ISSN (Online): 2348 – 3539
HYBRID MULTIOBJECTIVE EVOLUTIONARY ALGORITHMS FOR TASK
SCHEDULING PROBLEM ON HETEROGENEOUS DISTRIBUTED SYSTEMS
1
Gomathi,
2Natarajan
1
Research Scholar, Department of Computer Science, Thanthai Hans Roever College, Perambalur
2
Assistant Professor, Department of Computer Science, Thanthai Hans Roever College, Perambalur
Abstract: Heterogeneous distributed systems are generally sent for executing computationally concentrated parallel applications with various registering needs. Different execution measurements are accessible in the writing to quantify the joining and assorted qualities of the got non commanded arrangements of the multiobjective transformative calculations. Despite the fact that GA based strategies outflank the heuristic based techniques in timetable quality, it is still inclined to untimely union traps because of constrained investigation capacity. Accordingly, it is ideal to consider the hybridization of metaheuristic, likewise called as memetic calculations. The two Pareto based multiobjective hereditary calculations: NSGA-II and SPEA2 are actualized in the unadulterated and half and half form and looked at. The joining and differing qualities of the got non-overwhelmed arrangements are assessed. The execution is assessed for the irregular and genuine application errand charts. The appropriateness of utilizing crossover NSGA-II for tackling the assignment booking issue is affirmed by the reproductions. A correlation of the metaheuristic and their hybrid version rendition is additionally reported for irregular and genuine application assignment charts on heterogeneous distributed systems.
Keywords: Hetrogeneous Distributed Systems , Evolutionary Algorithms , Scheduling.
Reference to this paper should be made as follows: 1Gomathi, 2 Natarajan (2016) „Hybrid Multiobjective Evolutionary Algorithms For Task Scheduling Problem On Heterogeneous Distributed Systems‟, International Journal of Inventions in Computer Science and Engineering , Volume 1 Issue 8 sep 2014
1 Introduction
Task scheduling in distributed computing systems is characterized as the way toward allocating undertakings of a circulated application into the accessible processors. The test of undertaking booking is to locate a spatial and fleeting task of the errands onto the processors, which results in the speediest conceivable execution, while affirming the priority requirements communicated by the edges of the DAG. A standout amongst the most imperative segments for accomplishing superior with HDCS is the mapping methodologies they embrace. Mapping of an application includes the coordinating of undertakings to machines and booking the request of execution of these errands [1]..
The task-scheduling issue is an inquiry issue where the pursuit space comprises of an exponential number of conceivable calendars as for the issue size. Metaheuristics based strategies are a class of pursuit strategies in light of enumerative procedures with extra data used to manage the inquiry. They have been utilized widely to take care of extremely complex issues. By and large, metaheuristics can be isolated into direction techniques (additionally named nearby inquiry heuristics) and populace based strategies [2].
One methodology depends on task duplication where every assignment is executed more than once keeping in mind the end goal to diminish the likelihood of disappointment. The primary issue of this methodology is that it expands the quantity of required processors. On the other hand, it is conceivable to checkpoint the application and restarts the application after a disappointment [3]. Be that as it may, if there should arise an occurrence of disappointment, the
application is backed off by the restart instrument, which requires the client to restart the application on a subset of processors and rehash a few correspondences and calculations. Subsequently, so as to minimize the effect of the restart system, it is imperative to decrease the danger of disappointment. Additionally, even for the situation where there is no checkpoint-restart instrument, ensure that the likelihood of disappointment of the application is kept as low as could reasonably be expected.
Hybridization of Multiobjective transformative calculations enhances the merging pace to Pareto front. Thus, there is a need to ponder the execution of the pareto-based calculations in their unadulterated and cross breed frames for taking care of the errand booking issue. The merging and differing qualities of the got non-commanded arrangements are vital execution measurements for assessing the multiobjective transformative calculations.
An examination of multiobjective transformative calculations (MOEAs, for example, NSGA-II, SPEA2 and their crossover variants for taking care of this multiobjective undertaking planning issue is accounted for. A straightforward neighborhood look calculation is utilized as nearby hunt strategy down hybridizing. The calculations are thought about for haphazardly produced undertaking diagrams and genuine application assignment chart. The exhibitions of the MOEAs are measured as far as the Convergence and Diversity of the got arrangements.
transformative tackling the undertaking booking issue. Session 4 the execution examination of the unadulterated and cross breed adaptation for irregular and genuine application errand diagrams are introduced. Session 5 displays the finish of this exploration work and a sign of future examination headings.
