Empowering Technical Risk
Assessment in Software
Development
Vard Antinyan
Department of Computer Science and
Engineering
ii
Thesis for the degree of licentiate of engineering
Empowering Technical Risk Assessment in Software Development © Vard Antinyan 2014
iii
“Risk comes from not knowing what you`re doing.” Warren Buffett
v
Abstract
Contemporary software development organizations focus on continuous delivery of product features, in order to respond customers’ requests quickly. In large software development organizations this focus is realized by parallel development of multiple features by independent software development teams. However, the continuous delivery is not only a contributory factor for organizational success but also a challenging one, in terms of delivering high quality product: Continuous code delivery combined with large code base induces risks of gradually degrading code quality. In order to quickly assess these risks software engineers need methods and automated tool support.
In this thesis we investigate the possibilities of assessing the technical risks, that the newly delivered code can be defect-prone or hard-to-maintain. We conduct a series of action research projects in two organizations at Ericsson and Volvo Group Truck Technology. Our results show that a set of complexity and change measures of source code can be used to assess the technical risks. Based on these measures, we develop methods and tools for technical risk assessment in source code delivery. These methods and tools empower software engineers to quickly identify the few risky functions and files in a large code base. Subsequently, software engineers can focus on enhancing product quality by refactoring these functions and files.
Keywords: software development, technical risk, risk assessment, software metrics, software complexity, continuous integration
vii
Acknowledgement
I express my deep appreciation to my main advisor, Miroslaw Staron, who has guided me throughout my entire research. I also show my gratitude to my second advisor, Anna Sandberg, for her support in my research. I thank Jörgen Hansson for his support in this research journey. Miroslaw, Anna, and Jörgen, I am thankful to you all for your support in accomplishing this research project.
I cordially thank Wilhelm Meding for welcoming me to his team as a researcher at Ericsson. When I walked in through the doors of Ericsson, I knew nothing about large software organizations. It is thanks to Wilhelm’s dedication that I learned rapidly. I also thank Anders Henriksson for including me to his team as a researcher at Volvo Groups. Supporting with tools within counted hours and pointing to the right people to talk to are the greatest thing a researcher can get in an organization. I thank Per Österström. He is a person, being a project leader, with vast interest in research and collaboration. Per has invested so much from his precious time to take our research forward. Also, I would like to extend my thanks to Kent Niesel and Christoffer Höglund for their participation and advices in this research. I am happy we are going to have more active collaboration with you in upcoming research projects. I thank Micael Caiman who supported me in getting access to Ericsson and do research inside the company. That has been a great privilege for me.
Other colleagues in industry: Jesper Derehag, Erik Wickström, Henrik Bergenwal, John Walmark, Johan Wranker, Mattias Runsten, Jonas Bjurhede and Jimmie Arvidsson. You helped me tremendously with any technical question that I had. Without your support, I hardly imagine my research targets would have been accomplished.
I thank colleagues in Software Engineering divisions and particularly Rebecca Cyren for creating nice environment for my research.
The most important people in my life: Ulrika - thank you for your unconditional support in bad and good times. Parents, Misha and Roza - you were just great support. Harutyun - thanks for genuinely sharing my problems and doubling my joys throughout this journey. Hasmik, Vahan, Artyom, Erik, Hrach, Davit, Edward and Hakob - you all were just great being beside me.
ix
Included Publications
This thesis is based on the following studies.
I. Vard Antinyan, Miroslaw Staron, Wilhelm Meding, Anders Henriksson Jörgen Hansson and Anna Sandberg, "Defining Technical Risks in Software
Development. "International Conference on Software Process and Product Measurement. 2014.
II. Vard Antinyan, Miroslaw Staron, Wilhelm Meding, Per Österström, Anders HenrikssonJörgen Hansson, "Monitoring Evolution of Code Complexity and Magnitude of Changes. "Journal of Acta Cybernetica (0324-721X). 2014, Vol. 21, p. 367-382.
III. Vard Antinyan, Miroslaw Staron, Wilhelm Meding, Per Österström, Erik Wikström, Johan Wranker, Anders Henriksson, Jörgen Hansson, "Identifying risky areas of software code in Agile/Lean software development: An industrial experience report". Conference on Software Maintenance, Reengineering and Reverse Engineering, IEEE. 2014 p. 154-163.
IV. Vard Antinyan, Miroslaw Staron, Jesper Derehag, Mattias Runsten, Wilhelm Meding, “A method for effective reduction of code complexity by investigating various aspects of code complexity”. In submission to 22nd IEEE international
conference on software analysis, evolution and reengineering
V. Vard Antinyan, Miroslaw Staron and Wilhelm Meding, “Profiling Pre-release Software Product and Organizational Performance”. Software Center book chapter". Springer 2014, p. 167-182.
x
Additional Publications
I. Vard Antinyan, Miroslaw Staron, Wilhelm Meding, Per Österström, Anders Henriksson, Jörgen Hansson. "Monitoring Evolution of Code Complexity in Agile/Lean Software Development - A Case Study at Two Companies." 13th Symposium on Programming Languages and Software Tools. 2013, p. 1-15.
