A New Pattern Matching Technique for Web
Personalization based on Weighted Association
Mining
Prachi Pandey, Zaved Akhtar, Indradeep Verma, Ramveer Singh
Abstract - Web is overwhelmed with a ton of helpful and futile data. It is exceptionally difficult to characterize helpful data for a specific client which is changing now and again. The valuable data of one specific time may not be helpful on various time or an alternate circumstance. The web itself is concerning step by step with more up to date innovations. Since web is without using style medium that acknowledges organized, non-organized, requested, non-requested organization to give a data in the web, finding the applicable data as well as to design them as per the enthusiasm of a client is likewise a key test today and is known as Web Personalization. The proposed weighting plan can be utilized to quantify the centrality of a thing to a client. Presently we analyze arrangement get to design for weighted pattern tree. We proposed a squashed data model, which is intended to keeps the back to back web get to designs and for creating suggestion rules for client an effective methodology is structured. The work is supported by the implementation and also some of the quantitative work have been provided for the better validation of the work.
Index Terms –Web personalization, patterns, weights, links, user.
I. INTRODUCTION
Constant development in the size and utilization of the World Wide Web forces fresh strategies for plan and improvement of online data administrations. Maximum number of Web structures is substantial and convoluted and clients regularly miss the objective of their request or get equivocal outcomes when they endeavour to explore through them. Then again, the e-business division is quickly developing and the requirement for Web commercial centres that foresee the necessities of the clients is more apparent than any other time in recent memory.
AlongT theseT lines,T theT prerequisiteT forT anticipatingT clientT needsT soT asT toT improveT theT easeT ofT useT andT clientT maintenanceT ofT aT WebT siteT canT beT tendedT toT byT customizingT it.T WebT personalizationT isT characterizedT asT anyT activityT thatT adjustsT theT dataT orT administrationsT givenT byT aT websiteT toT theT requirementsT ofT aT specificT clientT orT aT lotT ofT clients,T exploitingT theT learningT pickedT upT fromT theT clients'T
Revised Manuscript Received on December 22, 2018.
Prachi Pandey, Department of Computer Science & Engineering, Vishveshwarya Group of Institutions, Dadri (Gautam Budha Nagar, U.P.), [email protected]
Zaved Akhtar, Department of Computer Science & Engineering, Vishveshwarya Group of Institutions, Dadri (Gautam Budha Nagar, U.P.), [email protected]
Dr. Indradeep Verma, Department of Computer Science & Engineering, Vishveshwarya Group of Institutions, Dadri (Gautam Budha Nagar, U.P.), [email protected]
Dr. Ramveer Singh, Department of Computer Science & Engineering, Vishveshwarya Group of Institutions, Dadri (Gautam Budha Nagar, U.P.), [email protected]
Navigational conduct and discrete premiums, in mix with the substance and the structure of the Web site. Target of a Web personalization framework is considered to “provide users with the information they want or need, without expecting from them to ask for it explicitly” [Mulvenna et al. 2000] [1].
Key components of Web personalization incorporate
a) Arrangement and pre-handling of Web information,
b) Extraction of relationships between and crosswise over various types of such information, and c) Assurance of the activities that ought to be
suggested by such a personalization framework [Mobasher et al. 2000a] [2].
TheT mainT objectiveT ofT thisT workT isT toT introduceT aT patternT matchingT approachT forT Web
T PersonalizationT basedT onT weightedT associationT miningT forT betterT recommendationT withT respectT toT eachT andT specificT user.T ItT providesT theT meaningfulT informationT orT servicesT toT anT eachT andT specificT userT inT rightT time.T InT thisT approach,T aT WebT PersonalizationT methodT thatT usesT consecutiveT accessT patternT miningT associateT withT weightT factorT withT everyT elementT inT aT pattern.T InT thisT conceptT allocateT aT significantT weightT toT eachT itemT orT webT pageT basedT onT visitingT rateT byT userT onT eachT webT documentT (item)T andT theT timeT spentT onT thatT item.T AnT effectiveT consecutiveT patternT miningT procedureT isT usedT toT recognizeT recurrentT successiveT netT accessT patternsT basedT onT significantT weight.T AT treeT formatT isT constructedT toT keepT theT accessT patternsT knownT asT Pattern-tree,T whichT isT usedT forT equivalentT andT creatingT netT linksT forT betterT suggestions.