II. Related Work
Heterogeneous circulated registering frameworks (HDCS) are the developing stages for executing computationally concentrated applications with various figuring needs. They are figuring stage where equipment or programming parts situated at arranged PCs impart and organize their activities by passing messages [4]. It empowers client to get to administrations and execute applications over a heterogeneous gathering of PCs and systems [5].
As of late, HDCS are appropriate to meet the computational requests of extensive, differing gatherings of errands. The issue of mapping (counting coordinating and planning) undertakings and interchanges is an imperative issue subsequent to a proper mapping can genuinely abuse the parallelism of the framework hence accomplishing expansive speedup and high efficiency[14]. It manages appointing (coordinating) every errand to a machine and requesting (booking) the execution of the assignments on every machine keeping in mind the end goal to minimize some cost capacity.
Makespan or the timetable length is the most widely recognized cost capacity. The general issue of ideally mapping undertakings to machines in HDCS has been appeared to be NP-finished [6]. Indeed, even issues developed from the first mapping issue by making improved investigation of the hunt space [7]. The calculation was assessed for set of benchmark issues with differing CCR and calculation costs.
A half and half Genetic calculation was proposed by Varghes et al for booking continuous errands on multiprocessor framework. The calculation joined the Earliest Deadline First planning with GA. The calculation demonstrates plans with higher processor use can be created by the crossover calculation. A heuristics-based honey bee province calculation for the multiprocessor planning issue was proposed by Rebreyend et al [8]. The calculation joins the honey bee calculation with a heuristic keeping in mind the end goal to create rapidly great arrangements. The picked heuristic uses a covetous methodology and hybridization was done utilizing the roundabout representation. The heuristic is a rundown heuristic and the honey bee calculation finds the best request for the requested rundown of errands utilized by the heuristic [9].
A heuristic based cross breed hereditary calculation for heterogeneous multiprocessor planning was proposed by Wen et al. The calculation amplifies the customary GA-based methodologies in three angles. In the first place, it fuses GA with Variable neighborhood Search (VNS), to improve the harmony between worldwide investigation and
nearby abuse of inquiry space. Second, two novel neighborhood structures, in which issue particular information worried with burden adjusting and correspondence decrease is used [10]. Third, the utilization of GA with upward positioning heuristics is introduced.
The outcomes demonstrate that half breed calculation beats the immaculate variant. Subsequently, these perceptions have persuaded this examination work to apply heuristic and metaheuristics ways to deal with the undertaking planning issue [11]. The requirement for a parametric assignment diagram generator was fundamental to apply and analyze the calculations. To do the correlation of the calculations an errand chart era instrument is additionally created.
III. Materials And Methods.
Being a populace based methodology, GA is appropriate to take care of multiobjective improvement issues. A nonexclusive single-target GA can be altered to locate an arrangement of various non-ruled arrangements in a solitary run. The capacity of GA to all the while look changed locales of an answer space makes it conceivable to locate a various arrangement of answers for troublesome issues with non-raised, spasmodic, and multimodal arrangements spaces [12]. The hybrid administrator of GA may abuse structures of good arrangements as for various destinations to make new non-overwhelmed arrangements in unexplored parts of the Pareto front. Furthermore, most multi-target GA does not require the client to organize, scale, or measure goals. Hence, GA has been the most prominent heuristic way to deal with multiobjective advancement expected to surmised the genuine Pareto front for the basic issue. A larger part of these utilized a metaheuristics system and 70% of all metaheuristic methodologies depended on developmental methodologies.
Weighted-sum method
The classical approach to solve a multiobjective optimization problem is to assign a weight Ѡi to each normalized objective function Fi such that the problem is converted to a single objective problem with a scalar objective function as follows:
Min F= Ѡ1f1 + Ѡ2f2+… Ѡnfn.
Pareto-ranking approaches
Pareto-ranking approaches explicitly utilize the concept of Pareto dominance in evaluating fitness or assigning selection probability to solutions [13]. The population is ranked according to a dominance rule, and then each solution is assigned a fitness value based on its rank in the population, not its actual objective function value. If all the objectives are assumed to be minimized, a lower rank corresponds to a better solution.