xi
Table of Contents
Abstract ... v
Acknowledgement ... vii
Part 1: Technical Risks in Large Software Product Development ... 15
Introduction ... 16
1 research Overview ... 18
2 Agile software development ... 19
3 Agile software development in the collaborating organizations ... 19
3.1 Industrial Partners ... 21
4 Volvo Group Truck Technology (GTT) ... 21
4.1 Ericsson ... 21
4.2 Volvo Cars Corporation (VCC) ... 22
4.3 Saab Defense ... 23
4.4 Risk ... 23
5 Risk assessment in software development ... 24
5.1 Technical risks in software development ... 26
5.2 Technical risks in source code delivery ... 27
5.2.1 Software metrics ... 30
6 The scope of software metrics ... 31
6.1 Research focus ... 32
7 Research methodology ... 34
8 Action research methodology ... 34
8.1 Application of action research ... 36
8.2 Methods of data collections ... 37
8.3 Methods of data Analysis ... 38
8.4 Correlation Analysis ... 39 8.4.1 Correlograms ... 40 8.4.2 Time series ... 40 8.4.3 Reference Groups ... 40 8.4.4 Validity Evaluation Frameworks used in the thesis ... 41
9 Part 2: Defining Technical Risks in Software Development ... 43
Introduction ... 45
1 Motivation of the study ... 46
2 Defining Technical Risks... 47
3 Software Engineers View on Technical Risks ... 50
4 Risk Assessment by Forecast Model ... 53
5 Related Work ... 55
6 Conclusions... 56
7 Part 3: Monitoring Evolution of Code Complexity and Magnitude of Changes ... 57
Introduction ... 59
1 Related Work ... 60
2 Design of the Study ... 61
3 Studied Organizations ... 61 3.1 Units of Analysis ... 62 3.2 Reference Group ... 62 3.3
xii
Measures in the study ... 63 3.4
Research method ... 63 3.5
Analysis and results ... 64 4
Evolution of the studied measures over time ... 64 4.1
Correlation analyses ... 68 4.2
Design of the measurement system ... 70 4.3
Threats to validity ... 72 5
Conclusions ... 72 6
Part 4: Identifying Risky Areas of Software Code in Agile Software
Development ... 75 Introduction ... 77 1
Agile software development ... 78 2
Study design ... 79 3
Industrial context ... 79 3.1
Reference groups at the companies ... 80 3.2
Flexible Research design ... 80 3.3 Definition of measures ... 81 3.4 Results ... 83 4 Correlation analysis ... 84 4.1 Selecting metrics ... 87 4.2
Evaluation with designers and refinement of the method ... 88 4.3
Evaluation ... 90 5
Correlation with error reports ... 90 5.1
Evaluation with designers in ongoing projects ... 91 5.2 Impact on companies ... 92 5.3 Related work ... 93 6 Threats to validity ... 94 7 Conclusions ... 95 8
Part 5: A Method for Effective Reduction of Code Complexity ... 97 introduction ... 99 1
Motivation of the study ... 100 2
Study design ... 100 3
Industrial context ... 101 3.1
Target software products ... 101 3.2 Collected measures ... 102 3.3 Research method ... 103 3.4 Results ... 105 4
Delineating two aspects of complexity ... 105 4.1
Visualization of measures’ dependencies ... 107 4.2
Complexity distribution ... 108 4.3
Complexity trade-off ... 112 4.4
Evaluation and calibration of results ... 113 4.5
A method for code complexity reduction ... 114 5 Threats to validity ... 115 6 Related work ... 117 7 Conclusions ... 118 8
xiii
Acknowledgment ... 118
Part 6: Profiling Pre-Release Software Product Performance ... 119 Introduction ... 121 1
Profiling ... 121 2
Profiling pre-release product and process performance in large 3
software development organizations ... 123 Establishing the process of profiling ... 124 4
Case study: developing risk profile of software code ... 126 5
Case study: profiling change frequency of models over time ... 131 6 Related work ... 133 7 Conclusions... 135 8 References ... 137
15
PART 1: TECHNICAL RISKS IN
LARGE SOFTWARE PRODUCT
DEVELOPMENT
16
INTRODUCTION
1
A central issue in large software development projects is the assessment of quality of software development products. Based on such assessments developers can get insights on products’ time-to-market and customers’ satisfaction. Moreover, based on such assessments, products’ ineffectual design solutions can be identified and improved. Nowadays, large software development products contain several millions lines of code developed by tens of software engineering teams incorporated in one big organization. Large software code bases and sophisticated development processes require rigorous assessment methods and supporting tools adapted to the organization. Without assessments, the organization takes on risks of gradual degrading the quality of the software products and processes. However, as software products grow in size to provide more functionality for its customers, this kind of assessment certainly becomes an effort-intensive task if done manually.
The outcome of accepting such risks can be production delay, post-release product defects, and ultimately customers’ dissatisfaction. To balance the trade-offs between the costs of assessments and the prevention of gradual degradation of the product quality the companies usually conduct risk management. De Bakker [1] shows how risk management affects project success positively by permitting instrumental actions. Many researchers’ endeavors were directed towards creating a set of such instruments for effective risk management: Boehm [2], Charette [3], and Higuera and Haimes [4] have become standard for software engineers. Notwithstanding, with growing software product size the risk assessment activities need to be done more effectively. This requires automated support and increased focus on technical solutions used in the product. Assessing the technical solutions of the product, which was not considered so crucial for software production 15-20 years ago, have become an indispensable activity today [5]. This is due to the need of creating highly modular systems in order to manage risks due to the growing size of the products [5, 6]. The emerging risks due to poor design and engineering is defined as technical risks [7]. Poor technical solutions trigger technical risks of emerging defects in software code and increasing software maintenance effort. In order to manage these technical risks, software engineers in industry attempt to assess the quality of product’s design solutions, but the lack of standardization
17
often impedes these attempts. Realizing technical risk management is a difficult task, and reasons for this difficulty are multifold:
Inaccurately perceived nature of technical risks
Incomprehensive foundation of its assessment and mitigation methods
Incomplete automation of risk identification and assessment activities
Unpredictable evolution of technical solutions
Fenton and Neil [8] state that one effective way of assessing risks is to use software metrics in order to provide quantitative support for risk mitigation. The use of software metrics permits automation of risk assessment, whereas, software metrics are mostly used for isolated purposes, such as defect prediction or cost estimation.
The research presented in this thesis proposes metrics-based practical methods for supporting technical risk assessment and automation in large software product development. The focus of this work is the identification and assessment of technical risks with source code delivery. The general research question that is addressed in the thesis is formulated as follows:
How to automatically assess technical risks with source code delivery?
In this thesis, first, a number of examples of technical risks are presented, which software engineers encounter in large software development products. Next, a scrutinized definition of software development technical risk is formulated. Last, a deeper investigation of technical risks in source code delivery is presented:
Several code properties are examined that affect technical risks
A set of metrics are selected for measuring these properties
Metrics-based methods are proposed for risk assessment
Furthermore, tools for automation of risk assessment are also presented, that were developed in the collaborating organizations. In the end, we discuss the benefits for the collaborating organizations.
In the next section, a brief overview of the research topic is presented to help the reader understand the research context from an abstract level.
18
RESEARCH OVERVIEW
2
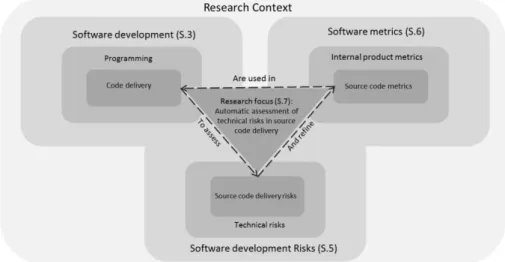
The aim of this research is to provide methods and tools for assessing technical risks with source code delivery in large software development products. Figure 1 illustrates the overview of our research in the context of software engineering. On the left side of the figure we can see the granular representation software development activities. The code delivery is the activity on which this research has focused. On the bottom of the figure we can see the conception of risks that software engineers deal with in different activities. The focus of this research is technical risks in code delivery, as represented on the lowest hierarchical order in the figure.
On the right hand of the figure we can see software metrics. This represents measures, by means of which various aspects of development products and processes are assessed. The source code metrics are used in this research for investigating the possibilities of assessing technical risks in source code delivery.
In the middle part of the figure the research focus is depicted in a rectangle. As the figure illustrates source code metrics are used in code delivery for assessing technical risks.
In Figure 1 the names of outlined areas also contain the section numbers (for example S.6 – section six) where the specified area is presented. The rest of part 1 is organized as follows: In section three, we present an overview of Agile Software Development in large software
19
product development. In section four we introduce the collaborating organizations. In section five and six, we introduce software risks and metrics correspondingly. In section seven, we present the research focus and break down the general research question into specific areas. Finally, in section eight we present the action research methodology by which we carried out this research.
AGILE SOFTWARE DEVELOPMENT
3
In recent years many software development organizations have adopted Agile software development methodology, which promises to accelerate software delivery to its customers [9, 10]. The organizations that we collaborate with has also adopted this methodology, therefore an overview of it is presented here.
