A NOVEL DELAY EFFICIENT CARRY-SELECT ADDER USING RECURSIVE LOGIC Priyanka Agrawal 1, Prof. Vijay Yadav2 , Prof. Rahul Shrivastava
Full text
Figure




Related documents
One study that has empirically assessed the mental health of UK veterinary students (Cardwell et al., 2013), reported that study participants experienced significantly poorer
The result shows that an unanticipated increase in expected economic growth, Gross Fixed Capital Formation, government expenditure on health, labour force and government
Included is a distribu- tional analysis across the categories of the interRAI IADL-ADL Functional Hierarchy scale by country; and validation crosswalks based on a count of
Cox regression estimated hazard ratios (HRs) for CD in the offspring among mothers exposed to antibiotics during pregnancy, with adjustment for parent-reported diary data
This study will show us and will extend us more perspective on the status, leadership style, some specific types of communication, cooperation, tolerance, and many other factors
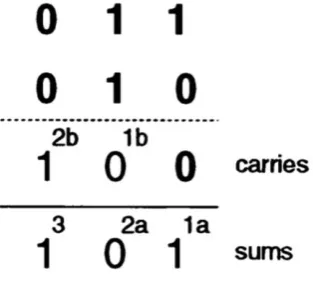
V.Vijayalakshmi et al.[10] proposed a multiplier using carry look-ahead adder and carry select adder (CSLA) which involves higher delay and area. Hasan Krad and Aws Yousif Al-Taie
2. Do you have to spend the recommended time on each task? 3. Can you stop the clock after you’ve pressed ‘Start Component’? 4. Can you go back to a previous part of the test if
The performance evaluation of the proposed architecture in terms of area and power is compared with Square Root Carry Select Adder (SQRT CSLA), Square Root Carry Select Adder