There are different ranking techniques available in the literature[11].The ranking techniques are combined with various fitness sharing techniques to achieve uniformly distributed and diverse set of solutions in the pareto front. Crowding distance approach is used in NSGA-II [12] to obtain a uniform spread of solutions along the best-known Pareto front without using a fitness sharing parameter. In SPEA2 [14, 15], density measure is used to discriminate between solutions with the same rank, where the density of a solution is defined as the inverse of the distance to its kth closest neighbor in the objective function space.
SYSTEM MODEL
The system model consists of an application represented by DAG G(V,E) , Heterogeneous Distributed Computing Systems (HDCS) represented by a resource graph. The HDCS consist of set of P processors connected in a fully-connected topology. The objectives considered for scheduling the task on this system model are: Makespan and Reliability index.
Makespan
Schedule is a function S:V->Pmaps a task to the processor that executes it. Let V( j,s) = { i|s(i) = j} be the set of tasks mapped to processor j.
The completion time of a processor j is given by
where denotes the start time of the task i on processor j. The start time of the entry task is assumed to be zero. Other tasks‟ start time can be computed by considering the completion time of all immediate predecessors of the task. The communication time eij is added to the start time, if the dependent tasks are allocated to different processors. The makespan of a schedule is the time where all tasks are completed.
Reliability index
Successful execution of the DAG requires that each processor/link be operational during the time that its mapped tasks are executing or are in communication. The failure of processors during an idle time is not considered because they only affect the task‟s finish time, not the system‟s reliability.
If a processor fails an idle time, it will be replaced by a spare unit, and such a failure is not critical. The reliability
index of the HDCS when an application represented by DAG is allocated by a schedule S , is given by
HYBRID MULTIOBJECTIVE EVOLUTIONARY ALGORITHMS
In this section, a simple neighborhood search (SNS) algorithm is proposed and used as the local search procedure with the multiobjective evolutionary algorithms. The steps in the HMOGA are shown in Algorithm I. The algorithm is terminated when a pre-specified number of iterations are completed. The algorithm starts with storing all non-dominated solutions in Pt‟ with no restriction on its size. Defining a restriction on the size of this list may be necessary in certain types of applications. However, there is no restriction for the task scheduling problem because during the simulations there were no difficulties. Pt" contains the offspring generated after applying the genetic operators. Elitism is introduced in the algorithm by constructing Pt+1 as a combination of Pt‟ and Pt" .
In the SNS search part (i.e., step 8), a predefined number of neighbors are generated randomly from the neighborhood of the current solution. If any of the neighbors is better than the current solution, the current solution is replaced. When the quality of an offspring is very poor, the application of SNS seems to be waste of the computation time. Thus SNS should be applied to only good offspring. Hence, the choice of offspring to which SNS is applied is also important. Here tournament selection is used for selecting the offspring. The algorithm for the SNS is given in Figure 5.3. The same generation update method as of the NSGA-II and SPEA2 is used, which evaluates each solution using Pareto ranking and a crowding measure in step 7
Initialize population Pt of size PN
Repeat the steps 3 to 8 until termination condition is met
Evaluate the multiple objectives for each of the solution in Pt
Store the non-dominated solutions PND in Pt‟
Apply Roulette wheel selection for the selecting (PN - PND) pair of parents
Construct Pt+1 consisting of PN solutions by combining Pt‟ and Pt‟‟ using a replacement strategy.
8. Perform Simple neighborhood Search
8.1. Iterate the steps 8.2 to 8.4 PN times. Replace the current population with the PN solutions hence obtained
8.2. Randomly specify the weights obj 1.. 2 ..N where obj i for i =1, 2,....N.
8.3. Select PL solution from the current population, Pt+1 using tournament selection with replacement based on SWGR fitness evaluation using the weights specified in step 8.2.
8.4. Apply the neighborhood structures to the selected PL solution (by calling the procedure SNS).
8.5. Combine the PL solutions to the population PN-PL to get PN solution
9. Return all the PN solutions
Algorithm I: Steps involved in Hybrid MOGA
1. Procedure SNS
2. Input : PL Solutions with their fitness f from the tournament selection of step 8.3 of Figure 5.2, number of neighbors (k)
3. Repeat steps 4 to 6 for all PL solutions
4. Apply Exchange and Insert operation to each of the PL solutions K times and store in Pneigh
5. Calculate the fitness ' f of each of the K solutions in Pneigh using the SWGR fitness evaluation.
6. If ' f < f then replace the solution corresponding to f with ' f in PL
7. Return PL
Algorithm II: Steps of Simple Neighborhood Search
IMPLEMENTATION OF MOGA TO TASK SCHEDULING PROBLEM
The MOGA approaches start with a population of randomly generated candidate solutions and evolves towards better set of solutions (Pareto optimal front solutions) over number of generations or iterations. Its implementation for task scheduling problems is as given below.
