DOI : https://doi.org/10.32628/CSEIT1953145
A Manifestation of Cloud Computing Environments for Application Clusters,
High-Performance Clusters and Allocation strategies for Virtual Machines
Kranthi Kumar. K, R. Rindha Reddy, Kurumaddali Sushmitha Information Technology, SNIST, Ghatkesar, Telangana, India ABSTRACT
Cloud Computing (CC) is the advancement of the Grid Computing (GC) worldview in the direction of administration arranged structures. The phrasing connected to this sort of handling, while portraying shared resources, alludes to the idea of Service of X. Such assets are accessible on interest and at an altogether low cost contrasted with self-conveyance of individual segments. CC is found everywhere in current situations, from vast scale associations to a just little scale business, everybody is equipping themselves cloud. Due to its effortlessness, observing and support over remote association, expansive territory inclusion. Cloud can be any sort Software as an administration, stage as an administration, foundation as an administration dependent on its use. High Performance Computing (HIPECO) implies the accumulation of computational capacity to build the capacity of handling substantial issues in science, designing, and business. HIPECO on the cloud permits performing on interest HIPECO errands by superior clusters in a cloud atmosphere. Currently, CC arrangements (e.g., Microsoft Azure, Amazon EC2) enable the users to make use of only the fundamental storage and computational utilities. They prevent the allowance of custom adjustments of the topology designs or parameters of the system. The associations structures of the nodes in HIPECO clusters ought to give a quick bury node correspondence. It is vital that adaptability is safeguarded also. In a foundation, as an administration, virtualization viably maps virtual machines to the physical machines. In spite of the fact that it is difficult, undertaking for hypervisor to choose fitting host to serve up and coming virtual machine is a must requirement. In this paper, our main aim is to examine different techniques/types of cluster topology mapping and their necessities in numerous Cloud situations to accomplish higher dependability along with adaptability of utilization which is executed inside Cloud resources (CR), HIPECO resource allocation (RA) on the cloud clusters and Cluster based designation procedure.
Keywords : Virtualization, Cloud Computing, cloud, Resource Allocation, VM arrangement, Cluster, HIPECO cluster, Cloud Resource.
I. INTRODUCTION
Prior to the coming of web, process and figuring [1] substantial outstanding burdens were finished by neighborhood systems and supercomputers. Creation and development of the web expanded the association among systems and connected millions of electronic gadgets throughout the world.
rather pay for just the measure of the registering resources they really expend [2].
CC is an example for accrediting [3] helpful, on-request organized connection to a common collection of processing resources which are configurable that are immediately discharged and then provisioned with a minimum effort by the management or interaction of service provider [4]. The idea is for increasing more extensive acknowledgment among research clusters (CC Centers of Excellence) and in the business, where it is regularly connected (eg. Cloud|Intalio[5], Amazon EC2 [6]). Therefore, the idea of CC accepts the presence of 3 essential components: called as thin clients, Cloud computing architecture (Grid) and utility computing [7]. The Grid framework gives administrations to facilitated utilization of appropriated resources (utility figuring [8]), which infers for paying their sources /utilized.
So as to accomplish the previously given advantages it is important to enhance the abilities of the executive’s administrations with smaller, adaptable UIs empowering full authority for exchanging resources. CC is an area of deliberation and the particular resources that comprise the necessary administration and incorporates self-management of resources.
Apart from utilizing the architecture which is service-oriented, Cloud arrangements emphatically rely upon virtualization procedures [9] as methods for compelling administration of the resources that are exposed. Present Cloud situations still can't seem to advance in the event that they are to legitimately bolster arranges virtualization. Key client requests not as of now upheld in Clouds include:
• Options for controlling the system architecture design;
• Options for altering the arrangement of topology parameters of L-3, for example, tending to (conventions for dynamic location task), directing,
NAT, and so on.
• Ensuring correspondence confinement; i.e., expanding the detachment ensured by utilization of independent virtual machines to the system layer.
• Options for determining sets of parameter depicting physical association properties in virtual systems, for example, latency, loss of packets, jitter so on.
• Options for indicating required parameters, for example, QoS for specific correspondence stages among VMs.
• Options for secure coordination of virtual infrastructures with current end-client correspondence infrastructures and working administrations. According to this, the Cloud arrange network topology ought to comprise an augmentation of the customer organize and
encourage authoritative of nearby
administrations with key Cloud resources. • Options for coordinating custom local network
organize security approaches with those of the Cloud's virtual system.
The expression "cluster" can take diverse implications in various settings. There are 3 kinds of clusters: a) Fail-over clusters: This cluster has two nodes: one remains dynamic and alternate remains on remain by however continually screens the dynamic one. On the off chance that the dynamic node falls down, the remain by the node assumes control, permitting a errand-basic framework to keep working.
b) Load-balancing clusters: These clusters are usually utilized for occupied Web sites where a few nodes have a similar website, and each new demand for a Web page is powerfully directed to a hub with a lower stack.
programs which are CPU-exhaustive that will set aside an over the top measure of opportunity to keep running on standard equipment.
This paper is organized as, section 2 contains The necessity for CR clustering, section 3-Cluster Types, section 4-Concept of System level Clustering, section 5- HIPECO applications, Clusters in HIPECO, HIPECO Cluster in Cloud Environment, Analysis of performance of various HIPECO Cloud Vendors, Case studies of HIPECO Cloud, section 6-Virtual Machines strategies, its problem endowment and solution followed by Conclusion and References.
