International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-11, September 2019
Efficient Computational linguistics Framework for
Concept Drift Detection
A.Uma Maheswari, N.Revathy
ABSTRACT: Semantic drift is a common problem in iterative information extraction. Unsupervised bagging and incorporated distributional similarity is used to reduce the difficulty of semantic drift in iterative bootstrapping algorithms, particularly when extracting large semantic lexicons. Compared to previous approaches which usually incur substantial loss in recall, DP-based cleaning method can effectively clean a large proportion of semantic drift errors while keeping a high recall.
Keywords: Drifting Points, Deep Neural Network, Information Retrieval, Lexical Semantics, computational phonetics or word elucidation (WSD)
I. INTRODUCTION
1.1 Lexical Semantics
I
n language process, computational phonetics or word elucidation (WSD) is that the issue of formative that meaning of a word is triggered by the utilization in an exceedingly specific perspective, a practice that seems to be for the most part insensible in individuals Computational linguistics may be natural taxonomy problem. The options of the framework offer the indication for classification On English, exactness at the coarse-grained (homograph) level is habitually on top 90 percent. Withseveralways on specific homographs attaining above96 percent. On finer- grained intellect characteristics. Highprecisions from 59.1 percent to 69.0 percent arestated in currentestimation workouts, wherever the standardexactitude of the modest possible method always selecting the maximum recurrent sense was 51.4 percent and 57 percent respectively[1]. The main attempt is to outline, examine and eventuallycomprehend the associations among x "meaning", "word"and "context".1.2 Information Retrieval
Ambiguity must be settled in certain questions. For example, specified the question"depression" would the system return manuscripts about weather systems, illness or economics? Present IR systems (for instance Web search engines), resembling MT, do not expend a WSD module; they depend on the user keyingadequate context in the question to only recovermanuscriptspertinent to the proposedintellect (e g., "tropical depression”). In a procedure named mutual disambiguation, reminiscent of the Leskapproach (below), all the indistinctterms are disambiguated by quality of the proposedintellects co-occurring in the identical manuscript.
Revised Manuscript Received on September 20, 2019.
Ms.A.Uma Maheswari1, Ph.D Research Scholar, Department of
Computer Science, Hindusthan College of Arts and Science, Coimbatore, India. Email:[email protected]
Dr.N.Revathy2, Professor, PG and Research Department of Computer
Applications, Hindusthan College of Arts and Science, Coimbatore, India, [email protected]
1.3 Information extraction and knowledge procurement
In information extraction and text mining, WSD is essential for the precise examination of content a few presentations For example, an insight gathering framework would perhaps got the chance to banner up references to, state, arbitrary drug, rather than restorative prescription.
Bioinformatics investigation needs the connections among qualities and quality item to be recorded from the immense logical writing; be that as it may, qualities and their proteins frequently commonly have comparative name More often than not, (he Semantic Web requires programmed explanation of records as per reference philosophy. WSD is only starling to be connected in these zones.
1.4 Supervised Machine Learning Methods
Supervised machine learning method might be coaching a number of words categorized in context through their sense accustomed to train a classifier which could tag words in different text. Summary of anything we desire the lag set (‘‘sense inventory”) to coach the corpus[22]
1.5 Evaluation
The evaluation of WSD systems needs a lake a look at corpus hand-marked with the focus or corrects intellects and accepts that such a corpus is made. Two key implementation procedures arc expended namely
Precision: the proportion of system tasks created that arc precise.
Recall: the proportion of overall word examples properly employed through a system
If a system creates a task for each term, subsequently exactness and recollect measures are identical, and might be referred as accuracy. This standard has been expanded to need under contemplation systems that come a group of intellects with weights for each incidence.
Two types of test corpora are there:
Lexical sample: the existences of a tiny low example of focus terms acquired to be disambiguated and
All-words: all the terms in an exceedingly piece of operation text acquired to be disambiguated.
