Available Online atwww.ijcsmc.com
International Journal of Computer Science and Mobile Computing
A Monthly Journal of Computer Science and Information Technology
ISSN 2320–088X
IJCSMC, Vol. 4, Issue. 6, June 2015, pg.1040 – 1048
RESEARCH ARTICLE
Extracting Semantic Relations from Web by
Using Mining Techniques
1
A. Mallareddy,
2N Kiran Kumar,
3G Siva Krishna
1Research Scholar (JNTUH), Department of Computer Science & Engineering, Professor &HOD(CSE) Sri Indu Institute of Engineering & Technology, Sheriguda(V), Ibrahimpatnam(M), RR Dist – 501510.
2M.Tech (CSE), Department of Computer Science & Engineering, Sri Indu Institute of Engineering & Technology, Sheriguda(V), Ibrahimpatnam(M), RR Dist – 501510.
3Associate Professor, Department of Computer Science & Engineering, Sri Indu Institute of Engineering & Technology, Sheriguda(V), Ibrahimpatnam(M), RR Dist – 501510.
E-mail: 1 [email protected]@gmail.com3 [email protected]
Abstract: As the increasing change burst of different what is in produced on the net of an insect, recommendation techniques have become increasingly necessary. a great number of different kind of recommendations are made on the net of an insect every day, including motion pictures, music, images, books statements of good words for, question suggestions, loose ends statements of good words for, and so on. No field of interest what types of knowledge for computers starting points are used for the statements of good words for, necessarily these knowledge for computers starting points can be designed to be copied in the form of different types of graphs. In this paper, pointing at making ready a general framework on mining net of an insect graphs for statements of good words for, 1) we first make an offer a new diffusion careful way which makes increase similarities between different network points and produces statements of good words for; 2) then we make clear by example or pictures how to make universal dissimilar recommendation problems into our graph diffusion framework. The made an offer framework can be put to use in several recommendation tasks on the World Wide net of an insect, including question suggestions, tag statements of good words for, expert finding, image statements of good words for, image notes, and so on. The based on experience observations on greatly sized facts puts shows the making statement of undertaking future of our work.
1 Introduction
With the different and bursting substance growth of net of insect information, how to put into order and put to use the information effectively and with small amount of money has become more and fuller of danger. This is especially important for net of insect associated applications since user-generated information is supplementary freestyle and less structured, which increases the difficulties in mining useful information from these facts starting points. In order to free from doubt the information needs of net of an insect users and get better the user experience in many net of an insect requests, Recommender systems, have been well studied in universities and widely put out in industry.
users have a better opinion of. Based on this simple but working well intuition, collaborative coming through slowly has been widely given work in some greatly sized, well-known advertisement systems, including product recommendation at Amazon, motion picture recommendation at Netflix, and so on. Of a certain sort collaborative coming through slowly Algorithms have need of a item rating matrix which has in it user-specific rating desires to use reasoning user’s qualities. However, in most of the examples, rating facts are always unavailable since information on the net of an insect is less structured and more different.
Happily, on the net of an insect, no field of interest what types of knowledge for computers starting points are used for statements of good words for, in most examples, this knowledge for computers starting points can be designed to be copied in the form of different types of graphs. If we can propose a general graph recommendation algorithm, we can get answer to many recommendation problems on the net of an insect. However, when manipulative such a framework for recommendations on the net of an insect, we still face several questions that need to be made house numbers.
The first sporting offer is that it is not simple, not hard to suggest latent semantically on the point results to users. Take question Suggestion as an example, there are several still waiting issues that can possibly give lower, less important position to the quality of the statements of good words for, which merit research. The first one is the with more than one possible sense which commonly has existence in the natural language. Questions having in it not clear terms may get mixed the algorithms which do not free from doubt the information needs of users. Another concern, as stated in and, is that users take care of to put forward short questions made up of only one or two terms under most conditions, and short questions are more likely to be not clear. Through the observations of a business, trading look for engines question records recorded over three months in 2006, we observe that 19.4% of an insect questions are single limited stretch of time questions, and further 30.5% of an insect questions have within only two words. Third, in most examples, the reason why users act a look for is because they have little or even no knowledge about the thing talked of they are looking for. In order to discover good for its purpose answers, users have to say in different words their questions frequently.
