CSEIT1831201 | Received: 02 July 2016 | Accepted: 25 July 2016 | July-August 2016 [(1)1: 98-107 ]
International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2016 IJSRCSEIT | Volume 1 | Issue 1 | ISSN : 2456-3307
98
Systematic Component Clustering Scheme for Collective
Objects through Micro - Clusters
M. Shailaja
1,Dr. S.Vijay Bhanu
21Ph.D Scholor, Department of Computer Science And Engineering, Annamalai University, Annamalai
Nagar,Chidambaram,Tamilnadu, India
2Professor, Department of Computer Science And Engineering, Annamalai University, Annamalai
Nagar,Chidambaram,Tamilnadu, India
ABSTRACT
We extend and assess another procedure to address this problem for miniaturized scale bunch essentially based calculations. We present the idea of a common thickness chart which expressly catches the thickness of the one of a kind data between small-scale bunches for the length of grouping after which indicate how the diagram might be utilized for reclustering miniaturized scale groups. This is a particular approach on account that fairly on relying on presumptions about the dissemination of records directs doled out toward a microcluster (frequently a Gaussian dispersion cycle a center), it appraises the thickness in the mutual area among microclusters immediately from the records. To the top notch of our understanding, this paper is the first to propose and explore utilizing a common thickness principally based reclustering procedure for records course grouping. In this paper, we advocate a fresh out of the plastic new information-theoretic troublesome calculation for work/state bunching and utilize it on content sort. Existing strategies for such "distributional bunching" of words are agglomerative in nature and result in (I) sub-best word bunches and (ii) high computational expense. With a specific end goal to expressly catch the optimality of word groups in an certainties theoretic system, we initially determine a universal standard for work grouping. We at that point blessing a speedy, disruptive arrangement of tenets that monotonically diminishes this objective trademark expense. We show that our arrangement of tenets limits "within bunch Jensen-Shannon dissimilarity" in the meantime as at the same time boosting the "between-group Jensen-Shannon uniqueness". As opposed to the beforehand proposed agglomerative techniques our troublesome arrangement of standards is significantly quicker and accomplishes similar or higher class correctnesses. We additionally show that element grouping is a viable approach for building littler style models in the progressive sort. We show unmistakable trial impacts the use of Naive Bayes and Support Vector Machines at the 20Newsgroups records set and a three-level progressive system of HTML documents amassed from the Open Directory challenge.
Keywords : Data mining, data stream clustering, density-based clustering. Information theory, Feature Clustering, Classification, Entropy, Kullback-Leibler Divergence, Mutual Information, Jensen-Shannon Divergence.
I.
INTRODUCTION
Bunching insights streams have to wind up a basic approach for records and know-how designing. An actualities stream is a requested and likely unbounded arrangement of records factors. Such
by and large refined as a two-arrange procedure with a web part which compresses the data into numerous miniaturized scale groups or matrix cells and afterward, in a disconnected system, those small-scale bunches (cells) are reclustered/blended directly into a little wide assortment of conclusive groups. Since the reclustering is a disconnected procedure and in like manner now not time imperative, it's far usually not specified in detail in papers about new actualities flow grouping calculations. Most papers encourage to apply an (every so often scarcely changed) display conventional bunching set of guidelines (e.G., weighted alright technique in CluStream ) where the small scale groups are utilized as pseudo variables. Another strategy used in DenStream is to utilize reachability where every single small scale group which may be less than a given separation from each other are associated by and large to frame bunches. Matrix based calculations regularly consolidate nearby thick framework cells to shape bigger groups (see, e.G., the first model of D-Stream and MR-Stream,). A not irregular, and frequently overpowering, normal for content data is it's to a great degree exorbitant dimensionality. Normally the record vectors have molded the utilization of a vector-territory or sack of-words demonstrate (Salton and McGill, 1983). Indeed, even a modestly measured report arrangement can cause a dimensionality in hundreds. For instance, surely one of our test certainties sets contains 5,000 web pages from www.Dmoz.Org and has a dimensionality (vocabulary measure subsequent to pruning) of 14,538. This intemperate dimensionality might be an exceptional obstruction for class calculations essentially in light of Support Vector Machines, Linear Dis-criminant Analysis, alright closest neighbor et cetera. The issue is exacerbated while the reports are composed in a pecking order of preparing and a total trademark classifier is completed at every hub of the chain of importance. An approach to decrease dimensionality is the guide of the distributional grouping of words/abilities (Pereira et al., 1993, Baker and McCallum, 1998, Slonim and Tishby, 2001). Each