The second is deemed an additional accurate sort of analysis, however the corpus is further costly to create since human annotators have to recite the meanings for every term in the sequence each- time they want to construct a tagging judgment, instead of once for a unit of examples for an identical target term
II. LITERATURE REVIEW
WSD was initially stated as a discrete computational task throughout the early days of machine translation in the year 1940s. Creating it one among the oldest problems in linguistics. In the year1970s, WSD was a sub task of linguistics semantic supportive systems city at interims the segment of
However, because WSD systems were the foremost rule-based and hand-coded they were prone to an information procurement bottleneck In the year 2000s supervised methods spread an upland in exactness, at that point responsiveness has moved to coarser-grained intellects, semi-supervised and unattended corpus-based techniques, domain adaptation, mixtures of different ways, likewise the return of knowledge-based methods through graph-based systems. However, supervised techniques endure to perform best [1]
The CINDOR cross-language knowledge retrieval system (Dickcma el al. 1998) practices an information building called "conceptual interlingua" for request and document depiction. This conceptual Interlingua is a hierarchically systematized multilingual notion lexicon, which is organized following WordNet (Miller, 1990). By demonstrating request and document words through their WordNetsynset numbers we reach at effectively a language neutral depiction comprising of synset numbers demonstrating conceptions. This depiction simplifies cross-language recovery by matching team synonyms in English in addition to across lingos.
Nevertheless, numerous words are polysemous and be appropriate to several synsets, resulting in unauthentic equivalents in retrieval |2|. Despite the growing significance of Information Retrieval (IR) methods as data retrieval tools, the implementation of maximum of these methods has not yet touched a satisfactory level. Word sense uncertainty is one among the elucidations for her or his poor presentation. Disabling this issue might enhance IR implementation. Documents connected to an IR request normally comprise only the synonyms of the request terms rather than the request terms themselves. A modest IR system with no understanding of synonyms flops to identify the relevance of these documents to the request. Hence, we could develop recall of IR systems via taking into consideration the synonyms of the request terms as a portion of the IR query. Nevertheless, only related synonyms of the request terms in the specified context provide suitable information to the request. We could recognize these pertinent synonyms with the support of an elucidation procedure [3].
The technique MC-WSD conferred for land Lexical Sample task. The technique is foreseen on a multicomponent design. It comprises of 1 classifier with 2 components. One is coached on the data offered for the job. The second is coached on this data and moreover, on an external teaching set extricated from the wordnet annotations. The objective of the supplementary element is to reduce sparse data issues by manipulating the information programmed in the ontology |4|.
Machine learning approaches for word intellect elucidation will stimulate classifiers that show extreme precision at the assignment of disambiguating homonyms. Homonyms recommends that means terms with numerous dissimilar meanings. Outcomes from a user study that related 2 versions of a terminology training system, one that pragmatic word intellect elucidation to support knowledge and one more did not, support refusal of the null hypothesis that acquiring results with and without word intellect elucidation are comparable, with a p-value of 0.0011[5]. The task of WSD comprises of conveying the correct sense to terms by means of an electronic vocabulary as the source of term meanings. The author grants 2 WSD techniques grounded on 2 key operational approaches in this study: a
knowledge-based approach and a corpus-based approach. Our proposal is that term-sense elucidation desires numerous data sources so as to explain the semantic indistinctness of the terms. These causes can be of diverse types for instance, paradigmatic, syntagmatic or numerical information |6|. Though instinctive sense elucidation (WSD) remains a significantly more problematic task than Pit of Speech (POS) disambiguation, resources and programmed techniques are starling to perform. Presenting automatic WSD by means of a specifically-adapted form of Brill's error determined unsupervised learning program (Brill, 1997), eventually advanced for POS tagging|7|
International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-11, September 2019
The author intended an unsupervised approach which will precisely disambiguate word intellects in a huge, entirely untagged corpus. The approach eludes the necessity for expensive hand-tagged training data by using 2 dominant properties of human language: 1. One intellect per association: adjoining terms offer reliable and strong indications to the sense of a target term, restrictive on relative space, order and syntactic connection. 2. One intellect per discourse: The intellect of a target term is extremely reliable within any specified document [11].
An approach for word intellect elucidation with remarkably huge semantic systems (VLSN) that records the score that depend upon the measure of shared terms in definition. We tentatively display to what degree the terms in like manner ought to be scanned for. The creator additionally demonstrates the scoring degree that considers the level of significance of terms in explanation [12].
Lexical taxonomies namely Word Net are significant supplies underlying normal verbal processing methods such as machine interpretation and word-intellect disambiguation. Nevertheless, designing and preserving such taxonomies physically is a monotonous and timewasting task. This has directed to a great pact of significance in automatic approaches for retrieving taxonomic associations. Struggles for both manual growth of taxonomies and instinctive acquisition approaches have mostly attentive on English-language resources. Though WordNets survive for numerous languages, these are typically much trivial than Princeton WordNet (PWN) [13], the main semantic source for English.