II. THE NECESSITY FOR CR CLUSTERING
The cluster, for the most part 'talking, determines a situation, which ease load balancing by dispersing heap over different systems. It bolsters very high accessibility over occurrence level failure and gives a method for virtualization, going about as an element among which every last bit of IT framework by leasing resources is a profoundly detectable pattern. Cloud resource conditions are made and shared on interest, as indicated by customer determinations. Virtualization methods empower making resources when required and adaptably dealing with their arrangement. Such situations activities are performed once and after that engendered to the majority of the cluster's cases. These highlights output in a framework that penances effectiveness for very high accessibility and empowers flat adaptability. Limiting the costs address the issues of compelling administration of processing resource allotment (access to CPU, memory) and versatile information stockpiling administrations (virtual storage).
Shockingly, the displayed comprehension of the resource re-appropriating issue may demonstrate inadequate, particularly for associations in which utilizing CC resources comprises a monetary option in contrast to expansive scale interests in framework
(e.g., applications of serving variable-stack entrance). To appropriately work, the parts of business the Cloud economy display must consider the decrease of dependability that may result from:
• Lacking of power in the physical parts of the framework. (Be that as it may, for substantial data centers that uncover their resources in the CC model this issue isn't viewed as genuine thus organizations commonly work excess power and cooling frameworks just as numerous system associations with the outside world).
• Introduction of virtualization, which makes one more reflection layer among the equipment and the application. Because of its moderately higher level of refinement, this layer ought to be seen as an extra purpose of failover. The utilization of cutting-edge systems accessible through virtualization, for example, virtual machine movement, can cause extra solidness issues.
• Lack of power over topology of system and information about the physical system utilized as a mode for correspondence between VMs. This is a standout amongst the many imperative purpose for the decrease in security of application in Cloud constraints.
III. CLUSTER TYPES
A basic necessity in numerous establishments there is a need to guarantee high unwavering quality. In frameworks which are physical there exist across the board and viable answers for expanding application unwavering quality (notwithstanding enhancing their execution, e.g., by expanding handling throughput, lessening latencies, and so forth.) Such arrangements depend on the idea of a cluster, i.e., the capacity to make a framework comprising of a gathering of resources that work on a similar arrangement of business administrations (allocating a typical setup). In this setting it is imperative to create programming, which expects to identify and deal with capable administration disappointments, guaranteeing a orderly perspective of the cluster (concealing with its multifaceted nature so the client has the hallucination of utilizing a single example of a given administration).
By the usage of CR, the customers can expand the execution of their services [7]. It is because of the way that such architectures allow designation of dynamic resource. Cloud frameworks are especially speaking to establishments where interest for framework vacillates after some time and where guaranteeing appropriate administration execution amid times of heightened action would require huge infrastructural speculations, not generally legitimized. The task of Cloud frameworks is on the bases of the capacity to progressively change mappings among virtual and physical resources. In these frameworks specific consideration is given to empowering the clients to:
• Particularly mention the original configuration, e.g., the no. and essential virtual machines parameters.
• Particularly mention the association of storage areas.
System correspondences and its association (network topology format, its parameters and so forth.) pursue the standard of empowering just fundamental reachability of virtual PCs. Normally, this includes associating interfaces of Virtual Machine to a single (per-client) virtual LAN organize. The client will not be able to uphold the necessary settings of system.
Considering the exhibited viewpoints, it is hard to utilize current Cloud establishments for profoundly accessible situations that depend on complex application clustering instruments. Such situations regularly need to satisfy certain prerequisites identified with the infrastructure of the correspondence on which the clustered conditions work.
The accompanying subdivisions present two distinct ideas of making cluster frameworks
1. Application-Level Clusters–clustering [ALC] J2EE administrations dependent on the GlassFish Application [GFA] Server [9].
2. Hardware-Level Clustering [HLC] based on professional software used by large corporations – Sun Cluster [SC] [10].
ALC
nearby storehouses, keeping them in a state of harmony with the presently introduced applications. Figure 1 demonstrates the GFA clustering design and the advantages that this setup presents. DAS predominantly represents the managing part.
Figure 1. Runtime-centric viewpoint GFA clustering architecture
The system utilized in the GFA Server to deal with the cluster framework depends on the Shoal [12] venture. Shoal is a clustering structure based on java, empowering adaptation to non-critical failure alongside expanded infrastructural dependability and accessibility. The center administration of Shoal, called the Group Management Service (GMS), gives Java Virtual Machine forms the capacity to end up imparting individuals from a cluster. Its API guarantees coordination with any current gathering correspondence innovation, for example, JXTA [13], Clusters [14], and so forth. By actualizing the Shoal API, procedures can acquire warnings about events of cluster and execute some operations, including
• Transferring/accepting information to/from a cluster or a specific part of cluster.
• Getting warnings of other individuals' failures, joining and planned shutdowns (Shoal Cluster Notifications of Events).
GFA server utilizations GMS for automatic transaction recovery, in-memory replication, cluster health maintenance, and load-balancing and IIOP failover. Empowering GMS implies tuning in for
cluster events on a preconfigured multicast address and port. Few GMS-related functions can be balanced –it incorporates the quantity of retries on a shaky fizzled part, the timeout among failure recognition endeavors, and so on.