expression group would then be able to be dealt with as a solitary element and as needs are dimensionality might be broadly diminished. As demonstrated by Baker and McCallum (1998), Slonim and Tishby (2001), such trademark grouping is additional intense than trademark selection(Yang and Pedersen, 1997), especially at bring down a number of highlights. Likewise, regardless of whether dimensionality is diminished through as parcels as two requests of significant worth the resulting compose precision is like that of a full-work classifier. In fact, in a few occasions of little training units and loud highlights, state bunching can genuinely development compose exactness. However, the calculations created through both Baker and McCallum (1998) and Slonim and
to for all time keep the majority of the realities in the course which suggests that rehashed arbitrary access to the certainties is infeasible. Additionally, insights streams flaunt thought coast during that time wherein the area as well as type of groups alterations, and new bunches may likewise show up or existing bunches vanish. This makes the use of existing bunching calculations intense. Information development grouping calculations limit records access to a solitary skirt the certainties and adjust to thought skim. In the course of the most recent 10 years numerous calculations for bunching data streams were proposed. Most records stream bunching calculations utilize a - organize on-line/disconnected technique:
1) Online: Summarize the insights the utilization of an arrangement of k0 microclusters arranged in a space-proficient certainties shape which moreover allows quick query. Smaller scale bunches are delegates for units of comparable actualities focuses and are made the use of an unmarried disregard the records (commonly progressively when the data development arrives). Smaller scale bunches are typically spoken to by utilizing group offices and additional insights as weight (thickness) and scattering (difference). Each new measurements point is relegated to its nearest (in expressions of a comparability highlight) smaller scale group. A few calculations utilize a framework on the other hand and non-discharge network cells constitute microclusters. On the off chance that another records point can't be doled out to a present miniaturized scale group, a fresh out of the box new microcluster is made. The calculation can likewise do a couple of home undertakings (consolidating or erasing microclusters) to keep the assortment of miniaturized scale bunches at an achievable size or to wipe out commotion or realities past because of idea stream. 2) Offline: When the buyer or the application requires a grouping, the k0 small scale bunches are reclustered into (alright _ k0) last bunches now and again known as large-scale bunches. Since the
where k is the amount of expression groups (normally approve _ m), and t is the scope of cycles (typically t = 15 by and large).
III.
THE DBSTREAM ONLINE COMPONENT
Average miniaturized scale bunch based absolutely insights course grouping calculations keep the thickness inside each smaller scale bunch (MC) as a couple of state of weight (e.G., the scope of things doled out to the MC). A few calculations additionally catch the scattering of the components with the valuable asset of recording fluctuation. For reclustering, at the same time, best the separations among the MCs and their weights are utilized. In this putting, MCs that are nearer to each one of a kind are substantially more liable to end up plainly inside the indistinguishable group. This is even real if a thickness based completely set of directions like DBSCAN [10] is utilized for reclustering considering ideal here best the situation of the MC focuses and their weights are utilized. The thickness inside the region among MCs isn't to be had in light of the fact that it isn't held all through the online degree. The fundamental idea of this work is whether we will grab no longer handiest the hole among abutting MCs however also the availability utilizing the thickness of the specific data in the region some of the MCs, at that point the reclustering impacts might be advanced. In the consequent we expand DBSTREAM which remains for thickness based circle grouping.
3.1 Leader-based Clustering
Pioneer based absolutely grouping was conveyed by utilizing Hardigan as a customary bunching calculation. It is straightforwardly ahead to utilize the idea to records streams (see, e.G., ). DBSTREAM speaks to each MC through a pacesetter (a data point characterizing the MC's center) and the thickness in a region of somebody specific range r (limit) all through the inside. This is much similar to DBSCAN's idea of checking the components is an eps-organize, notwithstanding, legitimate ideal here
the thickness isn't generally expected for everything, except best for each MC which should resultseasily be possible for spilling insights. Another measurements issue is appointed to a present MC (boss) if it's far inside an intense and fast span of its middle. The appointed part will build the thickness those recently formed MCs are most more then likely now not best for the bunching. To cure this issue, we utilize a forceful examining approach got to transport the MC focuses inside the way of each recently appointed component. To control the cost of the movement, we utilize a group trademark h() simply like self-arranging maps [27]. In our execution we utilize the notable Gaussian system work depicted among focuses, an and b.