The software development processes should not be built upon rigid methods, but rather flexible and change-driven principles. Agile manifesto suggests twelve such principles for software development [11]. The first principle states that:
The customer satisfaction is the highest priority which can be achieved by early and continuous delivery
Our collaborating companies had a strong focus on continuous delivery. With continuous delivery the quality of the software product also should be monitored and improved continuously, therefore the eight principle of agile manifesto states that:
Continuous attention to technical excellence and good design enhances agility
In continuous source code delivery the technical risk assessment should be carried out also continuously, in order to ensure that the code quality does not decrease gradually. In the next section we present how the collaborating organizations follow Agile principles.
Agile software development in the
3.1
collaborating organizations
In our collaborating organizations, the size of the software products reach to several millions of lines of code and up to several hundred software engineers distributed in standalone development teams. A development team contains five to eight software engineers with a designated team leader within the team. Every development team have an assigned development area, such as development of a newly specified
20
feature or error correction in a previously developed area. To a certain degree, the development teams are given the mandate to make decisions and develop their own schedule for their development activities. In this process the project managers coordinate the activities for a common vision and ensure the amicable communication between the development teams. This type of behaviors is very much in line with original Agile development methodology.
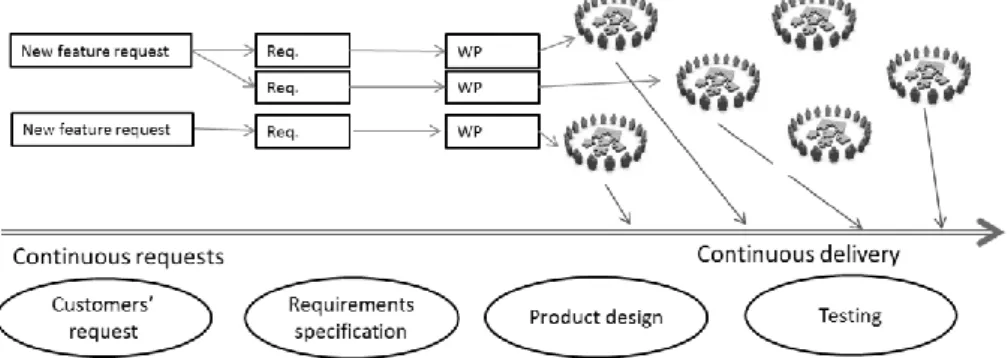
An overview of software development process in collaborating organizations is illustrated in Figure 2. As the figure shows customers are continuously requesting new product features. These requests are formalized in a requirements specification (Req.), which was broken down into work packages (WP). The WPs are distributed in Agile software development teams, who design, test, integrate, and deliver the software.
The continuous delivery process is supported by parallel development carried out by independent teams. This is reflected by arrows in the Figure 2, indicating parallel delivery by development teams. The process of customers’ request and feature delivery is a smooth continuous process aligned with the principles of Agile software development. With every new feature request customers also report feedback on the quality of previously delivered software. This means that identified post-release defects are also continuously reported. Accordingly, the organizations have assigned teams for continuous defect correction and quality improvement. Therefore, for the quality improvement teams the technical risk mitigation is crucial, in order to decrease the chance of getting high number of post-release defects. Hence, it is important to have effective tools for assessing the code quality and particularly defect-proneness before code delivery. This permits software engineers to identify the most defect-prone areas of
21
source code and improve it, so the risk of high number of post-release defects can be low.
INDUSTRIAL PARTNERS
4
In this section we give a brief overview of the collaborating organizations that support and are the direct stakeholders of the conducted research. Two of the organizations, Ericsson and Volvo Group Truck Technology, are the main collaborating partners and supporters of this research. The other two organizations, Volvo Cars Corporation and Saab, are partially involved in this research.
Volvo Group Truck Technology (GTT)
4.1
At Volvo GTT the software development organization supporting this research develop Electronic Control Units (ECU) for trucks. Every ECU represents a small computer, which performs various real-time tasks for the truck. Such tasks can be speed control, automatic breaking, air suspension, and climate control. Our collaborating organization develops one of the main ECUs for the truck. Additionally they carry out the verification and validation task of another ECU development (developed by another unit of the organization).
The development organization comprises tens of software engineers who perform requirements documentation, design, code development and testing. Each of these activities are executed by dedicated software development teams consisting of 5-8 software engineers.
The collaborating engineers of the organization have supported us with problem formulation, creating researcher-engineer collaboration environment in the organization and providing access to their data repositories. Additionally, four of the software engineers have been directly involved in evaluating the results. Several other engineers have been indirectly involved in the research by providing knowledge for tool usage and data collection.
Ericsson
4.2
The software development organization at Ericsson develops software for a telecom node. The node serves for interconnecting mobile users. The software of the node encapsulates a few millions lines of code. The functionality perform tasks such as signal processing, converting
22
signals from one type to another, controlling access of different user groups, and accounting.
The software development organization of this product comprises a few hundred software engineers. Tens of developers, distributed in semi-autonomous development teams, develop and test the software. For different architectural areas of the product, there are dedicated design architects. Development teams can carry out different activities such as maintenance, error correction or feature development. The assignments of the teams can change over time considering overall development efficiency.
We have conducted our research in the metrics team of the organization. The metrics team provides various measurement systems for measuring several aspects of the product’s performance. The metrics team leader has helped us with accessing data repositories. The line manager and five software engineers of the product have directly been involved and supported our research. The line manager has also been the main stakeholder for our action research project. Many other engineers that have not been directly involved in the research have helped us with accessing the right data repositories and the right versions of the product.
Volvo Cars Corporation (VCC)
4.3
VCC developed and manufactured personal cars. This development included software development of ECUs for cars also. Our collaboration organization develops one specific ECU for the car.
The development organization in VCC consists of tens of software engineers in several development teams. Every team is responsible for a particular activity of development. The activities are requirement specification, product design by domain specific language and testing.
The technical leader has been involved in the research. He has also provided access to company’s premises and data repositories. VCC has participated in the research presented in Part two and Part six of this thesis. In Part two, the technical leader from VCC have had a contribution to identifying technical risks. In Part six, we describe how one of the metrics developed at Ericsson is used at VCC.
23
Saab Defense
4.4
Saab Defense develops defense equipment. Our collaboration organization develops surveillance radar system.
The organization comprises several dedicated development teams, who carry out requirements specification, code design testing and deployment of the software.
Two software engineers have been involved in our research. They have supported the research presented in Part two of this thesis. They have also used the research results presented in Part four. As the organization develops defense equipment, there are strict rules for data collection and analysis. Therefore, we provided the tools to collaborating engineers who did data analysis themselves.
