Contextualization: dynamic configuration of virtual machines
Full text
Figure

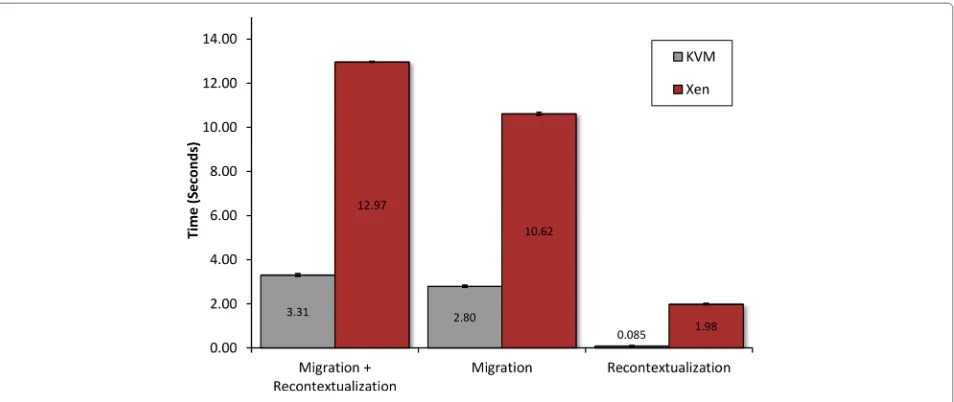
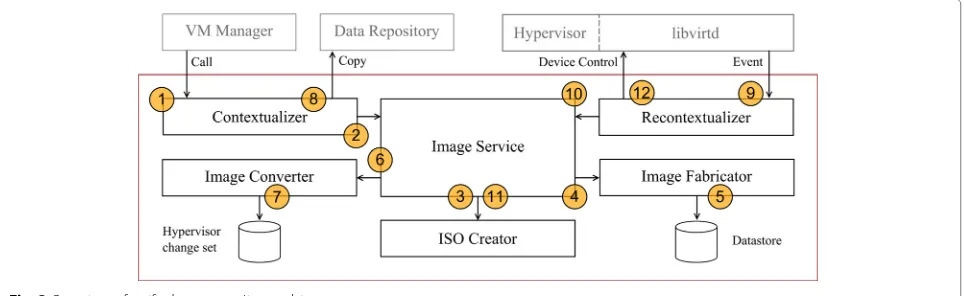
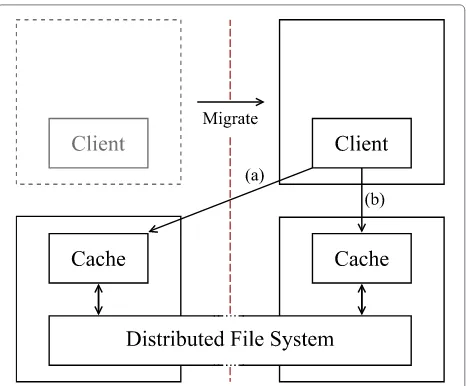
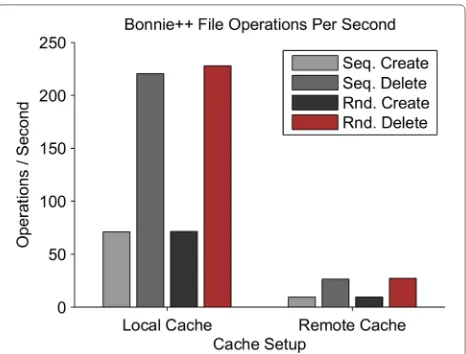
Related documents
In simple terms, Configuration Management is a Service Management process which is part of the high level Service Asset and Configuration Management process to manage
SCAP was introduced by NIST National Institute of Standards and Technology in 2006 and SCAP can be used for management of configuration settings Improper configuration setting
• Dynamic Host Configuration Protocol (DHCP) for auto address configuration to the IP network • Cisco Discovery Protocol for Cisco Unified IP Conference Station 7936 to Cisco
As with an IP address, virtual router interface addresses using Virtual Router Redundancy Protocol (VRRP) are also used for device management.. For Simple Network Management
• ProCurve Switch VLAN and Route Configuration • ProCurve Threat Management Services zl Module Installation and Configuration • BIG-IP Platform Configuration • BIG-IP
Alert Notifications Manage device management settings Alerts Configuration Manage device management settings Unconfigured Devices Manage device management settings SyncThru Update
Therefore, regardless of whether the elasticity-adjusted Lerner index or traditional Lerner index is adopted as the indicator to measure competition, we conclude that Chinese
This Chapter This chapter describes the PCI Express hot plug model. A standard usage model is also defined for all devices and form factors
