, "A discrete binary ver-sion of the particle swarm algorithm," In Proceedings of the World on Systematics, Cybernetics and Informatics, vol. 8, pp. 4104-4109, 1997.
[11]V. Vapnik, The nature of statistical learning theory, New York: Springer-Verlag, 1995.
![X-ray diffraction Studies of Cu(II), Zn (II), Mo(II), Fe(II)complexes with Glibenclamide (5-chloro-N-(4-[N-(Cyclohexyl Carbnonyl) sulfamonyl]phenethyl)-2-methoxylbenzamide](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)