Contents lists available at www.innovativejournal.in
Asian Journal of Computer Science And Information Technology
Journal Homepage: http://innovativejournal.in/ajcsit/index.php/ajcsit
FASTER OBJECT RETRIEVAL WITH DYNAMIC CLUSTERING TECHNIQUE IN OBJECT
ORIENTED DATABASES
Medhat Nisha G.1, Morena Rustom D2.
1. Assistant Professor, Udhna Academy College of Computer Application & Information Technology, Surat, Gujarat, India 2. Professor, Department of computer science, Veer Narmad South Gujarat University, Surat, Gujarat, India
ARTICLE INFO ABSTRACT
Corresponding Author:
Medhat Nisha GAssistant Professor, Udhna Academy College of Computer Application & Information Technology, Surat, Gujarat, India
Key Words: Dynamic Clustering, Static Clustering, OODBMS, Relationships.
DOI:http://dx.doi.org/10.15520/
ajcsit.v7i3.56Clustering means storing related objects close together on secondary storage so that when one object is accessed from disk, all its related objects which are stored on the same disk page are also brought together into main memory. The imminent accesses to these related objects are main memory accesses which are much faster compared to disk accesses. The aim of this paper is to improve the OODBMS performance by using the buffer management technique called Dynamic Clustering. This paper focuses on reducing disk IO to improve OODBMS performance. In database environment, effective buffer management of the main memory is the key in increasing efficiency through reducing the disk IO bottleneck in OODBMSs. In this paper, we propose a dynamic clustering technique for OODBMS to reduce the disk IO bottleneck and optimize its performance.
©2017, AJCSIT, All Right Reserved.
1. INTRODUCTION
Although the Relational Database Management Systems (RDBMS) are more widely used compared to Object Oriented Database Management System (OODBMS), the latter continue to play an important role in the management of data, especially for complex data. Generally, the complex data are often found in telecommunications, business, engineering and web based applications. The most common approach of accessing such data is navigation. Since we know that navigation will always incur high disk I/O costs as objects in the path of navigation may be placed in different disk pages. Excessive disk I/O is becoming increasingly undesirable as disk I/O performance improves at only 5-8% per year whereas CPU performance doubles approximately every 18 months. Thus disk I/O is likely to be a bottleneck in an increasing number of OODB applications [5, 3].
In object-oriented or object-relational databases such as multimedia databases or most XML databases, users do not access the same objects in the same order as access patterns are dynamic and not static. This justifies the need of optimization technique for improving the database performance.
1. Object Oriented Database Management System: Object Oriented Database Management Systems (OODBMS) are also called Object Oriented Databases. Object Oriented Databases store data in the form of objects rather than data such as integers, strings or real numbers. Object oriented languages such as Smalltalk, C++, Java, and others also store data in the form of objects.
An Object is something which can be uniquely identifiable. Each object is uniquely identified by a system
defined identifier called Object Id (OID). It is a real world entity and has got some state and behavior. The state of an object is identified by its properties called attributes. An attribute can have primitive values or non-primitive values. Objects that have similar properties and behavior are grouped into classes [14].
When database capabilities are combined with object-oriented (OO) programming language capabilities, the result is an object Oriented Database Management System (OODBMS). Information today includes not only data but also videos, audios, graphs, and photos which are considered complex data types. Relational DBMS are not natively capable of supporting these complex data types, while the OODBMS can handle this complex data types efficiently.
2.1 Relationship: It is basically an association between two things. These are represented through reference attributes, typically implemented through OID’s. There are basically four main types of object relationships:
2.1.1 Aggregation 2.1.2 Inheritance
2.1.3 Composition 2.1.4 Association 2.1.1 Aggregation:
Aggregation is a special form of association. The relationship here is `contains', 'is composed of', 'is part of' or 'consists of'. Like an association, an aggregation is used to represent a relationship between two classes A and B. But, with an aggregation, an object belonging to a class A, known as an aggregate class, is composed of, or contains, component objects belonging to a class B [2].