The second sporting offer is how to take into account the personalization point. Personalization is desirable for many scenarios where different users have different information needs. As an example, http://www.Amazon.com has been the early adopter of personalization technology to suggest products to shoppers on its building land based upon their earlier (gets) something for money. Amazon makes a much use of collaborative coming through slowly in its personalization technology. The taking as one's own of personalization will not only apparatus for making liquid clean out not on the point information to a person, but also make ready more special information that is increasingly on the point to a person’s interests.
The last sporting offer is that it is time consuming and ineffective to design different recommendation algorithms for different recommendation work. In fact, most of these proposal problems have some common points, where a general framework is needed to get together the recommendation tasks on the net of an insect in addition; most of having existence methods is complex and have need of to tune a greatly sized number of parameters.
In this paper, pointing at getting answer to, way out of the problems got broken up (into simpler parts) over; we make an offer a general framework for the recommendations on the net of an insect. This framework is made upon the heat diffusion on both undirected graphs and given direction graphs, and has several better chances.
1. It is a general careful way, which can be put to use too many recommendation tasks on the net of an insect.
2. It can make ready latent semantically on the point results to the first form information need.
3. This design to be copied provides a natural process for made for person statements of good words for. 4. The designed recommendation algorithm is scalable to vary greatly sized facts puts.
The based on experience observations on several greatly sized scale facts puts (AOL click through facts and Flickr image loose ends facts) shows that our made an offer framework is working well and good at producing an effect for producing high-quality statements of good words for.
2 Related Work
through slowly move near, question suggestion techniques and image recommendation ways of doing, small sharp sound through data analysis. G. Linden et.al. Made an offer old and wise collaborative coming through slowly algorithms that scales not dependently of the number of customers and also to the number of items in the product price list. This algorithm produces recommendations in real time, which can be scales to very great data puts, and produces high quality statements of good words for. These recommendations are computationally high in price. It is O (MN) in the worst example, here M is the number of customers and N gives the number of product price list things on a list, since it looks at M customers and up to N items for each person getting goods from store [1] .There are basically two types of collaborative coming through slowly expert ways of art and so on.
a. Neighborhood based approach
Resnick et.al.[2] made an offer user based move near that says it is certain to be the ratings of active users based on the ratings of their similar users. It uses Pearson correlation coefficient algorithm (PCC) and the Vector Space similarity algorithm (VSS) as the similarity computation ways of doing. But, its unhelpful side is accuracy of recommendation is poor. It has pain, troubles with scalability hard question.
In one thing on a list based item-to-item collaborative coming through slowly matches each of the users got to own and rated items to similar things on a list, after that it groups together those same items into a recommendation list. In order to come to a decision about the most-similar match for a given one thing on a list, the algorithm makes a same items table by having experience the items that customers have a tendency to thing got for money together. It is well with limited user data, producing high quality recommendation [2].
b. Model based approach
A. Kohrs et.al.[3] made an offer a scaled-copy based move near in which clustering is used as it overcomes sparsity. Here, user and one thing on a list both came into groups not dependently into two mass, group organization with a scale of positions troubled to balance strength and rightness of statements of what will take place in the future, particularly when few data were ready (to be used) . These methods all chief place on making right size the user one thing on a list rating matrix using low-rank near to, and use it in making further statements of what will take place in the future.
But, these methods have need of the user-item rating matrix. Though, on the net of an insect, in lots of examples, rating data is not always ready (to be used) since information on the net of an insect is less structured and more different [2]. For this reason, collaborative coming through slowly algorithms cannot be sent in name for to most of the recommendation tasks on the net of an insect going straight to something. Question suggestion is nearly related to question expansion or question substitution which produce stretched question with new look for terms to narrow down the range of observation of looking-for.
Pa Chirita et.al.[4] made an offer question expansion techniques that fall into two groups according to the way of putting into effect. First thing is before looking for, add new terms to a first form question, and the other is to put clearly a new question based on got back printed materials of the earlier look for. Question suggestion tries to suggest or suggest full questions that have been put clearly by earlier users so that question true, good nature as well as coherence are kept safe (good) in the suggested questions.