3.3 Capturing Shared Density
Catching shared thickness instantly in the online perspective is a current thought presented on this paper. The truth, that amid thick districts MCs can have a covering challenge area, might be utilized to degree thickness among MCs with the guide of tallying the elements which is most likely allowed to 2 or additional MCs. The idea is that high thickness inside the crossing point put in respect to the unwinding of the MCs' region way that the two MCs share an locale of unbalanced thickness and must be a piece of the same microcluster. In the occurrence in Figure 2 we see that MC2 and MC3 are close to each unique and cover. Be that as it may, the mutual weight s2;three is little in contrast with the heaviness of everything about two included MCs demonstrating that the 2 MCs do never again shape an unmarried district of unbalanced thickness.
Calculation 1 demonstrates our approach and the utilized grouping measurements frameworks and individual assigned parameters in detail. Small-scale bunches are spared as an immovable MC. Each miniaturized scale bunch is spoken to through the tuple (c;w; t) speaking to the group center, the group weight and the last time it progressed toward becoming a la mode, separately. The weighted contiguousness posting S speaks to the meager shared thickness chart which catches the weight of the information factors imparted to the guide of MCs. Since shared thickness gauges are likewise worried to blurring, we moreover spare a timestamp with each passage. Blurring likewise shared thickness gauges is fundamental in see that MCs are permitted to transport which during that time may cause appraisals of crossing point districts the MC isn't ensuring any longer. The client focused on parameters r (the sweep around the focal point of an MC inside which actualities elements might be doled out to the group) and _ (the blurring expense) are a piece of the base arrangement of principles. _, gap and win are parameters for reclustering and memory administration and could be talked about later. Refreshing the bunching through including another record guide x toward the grouping is characterized by Algorithm 1. In the first place, we discover all MCs for which x falls inside their sweep. This is the same as asking which MCs are an insider from x, that is the fixed radius closest neighbor issue which might be effectively comprehended for data of low to direct dimensionality [22]. On the off chance that no neighbor is found then another MC with a weight of one is made for x (line four in Algorithm 1). On the off chance that at least one associates are watched then we supplant the MCs by utilizing making utilization of the exact blurring, developing their weight and afterward we endeavor to move them towards x utilizing the Gaussian neighborhood work h() (follows 7– 9). Next, we supplant the common thickness diagram (follows 10– thirteen). To spare you falling MCs, we restrict the development of MCs on the off chance that they come closer than r to each other (lines 15– 19). At long last, we refresh the
time step. The cleanup system appears in Algorithm 2. It is proficient each gap time steps and disposes of powerless MCs and defenseless passages inside the mutual thickness diagram to show signs of improved memory and upgrade the bunching calculation's preparing pace.
V.
PROBLEM SOLUTION
Two differentiating classifiers that perform well on content order are (I) the basic Naive Bayes strategy and (ii) the more unpredictable Support Vector Machines.
5.1 Naive Bayes Classifier
Let C ={c1;c2; : : : ;cl} be the set of l classes, and letW
={w1; : : : ;wm} be the set of words/features contained in these classes. Given a new document d, the probability that d belongs to class ci is given by Bayes rule,
the outstanding Naive Bayes classifier (Mitchell, 1997), which registers the most likely class for d as
where n(wt ;d) is the number of occurrences of word
wt in document d, and the quantities p(wt jci) are usually estimated using Laplace’s rule of succession:
The class priors p(ci) are estimated by the maximum
likelihood estimate We now
manipulate the Naive Bayes rule in order to interpret it in an information theoretic framework. Rewrite formula (3) by taking logarithms and dividing by the length of the document jdj to get
where the document d may be viewed as a probability distribution over words: p(wt jd)=n(wt ;d)=jdj. Adding the entropy of p(Wjd), i.e.,
5.2 Support Vector Machines
The Support Vector Machine(SVM) (Boser et al., 1992, Vapnik, 1995) is an inductive learning plan for unraveling the two-class design acknowledgment issue. As of late SVMs have been appeared to give great outcomes for content classification (Joachims, 1998, Dumais et al., 1998). The strategy is characterized over a vector space where the arrangement issue is to discover the choice surface that "best" isolates the information purposes of one class from the other. If there should be an occurrence of straightly divisible information, the choice surface is a hyperplane that boosts the "edge" between the two classes and can be composed as
where x is a data point and the vector w and the constant b are learned from the training set. Let
for positive class and −1 for negative class) be the classification label for input vector xi. Finding the hyperplane can be translated into the following optimization problem
subject to the following constraints
VI.