II. ISSUES AND CHALLENGES Security and Privacy
Client's security and protection of data is the essential issue in Web Personalization since Personalization depends on clients' private data. Security implies the ability of clients or sites to ensure their information or data against unapproved get to use and change data while protection is the brilliance of being mystery from the nearness of perspective on others.
Fair Dealing and Integrity
These are very important suggestions in managing customers on any E-business [3] site. all clients envision to be dealt with similarly if there should arise an occurrence of conveyance of information, administrations and item yet when it push toward Personalization they act contrastingly dependent on time, premium and cash contributed by the customer just as stature of prior contracts and dependability.
Self Esteem and Sense of Worth
It is proposed by personalization a one of a kind opportunity to save and improve confidence and feeling of worth for clients or users by offering a user– benevolent arrangement in which client feel in charge, significant and loose while having adequate assortments. As clients turn out to be progressively cautious, they may discover Personalization extra fulfilling and alluring, in the event that they could utilize more straightforward over it.
Cost
Truth be told, altering on the web contributions is expected more affordable than adjusting physical merchandise due to the “digital” idea of data products. Through Personalization, web content can be affected effectively to equip singular clients' wishes. In any case, everything relies upon the quantity of clients and customers just as nature of business. Be that as it may, there will be likewise interrelated relations between interests of clients who have related acquiring conduct.
Usability
Personalization must be proposed to be significant and utilizable. This is made likely by offering comprehensive introduction and understandable choices, so the client can make a straightforward choice, most reasonable to their requirements by then of case, inside a satisfactory, brilliant information space. Asset advancement and discovering nature that need to suggest Personalization qualities on their destinations might want to do as such with the declaration that clients will look at the benefit when make utilization of them.
III. LITERATURE REVIEW
Classification based Web Personalization [12] there are two methodologies, the primary methodology is community-oriented separating; this licenses clients to take advantage of other clients' intuitive activities dependent on a level of resemblance between them. Another methodology is ruled based Personalization; instead of coordinating clients' reaction to the web content or outlines of different clients, this framework coordinate that question to a lot of principles or traditions, about client execution.
Framework lumberjack is expected to accumulate clients' web utilization data. We accumulate clients' clicking relies on each hyperlink on the Web pages. By applying a few data mining strategy [4] we can portion information from the log. Category Generator can order the clients into
various gatherings based on log information. Category Generator can distinguish which client has a place with which gathering.
With this methodology, author suggested a unified model for multilevelT WebT PersonalizationT [5].T ForT incorporatingT allT systemT andT strategyT forT personalizationT aT broughtT togetherT modelT isT proposed.T WithT theT unifiedT model,T anyT hypothesisT canT beT acceptedT fromT aT fewT perspectives,T andT eachT understandingT comprisesT ofT differentT dimensions.T AT fewT translationsT andT levelsT giveT betterT Personalization,T creatorT prescribeT theT abuseT ofT theT broughtT togetherT modelT forT staggeredT customerT andT administrationT design,T toT giveT progressivelyT correctT WebT proposalT andT PersonalizationT systems.T AuthorT utilizedT WebT PersonalizationT capacityT toT gaugeT theT fulfillmentT ofT aT supportT ofT aT customerT orT user.
WithT thisT methodology,T aT strategyT proposedT byT authorT dependentT onT content-basedT productT filteringT [6]T ratherT thanT collaborativeT filteringT andT guideline-basedT productT filtering.T TwoT dataT modulesT andT twoT preparingT modulesT areT consideredT inT thisT methodology.T DataT moduleT gatherT theT clientT andT administrationT dataT andT preparingT modulesT areT accustomedT toT estimatingT customerT preferenceT andT productT filteringT [7],T whichT areT theT keyT segmentsT inT thisT WebT PersonalizationT technique.