Uniformity in a GFA cluster infers a reliable adaptation of the application server (AS) and does not reach out to equipment functions or working framework points of interest. Thus, it is conceivable to cluster ASs introduced on various operating systems (e.g., Windows& Solaris). It is on the grounds that Shoal, the clustering system, depends on Java and consequently use its movability and OS-autonomy features. Then again, it ought to be seen that clustering in DAS does not depend on this component, rather basing on abstractions of lower level for example, SC.
The SC HA for GFAServer gives lofty accessibility, supplementing the lofty accessibility given by GFAServer. It makes DAS very accessible by executing it as a failover SC data service [15].
This product forces no necessities with respect to the system topology on which infrastructural parts work. Subsequently, it very well may be effectively utilized in Cloud environments where the client doesn't know about the format and setup of the virtual system
HLC
of basic business administrations. Sun Cluster likewise underpins essential dependability perspectives (HA administrations – High Availability). It incorporates the idea of failovers and adaptability. To take out single purposes of disappointment, Sun Cluster licenses repetitive parts (basically system and plate stockpiling associations) through its SAN setup. Solaris Cluster is a case of cluster programming that incorporates with the working framework's bit. Most cluster parts are kept running as would be expected OS forms, yet with ensured access to the association's information. Furthermore, there is an expansion known as the SC Geographic Edition, equipped for
taking care of complete establishment
disappointments at indicated areas. In such cases it is important to repeat information between remote regions in close constant, limiting the postpone engaged with continuing execution after identifying a failure. Figure 2 demonstrates the SC equipment structure.
It comprises of the accompanying parts:
• Multi host disks used for storage, which are shared between the existing nodes;
• Arrangement of removable media as gadgets recognized worldwide, for example, CD-ROMs and tapes
• Interconnection of clusters provides a channel for inter node communication;
• Interfaces which are organized publicly utilized by customer frameworks for get to information benefits of the cluster.
A classic environment of SC (Figure 2) forces some prerequisites in transit arrange interchanges are sorted out. This is an aftereffect of the various types of information exchanged with these associations. In environments of cluster, communication of diverse sorts is appropriated through assigned interfaces. Explicit interfaces of network are required for getting to general society arrange (association between an
application and a client), for speaking with shared capacity and for associations between cluster nodes (cluster interconnects). In addition, these interfaces are much of the time recreated so as to expand the dimension of correspondence unwavering quality and alleviate faults of specific physical interfaces.
Figure 2. Hardware components of Sun Cluster [17]
Interconnections of cluster comprise of the accompanying equipment parts [18]:
• The system cards of interface that live on every node cluster called Adapters.
• Switches that live out of the cluster nodes. Junctions perform go through and changing functions to empower associations among something other than 2 nodes. A dual-node cluster does not require Junctions on the
grounds that the nodes can be
straightforwardly associated with one another
through repetitive physical links.
Configurations comprising of multiple nodes require Junctions.
• Physical associations present between 2 network connectors or a connector and Junctions are called Cables.
In the clustered conditions, rapid, low-inertness links and protocols for internode correspondences are basic. The Sun Cluster interconnect can work on Gigabit Ethernet, Fast Ethernet, Sun Fire Link, or the Scalable Coherent Interface (SCI, IEEE 1596-1992), empowering superior cluster private interchanges Another kind of association comprises of Public Interfaces of Network over which customers have cluster interface. Each system connector card can associate with at least one open systems, contingent upon that the card has numerous equipment interfaces. Nodes are set to incorporate different open system interface cards. Contingent upon the setup different cards can be dynamic and fill in as failover reinforcements for each other. On the off chance that one connector falls flat, the Sun Cluster arrange multi pathing programming is conjured to deal with the disappointment of the damaged interface.
IV.CONCEPT – SYSTEM-LEVEL CLUSTERING
[SLC]
Introduced in past segment highlights of the two arrangements were used in the idea of applications clustering inside resources in Cloud. This expect enhancing the configuration of resource capabilities with the capacities to exactly determine the system architecture design that is utilized to guarantee correspondence between resources which are shared.
This model identifies with sorting out system interchanges in a cluster utilizing procedures of virtual system. This requires bolster for components empowering the development of system architectures with explicit designs and, all the more critically, affecting the specific virtual parameters of associations (QoS confinements).
The proposed arrangement is a virtual system topology the executive’s component satisfying the previously mentioned prerequisites. This condition
was structured as a feature of the work done on a Grid resource the board framework dependent on the idea of isolating infrastructures of virtual machines and distributing them into applications on a select rights premise [12]. The system oversees processing resources (VM with indicated CPU and memory access policies) just as network design and configurations of topology.
The offered abilities by management of network parts include:
• Defining virtual system architecture by associating interfaces of VM virtual systems. • Specifying essential association functions
(transfer speed, and so forth).
• Creating committed network services, for example, VM application and firewalls intermediaries dependent on OS pictures which are preconfigured.
The essential part which has exhibited arrangement is the capacity to change the arrangement of physical format while saving the virtual associations parameters. This task is performed utilizing the VM technique used for migration and can be executed self-sufficiently. Virtual Machine movement is a fairly direct process which gives reallocation of computational resources. In any case, assurance of the arrangement of the systems administration parts, with the goal that the client low-level system prerequisites are fulfilled and the base system resources that are assigned is a non-paltry undertaking.
extensive number of committed, repetitive system associations among physical PCs on which VMs work) for the cluster to satisfy its proposals and prerequisites, giving expanded dependability to applications running in infrastructures of Cloud.