RISK
5
Historically the concept of risk is used to describe situations in decision making, where the possibility of loss exists. According to Slovic [12] the human perception of risk is closely associated with the factor of “dread”, threatening to inflict loss of health, property or reputation. Stanford Encyclopedia of Philosophy presents the most widely used five definitions of risk [13]:
1. An unwanted event which may or may not occur
2. The cause of an unwanted event which may or may not
occur
3. The probability of an unwanted event which may or may
not occur
4. The statistical expectation value of an unwanted event
which may or may not occur
5. The fact that a decision is made under conditions
of known probabilities
In ISO 31000 a risk is defined as an effect of uncertainty on objectives
[14]. As we can see all definitions contain two elements: The first one is the uncertainty that an unwanted event can happen. The second one is the effect, impact, or cause of the unwanted event, which inflicts loss,
when attempting to meet some targeted objectives. Kaplan and Garrick [15] define risk as a superposition of uncertainty and loss when taking on a decision. Unlike the previous definitions Kaplan and Garrick do not regard risk as a variable which should have a fixed value. They consider risk as collection of probabilities and losses, any instance of which can
24
occur. Figure 3 illustrates the risk according to the definition of Kaplan and Garrick: The risk is not a specific value of probability and loss but the whole surface of distribution of probabilities and losses.
In this study we rely on Kaplan’s and Garrick’s definition of risk, because it assumes that before the occurrence of the unwanted event the loss
cannot be a fixed value. The loss in source code delivery is the number of defects and decreased maintainability of the code. Therefore, when assessing technical risks of source code delivery, the loss is not a fixed value before the delivery is done. We do not usually say source code will or will not have defects, or the code is maintainable or not maintainable. We rather talk about the number of defects and degree of maintainability of delivered code.
The last phrase of risk definition in Kaplan’s and Garrick’s definition focuses on decision making. In business organizations the concept of risk is usually accompanied with decision making, because when making decision, the organization is prompted to change from one state to another. Notwithstanding, the decision maker cannot forecast the exact consequences of the decision, thus leaving other unpredictable possibilities. Not making any decision is another decision, therefore there is no such thing as avoiding risks but rather choosing between risks.
Risk assessment in software
5.1
development
In software development organizations risk is viewed as a possibility of loss when making decisions under given uncertainty [15]. Several researchers have investigated the most common risks in software engineering and their nature [2, 16]. Risks identified in their work are divided into categories as reputational, operational, business, technological, and technical. Software risk management is usually carried out in software projects by the project manager or risk manager
25
with a participation of other software engineers and experts. Phases of software risk management include:
1. Identification 2. Prioritization 3. Assessment
4. Mitigation strategy planning 5. Implementation of a strategy plan
In this thesis we focus on the assessment phase which usually is carried out manually with software engineers and experts. Normally in an organized workshop, the experts (e.g. architects, managers, business analysts) identify and present risky events (phase 1). They then select top priority risks (phase 2) and assess them (phase 3) [4]. In general there are several assessment methods of risks, both quantitative and qualitative, two of which are mostly used. The first one relies on qualitative assessment of risk, where the likelihood and the impact of the identified adverse event are qualitatively assessed. Then these two values are summed or multiplied as a relative value of risk exposure, [17] (Figure 4).
Risk = Likelihood * Loss (1)
The other assessment method relies on the triple estimation formula, and is fundamentally a different way of risk estimation compared to the first one. It allows not only estimating the absolute value of loss, but also the most likely interval of loss [18]. According to this method the value of risk exposure is calculated as:
Risk = (max + 4*most likely + min)/6 (2)
Where max is the maximum estimated loss, most likely is the most likely estimated loss, and min is the minimum estimated loss by experts. In this case, not only the value of risk exposure matters, but also the [min,
26
max] interval. This method has been and still is used at Ericsson [19]. After the assessment mitigation strategy plan is prepared (phase 4) and executed by the initiation of the risk facilitator or project manager (phase 5).
In the next section we introduce technical risks in software engineering, discuss the difficulties of their assessment with aforementioned techniques, and emphasize the need of new approaches for technical risk assessment.
Technical risks in software development
5.2
A technical risk is defined similar to other definitions of risks presented in section 5. The risk is a combination of likelihood of adverse event and expected loss. Educational websites define technical risks as follows:
1. Investor Words defines technical risks as the probability of loss incurred through the execution of technical process in which the outcome is uncertain [20]. Technical risk assessment in this case, is realized based on prior experiences.
2. Business dictionary defines technical risk as an exposure to loss due to design and engineering of a product [7].
In software development, the technical risk is defined as a measure of probability and severity of adverse effects that are inherent in the development of software, and associated with its intended functions and performance requirements [21]. All of these definitions of technical risks rely on the generic risk definitions, implying that there are two orthogonal components in risk, probability and loss. In case of technical processes, the probability and loss are induced specifically by technical decisions. In order to make a good decision the engineers need an objective and quantitative assessment of risk, permitting clearly determined choice on how to spend the precious time for enhancing development productivity. The risk quantification formulas presented in section 5.1 are not applicable for certain technical risks because of three essential reasons:
1. The number of risk items to be assessed are overwhelmingly bigger than in other types of risks
2. The frequency of risk assessment is needed on a daily or even sometimes hourly basis
27
3. Before the technical risk occurs we cannot give an exact value of loss, but an interval: After the risk occurs we can calculate the actual value of the loss.
The first two reasons highlight the importance of automation of risk assessment. Thus we need a method which supports the automatic risk assessment. The last reason indicates that we need a method which does not imply preliminarily decided value of expected loss.
Technical risks in source code delivery
5.2.1
Technical risk assessment in source code delivery is the focus of this research. We therefore give an overview of technical risks in the delivery process.
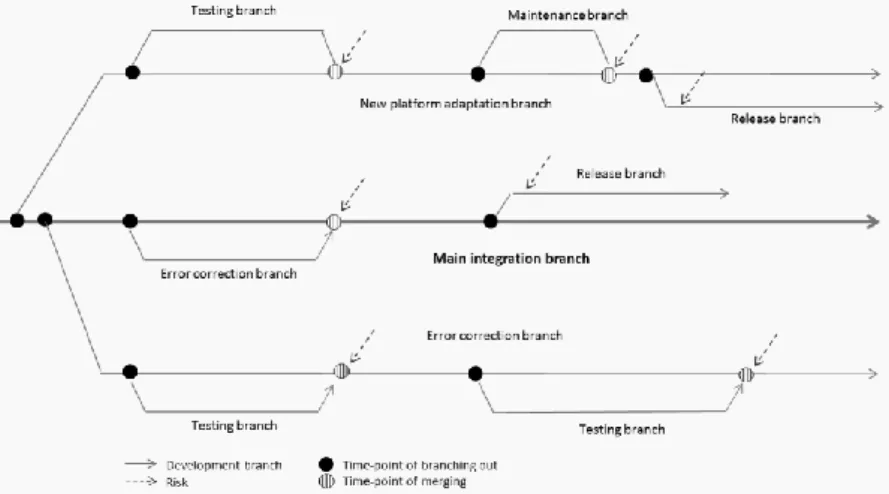
In the collaborating organizations, the development teams continuously deliver newly developed software code [22]. They merge the newly developed code with the whole product code that is called an integration branch. The latest updates of the source code are always merged with an integration branch called the main integration branch. Beside this, due to several possible releases and activities on the product, there are several other integration branches, such as release branch for a particular platform, error correction branch, and testing branch. Figure 5 presents several possible integration branches in code delivery.
The black circles show the place where a new branch was created for a specific activity. The stripped circles show the place where the newly developed or modified code was merged back to its initial branch.