Step 1) Initialization
The chromosome representation consists of two parts: the matching string and the scheduling string. The matching string is obtained by randomly assigning each subtask to a processor. The matching string, ms is a vector of length V, the number of subtasks. ms(i)=j indicates task vi is assigned to processor pj . The scheduling string is formed by performing a topological sort of the DAG, i.e., a total ordering of the nodes in the DAG that obeys the precedence constraints. The scheduling string, ss is a vector of length V, where ss (k) =i indicates vi is the kth subtask in the
scheduling string. The scheduling string gives an ordering of the subtasks that is used by the evaluation step. The initial population comprises a predefined number of chromosomes.
Step 2) Evaluation
The fitness function is used to measure and select the solutions. The makespan and reliability index are evaluated. In order to optimize both the makespan and reliability for an application, the sum of weighted global ratios (SWGR) models is used for computing the fitness as given in Equation for the weighted sum method. Different methods are used for populating pt‟ by NSGA-II and SPEA2. For the NSGAII, sort the current population according to non-domination and identify the different Pareto fronts, Fronti . The set of solutions in the first set, that is all ND 1 P Front are stored in pt‟. Similarly, for SPEA2, the fitness assignment procedure specific to it is used for evaluating the fitness of the individuals. All the individuals having the fitness value lesser than one are stored in pt‟.
Step 3) Crossover
The crossover operation was done using the same method described in this Chapter . The probability for performing crossover was determined by experimentation and set to 0.8.
Step 4) Mutation
The mutation was done using the same method described in this Chapter . The probability for performing mutations was determined by experimentation and set to 0.2.
Step 5) Replacement
The next population is constructed from the best solutions of the current population, that is, individuals belonging to pt‟and the generated offspring Pt” . This method of combining the individuals in pt‟ and the good individuals got after the reproduction operator introduces the elitism in the algorithm. In the weighted sum method, the combined set of individuals in pt‟and pt‟‟are sorted with respect to the fitness evaluated using Equation and the best N P are considered for the Pt+1 . For NSGA-II, the pareto ranking and crowding measures are used on the combined set pt‟ and pt‟‟. For SPEA2, the fitness value specific to it is used to sort the combined set.
Simple Neighborhood Search
The neighborhood structure with which the neighboring solutions are determined to move to is one of the important elements of any random search heuristics. Exchange and Insert are two neighborhood structures employed for this HMOEA.
Insert is another fine-tuning function that inserts a randomly chosen gene in front or back of another randomly chosen gene. In order to apply Insert, two random numbers are generated, one for determining the gene to be inserted and the other is for the gene that insertion to be done in front/back of it. Let these numbers be 1 and 4, where 1st gene is 1and the 4th one is 0 for the matching string m1. Now, the new state will be [2 1 2 1 0 0].
IV. Simulation Results
The correlation of the proposed HMOEA and the MOEA is displayed in this area. To start with, the calculations are assessed for a genuine application assignment chart. Next, the examination for arbitrary undertaking diagrams is talked about.
Correlation measurements
In any multiobjective improvement issue, it is sensible for the decision producer (DM) to pick a last stage arrangement x* from the pareto optimal set. The last arrangement x* is the best arrangement as for the DM's preference. The consequence of the DM for the pareto ideal set created by the weighted whole approach is examined. The triangular membership capacity is utilized for straightforwardness as a part of the procedure of basic leadership.
At the point when the genuine pareto ideal arrangement set is not given, the DM will choose a last arrangement x from an accessible arrangement set Sj . At the point when Sj is a good approximation of the genuine pareto ideal set, the picked arrangement x may be close to the best arrangement x* .The misfortune because of the decision of x rather than x* can be around measured by the separation amongst x and x* in the objectivespace. Since x and x* are obscure, the separation amongst x and x* can't be directly measured. Thus, the normal estimation of the separation between x and x* can be assessed by the normal estimation of the separation from every pareto optimal solution to its closest accessible arrangement. The D1R measure corresponds to this guess.Let S* be the reference arrangement set. The D1R measure can be composed as
where d_xy is the distance between a solution x and a referencesolution y in the N-dimensional objective space
where 〖f_1〗^* (.) is the ithobjective that is normalized using thereference solution set S*.The smaller the value of D1R (Sj ) is, the better thesolution set Sj is.