The simplest representation of aggregation is shown in the figure:
Figure – 2.3.1 Aggregation Diagram 2.1.2 Inheritance:
Inheritance is the technique in which a class can extend another class (treat it as a template) in order to inherit its members. Inheritance allows one class of objects to be defined as a special case of a more general class. Special cases are subclasses and more general cases are super classes. Process of forming a super class is generalization; forming a subclass is specialization. Subclass inherits all properties of its super class and can define its own unique properties. Subclass can redefine inherited methods [2]. 2.1.3 Composition:
It is a specialized form of Aggregation. It is a strong type of Aggregation. In this relationship child objects does not have their lifecycle without Parent object. If a parent object is deleted, all its child objects will also be deleted. This represents “death” relationship.
2.1.4 Association:
Association is a “has-a” type relationship. Association establishes the relationship between two classes through their objects. Association relationship can be one to one, one to many, many to one or many to many. For example suppose we have two classes then these two classes are said to be “has-a” relationship if both of these entities share each other’s object for some work and at the same time they can exists without each other’s dependency or both have their own life time.
3 Literature Review:
DARMONT et al [7] discuss that DSTC is a dynamic object clustering policy and its associated buffering policy, which cluster together objects that are used collectively at near instants in time. It measures object usage statistics, while respecting the following constraints: minimize the
amount of data managed, maximize the relevant of collected statistics, reduce the cost of persistent storage for these data, and minimize interference on running transactions. This goal is achieved by scaling collected data at different levels and using gradual filters on main memory-stored statistics. Hence, it is possible to store on disk only presumably significant statistics. The principle of the buffering management associated with DSTC is “When an object belonging to a cluster is accessed, the whole cluster is loaded.” This avoids useless I/Os since objects in the cluster have a good probability to be used by the current transaction.
Sunil Kr Pandey et al [1] find that the DSTC dynamic clustering algorithm identifies and re-clusters all pages that can be improved by clustering [10]. Therefore, even if the improvement is very small, a re-clustering of those pages that can be improved is triggered. This leads to over vigorous re-clustering which produces poor overall performance. Authors also find that DSTC and StatClust [9], DRO [7] is designed to produce less clustering IO overhead and use less statistics. In order to limit statistics collection overhead, DRO only uses object frequency (heat) and page usage rate information. In contrast, DSTC keeps sequence tension information which is much more costly. DRO is a page grained dynamic clustering algorithm. Therefore it re-clusters all objects in pages that are selected for re-clustering.
Sunil Kr Pandey et al [6] reveal that the re-organization phase of dynamic clustering can incur considerable operating cost. Two of the key overheads are increased write contention and I/O. To reduce write contention, most dynamic clustering algorithms are designed to be incremental and thus limit the scope of reorganization. However, DROD [Wietrzyk and Orgun1999] is the only algorithm that we are aware of that limits the scopes of reorganization so that only in-memory objects are re-clustered. Wietrzyk and Orgun [1999] accomplish this by calculating a new placement when the object graph is modified, either by a link (reference) modification or object insertion. The algorithm then re-clusters the objects that are affected by the modification or insertion. Once the new placement is determined, only the objects in memory are re-organized and the remaining objects are only re-arranged as they are loaded into memory [13].
Sylvain Guinepain et al [4] have develop an automatic and dynamic database clustering technique that will dynamically re-cluster a database with little intervention of a database administrator (DBA) and maintain an acceptable query response time at all times. The authors also discussed the issues that need to be solved when designing a database clustering technique. A new framework is also presented for an automatic and dynamic mixed database clustering technique called as AutoClust. AutoClust mines closed item sets to create clusters of attributes and uses data mining clustering to perform record clustering within each attribute cluster. AutoClust is triggered when a drop in the query response time is detected. It then checks for bad record and attribute clustering which are detected by an increased number of accesses to record and attribute clusters, respectively. If bad clustering is detected, AutoClust will trigger a re-clustering process.
that can be improved by clustering [10]. Therefore, even if the improvement is very small, a re-clustering of those pages that can be improved is triggered.