28
In the merging circles the dashed arrows show the risks which the development team takes when merging the newly developed code. One of these risks can be the likelihood of new defects inserted in the code together with the merged code.
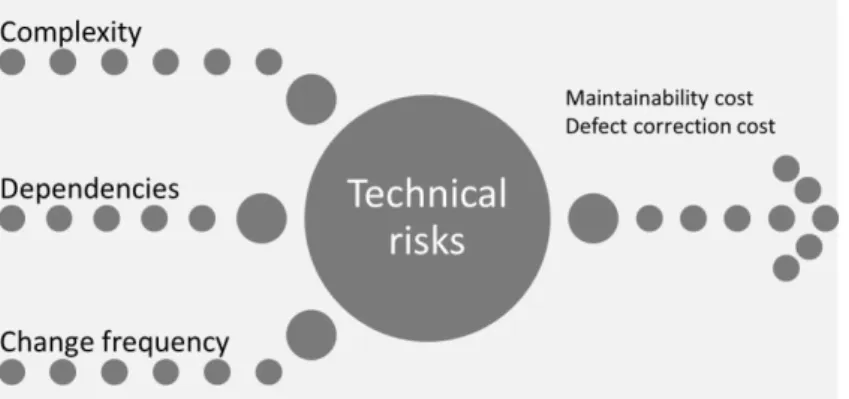
However, the newly developed code can also become more risky for multiple reasons. For example the increased code complexity or too many changes in the code can trigger risks. Figure 6 presents an example of triggers of technical risks and the expected outcome, when merging a newly developed portion of code.
In the process of source code development and delivery to integration branches there are there major technical risks that developers are concerned with.
1. Does the newly delivered code contain defects? a. How many defects does it contain? b. How severe are the defects?
2. Does the newly delivered code contain an area that is difficult to maintain or has become significantly less maintainable than it was before?
3. Is the newly delivered code at least as manageable as it was before?
As we can conclude from the listed questions, three main adverse events are associated with the integration of newly developed or maintained code, the occurrence of which eventually will slow down the development. The possibility of such adverse events, as inserted errors or exacerbated maintainability of source code, in standard terms can be stated as technical risks associated with source code delivery.
29
In Agile software development, where the product features are delivered to the customer continuously, the number of newly developed code portions and the number of merges of new code to the main integration branch per day can reach to hundreds. In order to assess technical risks in source code delivery, there is a need of methods that permit automation of risk assessment.
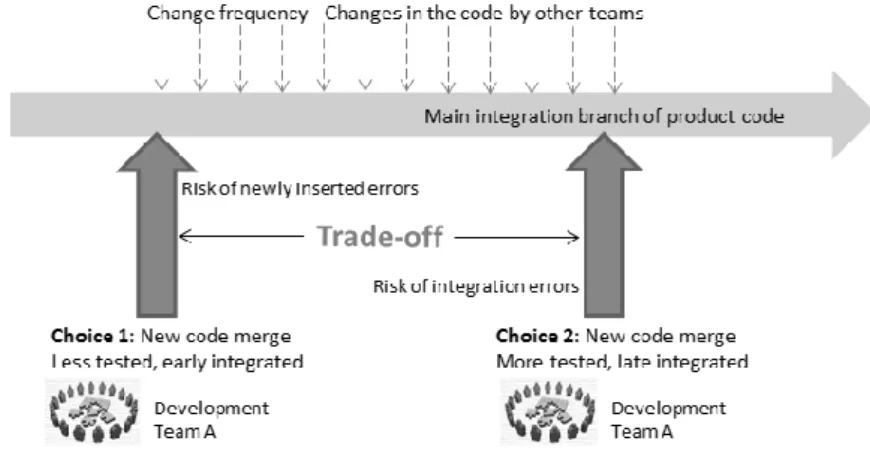
In software product development one choice in technical decision making can be integrating newly developed code with the whole product code. An alternative choice can be doing more testing andintegrating the code later. In the above example there is a trade-off with the aforementioned two alternative choices: Integrating the code early with a risk of newly inserted errors versus integrating late with a risk of late integration errors (Figure 7).
Figure 7 shows that when code integration is late, changes to the overall code are introduced by other teams (dashed arrows). Thus there is a risk that integration will not be smooth due to changes that other teams introduced to the overall code. Pondering on this decision, software engineers need to understand how complex the newly developed code is, how much problems it might cause, how much time and effort it will take to reduce the complexity, and how the late integration will affect the business of the organization. Based on this considerations software engineers attempt to understand the trade-off between the two choices and find an optimal point when the code can be integrated to the main branch.
Figure 7 Illustrating trade-offs between two technical choices in decision making
30
SOFTWARE METRICS
6
One effective way of obtaining information about various aspects of software is observing its attributes (properties). Software attributes (properties) are characteristics of an entity that can be distinguished quantitatively or qualitatively by human or automated means [23].
For example size, complexity or change rate are properties of software code. Length, size, documenting style and understandability are properties of textual requirements. The experience shows that measurable properties of software are widely used for observing the behavior of the software products. Measures that are designed to quantify properties of software artifacts are also called software metrics. For example Lines of Code is a metric for measuring software code’s size. The ISO/IEC 15939 Standard for Software Quality Metrics defines the
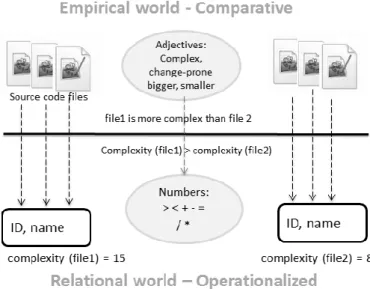
measurement as the process of assigning a number or category to an entity to describe an attribute (property) of that entity. A metric is a variable to which a value is assigned as a result of measurement [23]. An example entity can be the source code of product with such attributes (property) as code complexity, size, length, readability etc. A measure of the size can be the calculated value of number of lines of code of a file. Figure 8 illustrates how software properties defined in the empirical word can be transmitted into quantified measures in the relational world.
31
Software artifacts, source code files, have several properties: Complexity, size, change frequency, etc. In order for this properties to be quantifyable and comparable, software metrics are designed.
The lower part of Figure 8 represents the relational world. In relational world a software metric for complexity is used to measure the code complexity. In relational world software properties are quantified and therefore mathematical operations can be used to compare properties of different artifacts [24]. For example the complexity of two source code files can be compared by numbers.
The scope of software metrics
6.1
Software measurement encompasses a variety of measurement and prediction activities carried out in software development and production. The most well-known activities listed by Fenton and Pfleeger [25] are:
Data collection
Cost and effort estimation
Productivity measurement
Quality models and measurement
Reliability models and measurement
Performance evolution measurement
Structural and complexity measurement
In our thesis the focus is on the last bullet point above, that is structural and complexity measurement. Structural and complexity measures are measures for properties of internal product artifacts. Internal properties of product are those that can be measured purely in terms of product, process or resource itself [25]. For example source code, requirements documentation, models and other documentations are parts of the product artifacts that have internal properties. Internal properties can be complexity of code or size of textual requirements. Measures of internal product properties are internal product measures. In this thesis, we use internal product measures and particularly source code measures for risk assessment.