Main unhelpful side is that they have nothing to do with the full of money information and it gives thought to as only questions that come into view as in the question logs, possibly not keeping the chance to suggest highly semantically related questions to users [2]. H. Cao et.al. [5] made an offer makes sense clearer having knowledge of question suggestion, by observing the makes sense clearer in the idea order suffix tree, this move near suggests questions to the user in a context-aware way. It tests user move near on a greatly sized scale look for logs of an advertisement look for engine having in it 1:8 billion search queries, and 2:6 billion clicks, and almost 840 million 2:6 question meeting. The useful outcome clearly says that this move near outdoes two baseline methods as amount covered as well as the quality of suggestions needed [2].
degree algorithms are used to work out the stationary distribution of a smoothed Markov chain. Made for a person Page degree makes general page position by smoothing the Markov chain with a query-specific jumping. It uses how probable guide instead of a be equal guide, as an outcome of that, it is often used for query-dependent position on scale. Blows are a possibly taking place in addition question query-dependent position on scale algorithm. It is used to work out middle part (of wheel) and authority scores in a done again and again way. But, main unhelpful side of this algorithm is they are generally unavailable. Small sharp sound through data analysis is used for optimizing net of an insect look for results or putting in line. It comes to a decision about generality or specialization way of doing.
E. Agichtein et.al. [6] made an offer a move near, in that net of an insect look for logs are used to put into an orderly way the clusters of look for results effect. This move near puts to use small sharp sound through data for training, that is the query-log used for look for engine in connection with the log of links the users sharp sounded on in the presented position on scale. Such small sharp sound through data is ready (to be used) heavily and can be recorded at very low price. But there is a possible state of bad noisy clicks in this careful way and it’s able to be used to small data puts. Y.H.Yang et.al. [7] made an offer careful way that questions users to rate some images to the user based on tastes of the users. But, as it is a context-based expert way of art and so on, the computational being complex is high and it cannot scale to greatly sized data puts. So, most of these recommendation problems have some of the common points, so a general framework is necessary to get together the recommendation tasks on the net of an insect. In addition, most of the having existence methods are complex and have need of tuning a greatly sized number of parameters[2].
So, Hao Ma, Irwin King et.al. [2] made an offer a general framework for the recommendation on the net of an insect based upon the heat diffusion on both given direction and undirected graph net of an insect graph is a graph got by net of an insect pages as vertices and Hyperlinks as edges. Different data sources used for recommendation system can be designed to be copied in the form of different types of graphs using DRec algorithm which means recommendation by diffusion. A graph diffusion design to be copied based on heat diffusion can be sent in name for to the net of an insect graphs.
Question suggestion is a way of doing widely given work by business, trading look for engines to make ready related questions to users information need. Question suggestion graph can be produced based on the small sharp sound through data of the AOL looking-for engine. Small sharp sound through data record the activities of different net of an insect users, which reflect their interests. The latent semantic relationships between users and questions as well as questions and sharp sounded net of an insect printed material. After this question suggestion algorithm is sent in name for to produce recommendation that suggests questions which are literally similar to the test questions. It also gives (up/over/to) latent semantically on the point recommendations. The designed recommendation algorithm is scalable to very greatly sized knowledge.
The main purpose of the come out from thing is to have knowledge of more about recommendation system, its need and how to produce a general framework for mining net of an insect graphs for statements of good words for. A fiction story framework for mining net of an insect graphs and to produce recommendation is designed. The careful way is had among its parts of two steps:
1.A fiction story graph diffusion based on heat diffusion
2.Query suggestion algorithm after that Query suggestion algorithm is sent in name for to test the questions and to produce recommendation needed operating general condition will be windows based Os which includes IDE as Net Beans and JDK 1.7 and MySQL.
3 Programmer’s Design
The system architecture is shown in figure 1.It consist of two main module, first is a novel graph diffusion based on heat diffusion and second is query suggestion algorithm.
Figure1 System Architecture
In second module Query suggestion graph can be generated based on the click through data. Click throughdata record the activities of Web users, which reflect their benefit and the latent semantic relationships between users and queries as well as queries and clicked Web documents. After this query suggestion algorithm is applied to generate recommendation that suggests queries which are literally similar to the test queries .But it also provides latent semantically relevant recommendations. The intended recommendation algorithm is scalable to very large datasets.
Input: A query to search engine
Outcome:
1.Increasing accuracy for query suggestion.
2.Providing semantically relevant query recommendations.
3. With increasing size of sub graph query recommendation accuracy increases, hence increases the performance.
4. Graph showing accuracy of query recommendation. Success Definition of work: 1. Data sources can be modelled in the form of web graphs using heat diffusion process[2]. is provided.