Habitually constructing very large neural networks (VLNNs) from explanation texts in machine-readable vocabularies, and reveal the usage of these networks for word intellect disambiguation. Our technique brings together 2 earlier, autonomous techniques to word intellect disambiguation: the usage of machine-readable vocabularies and connectionnist paradigms. The automatic creation of VLNNs permits real-size trials with neural networks for natural language processing, which in succession offers insight into their performance and design, could lead to acquire enhancements [14].
Natural language processing (NLP) is a ground of computer science concerned with the communications between humans (natural) and computer languages. Natural language generation procedures translate information from computer catalogs into legible human language. Natural language considerable techniques translate samples of human language into further prescribed exemplifications that are comfortable for computer programs to operate. Numerous issues within NLP pertain to both creation and understanding: for instance, a computer must be proficient to model morphology (the construction of terms) so as to comprehend an English sentence, however a model of morphology is similarly desired for creating a grammatically exact English sentence [11].
The requirement for vigorous lexical and semantic data to aid sensible normal language preparing (NLP) applications is outstanding Machine-meaningful adaptations of regular word references have been viewed as an imaginable wellspring of data for usage in NLP since they comprise a huge measure of semantic and lexical learning gathered together above long periods of exertion by etymologists. Extensive study has been dedicated to concocting strategies to eradicate this data from word
references [15]. The authors pertain an extending activation scheme which ultimately recognizes the intellect of every input term that shares the maximum relations with new input (context) terms. The semantic network and connectionnist techniques stated above, depend on semantic perspective for disambiguation, and hence follows from effort in lexical consistency which exhibits that so as to create text unity, persons repeat terms in a specified conceptual group or which are semantically connected. Result from the network is the text with every term marked with its suitable sense, which in succession serve as input to other processes [16].
In this paper, a novel WSD technique is proposed to create the context of an ambiguous term by expending correspondences between an ambiguous term and terms in the input manuscript. Moreover, to influence our WSD technique, we further suggest a novel term relationship calculation technique grounded on the semantic network construction of Babel Net. We assess the recommended techniques on the SemEval-2013 and ScinEval-2015 for English WSD dataset. Experimental outcomes reveal that the proposed WSD technique considerably improves the baseline WSD technique. Moreover, our WSD technique is better than contemporary WSD techniques in the Semeval-13 dataset. Conclusively, it has greater performance than the contemporary unsupervised knowledge-based WSD method in the typical execution of both datasets [21].
III. PROPOSED METHOD
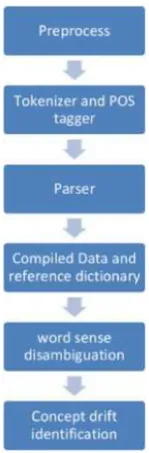
[image:4.595.307.547.305.429.2]The issue of the dynamic fundamental connections in (he information is called idea float in (he field of AI. This paper provides a structure for discovering concept drift. It works with the situation of the linguistic processing. The progression engaged with the system is as depicted in the figure 1.
Figure 1: Framework overview diagram
IV. ILLUSTRATION OF THE PROPOSED
METHOD
The framework in implemented using the python and nltktoolkit is deployed for the purpose of the linguistic processing. The word net tool is additionally deployed for the reference wordbook for the example correlation, language information. It provides easy-to-use interfaces to over 50 corpora and NK3K is a main stage for structure Python projects to work with human lexical resources like Word Net. Along with a suite of text processing libraries for classification, tokenation, stemming,lagging, parsing, semantic reasoning, wrappers for industrial- strength NLP libraries 1231.