EXPERIMENTAL RESULTS
This section gives exact evidence that our troublesome grouping set of guidelines of Figure 1 beats various capacity decision strategies and previous agglomerative bunching forms. We analyze our results with trademark determination by methods for Information Gain and Mutual Information (Yang and Pedersen, 1997), and include bunching utilizing the agglomerative calculations of Baker and McCallum (1998) and Slonim and Tishby (2001). As expressed in Section five.Three we can utilize AIB to specify "Agglomerative Information Bottleneck" and ADC to signify "Agglomerative Distributional Clustering". It is computationally infeasible to run AIB at the total vocabulary, so as informed by implies regarding Slonim and Tishby (2001), we utilize the zenith 2000 expressions construct absolutely in light of the shared information with the greatness variable. We signify our calculation by a method for "Troublesome Clustering" and show that it accomplishes preferred to compose exactnesses over the best performing highlight determination strategy, exceptionally while preparing data is scanty and show changes over tantamount impacts expressed by methods for the use of AIB (Slonim and Tishby, 2001).
6.1 Data Sets
class inside the class venture. This actuality set has been utilized for experimenting with various printed content class methods (Baker and McCallum, 1998, Slonim and Tishby, 2001, McCallum and Nigam, 1998). Amid ordering we skipped headers yet held the title, pruned phrases occurring in under 3 documents and utilized a hinder posting, however, did now not utilize stemming. In the wake of changing over all letters to lowercase, the following vocabulary had 35,077 expressions. We accumulated the Dmoz data from the Open Directory Project (www.Dmoz.Org). The Dmoz chain of importance consolidates around 3 million archives and three hundred,0000 preparing. We chose the best Science classification and slithered some of the firmly populated inward hubs underneath it, bringing about a three-profound order with forty-nine leaf-degree hubs, 21 internal hubs, and around 5,000 aggregate records. For our exploratory impacts we overlooked records at inside hubs. While ordering, we avoided the content between HTML labels, pruned words occurring in under five records, utilized a forestall list, however, did now not utilize stemming. In the wake of changing all letters to lowercase, the subsequent vocabulary had 14,538 words.
Figure 1. Fraction of Mutual Information lost while clustering words with Divisive Clustering is significantly lower compared to ADC at all feature sizes (on 20Ng and Dmoz data).
6.2 Implementation Details
Bow (McCallum, 1996) is a library of C code valuable for composing content assessment, dialect demonstrating and certainties recovery programs. We stretched out Bow to list BdB (www.Sleepycat.Com) level record databases where
we put away the content archives for green recovery and capacity. We connected the agglomerative and troublesome bunching calculations inside Bow and utilized Bow's SVM execution in our analyses. To do progressive classification, we composed a Perl wrapper to conjure Bow subroutines. For slithering www.Dmoz.Org we utilized libraries from the W3C consortium.
6.3 Results
We first give confirmation of the enhanced nature of word groups got by our calculation when contrasted with the agglomerative methodologies. We characterize the portion of shared data lost because
of bunching words as:
records). While the bunches acquired by utilizing our calculation and AIB may need to solidly recognize rec.Game.Hockey and rec.Sport.Baseball, ADC mixed expressions from every lesson in a solitary expression group. This finished in diminish write exactness for every class with ADC in contrast with Divisive Clustering. While Divisive Clustering completed ninety-three .33% and ninety four.07% precision on rec.Recreation.Hockey and rec.Sport.Baseball separately, ADC should least complex accomplish 76.Ninety-seven % and 52.Forty-two %. AIB accomplished 89.7% and 87.27% individually — those lessening exactnesses seem, by all accounts, to be because of the preparatory pruning of the expression set to 2000.
Table 1. Top few words sorted by Mutual Information in Clusters obtained by Divisive Clustering, ADC and AIB on 20 Newsgroups data.
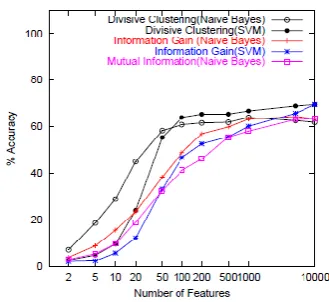
6.3.1 classification results on 20 newsgroups data Figure 3 demonstrates the order exactness comes about on the 20 Newsgroups informational collection for Divisive Clustering and the element choice calculations considered. The vertical pivot demonstrates the level of test records that are arranged accurately while the even hub shows the quantity of highlights/groups utilized as a part of the characterization display. For the component choice techniques, the highlights are positioned and just the best positioned highlights are utilized as a part of the relating test. The outcomes are midpoints of 10 trials of randomized 1=3-2=3 test-prepare parts of the aggregate information. Note that we bunch just the words having a place with the archives in the preparation set.