Permitting end clients to determine strategies identified with building and streamlining system topologies is, in the authors' assessment, a characteristic development of infrastructures present in cloud. It is likewise essential for IT associations which utilize these conditions as a method for re-appropriating resources in help of business objectives.
V. HIGH PERFORMANCE COMPUTING
(HIPECO)
HIPECO assumes a vital job in both logical headway and financial aggressiveness [1] of a country - making creation of logical and mechanical arrangements quicker, more affordable, and of best quality. It is a key part in numerous applications: planning vehicles and planes; structuring tall structures and extensions; revelation of medications; disclosure and extraction of new vitality sources like flammable gas and oil; climate determining; and some more. HIPECO requires high handling capacity to register to a great extent complex logical application. The pay-as you-go processing benefits has been an industry objective for a long time beginning from cluster and main frame.CC takes grid computing to an unheard-of level by utilizing virtualization to typify a working operating system occurrence and run it in a cloud at whatever point they require computational resources. Likewise, storage of Cloud can likewise be utilized freely with operating system instances. CC additionally gives boundless storage and in a split second accessible and versatile figuring resources, all at a sensible expense which is metered. Likewise, Cloud having extensive data centers which is appropriate for information concentrated applications.
5.1 Applications of HIPECO In Cloud
In the expanding interest for superior, effectiveness, readiness and lower cost [19], since quite a while, data correspondence innovation are drastically modifying from static storehouses with physically overseeing applications and resources, towards virtual dynamic situations with computerized and shared administrations, for example from storehouse situated to benefit arranged architectures [20]. The "traditional" cloud characteristics are appealing to the common crowd. These offers include inexactly coupled examples (occurrence of an OS executing in a virtualized situation) and storage frameworks sponsored by Service Level Agreements (SLAs) which are single, that give the end client ensured dimensions of service.
These type of clouds offer the accompanying highlights: Moment accessibility of resources is available in cloud which is referred as Instant Availability, In a split-second user can scale the quantity of utilizations inside the cloud of Large Capacity, Configuration occurrences to suit their necessities from the OS up by users Software Choice, Instances can be effectively moved to and from comparable cloud using virtualized technique.
Tuned Hardware, Storing of the HIPECO is frequently intended for any application set and client based Tuned Storage. All HIPECO frameworks utilize a batch scheduler which enables the sharing of resources which are restricted is known as Batch Scheduling.
Contingency upon the client's space of application can have a major effect in execution. For this situation, the client may have only one program which must be kept running with a broad scope of information functions (frequently called parametric preparing), or they may have flow of data occupations, for example, the Galaxy suite utilized in study of biomedical field. Such sorts of utilizations can be profited by most CC resources. A few applications can use exceptionally correspondent frameworks yet don't require an interconnect which has high-performance or quick storage.
One regularly refers to precedence is advanced exhibition, in which numerous non-cooperating functions can be brought forth over an expansive number of nodes with practically impeccable adaptability. These types of applications frequently function admirably with standard Ethernet and don't need a specific interlink for superior. Moving towards the HIPECO tree, one will find sensitive-interconnect applications which need low idleness and interconnects with maximum throughput are not present in clouds which are conventional. Without a doubt, a large portion of interconnects (e.g., Ethernet of High-Performance and Infini Band) requires "client space" correspondence pathways that don't include the OS piece. This strategy has the utilization of cloud virtualization troublesome in light of the fact that most virtualization plans can't oversee "kernel bypass" applications (i.e., these are "on the wire" information exchanges that are difficult to virtualize). On the off chance that High-Performance systems cannot be accessible, numerous HIPECO applications run gradually and experience the ill effects of poor
versatility. Additionally, in the HIPECO tree are numerous applications that are I/O sensitive which without a quick subsystem of I/O, will execute gradually due to storage bottlenecks.
R-HIPECO, Penguin, Univa, Gompute, Amazon, SGI, and Sabal core offer particular HIPECO clouds. IBM is remarkably missing who, right now, is not offering
open HIPECO clouds. The organization,
notwithstanding, provides numerous choices for developing inner or private.
5.2 Clusters in HIPECO
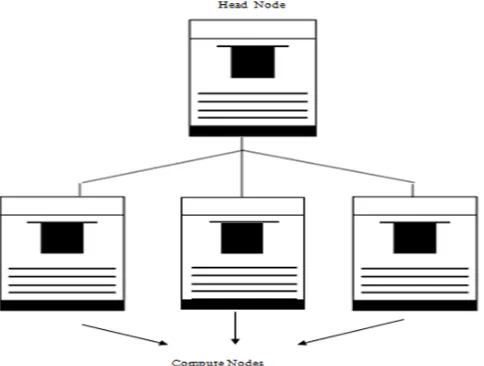
A PC of high-performance fitting for most little and moderate-sized organizations in these days is worked from what are fundamentally numerous common PCs associated together with a system and midway planned by some unique programming. Since the PCs are typically physically exceptionally near one another, the basic term for a superior PC in these days is a cluster [21]. The essential cluster-based structure processing is appeared in the below figure
Figure 3. The representation of basic structure of cluster
HIPECO clusters are portrayed in numerous processors and centers, huge memory, rapid systems administration, and expansive information stores all common crosswise over many servers which are rack-mounted. Jobs are those sort of client programs that continuously run on a cluster, and which are regularly overseen through a lining framework for ideal use of every single accessible resource. A
HIPECO cluster consists of numerous servers which are separate, called nodes, conceivably completing a whole data center with many for racks which are
power-hungry. HIPECO ordinarily includes
recreation of numerical models or examination of information which is logical. At the center of HIPECO is sensible equipment and frameworks programming squabbled by frameworks software engineers, which enable analysts to give their vitality to their code.