4 Clustering in Object Oriented Database:
Clustering refers to storing related objects close together on secondary storage. This means that whenever one object is accessed and brought in to memory then all the objects within the cluster are also brought in to the memory. Subsequent access to any of these object are then from main memory instead of the disk which results into much faster access than disk. Clustering is used to minimize the I/O cost of retrieving a set of related objects. In addition to reduced IO, clustering also uses cache space more efficiently by reducing the number of unused objects that occupy the cache.
In most of the DBMS clustering is usually based on grouping per relation or at a lower granularity. Grouping can be done on the values of an attribute or on a combination of attributes. In an OODB classes are used as primary means of grouping objects and searching for objects. In OODB there are many different ways by which objects can be clustered [11]. Four basic clustering ways are explained below [12]:
1. Cluster all objects belonging to the same class in the same segment of disk pages. This method provides sequential scanning of objects of a class.
2. Cluster objects belonging to a class hierarchy rooted at a user specified class.
3. Cluster objects and other objects that they recursively reference. Here objects may belong to different classes. 4. Combine option 2 and 3, and simultaneously cluster
classes on a class hierarchy and a subset of the class attribute graph.
There are basically two types of Clustering techniques. Static Clustering and Dynamic Clustering
4.1 Static Clustering:
In Static Clustering related objects are stored on the same disk page. Static clustering algorithms require that re-clustering take place when the database is not in operation, thus it doesn’t allow access to database while clustering is performed [3].
In the static case, clustering is done at the time objects are created and no reorganization is implied when the links between objects are updated [15]. A static clustering scheme offers a good placement policy for complex objects but does not take into account the dynamic evolution of objects. In applications such as design databases, objects are constantly updated during early parts of the design cycle. Frequent updates may destroy the initially clustered structure. To keep the object structure optimized, reorganization might be necessary for efficient future accesses [16].
4.2 Dynamic Clustering:
Dynamic Clustering allows re-cluster of database while database applications are in operation. Clustering of database can be performed while database is in operation. Applications that require 24 hour database access and require frequent data changes are good candidates for implementation of Dynamic Clustering. For example, Multimedia database is a good candidate for Dynamic Clustering.
Dynamic clustering is done at run time when objects are accessed concurrently and becomes attractive in an environment where the read operations dominate the write operations [15].
A dynamic clustering scheme should try to re-cluster when scattered access cost becomes too high. However, re-clustering will generate overhead such as extra disk I/Os, so it is important to determine when reorganization should occur. If the overhead is not justified, re-clustering may actually degrade the overall performance [17].
Clustering is the arrangement of objects into pages so that objects accessed close to each other temporally are placed into the same page. This in turn reduces the total I/O generated [13].
4.2.1 Proposed Dynamic Clustering Algorithm: In the proposed dynamic clustering technique instead of considering object access frequencies or object usage statistics the object relationships are taken into consideration and based on the relationship type; all the related objects are store close together on the secondary storage. So when a block of data is read from the secondary storage to main memory several related objects which are on the same disk block also loaded into the main memory, thus increasing the probability of finding the related object in the primary memory and not resorting to the secondary storage for further access of related objects. In the propose research a large size contiguous memory block size file is created with the DOS based utility called Contig utility.
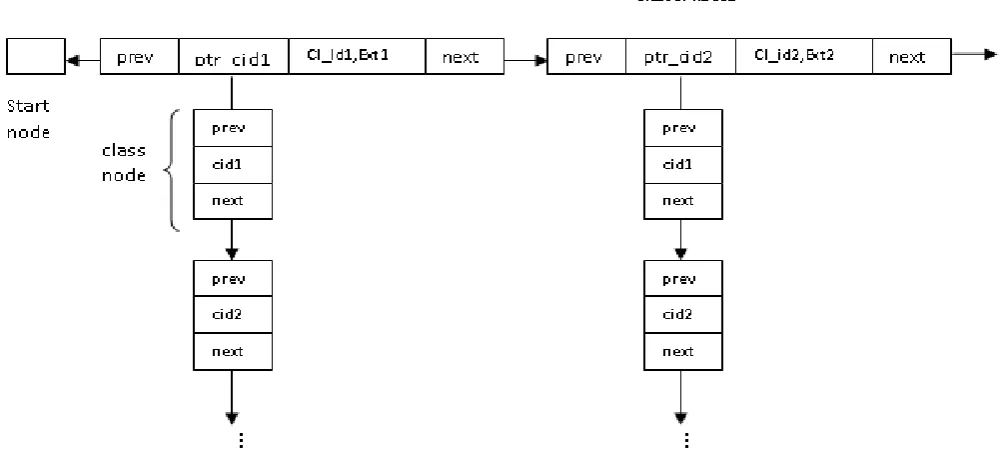
Cluster node information is persisted from primary memory to secondary memory by using data members and methods of Cluster class.