Figure 2. 20 Newsgroups data with 1=3-2=3 test-train split. (left) Classification Accuracy (right) Divisive Clustering vs. Agglomerative approaches (with Naive Bayes).
Figure 3. Classification Accuracy on 20 Newsgroups with 2% Training data (using Naive Bayes).
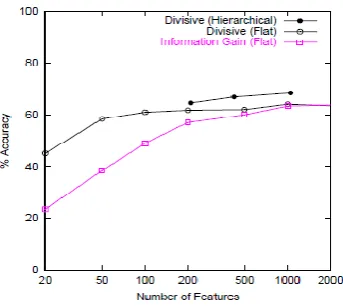
Figure 4. Classification Accuracy on Dmoz data with 1=3-2=3 test-train split.
6.3.2 classification results on dmoz data set
Figure 6 plots the characterization precision on Dmoz information utilizing Naive Bayes when the preparation set is only 2%. Note again that we accomplish a 13% expansion in order precision with Divisive Clustering over the most extreme conceivable with Information Gain.
Figure 5. (left) Classification Accuracy on Dmoz data with 2% Training data (using Naive Bayes). (right) Divisive Clustering versus Agglomerative approaches on Dmoz data (1=3-2=3 test train split with Naive Bayes).
6.3.3 hierarchical classification on dmoz hierarchy Figure 6 demonstrates the arrangement exactnesses acquired by three distinct classifiers on Dmoz information (Naive Bayes was the fundamental classifier). By Flat, we mean a classifier worked over the leaf set of classes in the tree. Conversely, Hierarchical indicates a various leveled conspire that assembles a classifier at each inside hub of the theme chain of importance (see Section 4.3). Encourage we apply Divisive Clustering at each inside hub to decrease the quantity of highlights in the characterization show at that hub. The quantity of word bunches is the same at each inside hub.
Figure 6. Classification results on Dmoz Hierarchy using Naive Bayes. Observe that the Hierarchical
Classifier achieves significant improvements over the Flat classifiers with very few number of features per internal node.
VII.
CONCLUSION
In this paper, we've offered a realities theoretic way to deal with "hard" expression bunching for literary substance grouping. To start with, we determined a worldwide objective trademark to grab the lower in shared insights because of grouping. At that point, we provided a troublesome arrangement of guidelines that immediately limits this goal trademark, focalizing to a close-by least. Our arrangement of standards limits within group Jensen-Shannon difference and all the while expands the among-bunch Jensen-Shannon disparity. At long last, we gave an experimental approval of the adequacy of our statement bunching. We have demonstrated that our troublesome bunching calculation is a horrendous parcel faster than the agglomerative systems proposed in the past by methods for Baker and McCallum (1998), Slonim and Tishby (2001) and acquires better express bunches. We have offered particular tests utilizing the Naive Bayes and SVM classifiers on the 20 Newsgroups and Dmoz measurements units. Our more prominent expression bunching results in improvements in classification correctnesses for the most part at bringing down a number of highlights. At the point when the instruction records are meager, our trademark bunching accomplishes higher class precision than the most exactness accomplished with the guise of trademark determination techniques alongside realities pick up and common information. In this way, our disruptive bunching strategy is a capable system for bringing down the variant intricacy of a progressive classifier.
VIII.
REFERENCES
[2].L. D. Baker and A. McCallum. Distributional clustering of words for text classification. In SIGIR ’98: Proceedings of the 21st Annual International ACM SIGIR, pages 96-103. ACM, August 1998.
[3].R. Bekkerman, R. El-Yaniv, Y. Winter, and N. Tishby. On feature distributional clustering for text categorization. In ACM SIGIR, pages 146-153, 2001.
[4].P. Berkhin and J. D. Becher. Learning simple relations: Theory and applications. In Proceedings of the The Second SIAM International Conference on Data Mining, pages 420-436, 2002.
[5].B. E. Boser, I. Guyon, and V. Vapnik. A training algorithm for optimal margin classifiers. In COLT, pages 144-152, 1992. P. S. Bradley and O. L. Mangasarian. k-plane clustering. Journal of Global Optimization, 16(1):23-32, 2000.
[6].S. Chakrabarti, B. Dom, R. Agrawal, and P. Raghavan. Using taxonomy, discriminants, and signatures for navigating in text databases. In Proceedings of the 23rd VLDB Conference, Athens, Greece, 1997.
[7].T. M. Cover and J. A. Thomas. Elements of Information Theory. John Wiley & Sons, New York, USA, 1991.