Let S be the union of the two solution sets (i.e., S=S1U S2 ).Another performance measure of the solution set 1 S with respect to the two solution sets is the ratio of solutions in S1 that are not dominated by any other solutions in S .This measure is written as:
Performance of HMOEAs in solving real application
task graph
In this section a real application task: Gauss elimination algorithm is considered. The weighted-sum based genetic algorithm was used to solve this bi-objective task scheduling problem. Then the hybrid version of the weighted-sum based GA (HGA) was developed using the procedure described in Algorithm.2.
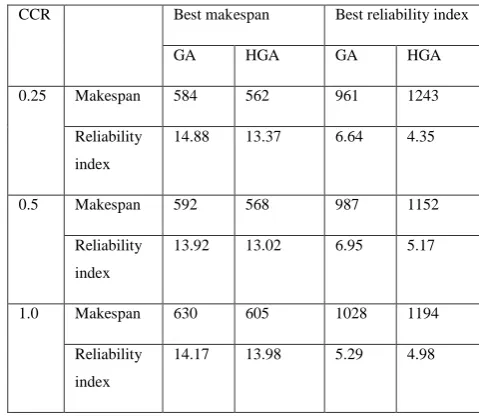
Table 1 gives the results of the best makespan and reliability index value obtained for the Gaussian elimination test graph for the matrix size, m=10 (GE-10) using the GA and HGA. The range percentage was fixed as 0.5. The average computation cost is set to 100. The numbers of processors was set to 4 and the heterogeneity factor was set to 0.2. Table 2 gives the output for the weighted sum approach using GA and HGA for the GE-10 task graph with CCR=0.25.
Table 4.1. Best values of makespan and reliability index for GE-10 task graph using GA and HGA
CCR Best makespan Best reliability index
GA HGA GA HGA
0.25 Makespan 584 562 961 1243
Reliability
index
14.88 13.37 6.64 4.35
0.5 Makespan 592 568 987 1152
Reliability
index
13.92 13.02 6.95 5.17
1.0 Makespan 630 605 1028 1194
Reliability
index
14.17 13.98 5.29 4.98
Weights GA HGA
Ѡ1 Ѡ
1
Makes
pan
Reliabili
ty index
Makespan Reliability
index
1 0 584 14.88 562 13.37
0.9 0.1 592 14.22 566 12.41
0.8 0.2 598 13.01 574 12.32
0.7 0.3 603 13.09 576 12.23
0.6 0.4 625 11.93 582 10.95
0.5 0.5 653 10.17 589 10.73
0.4 0.6 665 10.14 659 8.31
0.3 0.7 724 9.14 675 7.69
0.2 0.8 773 8.51 805 6.35
0.1 0.9 797 7.98 931 5.84
0 1 961 6.64 1243 4.35
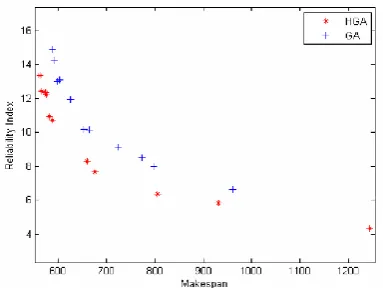
Various linearly distributed weights (Ѡ1) from 0 to 1 in steps of 0.1 are used in the weighted sum approach. The trade-off optimal solutions for solving the GE-10 task graph are obtained by running the weighted sum method program in 11 separate runs and shown in Figure 4.1. From this figure, it can be seen that the solution sets with larger diversity were obtained by the HGA.The best value for reliability index obtained using HGA is relatively less compared to GA, since the hybrid approach concentrates more on exploring the neighbors of the good solutions and finds the best possible reliability index value. Since, in this case the makespan objective is not considered at all, a bigger value for makespan is obtained. This weighted-sum method gives the tradeoff solutions for the two objectives. Though, this method is simple and flexible, the selection of the weights is critical in deciding the tradeoff between the two objectives.