BasedT onT clients'T presentT conduct,T theT entireT frameworkT givesT theT rundownT ofT prescribedT webT contentT toT theT client.T WithT theT helpT ofT thisT system,T authorT proposedT aT modelT whichT prescribedT administrationT orT itemsT toT theT clientT inT whichT theyT areT keenT on.T ItT discoversT thatT theT clients'T advantageT dependentT onT theirT pastT conductT onT theT webT [8].T InT thisT methodologyT weT haveT toT gatherT preparingT informationT likeT pastT snapT history,T clients'T intriguedT spaceT thenT theseT dataT andT storeT itT intoT theT learningT baseT forT betterT suggestionT AuthorT utilizedT k-T meansT algorithmT toT bunchT theT informationT andT k-closestT calculationT toT getT comparableT recordT inT theT informationT base.
WithT theT helpT ofT thisT methodology,T authorsT broadenedT theT regularT affiliationT ruleT techniqueT byT dolingT outT aT criticalT weightT [9]T toT everythingT inT anT exchangeT toT lookT atT theT significanceT ofT everythingT insideT theT exchangeT andT expandT anotherT algorithmT dependentT onT anticipatedT weightedT affiliationT ruleT miningT strategy.T DuringT thisT weightedT affiliationT ruleT miningT approach,T creatorT relegatedT aT quantitativeT loadT toT everythingT byT timeT spentT onT eachT pageT andT visitT tallyT ofT eachT pageT ratherT thanT customaryT twofoldT loads.T InT theT weightedT mapping,T timeT spentT onT aT pageT andT visitT tallyT ofT aT pageT isT utilizedT toT inspectT itsT centralityT inT everyT transactionT [10]. LengthT ofT timeT spentT onT eachT page,T itT uncoversT theT noteworthinessT ofT eachT pageT toT theT individualT client,T onT theT groundsT thatT aT clientT investT moreT energyT inT additionallyT fascinatingT thing,T inT theT eventT thatT he/sheT isn'tT keenT onT aT page,T he/sheT byT andT largeT changeT toT intriguingT orT newT pageT quickly.T InT anyT case,T a fast skip may likewise happen because of minimal size of a page so the extent of a page may impact the genuine time spent on everything.
TheT pertinenceT inputT strategiesT [11]T areT utilizedT toT recoverT theT report.T
web,T locateT theT intriguedT subjects,T andT getT theT foundationT informationT worriedT withT theT themeT ofT intrigue.T InT thisT methodology,T authorT proposedT significanceT inputT dependentT onT catchphraseT map,T whichT finishT upT theT customer'sT expectationT fromT theT watchwordT space.T ThisT methodologyT isT superiorT toT anythingT theT conventionalT importanceT inputT methodology,T asT theT clients'T inclinationsT areT anticipatedT onT watchwordT spaceT ratherT thanT reportT space,T inT whichT inquiriesT areT spokenT toT theT searchT engines.T ImportanceT criticismT canT beT possibleT ifT theT frameworkT canT finishT upT theT client'sT inclinationsT fromT theT watchwordT mapT modifiedT byT him.
.
IV. RESEARCH METHODOLOGY
In the weighting schematic, the time spent on a page and clicking tally of site pages is utilized to analyse importance of the site pages in a transaction, so as to take out the client's attention more precisely as opposed to the parallel loads which is considered in last examinations. Duration is the time used on web content, it copies the importance of web content, in light of the fact that a consumer by and large give additional time on an extra intriguing thing in such a case that a client isn't engaged with that thing, he don't commit much time on that thing or content and as often as possible change to elective thing quickly. Nonetheless, a client may change because of the little element of web content so the measure of substance may impact the genuine staying time. Along these lines, the length is determined from equation 1.
Frequency is the how frequently that a web content or web archive is opened by various clients. It is expected that web archives with a most extreme visiting rate are of higher significance to clients. An indispensable factor that must be estimated in the assessing the frequency of a report is the in- degree of that record. The likelihood to visit a site page will be higher with vast in-degree than little in-degree. When contrasting two web contents and same frequency, the substance with minor in-degree has higher significance. The formula of frequency is given in equation 2. We utilize time used by a client for watching a web substance and rate of visiting as two critical bits of certainties in registering the client's mindfulness on that content, so allocate an impressive weight (equation 3) to each content or thing in a transaction based on these definitions.