A fruitful HIPECO cluster is a ground-breaking resource in an association. In the meantime, these ground-breaking racks present are source which is multifaceted to oversee. If not appropriately oversaw, intricacy of software, cluster development, adaptability, and framework diversity can present undertaking setbacks and diminish the general profitability of an association.
An effective HIPECO cluster expects heads to arrangement, oversee, and screen a variety of equipment and programming parts. Clusters are the prevalent kind of HIPECO equipment nowadays; a cluster is a lot of Massively Parallel Processors (MPPs). A cluster contains a processor which is ordinarily alluded to as a node and has a memory of itself, Central Processing Unit, working framework, and subsystems of I/O which is equipped for speaking with different nodes.
5.3 HIPECO Cluster in a Cloud Environment
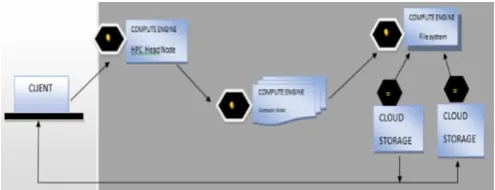
Figure 4. Cloud Environment Cluster
The processing portion of the HIPECO cluster comprises of a Head Node managing software and running planning on a Google Compute Engine (GCE) Virtual Machine. The figure/specialist nodes are additionally running on GCE Virtual Machines. C Sizes of cases can be selected to manage the remaining burden. Such decisions include Standard, High Memory or CPU occurrences in center sizes of 1, 2, 4, 8 or 16. Examples of this sort can be either taken into consideration or erased depending on the resources necessary. The client has different loads of business decisions or programming of open source segments to preparation of clusters.
Compute Engine Virtual Machines can similarly be utilized to create a document of cluster framework, 2 mainstream choices are Gluster and NFS. Cloud Storage of Google gives the cluster backend storage. It is a highly retrieving capacity alternative settling on it a great choice for HIPECO work. Google Cloud SQL is similarly used for information organization. This information can be moved by the user specifically into Storage of cloud or be shifted with the activity.
5.4 Analysis of Performance of Various HIPECO Cloud Vendors
In this section we discussed about the analysis of various HIPECO cloud vendor’s performance.
5.4.1 Penguin Computing [PC]
One the principal sellers to present a genuine HIPECO cloud was PC [23]. The POD(POD), was one of the main remote HIPECO administrations. Since the earliest starting point, POD cloud has been
an uncovered metal register show like a cluster of in-house. Virtualized login node is given to ever client that does not assume a job in execution of code. The typical figure hub has a scope of choices, which includes double 4-center Xeon, double 6-center Xeon, or quad 12-center processors of AMD extending in speed from 2.2 to 2.9GHz with twenty four to one hundred and twenty eight GB of Random Access Memory for each server and till 1Tera Byte from the very beginning near the storage of each node.
To make applications running on POD HIPECO cloud can be very basic, since Penguin has in excess of one hundred and fifty business and public source applications introduced and prepared to keep running on the framework. Introducing different applications is clear and accessible to clients. Nodes with two NVidia Tesla C2075 registering processors are accessible.
As far as system, POD nodes are associated through non-virtualized, low-idleness 10Giga byte Ethernet (GigE) or QDR IB systems. The system infrastructure is neighborhood to guarantee most extreme data transfer capacity and least dormancy between these nodes. Storage frameworks are accessible through 10GigE to the neighborhood process cluster. Moreover, POD has excess rapid Internet with remote network running speed of 50Mbps to 1Gbps.
A few storage choices are likewise accessible, beginning with rapid NFS utilizing 10GigE appended storage. Past NFS, there are parallel document framework alternatives connected by means of different 10GigE connections and InfiniBand. Panasas
and Lustre High-Performance frameworks
additionally can be given. At long last, committed capacity servers are accessible. These frameworks can
segregate information and encourage
POD offers a set of instruments to help deal with your calculation. Apropos called POD Tools, Penguin offers an accumulation of order line utilities for connecting with their HIPECO cloud. Past the standard SSH login, POD Tools give the ability to submit occupations, exchange information, and create reports. Also, Penguin POD can be consistently coordinated into existing nearby clusters to redistribute overabundance outstanding tasks at hand – frequently known as "cloud bursting." All these abilities are encoded and offer a high state of security.
Maybe PODs greatest resource is a big history of conveying nearby HIPECO arrangements. This experience has enabled them to build up an industry of staff area specialists. Likewise, they have not insignificant rundown of extra services that are placed in the place of their POD offering. These incorporate premises on arrangement of bursting of cloud to the POD cloud, remote administration of premises on HIPECO administrations, cloud relocation administrations, private remote HIPECO as administration situations, and private interior clouds.
5.4.2 R-HIPECO
It [24] offers R-Cloud, wherein customers can "lease" HIPECO resources. The R-Cloud offers 2 different processing situations. The main is a Cluster which is shared, that provides a login to those nodes which are and have a work line. This environment is an exemplary cluster condition and is basically a "shared cluster in the sky." Customers are charged by the activity, making a pay as-you go HIPECO benefit. No help or organization administrations are given. The 2nd environment includes virtual clusters which are private that are cut out of a mutual arrangement. Use can be on-request with VLAN get to. These frameworks are charged on an all day, every day premise.