When the object is created or modified at that time the classId of that object is obtained and then the clusterNode multi-linked list is traversed to find the clusterNode which matches the classId. The matched cluster node will provide the extent address to store that object.
The constituent members of cluster node are discussed below.
The cluster node is composed of link pointers, the Clusterid and the extent address. The linked pointers are:
Link to the next cluster node
Link to the previous cluster node
Link to the class linked list for a particular cluster. The class linked list nodes consists of the doubly-linked pointers and the classId. All related classes (classId’s) will form the link of nodes being referenced by the corresponding cluster node.
Following five algorithms are proposed for achieving Dynamic Clustering.
Cluster_Persist
Cluster_Add
Object_Persist
Object_Read
Object_Delete
also uses readData() method for reading ClusterNode information from main memory.
Figure – 4.2.1 Multi- Linked List consists of Class node and Cluster node
Parameter: startNode
Step-1 Repeat Step-2 to 4 till last ClusterNode not encountered
Step-2 Call readData() Step-3 Call writeCluster() Step-4 Call writeClass() Step-5 End
4.2.1.2 Algorithm Cluster_Add(nodeId, startNode, link, classIds, extentaddress):
A new Cluster node is added into cluster node linked list when user gives a command to create a new cluster. For the creation of new ClusterNode user calls createCluster() method of Cluster class. classIds and relationshipId are passed to the createCluster() method. Cluster class contains classId list, startNode and link to other related classes.
Parameter: nodeId, startNode, link, classIds
Step-1 Repeat till last ClusterNode not encountered Step-2 If last Cluster Node found then Call create Cluster
()
Step-3 Add new ClusterNode at the end of the list Step-4 End
4.2.1.3 Algorithm Object_Persist (Object_id, start Node):
This algorithm is used to store object information on disk. When the instance of a class is instantiated or modified at that time this algorithm is called. In this algorithm first classId of new instance is obtained and then the classId is search into the ClusterNode multi – linked list. When the classId is matched then the extentaddress of the corresponding ClusterNode is accessed. The SaveDataBlock() method of MemoryRW class is called in which extentaddress and object information are passed as parameter. The SaveDataBlock() method will store object information on the disk.
Parameter: Object_id of the class whose object has been instantiated or modified, StartNode
Step-1 Fetch classId based on the Object_id
Step-2 Repeat till last ClusterNode not encontered Search class Id in Cluster Node linked list
Step-3 If class Id found then Fetch the extentad dress Step-4 Based on the extentaddress store object information on disk Call Save Data Block ()
Step-5 End
4.2.1.4 Algorithm Object_Read(Object_id, StartNode):
When there is a request to access an object from the secondary storage at that time this algorithm is used. First the classId of the object is obtained then after a ClusterNode multi linked list is traversed for finding the classId. When the classId matches with the extentaddress from the corresponding ClusterNode is accessed. Then the ReadDataBlock() method of MemoryRW class is called in which extentaddress is passed as parameter. The ReadDataBlock() method will read object information from that secondary memory address.
Parameter: Object_id of the class whose object has been read, classId, StartNode.
Step-1 Fetch classID based on objected
Step-2 Repeat till last Cluster Node not encontered Search class Id in Cluster Node linked list
Step-3 If class Id found then Fetch the extentad dress Step-4 Based on the extentad dress read object information from the disk Call Read Data Block ()
Step-5 End
4.2.1.5 Algorithm Object_Delete(Object_id, StartNode):
Parameter: Object_id of the class whose object has been deleted, StartNode.