Size(I)
(I)
Time spent
)
Duration(I
(1)ree(I) In-visit(I) Number of I) Frequency( deg
(2)
I) Duration( I)
Frequency(
Weight(I) (3)
T GiveT ST aT chanceT toT beT theT sequenceT ofT eventsT orT pagesT thatT areT gottenT toT byT theT client.AT webT accessT orderT ST =T e1e2…enT (ei∈E)T forT 1≤i≤nT isT aT well-orderedT groupT (series)T ofT accessT itemsT orT pages.T Event-repetitionsT areT permittedT i.e.T itT isT notT essentialT thatT ejT ≠T
ejT forT i≠jT inT S.T AssumeT thatT itemT accessT canT beT
recappedT inT aT accessT seriesT orT order.AT webT accessT sequenceT ST isT calledT aT sequentialT webT accessT pattern,T ifT weight(S)T ≥T Avg.T weight,T whereT isT Avg.T weightT aT givenT
weightT threshold.T AnT accessT itemT ei∈ET isT knownT asT significantT item,T ifT weightT (Ii)T ≥T Avg.T weight.T Otherwise,T itT isT knownT asT insignificantT item.AverageT weightT ofT eachT sequenceT isT calculatedT byT thisT equ.T 4:
level in i quence(m) Pattern Se Number of W t
Avg. Weigh th
m
j j
1 (4)
Algorithm: Weighted Pattern-tree I/p: Web Access Sequence
Consecutive Web Access Pattern created on weight
O/p: T – Weighted Pattern-tree: Scheme:
a. Generate an void source node N
b. For each order SϵWSWAP, signified as S = e1e2…en, do
c. Set present _node point to N. d. For i = 1 to n do,
The Recommendation Rules Generation module finds the most fitting access track in the Pattern tree based on customer's present access succession. Fulfilment and exactness are some estimation estimates wanted to appraise the importance of the recommended model. Proposed technique removed examples are kept in the Pattern-tree, which is then utilized for indistinguishable and delivering net connections for recommendation. In this methodology we consider the size lengthiest track in the Pattern-tree is the profundity of the Pattern tree. The relating track won't happen when the span of the present access request is lengthier than the profundity of the Pattern-tree. Subsequently, some early items can be disconnected to make the present access request shorter than the profundity of the Pattern-tree prior the request coordinating method starts.
Algorithm: Recommendation Rules Generation I/p:
T – Weighted Pattern-tree
S = e1e2…en - present access order of a customer MinL - minimum length of access order
MaxL - maximum length of access order, (less than the depth of tree)
O/p:
RR – recommendation rule of a group of sequenced access items for S.
Scheme: a: Reset RR =Ø.
b: If |S| > MaxL then eliminate the first |S|- MaxL+1 events from S.
c: If |S| < MinL then return RR, otherwise set present
V. RESULT AND DISCUSSION
WhileT performingT theT calculationT theT pertinenceT ofT theT proposedT methodologyT twoT parametersT areT utilizedT forT theT assessmentT ofT results.T TheseT twoT parametersT areT exactnessT orT precisionT andT fulfillmentT orT satisfaction.T TheT quantityT ofT suggestedT thingT (siteT pages)T isT utilizedT forT figuringT theT estimationT ofT accuracy.T PrecisionT computedT howT toT
satisfactionT howT likelyT aT clientT isT consecutivelyT fulfilled.T TheT precisionT [12]T andT satisfactionT inT scientificT structureT canT beT spokenT toT as:
(R) mmendation Total reco
) on ( commendati Correct re
ecision
R
cPr (5)
) sequence ( commended
) sequence ( commended
Visited re on
Satisfacti
R
R
svs Re
(6)
[image:4.595.315.543.56.199.2] [image:4.595.41.295.286.424.2]TheT precisionT isT fundamentalT asT itT takesT careT forT decidingT howT plausibleT aT clientT visitT theT prescribedT pagesT thatT areT recommendedT byT theT framework.T What'sT more,T satisfactionT helpsT inT decidingT howT conceivableT aT clientT visitT theT prescribedT pagesT successively,T he/sheT isT consecutivelyT fulfilledT orT not.