R-HIPECO can give new 3.4GHz quad center-based Sandy Bridge frameworks with RAM/node of 16GB(4GB/center), DDR 2:1 blocking Infini Band, and 1TB of local disk. Also, they have double attachment 2.6GHz eight-center Sandy Bridge with
128GB of Random-Access Memory/hub
(8GB/centre), QDR non-blocking Infini Band, 1TB of nearby storage, and 1TB worldwide capacity. These contributions are adjusted by Magny-Cours, Nehalem, and Harper town frameworks. CPU-based frameworks in beta test are accommodated for devoted clients.
Many applications can be tuned to be fully operational inside one day (despite the fact that R-HIPECO noticed that permitting issues can defer the procedure for a few clients). Like Penguin's items, all High-Performance frameworks likewise can be given. At last, committed capacity servers are accessible. These frameworks can disconnect information and encourage encryption or decryption of inflated volumes of information by utilizing dispatching which is physical as opposed to Internet exchange.
VI.VIRTUAL MACHINES
CC has fundamentally three models like Software as a Service (SaaS) [25] Infrastructure as a Service (IaaS) [1], and Platform as a Service (PaaS). SaaS is a sort of administration, where the client makes use of the applications over Internet without introducing or looking after programming. PaaS is another sort of administration, in which client utilizes the creating conditions to create, run and oversee application without trouble of making and looking after condition. IaaS is sort of administration in which client can utilize the entire framework as they claim it, just thing is establishment, setup and upkeep taken care of by mists specialist co-ops.
applications on these very same resources which are physical. It is a principle invaluable of virtualization methods in serving increasingly simultaneous errands to accelerate time execution and viably utilize entire equipment gadgets. Hypervisor is a program that goes about as an operator, to map virtual programming application to real equipment [27]. Hypervisor is a kind of program that goes about as an operator, to map virtual programming along with applications to real equipment [28]. Hypervisor is otherwise called as a virtual machine monitor (VMM). It is a Hypervisor's obligation to assign and discharge resources when required. Anyway, hypervisor ensure that singular application or procedure live on same equipment can't interrupt each other. Now, firewall is been an essential piece of all kind of system framework and gadgets; SDN or TNA both have an alternate system innovation however the center usefulness of both is same to give availability between system gadget and oversee traffic crosswise over them.
Hypervisor has for the most part two sorts- hosted and bare metal or native. Bare metal kind of Hypervisor maps straightforwardly visitor frameworks over resources. Hyper-v, Xen are exposed metal hypervisor. Hosted hypervisor keeps running on working framework same as should be expected PC working framework. VMware workstation, VirtualBox is facilitated hypervisor [28].
There are a wide range of Virtual Machine portion arrangements. Each one has its own profitable and limitations. B Shrimali et al. [29] recorded a part of systems like execution, vitality, system, and based on SLA. To take most extreme advantages of SDN, the difficulties ought to be recorded with the goal that proper security component can receive consistently. From a key perspective, SDN security susceptibilities are focused on its 3 designs [30].
A. Performance: This is one among the difficulties of CC, which should be viewed as and when characterization of VM assignment systems is done. From client’s perspective execution is absolute first part of cloud benefit. Cloud specialist co-ops essential thought process is to accomplish 100%performance; however, it is difficult to achieve 100%. Since performance is impact by system, simultaneous ward forms, VM relocation and so on. S. Shirinbab et al. [31] presented a unique methodology of the over-allotment where the physical CPU centers are treated instead as vCPU centers. It gives us more Virtual Machine arrangement contrasted with firmly time-sharing Virtual Machines. Henceforth, the execution of progressively parallel assignment is done to improve the execution. MB Nagpure et al. [32] shared a dynamic resource distribution dependent on dissymmetry. The dissymmetry calculation estimates irregularity in condition, additionally it anticipates the load of future by using calculation of Fast Up and Slow Down (FUSD). The above framework if utilized properly can be used to present the challenges of security in SDN.
bin-packing calculation. The straight whole number program lessens the energy utilization through union.
C. Network: Processes which are Data-intensive regularly needs to communicate much of the time with database. This influences the system execution, so it is better to diminish organize dormancy and movement of VMs because of sudden breakdown of system. LA Rocha et al. [34] presented a methodology of Mixed Integer Linear Programming (MILP). Reenactment of MILP Flow gives best courses to arrange traffic. Z Zhuang et al. [35] has proposed OCPA (Opportunity Cost based VM situation and Assignment) which appoint clients Virtual Machine dependent on client populace, with the goal that much of the time imparting VMs are serve nearer to one another.
D. Service Level Agreements (SLA): SLA given by specialist of cloud organization to better functionality and client trust. Which incorporates Quality of Service (QOS), reaction time, downtime? At times SLA is disregarded by specialist of cloud co-ops to guarantee better execution with satisfactory punishments. A McConnell et al. [36] proposed a novel methodology of Innkeeper structure for n-level applications. Focal Innkeeper of cloud go about as an agent and gives versatile and dynamic chain of importance to the SLA-agreeable VM situation. W Iqbal et al. [37] portrayed issue of bottleneck discovery and the goals of multi-level Web application. Approach gives most extreme reaction time to web application proprietors while lessens the usage of resource.