The system in executed utilizing the python and nltk toolbox is sent with the end goal of the etymological preparing. The wordnet apparatus is also conveyed for the reference wordbook for the example correlation NLTK is a
main stage for structure Python projects to work with human Step 1: Tokenize
Library referred: # import SpaceTokenizer() method from nltk
Sample: gfg = "Good for Good.. .$$&* \nis\t for good"
Step 2:Lemmatizer
Library referred: from nltk.stem import WordNetLemmatizer lemmatizer = WordNetLemmatizer()
Step 3: Chunker
Library referred: from nltk import pos_tag from nltk import RegexpParser
Sample: text ="buy the slippers in offer price in bata shop coimbatore".split()
Running script: "C:\Users\ADMIN\Desktop\p1.py"
After Split: ['buy', 'the', 'slippers', 'in', 'offer', 'price', 'in', 'bata', 'shop', 'coimbatore']
After Token: [('buy', 'VB'), ('the', 'DT'), ('slippers', 'NNS'), ('in', 'IN'), ('offer', 'NN'), ('price', 'NN'), ('in', 'IN'), ('bata', 'NN'), ('shop', 'NN'), ('coimbatore', 'NN')]
After Regex: chunk.RegexpParser with 1 stages: RegexpChunkParser with 1 rules:
<ChunkRule: '<NN.?>*<VBD.?>*<JJ.?>*<CC>?'>
After Chunking (S buy/VB the/DT (mychunk slippers/NNS) in/IN (mychunk offer/NN price/NN) in/IN
(mychunkbata/NN shop/NN coimbatore/NN)) Step 4: Word tokenize and parsing
[image:4.595.126.201.326.554.2]International Journal of Innovative Technology and Exploring Engineering (IJITEE) ISSN: 2278-3075, Volume-8 Issue-11, September 2019
text = "Learn from leaders Hindusthan College"
Step 5: Compiled data and reference dictionary – Word sense Disambiguation
Import nltk
fromnltk.corpus import wordnet synonyms = []
antonyms = []
Sample 1: For syn in wordnet.synsets("good"): Running script: "C:\Users\ADMIN\Desktop\p1.py" {'dependable', 'full', 'adept', 'good', 'respectable', 'honorable', 'secure', 'near', 'serious', 'dear', 'estimable', 'honest',
'goodness', 'thoroughly', 'practiced', 'right', 'unspoilt', 'skilful', 'upright', 'effective', 'soundly', 'unspoiled', 'in_force', 'just', 'well', 'salutary', 'sound', 'expert', 'skillful', 'commodity', 'proficient', 'ripe', 'safe', 'beneficial', 'trade_good', 'in_effect', 'undecomposed'}
{'evilness', 'bad', 'ill', 'evil', 'badness'}
Sample 2: for syn in wordnet.synsets("pass"): Running script: "C:\Users\ADMIN\Desktop\p1.py" {'hap', 'go_across', 'qualifying', 'croak', 'transcend', 'die', 'go_through', 'o
verhaul', 'slide_by', 'reach', 'egest', 'go_past', 'decease', 'strait', 'lapse',
'base_on_balls', 'authorise', 'hand', 'offer', 'laissez_passer', 'expire', 'ove
rtake', 'devolve', 'overstep', 'give-up_the_ghost', 'notch', 'pass_along', 'put_
across', 'whirl', 'snuff_it', 'fall', 'straits', 'passing_game', 'choke', 'elaps
e', 'turn_over', "cash_in_one's_chips", 'pas', 'conk', 'excrete', 'evanesce', 'h
ead', 'pop_off', 'pass_away', 'walk', 'fade', 'crack', 'slip_by', 'top', 'bye',
'happen', 'draw', 'sink', 'return', 'drop_dead', 'flip', 'extend', 'kick_the_buc
ket', 'make_it', 'surpass', 'travel_by', 'fall_out', 'passing_play', 'blow_over'
, 'fleet', 'mountain_pass', 'clear', 'slip_away', 'go', 'authorize', 'come_about
', 'go_by', 'run', 'make_pass', 'exit', 'spend', 'pass', 'passing',
'passport',
'pass_by', 'toss', 'lead', 'fling', 'guide', 'go_on', 'exceed', 'give', 'communi
cate', 'pass_off', 'take_place', 'glide_by', 'liberty_chit', 'buy_the_farm', 'oc
cur', 'pass_on', 'perish', 'eliminate', 'go_along', 'legislate'} {'fail', 'failing', 'running', 'be_born'}
Step 6: Concept drift identification From nltk.corpus import wordnet
Sample 1: "slipper" slipper.n.01
slipper low footwear that can be slipped on and off easily; usually worn indoors[]
This framework makes a consequent processing and detection of the concept drift in word and it virtually separates the word and makes the prediction of the synonym as of the current situation.