Table IPerformance Comparison of personalization based on User Access
Pattern and proposed work on the basis of precision
User
Personalization based on User Access Pattern
Proposed Method
R Rc Precision R Rc Precision
A 6 4 0.66 5 4 0.80
B 7 5 0.71 5 5 1
C 6 3 0.50 5 3 0.60
D 5 4 0.80 5 4 o.80
E 7 5 0.71 5 5 1
F 5 5 1 5 5 1
G 6 4 0.66 5 4 0.80
H 8 5 0.62 5 5 1
[image:4.595.306.555.296.482.2]It can be clearly seen from the table I that proposed work retrieved more relevant forms from existing approach based on User Access Pattern. The value of precision is greater than the existing approach. It may be possible that the value of precision is equal to the existing approach due to change in user’s interest.
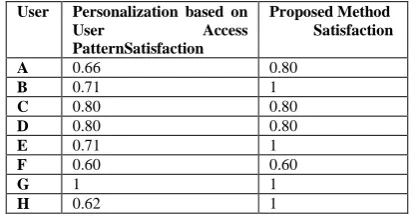
Table IIPerformance Comparison of personalization based on User Access
Pattern and proposed work on the basis of satisfaction
User Personalization based on
User Access
PatternSatisfaction
Proposed Method Satisfaction
A 0.66 0.80
B 0.71 1
C 0.80 0.80
D 0.80 0.80
E 0.71 1
F 0.60 0.60
G 1 1
H 0.62 1
Similarly, from table II it can be seen that there is increase in satisfaction or sometimes it is equal. The proposed work has higher satisfaction to the Personalization based on User Access Pattern.
Initial window at start of execution
Fig.1. Depicts the initial window at the start of execution, when the user must login to his or her account
GUI interface showing the welcome page which actually considers the visit count and estimates the frequency of represented webpages.
Window for access the domain
Fig. 2. GUI snapshot 2.
Above represented images shows the recommendation considered by the browser implemented using the proposed methodology.
Window for weighted item
Fig.3. GUI snapshot 3.
Above image shows the calculation of the weights on the basis of mathematical
[image:4.595.64.273.536.644.2] [image:4.595.311.546.551.725.2]computed weights are about the visit count and the frequency of visiting the particular link.
[image:5.595.41.560.41.780.2]Windows for Pattern sequence
Fig. 4. GUI snapshot 4.
The time span based recommendations are being considered for the user on the basis of the past patterns considered by the user.
Fig. 5.GUI snapshot 5.
Fig. 6. GUI snapshot 6.
[image:5.595.49.295.84.313.2]Fig.7. GUI snapshot 7.
Fig. 8. GUI snapshot 8.
Fig. 9. GUI snapshot 9.
Fig. 10.GUI snapshot 10.
VI. RESULT AND DISCUSSION
TheT designT orT architectureT thatT isT utilizedT forT hugeT weightT andT clientT getT toT designT forT onlineT suggestionT isT proposed,T whichT isT anT improvementT overT UserT AccessT
[image:5.595.54.452.370.751.2]utilizesT successiveT accessT designT miningT partnerT withT weightT parameterT withT everythingT inT anT example.T AtT firstT weT appointedT aT quantitativeT loadT toT everythingT byT timeT spentT onT eachT pageT andT visitT checkT ofT eachT pageT ratherT thanT customaryT twofoldT loads.T InT theT weightedT pattern,T timeT spentT onT aT pageT andT visitT checkT ofT aT pageT isT utilizedT toT inspectT itsT hugenessT inT everyT exchange.T LaterT weT planT aT squashedT informationT model,T termedT asT Pattern-treeT thatT keepsT theT progressiveT webT getT toT designs,T andT forT creatingT suggestionT rulesT forT client.T Pre-processingT ofT informationT mustT beT connectedT onT theT webT logsT goingT beforeT toT performT designT mining;T theT pre-processingT techniquesT utilizedT informationT cleaning,T informationT changingT toT setT upT thatT informationT forT anotherT procedure.T AlongT theseT linesT proposedT workT utilizingT weightT parameterT andT accessT designT forT onlineT suggestionT canT helpsT inT removingT richT andT highT elementT ofT dataT withT noteworthyT developmentT inT reviewT andT fulfillmentT ofT wishes.