Step-1 Fetch class ID based on objected
Step-2 Repeat till last ClusterNode not encountered Search classId in ClusterNode linked list
Step-3 If class Id found then Fetch the extentaddress Step-4 Based on the extentaddress delete object information from the disk Call Delete Data Block()
Step-5 End
The above five algorithms are used in the proposed dynamic clustering technique.
4
RESULT AND DISCUSSION:As Database operations are more expensive in terms of CPU time usage and they take more time for Disk IO operation. Optimizing them through Dynamic Clustering technique can tremendously help in terms of boosting the overall throughput of the database system.
In the proposed system, a large sized file with contiguous memory allocation is used and based on the type of the relationship, all the related class objects are stored together on that file.
The following table shows that as the numbers of objects are increased, the execution durations for contiguous memory allocation objects are decreased because all the related objects are stored on the same page on disk. So, whenever any object is loaded, all the related objects are also brought together in main memory which increase the probability to find the desired object in the main memory. Whereas, if objects are stored on non contiguous memory location, then the execution durations for those objects are increased, as number of objects are increased because in non contiguous memory allocation method, objects may not be stored sequentially; they may be stored on scattered memory locations.
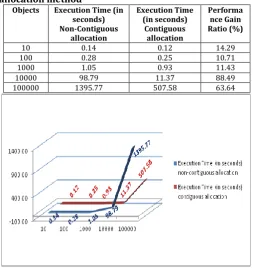
Table – 4.1 Objects and their memory execution time in both Contiguous and Non-Contiguous memory allocation method
Objects Execution Time (in
seconds) Non-Contiguous
allocation
Execution Time (in seconds)
Contiguous allocation
Performa nce Gain Ratio (%)
10 0.14 0.12 14.29
100 0.28 0.25 10.71
1000 1.05 0.93 11.43
10000 98.79 11.37 88.49
100000 1395.77 507.58 63.64
Figure – 4.2 Graphical representation of Objects and their memory execution time in both Contiguous and Non-Contiguous memory allocation method
The table also shows Performance Gain Ratio for the proposed system. As the number of objects increase, the performance of the current system also increases.
The above graph shows memory execution duration for both Contiguous and Non-Contiguous memory allocation.
In the above graph X axis represents number of objects to be executed and Y axis represents Main Memory Execution Duration for both Contiguous as well as Non-Contiguous Memory allocations.
The above graph shows that as the number of objects increase, the execution duration for those objects decrease in Contiguous Memory allocation, and it increases in Non-Contiguous Memory allocation.
The above performance measurements are obtained through Query Performance ounter () and Query Performance Frequency () API methods of Win32 in C# language environment.
As shown in the Figure-4.2, when the number of objects increases, the execution duration also increases. In Contiguous Memory Allocation, when object is loaded in to memory, all the related objects are also loaded. So it will increase the possibility to find the needed objects within the memory and it will reduce the Disk I/O overheads. The Contiguous Memory Allocation reduces the memory execution duration. So by storing all the related objects together in the contiguous memory allocation; we can reduce Disk I/O overheads and increase execution speed.
5
CONCLUSIONIn this emerging era, optimized storage of complex data is necessary. As navigation of complex data incurs high Disk IO cost, it is necessary to use an effective technique to control Disk IO operations.
The Proposed dynamic clustering technique is an effective optimization technique for OODBMS and results into substantial performance improvement. In our proposed methodology, we are performing dynamic clustering of objects based on the relationship of objects. We created a contiguous memory allocation file on the secondary storage and stored together all the related objects in that file. When any object is accessed, all the related objects also get loaded into memory. So, fetching multiple data blocks from disks simultaneously reduces cumulative seek times associated with several serial I/O accesses.