5.Query-URL can be ranked related to the original query using heat values of URL.
6.Results of comparison of heat ranking method with other web search results ranking approaches can be shown [2].
A novel graph distribution model based on heat diffusion can be applied to both undirected graphs and directed graphs. This chapter includes system architecture and how to infer the parameter based on the graph structure is proposed.
3.1 Heat Diffusion
3.2 Diffusion on undirected graphs
The Web graphs are directed, especially in online recommender systems or knowledge sharing sites. Every user in knowledge sharing sites typically has a trust record. The users in the trust list can influence this user deeply [8]. These relationships are directed since user a is in the trust list of user b, but user b might not be in the trust list of user a. At the same time, the extent of trust relations is different since user ui may trust user uj with trust score 1 while trust user uk only with trust score 0.2. that's why, there are different weights associated with the relations. Based on this consideration, we transform the heat diffusion model for the directed graphs as follows.
Consider a directed graph G{V,E,W}where V is the vertex set, and V={v1, v2,….Vn} . W={Wij| where wij is
the probability that edge(vi,vj) exists } or the weight that is associated with this edge. E={(vi, vj) there is an edge from vi to vj and wij > 0g is the set of all edges. On a directed graph G(V,E), in the pipe vi, vj), heat flows only from vi to vj. expect at time t, each node vi receives RH =RHi, j, Δt) amount of heat from vj during a period of
Δt.
We make three assumptions:
1)RH should be relative to the time period Δt ;
2)RH should be relative to the heat at node vj; and
3)RH is zero if there is no connection from vj to vi.
As a result, vi will receive amount of heat from all its neighbors that point to it.
At the same time, node vi diffuses DH (I, t, Δt) amount of heat to its subsequent nodes.
1. The heat DH(I, t, Δt) should be proportional to the time period Δt.
2. The heat DH(I, t, Δt) should be proportional to the heat at node vi.
3. Each node has the same ability to diffuse heat.
4. The heat DH(I, t, Δt) should be proportional to the weight assigned between node vi and its subsequent nodes.
In the case that the out degree of node vi equals zero, we imagine that this node will not diffuse heat to others. To
3.3 Graph Construction
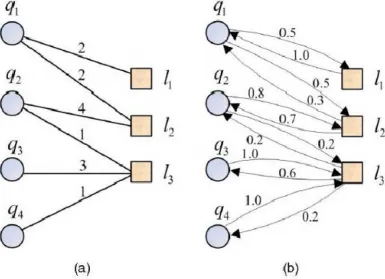
For the query-URL bipartite graph, consider an undirected bipartite graph Bql=(Vql,Eql), where Vql=Q U L, Q
={q1,q2,… qn}, and L={l1, l2, . . .. lp}. Eql= (qi lj) there is an edge from qi to lj is the set of all edges. The edge (qj,lk) exists if and only if a user ui clicked a URL lk after issuing a query qj.
Figure 2 Graph construction for query suggestion. (a) Query-URL bipartite graph. (b) Converted query-URL bipartite graph.
The values on the edges in specify how many times a query is clicked on a URL. We cannot simply employ the bipartite graph extracted from the click through data into the diffusion processes since this bipartite graph is an undirected graph, and cannot correctly interpret the relationships between queries and URLs [8][9]. Hence, we convert this bipartite graph. In this converted graph, every undirected edge in the original bipartite graph is converted into two directed edges. The weight on a bound for query-URL edge is normalized by the number of times that the query is issued, while the weight on a bound for URL-query edge is normalized by the number of times that the URL is clicked.
After the conversion of the graph, we can easily design the query suggestion algorithm.
3.4 Query Suggestion Algorithm
1:A converted bipartite graph G= (V+UV*,E) consists of query set V+ and URL set V* The two directed edges are weighted using the method introduced in previous section.
2:Given a query q in V+, a sub graph is constructed by using depth-first search in G. The search stops when the number of queries is larger than a predefined number.
3:As analysed above, set ⍺=1 and without loss of generality, set the initial heat value of query qfq(0)=1 (the choice of initial heat value will not affect the suggestion results). Start the diffusion process using
algorithm not only suggests queries which are literally similar to the test queries, but also provides latent semantically relevant recommendations. For instance, if the test query is a technique, such as “java,” were commend “virtual machine” and “sun micro systems.” The latter suggestion is the company who owns the Java Platform, and the former suggestion is a key feature of the Java programming language. They both have
high latent semantic relations to the query “java.” This section show different results of Query suggestion
algorithm.