6.1 Issue Endowment and Its Resolution
CC gives an approach for assigning a few VMs that continuously run on the physical machine. This permits an increase in the number of uses and
administrations that keep running at same time to accomplish greater profitability and increased benefit rate for cloud specialist co-ops. In order to have the advantages, legitimate designation strategy must be utilized to lessen relocation of machines, evade over-burden on single physical machine, less vitality utilization and so forth.
The process of allotment of virtual machines along with resources handles the newly occurred resources or virtual machines and then inquires and allocates them to those physical machines that have ample amount of resources to satisfy. Yet, the VM portion isn't exactly as basic as it appears, ill-advised assignment prompts starvation of resources, few hosts are over-burdened while different hosts are least or under stacked. These kinds of issues debase the general execution of cloud [38]. Relocation of VM is needed to overcome this problem, which additionally is not a great plan to move the machine that is running to another one.
Another problem is keeping harmony between various parameters of the cloud like execution, vitality utilization, SLA infringement and so on. At some point cloud specialist co-ops ready to give superior however it leads to more utilization of vitality, which specifically leads to a staggering expense rate. Once in a while sparing energy lessens execution.
6.1.2 Solution
For taking care of the allocation of VM issues in cloud and enhancing clustering adaptability ended up valuable technique. The physical machines are then together assembled to shape various clusters. Each and every host under the same cluster has the same highlights to satisfy the newly arrived VM. In data centers that are customary it is difficult to distinguish have in light of the fact that each time when a new demand enters there has to be a check on each host for designation. Although, through an approach of clustering, once clusters are made then new VM ask for the search of hosts that are properly accessible into clusters instead of checking for singular host use. This then serves to effectively look for accessible data centers resources. Virtual Machines which are under clustering are easy to maintain, configure and monitor.
VII. CONCLUSION
In this paper we have investigated about necessity of clustering and its types with their architectures and concept of system level clustering and offered abilities. We have also discussed about HIPECO its application in cloud and clusters in it, and behavior of HIPECO Cluster in a Cloud Environment, Analysis of Performance of Various HIPECO Cloud Vendors using Penguin computing-HIPECO and about the case studies of HIPECO Cloud. Additionally, we have discussed about the VM strategies, problem
formulation and Solution. We have thoroughly investigated about cloud cluster in application clusters, HIPECOs and also in the VMs.
VIII.REFERENCES
[1] . Sahba, A., & Prevost, J. J. (2016). Hypercube
based clusters in CLOUD COMPUTING. 2016
World Automation Congress (WAC).
doi:10.1109/wac.2016.75829741111111
[2] . Y. Jadeja, K. Modi,(2012) “CLOUD
COMPUTING - Concepts, Architecture and Challenges”, International Conference on Computing, Electronics and Electrical Technologies [ICCEET], 2012.
[3] . Kosinska, J., Kosinski, J., & Zielinski, K. (2010).
The Concept of Application Clustering in CLOUD COMPUTING Environments: The Need for Extending the Capabilities of Virtual Networks. 2010 Fifth International Multi-Conference on Computing in the Global
Information Technology.
doi:10.1109/iccgi.2010.34
[4] . Peter Mell and Tim Grance. (2009)The NIST
definition of CLOUD COMPUTING. Jul 2009.
[5] . Intalio|Cloud Home Page:
http://www.intalio.com. Accessed Jun 2010.
[6] . Amazon EC2 Home Page:
http://aws.amazon.com/ec2. Accessed May 2010.
[7] . Michael Armbrust, Armando Fox, Rean Griffith,
Anthony D. Joseph, Randy H. Katz, Andrew Konwinski, Gunho Lee, David A. Patterson, Ariel Rabkin, Ion Stoica, and MateiZaharia. (2009)Above the clouds: A berkeley view of CLOUD COMPUTING. Technical Report
UCB/EECS- 2009-28, EECS Department,
University of California, Berkeley, February 2009
[8] . Douglas Parkhill.(1996) The Challenge of the
[9] . Liang-Jie Zhang and Qun Zhou.(2009)CCOA:
CLOUD COMPUTING Architecture. IBM T.J. Watson Research Center. Proc. of IEEE International Conference on Web service,July 2009.
[10] . Sun Cluster Home Page:
http://www.sun.com/software/solaris/cluster Accessed Jun2010.
[11] . Xuekun Kou.(2009)GlassFish Administration. Administer and configure the GlassFish v2 application server. 2009 PacktPublishing.
[12] . Joanna Kosińska, Jacek Kosiński, and Krzysztof
Zieliński.(2009)Virtual grid resource
management system with virtualization technology. Proc. of The Conference of the
High-Performance Computers’ Users,
March2009.
[13] . JXTAHomePage:
http://jxta.dev.java.net.AccessedApr2010.
[14] . JGroupsHomePage:
http://www.jgroups.org.AccessedApr2010.
[15] . Sun Microsystems. Sun Cluster Data Service for
Sun Java System Application Server Guide for Solaris OS. Sun Developer Network. Technical Article. December2006.
[16] . Richard Ellinga and Tim Read.(2001) Designing
Enterprise Solutions with Sun Cluster 3.0. The official Sun Microsystems Resource Series. 2001.
[17] . SunMicrosystems.SunClusterOverviewforSolari
sOS.April2004.
[18] . Sun Microsystems. Sun Cluster Concept Guide
for Solaris OS. Dec2006.