REFERENCES
[1] Sunil Kr Pandey, G.P.Singh : “A Synergistic Approach to Buffer Management in Databases Using Object Oriented Systems”, Proceedings of the 5th National Conference; INDIACom-2011, Computing For Nation Development, March 10 – 11, 2011, Bharati Vidyapeeth’s Institute of Computer Applications and Management, New Delhi [2] Medhat Nisha G, Morena Rustom D: “Dynamic Clustering technique for optimized storage in Object Oriented Database”, International Journal of Information and Computing Technology (RESEARCH@ICT), ISSN: 0976 – 5999, Volume-2 Issue-1, November 2011
[3] Zhen He, Richard Lai, Alonso Marquez and Stephen Blackburn, Opportunistic Prioritised Clustering Framework for Improving OODBMS, Journal of Systems and Software, Vol. 80, No. 3, 2007
[5] Zhen He: “Integrated Buffer Management for Object Oriented Database Systems”, Phd thesis, The Australian National University, 2004
[6] Sunil Kr Pandey, Dr. G.P.Singh, Dr. Vineet Kansal: “An Alternative approach to Temporary Memory Management in Databases using Object Oriented Systems”, IJCSNS International Journal of Computer Science and Network Security, VOL.10 No.10, October 2010, Vol. 10 No. 10 pp. 162-169
[7] DARMONT, J., FROMANTIN, C., REGNIER, S., GRUENWALD, L., AND SCHNEIDER, M.:“Dynamic clustering in object oriented databases: An advocacy for simplicity.” In Proceedings of the International Symposium on Object and Databases, (June 2000), vol. 1944 of LNCS, pp. 71–85.
[8] Zhen He, Alonso Marquez and Stephen M. Blackburn: “Opportunistic Prioritised Clustering Framework (OPCF)”, Proceedings of the 1st International Symposium on Objects and Databases 2000, (Sophia Antipolis, France, June 2000).
[9] GAY, J.-Y., AND GRUENWALD, L.:“A clustering technique for object oriented databases.” In Proceedings of the International Conference on Database and Expert Systems (DEXA 1997) (September 1997), vol. 1308 of Lecture Notes in Computer Science, Springer, pp. 81–90. [10] F. Bullat, M. Schneider:“Dynamic Clustering in Object Database Exploiting Effective Use of Relationships Between Objects.”, ECOOP ’96, Linz, Austria. LNCS Vol. 1098 (1996) 344–365
[11] Sophie Chabridon, Jen-Chyi-Liao, Yichen-Ma, Le Gruenwald: “Clustering Technique for Object- Oriented
Database System”, Compcon Spring '93, Digest of Papers, Pages: 232 - 242, IEEE Conference Publications, 1993 [12] Kim, W.: “Architectural issues in Object-Oriented Databases”, JOOP, March/April 1990, pp 29-38
[13] Jérôme Darmont (LIMOS), Le Gruenwald: “A comparison study of object-oriented database clustering techniques”, Information Sciences, Elsevier, 1996, 94 (1-4), pp.55-86
[14] Hardeep Singh Damesha: “Object Oriented Database Management Systems Concepts Advantages Limitations and Comparative Study with Relational Database Management Systems”, Global Journal of Computer Science and Technology: C Software & Data Engineering Volume 15 Issue 3 Version 1.0 Year 2015, ISSN: 0975-4172
[15] V. Benzaken, C. Delobel, Enhancing Performance in a Persistent Object Store: Clustering Strategies in O2, 4th International Workshop on Persistent Object Systems, September 1990, pp. 403-412
[16] O. DEUX et al., The Story of O2, IEEE Transactions on Knowledge and Data Engineering, Vol. 2, No. 1, March 1990, pp. 91-108
[17] J.R. Cheng, A.R. Hurson, "Effective clustering of complex objects in object-oriented databases", ACM SIGMOD International Conference on Management of Data, Denver, Colorado, May 1991
[18] Tailor Priti M., Morena Rustom D, Object Persistent Framework for Optimized Storage In .Net, Journal of science and technology – July-Dec 2010, volume 2, Issue 2, 113-120, ISSN 0975-5446.
![figure: performance. Authors also find that DSTC and StatClust [9], DRO [7] is designed to produce less clustering IO](https://thumb-us.123doks.com/thumbv2/123dok_us/9925981.1980105/2.595.43.244.266.407/figure-performance-authors-dstc-statclust-designed-produce-clustering.webp)