32
RESEARCH FOCUS
7
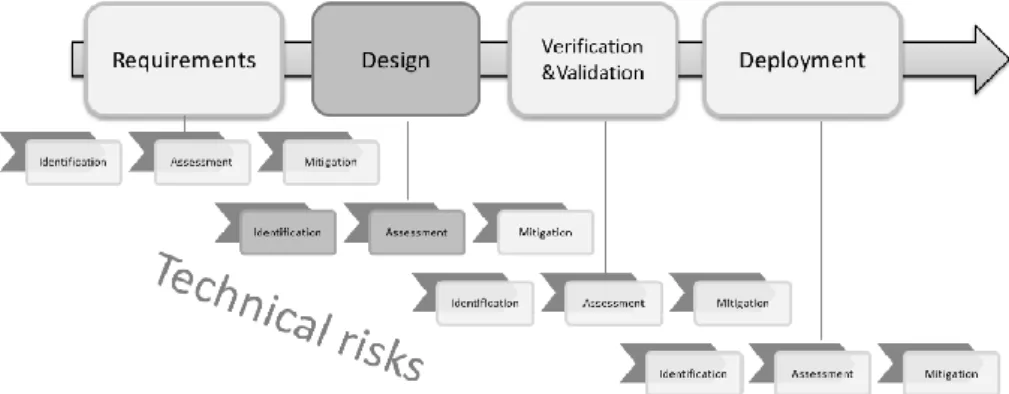
The main focus of this research has been the assessment of technical risks in source code delivery. Generally we view software development consisting of four consecutive phases (Figure 9). These phases are
requirements specification, software design, verification and validation,
and deployment. As Figure 9 illustrates, in every phase of development there are technical risk management activities, consisting of three phases: risk identification, assessment, and mitigation.
In Figure 9 the design phase as well as identification and assessment of technical risks are depicted darker, indicating our research focus. The general research question (RQ) presented in section one (Introduction) is broken down into five RQs presented below (Figure 10).
Part 2 (paper 1):
RQ 1: How can we define technical risk in order to support effective risk assessment?
In this paper we explore technical risks in depth and its difference from other types of risks. We have conducted three workshops with participation of software engineers of collaborating organizations. A set
Figure 9 The research focus in the context of software development phases
33
of technical risks have been identified and presented to software engineers. A definition of technical risk is proposed. In the next step the research has been focused on identifying the drivers of technical risks and monitor.
Part 3 (paper 2):
RQ 2:How to monitor code complexity and changes when delivering feature increments to the main code branch
The complexity and changes that are two important drives of technical risks have been explored. Different aspects of complexity and changes have been measured. The evolution of complexity and changes has been investigated over time. As a result of these investigations a measurement system has been developed at Ericsson for monitoring evolution of source code changes and complexity over time. This led to raising a research question concerned with identification and assessment of technical risks with source code delivery.
Part 4 (paper 3):
RQ 3: How to effectively identify risky source code and assess the risk, when delivering new feature increments in Agile development?
In this paper a method and supporting tool is suggested for identifying risky source code. Three software complexity and two change metrics have been investigated. A technical risk assessment method has been developed relying on a combination of two software metrics: McCabe’s cyclomatic complexity and number of revisions of a source code file. The method has been evaluated at Ericsson and Volvo GTT. The supporting tool has been integrated with the infrastructure of the development organization at Ericsson for systematic usage. In order to deepen our understanding how different aspects of complexity affect technical risks, the next research question has been formulated.
Part 5 (paper 4):
RQ 4:How to reduce code complexity considering various aspects of complexity?
Various complexity aspects of source code on five large software products have been investigated. Two main types of complexity have been delineated for a source code functions. These two types conditionally are called internal and outbound complexities. The investigation of these two aspects of complexities has showed that no matter how large the software is, the product of these two complexity measures for a function cannot exceed a certain limit. We suggested that, the source code functions, which have high complexity, considering both aspects of complexity, should be reviewed and refactored. The evaluation has been carried out at Ericsson and Volvo GTT by a group of software engineers. Concluding the investigation of technical risk
34
assessment in source code delivery, we addressed a task of developing risk profile in the last paper.
Part 6 (paper 5):
RQ 5: How to profile technical risks in large software development organizations?
In this paper we give a definition of profiling pre-release product performance. What the profile means and how it is used for organizations is discussed. We show how profiling technical risks can be informative and supportive in decision making for software engineers.
RESEARCH METHODOLOGY
8
The presented research relies on action research methodology [26, 27]. The methodology enables close collaboration with companies focusing researchers’ attention rather on “how things are done” in the organizations than “how engineers say things are done”. This implies that researchers are a part of the organization and observe the product and processes themselves.
Action research methodology
8.1
“Action research” is a term coined by Kurt Lewin already in 1946 [28] describing a methodological approach for research in social sciences. The methodology is maintained by Susman and Evered [26] and later adjusted to information science by Baskerville and Wood-Harper [27]. The necessity of action research methodology emerged when large numbers of post-war people were examined. Positivistic scientific methodologies turned out insufficient when investigating psychology of a large number of people, because every “case” was considerably different from the other “case”. Lewin applied a clearly defined methodology, where in a patient’s treatment an action was designed and applied for two purposes:
1. Helping the patient for recovery and
2. Adding body of knowledge in the science of social psychology.
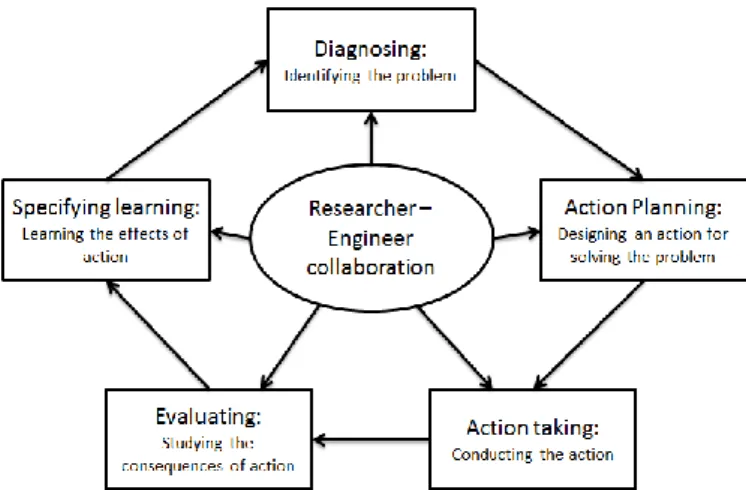
Originally, action research had five basic steps [26]: 1. Diagnosing the problem
2. Action planning 3. Action taking
35
4. Evaluating
5. Specifying learning
Figure 11 presents the general phases of action research. The research cycle starts with diagnosing the problem. In the field of engineering, action research is often conducted due to existing problems in an organization. Therefore the phase of diagnosing usually converts into formulating research questions of existing problems.