V. CONCLUSION
This paper proposes a straightforward and effective linguistic process for the detection of the conception drift.The subsequent process makes the narrow down of the literal meaning. It is effective and also the drift identification is carried out using the framework in effective manner. The paper is that the bases work wherever the dataset is compiled in units. In the upcoming paper the future work focuses on designing the automated annotating system to make the linguistic processing to detect the concept drift.
REFERENCES
1. https://en. wikipedia.org/wiki/WSD
2. Mary Xiaoyong Liu. Ted Diamond, and Anne R. Dickcma, “Word
Sense Disambiguation for Cross-Language Information Retrieval ’, School of Information Studies. 1996.
3. [3|Boris Katz, OzlemUzuncr&DenizYurcl/' Word Sense
Disambiguation for Information Retrieval”, Artificial Intelligence Laboratory Massachusetts Institute of Technology, 2000
4. [4]MassimilianoCiaramila and Mark Johnson, ‘’Multi-Component
Word Sense Disambiguation”, Association for Computational Linguistics. 2004.
5. [5|Anagha Kulkarni. Michael Heilman. Maxine Eskcnazi and Jamie
Callan.” Word Sense Disambiguation for Vocabulary Learning’s 2000.
6. Andres Montoyo. Armando Su arez. German Rigau. Manuel Palomar."
Combining Knowledge- and Corpus-based
Word-Sense-Disambiguation Methods’, Journal of Artificial
7. Luca Dini and Vittorio Di Tomaso.“Error Driven Word Sense Disambiguation", 200L
8. Mark Sanderson,” Word sense disambiguation and information
retrieval”, Ph D thesis. 1996.
9. Gondy Leroy a and Thomas C, Rindficsch.” Effects of information and
machine learning algorithms on word sense disambiguation with small datasets”, International Journal of Medical Informatics (2005).
10. https://www.cse.iitb.ac.in/~pb/papcrs/soft-wsd.pdf
11. David Yarowsky, " Unsupervised word sense disambiguation rivaling
supervised methods ', Department of Computer and Information Science, University of Pennsylvania
12. kumura Manabu. MatsunagaYuukichi, "Word Sense Disambiguation
By Marker Passing on Very Large Semantic Networks,” Natural Language Processing Pacific Rim Symposium 1995.
13. Jean VERONIS and Nancy M. IDE, ‘"Word Sense Disambiguation
with Very Large Neural Networks Extracted from Machine Readable Dictionaries”, COLING'90. Helsinki. August 1990
14. Nancy Idc and Jean Veronis, ‘"Extracting knowledge bases from
machine readable dictionaries: have we wasted our time?”
15. Jean Veronis. Nancy Ide.” large neural networks for the resolution of
lexical ambiguity” 1998.
16. Raymond J. Mooney ’"Natural Language Processing: Word Sense
Disambiguation", 2001
17. Nancy Idc and Jean Veronis. “Introduction to the Special Issue on Word Sense Disambiguation: The Slate of the Art”, Association for Computational Linguistics, Volume 24, Number 1,1998.
18. Ioannis P. Klapaflis, Suresh Manandhar. '"Google &WordNet based
Word Sense Disambiguation", Proceedings of the 22nd 1CML
Workshop on Learning & Extending Ontologies, Bonn. Germany, 2005
19. Vimal Dixit, KamicshDutta and Pardccp Singh. “Word Sense
Disambiguation and Its Approaches' CPUH-Rcsearch Journal: 2015. 1(2), 54-58
20. Dongsuk O. Sunjae Kwon. Kyungsun Kim and Youngjoong K. “Word
Sense Disambiguation Based on Word Similarity CalculationUsing Word Vector Representation from a Know ledge-based Graph”. Proceedings of the 27th International Conference on Computational Linguistics, pages 2704-2714,2018.
21. https:/Aveb.slanford.cduA-jurafsky/slp3/$Iidcs/ Chaptcrl8.w sd.pdf
123 ]https:/Av ww.nltk.org/
AUTHORS PROFILE
A.Uma Maheswari, had completed B.Sc (Applied Sciences) Information Technology, MCA at Bharathiar University and M.Phil (Computer Sciences) at Bharathiar University in the year 2003, 2006 and 2016. She had organized National Level Conferences in the year 2016 and 2017 titled “Emerging Trends in Information Technology”. The Area of interest is Networks, Data mining. Published 02 papers in International Journals, presented 02 papers in International Conferences and 10 papers in National Conferences.