REFERENCES
[1] Z.T Maamar,T G.T AlkhatibT andT S.K.T Mostefaoui,T “Context-basedT PersonalizationT ofT WebT ServicesT CompositionT andT
Provisioning,”T ProceedingsT ofT theT 30thT EUROMICROT
ConferenceT (EUROMICRO’04)T IEEET 2004.
[2] M.T EirinakiT andT M.T Vazirgiannis,T “WebT MiningT forT
WebPersonalization,”T ACMT TransactionsT onT InternetT
Technology,T VolT 3FebruaryT 2003.
[3] B.T Hua,T K.T WaiT WongT andT C.T C.T Fung,T “FuzzyT
LogicT BasedT ProductT FilteringT forT WebT PersonalizationT
InT E-Commerce,”T IEEET 2007.
[4] M.T LieT andT L.T Fan,T “AT WebT PersonalizationT SystemT
BasedT onT Users’T InterestedT Domains,”T Proc.T 7thT IEEET
Int.T Conf.T onT CognitiveT InformaticsT (ICCI'08)-IEEET 2008,T
pp.153-159.
[5] T.T Zhu,T R.T Greiner,T andT G.T Haubl,T “LearningT aT modelT
ofT aT webT user’sT interest,”T publishedT inT UserT ModelingT -UMT 2003,T pp.T 65–75.
[6] R.T Forsati,T M.T R.T MeybodiT andT A.T G.T Neiat,T “WebT
PageT PersonalizationT basedT onT WeightedT AssociationT
Rules,”T InternationalConferenceT onT ElectronicsT ComputerT Technology,T IEEET 2009,pp.130-135.
[7] C.H.T Cai,T A.W.C.T Fu,T C.H.T ChengT andT W.W.T Kwong,”T
MiningT AssociationT RulesT withT WeightedT Items”,T InT
DatabaseT EngineeringT andT ApplicationsT Symposium,T
ProceedingsT IDEAS'98,T JulyT 1998,T pp.T 68T –T 77.T
[8] F.T Tao,T F.T MurtaghT andT M.T Farid,”T WeightedT
AssociationT RuleT MiningT usingT WeightedT SupportT andT
SignificanceT Framework”,T InT ProceedingsT ofT theT 9thT
SIGKDDT Conference,T 2003.
[9] R.T SrikantT andT R.T Agrawal,T “MiningT sequentialT patterns:T
generalizationsT andT performanceT improvements,”T Proc.T ofT
theT 5thT InternationalT ConferenceT onT ExtendingT DatabaseT
TechnologyT (EDBT),T Avignon,T France,T 1996,T pp.T 3-17. [10]C.T C.T Chang,T P.T Chen,T F.T ChiuT andT Y.T Chen,T
“ApplicationT ofT neuralT networksT andT Kano’sT methodT toT
contentT recommendationT inT webT personalization,”T AnT
InternationalT JournalT onT ExpertT SystemsT withT Applications,T
ELSEVIERT 2009,T pp.5310-5316.
[11]A.T C.T M.T Fong,T B.T Zhou,T S.T C.T Hui,T G.Y.T Hong,T
andT T.A.T Do,T “WebT ContentT RecommenderT SystemT
basedT onT ConsumerT BehaviorT Modeling,”T IEEET
TransactionsT onT ConsumerT Electronics,T Vol.T 57,T No.T 2,T
MayT 2011,pp.962-969.
[12]W.T Xiao-GangT andT L.T Yue,T “WebT MiningT BasedT onT
UserT AccessT PatternsT forT WebT Personalization,”T IEEET