In this phase, the research questions are formulated based on the problems the companies have. In the second step, researchers design methods and tools for both answering the research question and solving the emerged problems. In the fourth step, the researchers study and document the consequences of the conducted action in the organization. In the last step, the researchers specify the learning and communicate it with software engineers.
The researchers usually conduct the research being at company and working with engineers side by side. This way of working permits observing how exactly things are done in the organization and learn the organizational change when a designed action is applied.
In positivist scientific methodologies, such as experimentations, the methods are created in laboratory, where the conditions are strictly controlled Oquist [29]. Then, the developed methods are applied in real life situations to specify the extent on how well the methods meet their requirements. However, as human interests are interwoven and change over evolution of the organization, it is not possible to have strictly controlled experimentation in organizations. Therefore, the
36
experimental studies fail to create similar environment in laboratory [27], and often the results of such experiments cannot be applied for organizations. Action research provides with an opportunity of designing an action, applying it, and learning the outcome in the organization.
Application of action research
8.2
The philosophy of action research is that every complex system is unique and requires unique approach for solving a problem emerged in it. Studying the complex systems by being a part of them, designing actions, applying actions and studying the consequences is one effective way of quickly gathering body of knowledge about complex systems that are in the same field but are somewhat different.
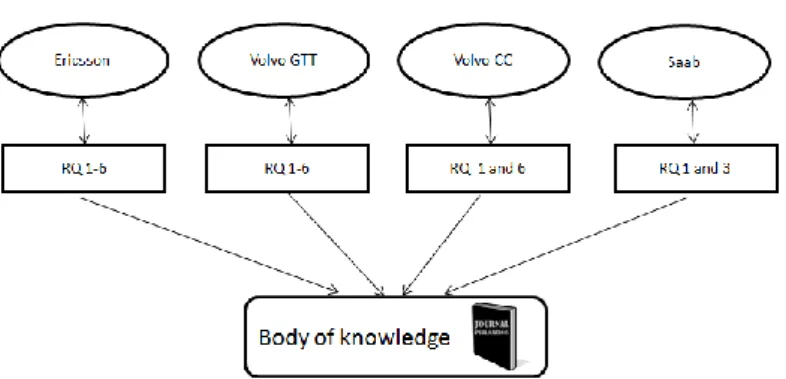
In our case four organizations have been involved in the research. Two of them have primary role in terms of conducting the research and evaluation the results. The other two have secondary role in the research. We have been a part of the organizations by investigating the formulated problems in the organizations. We have designed methods for solving the problems, and have designed actions based on results. Then we learned the consequences of taken actions and documented it. The process of collecting body of knowledge per company and per research question is illustrated in the Figure 12.
In our research besides collecting body of knowledge we also targeted improving the practice of collaborating organizations. In order to do this we established researcher-engineer collaboration environment. In this environment both engineers and researchers are involved in the research which is called collaborative practice research
Figure 12 Action research for generating knowledge on technical risk assessment of code delivery
37
[30]. Collaborative practice research allowed us to ease the understanding of obtained results and problem solving in the organizations. We specified similarities and differences between organizations and studied the impact of conducted action on the organization in a long period of time.
Methods of data collections
8.3
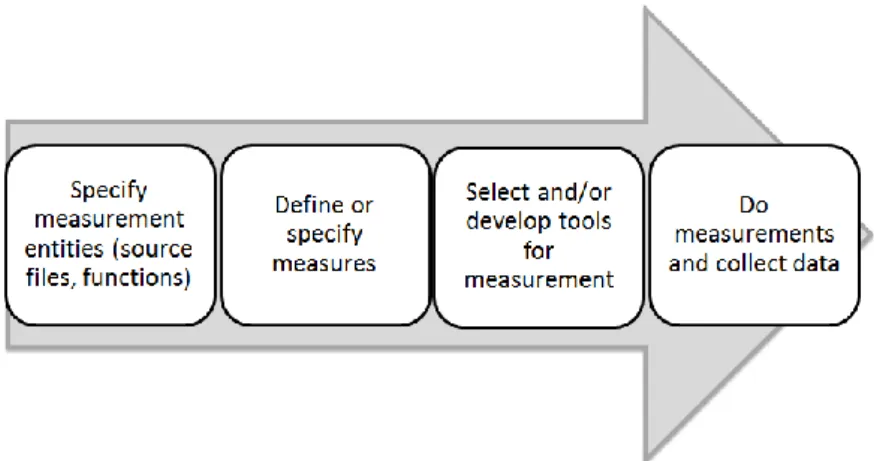
In this research we have strong focus on observing how “things” are instead of what software engineers say how “things” are. For this reason, indicators of facts and conditions are collected by relying first on analytical metrics and then engineers of reference groups, formed in the organizations. Particularly when focusing on assessing technical risks of source code delivery, source code measures have been collected by automatic tool support. An overview of the collection of measures by tools is visualized in Figure 13. Reference groups consisting of engineers have been involved in periodical meetings in order to discuss and verify the appropriateness of selected measures and correctness of the measurements. By involving engineers of different interests, e.g. engineers, design architects, testers and managers we could get multiple perspectives and interpretations of what the measures showed.
The exact number of involved engineers and their role are described in detail in papers, because in every part of research there were different involvements of engineers.
38
Methods of data Analysis
8.4
Correlation analyses were used for investigating dependencies of the measures and selecting the measures in an effective way for risk assessment (8.4.1) [31]. Correlograms of measures were developed to visually investigate the dependencies between the measures and separately study the outliers (8.4.2). Time series diagrams have been used for observation of the evolution of measures over development time (8.4.3). Reference groups have been formed for first discussing the appropriateness of the selected measures and then validating drawn conclusions (8.4.4). The information and conclusions extracted from the statistical and analytical operations were communicated with reference groups and discussed for validation.
Figure 14 presents the general overview of the research methods. On the left side of the picture the analytical and statistical tools are presented for analyzing the data and doing inferences. On the right hand the reference group is presented, which helped with interpreting and evaluating the results and provide insights on future research direction.
Based on these two different means, methods and tools for technical risk assessment were developed and evaluated.
39
Correlation Analysis
8.4.1
The correlation analysis was used to identify the dependencies between investigated measures. Correlation analyses are a group of statistical analysis techniques that permits quantifying the linear dependencies between variables. Pearson product-moment correlation coefficient [32] was used for quantification of the measures’ dependencies. Three types of dependencies were investigated in order to make decisions on which metrics to select for risk assessment. These were:
1. Strong positive correlation between two measures. This indicates that the two measures
a. Characterize the measured entity (source code) from the same perspective. Both measures have similar effect on technical risk. In this case only one of the measures has been selected for risk assessment, as including the other do not add additional predictive power for risk assessment b. Have the same cause for magnitude of those
measures. The common cause has been identified and studied. Understanding the cause have provided engineers with more knowledge over the product design
2. Strong negative correlation between two measures. This indicates that the two measures
a. Characterize the measured entity from the same perspective and have opposite effect on technical risk. In this case only one of the measures has been selected for risk assessment, as including the other do not add additional predictive power for risk assessment
b. Have the same cause for magnitude of those measures.