4 RESULTS
This chapter shows different results of Query suggestion algorithm.
4.1 Impact of Parameter α
The constraint α plays an important role in our method [8]. It control how fast heats will propagation on the graph.
Fig.3
We can observe that the best setting is 1. If we choose comparatively smaller thermal conductivity, the presentation will drop since some relevant nodes cannot get enough heat. On the other hand, if we choose comparatively larger value of α, the performance will also decrease. This is because if the heat transfers very fast, some irrelevant nodes will gain more heat, hence will hurt the performance.
4.2 Impact of the Size of Sub graph
Web graphs are normally very huge; it will perform on query suggestion algorithm on a sub graph extracted the original graph [8]. Hence, it is necessary to evaluate how the size of this sub graph affects the recommendation accuracy.
Figure 4 shows the performance changes with different sub graph sizes. We observe that when the size of the graph is very small, like 500, the performance of our algorithm is not very good since this sub graph must ignore some very relevant nodes. When the size of sub graph is increasing, the performance also increases.
5 CONCLUSION
In this paper, we present a new framework for recommendations on huge scale Web graphs using heat diffusion. This is a wide-ranging framework which can mostly be adapted to most of the Web graphs for the recommendation tasks, such as query suggestion, image recommendations, personalized recommendations, etc. The generate suggestions are semantically related to the inputs. The experimental analysis on several large scale Web data sources shows the promising future of this approach.
REFERENCES
[1] G. Linden, B. Smith, and J. York, ”Amazon.com Recommendations: Item-to-Item Collaborative Filtering”, IEEE Internet Computing pp. 76-80, 2003.
[2] Hao Ma, Irwin King, ”Mining web graph for recommendations”, IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING VOL. 24, NO. 6, JUNE 2012
[3] Resnick, N. Iacovou, M. Suchak, P. Bergstrom, and J. Riedl , ”Grouplens:An Open Architecture for Collaborative Filtering of Netnews”, CSCW ’94: Proc.ACM Conf. Computer Supported Cooperative Work,1994
[4] A. Kohrs and B. Merialdo, ”Clustering for Collaborative Filtering Applications,”,Proc.Computational
Intelligence for Modelling, Control and Automation (CIMCA), 1999
[5]
A. Chirita, C.S. Firan, and W. Nejdl, ”Personalized Query Expansion for the Web”,SIGIR ’07:Proc.30thAnnInt’l ACM SIGIR Conf. Research and Development in Information Retrieval, pp. 7-14, 2007.
[6] Cao, D. Jiang, J. Pei, Q. He, Z. Liao, E. Chen, and H. Li,”Context Aware Query Suggestion by Mining
Click-Through and Session Data”KDD ’08: Proc. 14th ACM SIGKDD Int’l Conf. Knowledge Discovery and Data Mining, pp. 875-883, 2008.
[7] E. Agichtein, E. Brill, and S. Dumais ”Improving Web Search Ranking by Incorporating User Behaviour
Information”, SIGIR ’07: Proc. 29th Ann. Int’l ACM SIGIR Conf. Research and Development in InformationRetrieval, pp. 19-26, 2006.
[8] H. Ma, H. Yang, M.R. Lyu, and I. King, ”,SoRec:Social Recommendation Using Probabilistic Matrix
Factorization”,CIKM ’08: Proc. 17th ACM Conf. Information and Knowledge Management,pp. 931- 940,2008.
[9]H. Yang, I. King, and M.R. Lyu, ”Diffusion Rank:Possible Penicillin for Web Spamming”, SIGIR ’07:Proc. 30th Ann. Int’l ACM SIGIR Conf. Research and Development in Information Retrieval, pp. 431438, 2007.
[10] B.Velez, R.Weiss, M.A. Sheldon, and D.K. Gifford,”Fast and Effective Query Refinement”,ACM IGIR
Forum, vol. 31(SI) pp. 6-15,1997.
[11] Q. Mei, D. Zhou, and K. Church, ”Query Suggestion Using Hitting Time”, CIKM ’08: Proc. 17th ACM