[19] . Sajay K R, &Babu, S. S. (2016). A study of
CLOUD COMPUTING environments for High-Performance applications. 2016 International Conference on Data Mining and Advanced
Computing (SAPIENCE).
doi:10.1109/sapience.2016.7684127
[20] . Costaa,P.,Cruzb, (2015) A.:Migration to
Windows Azure- analysis and
comparison.In:CENTERIS 2012-Conference on ENTERprise Information Systems/HCIST 2012
–
InternationalConferenceonHealthandSocialCar
e Information Systems and
Technologies.Procedia Technol. 5, 93–102 (2012)
[21] . http://www.wzl.rwth-aachen.de/en/index.html
[22] . Google
Apps.http://www.google.com/apps/intl/en/busi ness/cloud.html
[23] . Penguin Computing on
Demand.http://www.penguincomputing.com/se rvices/HiPeCo-cloud/POD
[24] . R-Cloud.http://www.r-HiPeCo.com/
[25] . Rajani, V., Shrimali, B., & Gohil, B. (2016). A
VM allocation strategy for cluster of open host in cloud environment. 2016 International Conference on Advanced Communication
Control and Computing Technologies
(ICACCCT).doi:10.1109/icaccct.2016.7831704 R ajani, V., Shrimali, B., & Gohil, B. (2016). A VM allocation strategy for cluster of open host in cloud environment. 2016 International Conference on Advanced Communication
Control and Computing Technologies
(ICACCCT). doi:10.1109/icaccct.2016.7831704.
[26] . Dillon, Tharam, Chen Wu, and Elizabeth
Chang.(2010)"CLOUD COMPUTING: issues and challenges." Advanced Information Networking and Applications (AINA), 2010 24th IEEE International Conference on. Ieee, 2010.
[27] . Perez-Botero, Diego, Jakub Szefer, and Ruby B.
Lee. "Characterizing hypervisor vulnerabilities in CC servers." Proceedings of the 2013 international workshop on Security in CLOUD COMPUTING. ACM, 2013.
[28] . Peng, Junjie, et al. "Comparison of several
[29] . Shrimali, Bela, and Hiren Patel.(2015)
"Performance Based Energy Efficient Techniques For VM Allocation In Cloud Environment." Proceedings of the Third International Symposium on Women in Computing and Informatics. ACM, 2015.
[30] . Xie, Ruitao, et al. "Energy saving virtual
machine allocation in CLOUD
COMPUTING.(2013)" Distributed Computing Systems Workshops (ICDCSW), 2013 IEEE 33rd International Conference on. IEEE, 2013.
[31] . Shirinbab, Sogand, and Lars
Lundberg.(2015)"Performance implications of over-allocation of virtual CPUs." Networks, Computers and Communications (ISNCC), 2015 International Symposium on. IEEE, 2015.
[32] . Nagpure, Mahesh B., Prashant Dahiwale, and
PunamMarbate.(2015) "An efficient dynamic
resource allocation strategy for VM
environment in cloud." Pervasive Computing (ICPC), 2015 International Conference on. IEEE, 2015.
[33] . Ghribi, Chaima, MakhloufHadji, and
DjamalZeghlache.(2013)"Energy efficient vm scheduling for cloud data centers: Exact allocation and migration algorithms." Cluster,
Cloud and Grid Computing (CLOUD
COMPUTINGGrid), 2013 13th IEEE/ACM International Symposium on. IEEE, 2013.
[34] . Rocha, L. A., and F. L. Verdi.(2015) "A
Network-Aware Optimization for VM
Placement." Advanced Information
Networking and Applications (AINA), 2015 IEEE 29th International Conference on. IEEE, 2015.
[35] . Zhuang, Zhenyun, and Chun Guo. (2013)
"OCPA: An Algorithm for Fast and Effective Virtual Machine Placement and Assignment in Large Scale Cloud Environments." CLOUD COMPUTING and Big Data (CloudCom-Asia), 2013 International Conference on. IEEE, 2013.
[36] . McConnell, Aaron, et al.(2012) "A
SLA-compliant Cloud resource allocation framework for N-tier applications." Cloud Networking (CLOUDNET), 2012 IEEE 1st International Conference on. IEEE, 2012.
[37] . Iqbal, Waheed, Matthew N. Dailey, and David
Carrera.(2010)"Sladriven dynamic resource management for multi-tier web applications in a cloud." Cluster, Cloud and Grid Computing
(CLOUD COMPUTINGGrid), 2010 10th
IEEE/ACM International Conference on. IEEE, 2010.
[38] . Xiao, Zhen, Weijia Song, and Qi Chen.(2013)
"Dynamic resource allocation using virtual
machines for CLOUD COMPUTING
environment." Parallel and Distributed Systems, IEEE Transactions on 24.6 (2013): 1107-1117
Cite this article as :
Kranthi Kumar. K, R. Rindha Reddy, Kurumaddali Sushmitha, "A Manifestation of Cloud Computing Environments for Application Clusters, High-Performance Clusters and Allocation strategies for Virtual Machines", International Journal of Scientific Research in Computer Science, Engineering and Information Technology (IJSRCSEIT), ISSN : 2456-3307, Volume 5 Issue 3, pp. 596-612, May-June 2019. Available at doi :
https://doi.org/10.32628/CSEIT1953145

![Figure 2. Hardware components of Sun Cluster [17]](https://thumb-us.123doks.com/thumbv2/123dok_us/1049508.1131254/6.595.310.552.183.295/figure-hardware-components-sun-cluster.webp)