3. Weak or no correlation between two measures: This indicates that the two measures
a. Characterize the measured entity from different perspective and have different effect on technical risk. In this case both measures have been used for risk assessment, as their combined predictive power was greater than any of them used alone
b. Have different causes for magnitude of these two measures
40
The measures are metrics that describe various aspects of software code, such as complexity, changes, size and dependencies. The number of errors for source code has also been collected as a measure of defect-proneness.
Correlograms
8.4.2
Correlograms are statistical correlation visualization techniques which permit visual observation of dependencies, identifying outliers and observing dependency patterns [33]. A correlogram represents multiple diagrams of correlation plots for several variables in one place. In order to visually observe the dependencies of variables correlograms have been developed. The visual observations have permitted us to detect the outlying data points or sub-groups and investigate why they do not follow the main trend of the data. The reasons and possible explanations have been communicated with reference groups and documented. While correlation coefficients can provide a quantitative number on how strong the dependencies are between variables in average, the correlograms allow local observation of subsets of data.
Time series
8.4.3
We have used time series technique for understanding the reasons that influenced the behavior of software measures over time. Time series is an ordered sequence of values of a variable at equally spaced time intervals [34, 35]. In our case the variables are measures that influence technical risks. By understanding why different measures for particular entities change over time we could investigate that entities and understand the reasons behind the changes. The measured entities have been source code files and functions.
Reference Groups
8.4.4
The reference group is a method in social psychology that serves as standard of comparison for respondents [36]. Since then reference group
has been widely used in other fields of qualitative research. In our study reference group was a mean for comparing analytically and statistically obtained results with software engineers’ perception. Two reference groups have been formed: One at Volvo GTT and one at Ericsson, for discussing the results and getting feedback. A part of evaluation is also done by relying on reference groups. A reference group in our case typically has consisted of five to six software engineers including a line manager, a quality manager, design architects and engineers. Software
41
engineers have been responsible for different development activities, thus had sundry perspectives in interpretations of results, which have allowed us to avoid biased conclusions.
VALIDITY EVALUATION
9
FRAMEWORKS USED IN THE THESIS
In this research we have constructed our research relying on studies by and Susman and Evered [26], and Baskerville and Wood-Harper [27]. Susman and Evered assesse the scientific merits of action research and indicate the key conditions that should be held in action research for generating knowledge. These conditions are encapsulated in six characteristics of action research, which we adapted to our research in the following way:
1. Action research is future oriented in dealing with the practical concerns of software engineers. It should permit creating more desirable future for the engineers and organization
2. Action research is collaborative. Independence between researchers and software engineers is essential. The direction of research process should be partly a function of needs and competences of the two
3. Action research implies system development. The research process should encourage the development of the capacity of a system to facilitate, maintain, and regulate the cyclical process of diagnosing, action planning, action taking, evaluating, and specifying learning 4. Action research generates theory grounded in action. The theory should provide a guide for what should be considered in the diagnosis of the organization.
5. Action research is agnostic. The action researcher should recognize that his theories and prescriptions for action are themselves the product of previously taken action, and therefore, are subject for reexamination and reformulation upon entering every new research situation
6. Action research is situational. The action researcher should know that many of the relationship between software engineers, processes and product are a function of the situation as relevant actors currently define it
42
Baskerville and Wood-Harper propose a set of strategies in order to provide rigor, when conducting action research. We strictly followed these strategies in order to overcome challenges we faced in our research. These strategies were as follows:
1. Considering the appropriateness of action research for answering the research question
2. Establishing a formal research agreement between software engineers and researchers
3. Provisioning a theoretical problem statement
4. Planning the measurement methods to support methodical data collection
5. Maintaining collaboration and subject learning
6. Promoting iterations for repetitive action planning, action taking, and evaluating
7. Restraining generalization of results
According to Baskerville and Wood-Harper, the last point of the enumerated strategies is the most problematic to realize when conducting action research. The researchers and engineers are interested in obtaining generalizable results, however the nature of action research restricts it.
According to Checkland and Holwell [37] in order to offset the threat of generalizability one pivotal criterion should be fulfilled. This criterion is the recoverability of the research, which requires the perspicuous representation of research environment and steps of process. This consideration allows the replication of results. Even though the research might not be replicated in the same environment as it has been done originally (and therefore it is not exact replication anymore), the proper documentation of variation points can generate a good insight on produced results. We followed this criterion when conducting our research in different companies.
The aforementioned strategies of action research were adopted in order to construct scientific rigor around our research. Furthermore, all the details of evaluation per action research project are provided in every paper as a separate section of evaluation.
43
PART 2: DEFINING TECHNICAL
44
Abstract
Challenges of technical risk assessment are difficult to address, while its success can benefit software organizations appreciably. Classical definition of risk as a “combination of probability and impact of adverse event” appears not working with technical risk assessment. The main reason of this is the nature of adverse event’s outcome which is rather continuous than discrete. The objective of this study was to scrutinize different aspects of technical risks and provide a definition, which will support effective risk assessment and management in software development organizations. In this study we defined the risk considering the nature of actual risks, emerged in software development. Afterwards, we summarized the software engineers’ view on technical risks as results of three workshops with 15 engineers of four software development companies. The results show that technical risks could be viewed as a combination of uncertainty and magnitude of difference between actual and optimal design of product artifacts and processes. The presented definition is congruent with engineers view on technical risk. It supports risk assessment in a quantitative manner and enables identification of potential product improvement areas.
45
INTRODUCTION
1
Managing risks of inefficient product design is of great importance for large software development organizations. The general features of inefficient design are well-known: defect-prone or unmaintainable code and models, untestable or untraceable requirements, etc. Chittister and Haimes [38] define the technical risk as the probability and impact of an adverse event. Boehm [39] defines the risk similarly and discuss the top ten risks in software development, most of which are related or directly affect software design. The Software Engineering Institute [4] relies on this definition when outlining the risk management processes. In these studies the definition of risk enables risk quantification by regarding the expected loss as a product of probability and impact of an adverse event. In order to avoid the “probability” element from risk quantification, which is not always possible to estimate explicitly, Barki defines risk as a product of uncertainty and loss [40]. Also, there are others, who view the risk as a qualitative concept that can be estimated subjectively [41, 42]. At present, either classical risk management approaches are applied, which view the risks as a combination of discrete values of probability and impact, or qualitative assessment is performed. However, in practice it is rare to have a discrete value of impact. For example, we cannot assume that a software program either will have an error or will not, because the program might have one, ten or 60 errors, and one error might be acceptable for a product. Similarly we cannot expect a piece of code to be either maintainable or unmaintainable, a requirement to be either traceable or not traceable, etc.
The presence of a continuous component in the risk concept disables quantification of risk exposure as a product of probability and impact of an adverse event. As a result no comprehensive definition of technical risk appears to exist in the field of software engineering, which would permit an effective risk assessment. Therefore an open question remains:
How can we define technical risk in order to support effective risk assessment?
The aim of this paper is to explore the essence of technical risk and define it in a manner that it supports risk assessment and management.
In this study we identified a list of technical risks based on input from four large software development companies: Ericsson, Volvo Car Corporation (CC), Volvo Group Truck Technology (GTT) and Saab. We show that the uncertainty on the difference between actual and optimal