Fig 4.1. Solutions obtained by GA and HGA using weighted-sum method for GE-10 task graph (CCR=0.25)
Table 4.4. Comparison of the pure MOEA using the R D1 and the ratio of non-dominated solutions measure for the GE-10 task graph
D1R (smaller values mean
better solution sets)
Ratio of non-dominated
solutions( larger values mean
better solution sets)
Task
graph
GA SPEA2
NSGA-II
GA SPEA2
NSGA-II
GE-10 2.2214 1.2933 0.5903 0.65 0.54 0.82
GE-20 6.9912 1.5919 1.405 0.56 0.61 0.74
GE-30 5.517 2.0452 1.901 0.47 0.53 0.68
Figure 4.2 shows the solution set obtained by the GA, NSGA-II and SPEA2 for the same task graph. Figure 4.3 shows the solution set obtained by the hybrid GA, hybrid NSGA-II and hybrid SPEA2 for the same task graph. The positive effect of hybridization with local search can be observed from Figure 4.3
V. Conclusion
SPEA2 for the same real time task graph is obtained. It was shown that the performance of NSGA-II and SPEA2 was significantly improved for the same task graph by the hybridization with local search. The convergence and diversity of the obtained non-dominated solutions by the MOEAs are reported. Experimental results show that better results were obtained by the HNSGA-II especially in terms of diversity of obtained nondominated solutions.
References
1. Ahmad, I. and Dhodhi, M.K. “Task assignment using a problem-space genetic algorithm”, Concurrency and Computation, Practice and Experience. Vol. 7, No.5, pp.411-428, 1995.
2. Ahmad, I. and Kwok, Y.K. “On exploiting task duplication in parallel program scheduling”, IEEE Transactions on Parallel and Distributed Systems, Vol. 9, No. 5, pp. 872-892, 1998.
3. Boeres, C., Rios, E. and Ochi,L. S. “Hybrid evolutionary static scheduling for heterogeneous systems”, Proceedings of the IEEE Congress on Evolutionary Computation, pp.1929-1936, 2005.
4. Braun T, et al 2001 A comparison of study of static mapping heuristics for a class of meta-tasks on heterogeneous computing systems. J. Parallel and Distributed Computing 61(6): 810–837
5. Chang Y, Ranka S 1992 Applications and performance analysis of a compile-time optimization approach for list scheduling algorithms on distributed memory multiprocessors. Proc. Supercomputing 512–521
6. Chitra P, Venkatesh P 2010 Multiobjective evolutionary computation algorithms for solving task scheduling problem on heterogeneous systems. Int. J. Knowledge-based and Intelligent Eng. Systems 14(1): 21– 30
7. Kwok Y K, Ahmad I 1999 Static scheduling algorithms for allocating directed task graphs to multiprocessors. ACM Computing Surveys (CSUR) 31(4): 406–471
8. Qin X, Jiang H 2006 A novel fault-tolerant scheduling algorithm for precedence constraint tasks in real time heterogeneous systems. J. Parallel Computing 32: 331– 356
9. Rewini-El H, Lewis T G 1990 Scheduling parallel program tasks onto arbitrary target machines. J. Parallel and Distributed Computing 9: 138–153
10. Shroff P, Watson D W, Flann N S, Freund R 1996 Genetic simulated annealing for scheduling data dependent tasks in heterogeneous environments. Proc. Heterogeneous Computing Workshop 98–104
11. Singh H, Youssef A 1996 Mapping and Scheduling Heterogeneous Task Graphs Using Genetic Algorithms. Proc. Heterogeneous Computing Workshop, pp. 86–97
12. Ye, G., Rao, R. and Li, M. “A Multiobjective Resources Scheduling Approach Based on Genetic Algorithms in Grid Environment”, Proceedings of the Fifth International Conference on Grid and Cooperative Computing Workshops, pp. 504-509, 2006.
13. Yoo, M. “Real time task scheduling by multiobjective genetic algorithm”, Journal of Systems and software, Vol.82, No.4, pp.619-628, 2009.
14. Youchan, Z. and Xueying, G. “Grid dependent tasks scheduling based on hybrid adaptive genetic algorithm”, art.no. 5209175, pp.35-38, 2009.
15. Zitzler, E. and Thiele, L. “Multiobjective evolutionary algorithms: A comparative case study and the strength Pareto approach”, IEEE Transactions on Evolutionary Computation, Vol. 3, No. 4, pp. 257-271, 1999.