Creation of an Annotated German Broadcast Speech Database for Spoken
Document Retrieval
Stefan Eickeler, Martha Larson, Wolff R ¨uter, Joachim K¨ohler
Fraunhofer Institute for Media Communication IMK Schloss Birlinghoven
53754 Sankt Augustin, Germany
{stefan.eickeler,martha.larson,wolff.rueter,joachim.koehler}@imk.fraunhofer.de
Abstract
In this paper we present a semi-automatic method for creating annotated data sets from German-language broadcast re-sources for which audio files as well as transcripts are available on the Internet. The transcripts are required to be reasonably accurate, but not perfect. Our approach is implemented by a integrated bundle of data processing tools, which support the human annotator in the creation of an annotated data set specialized for research in the area of spoken document classifica-tion and retrieval. Annotaclassifica-tion decisions that would require prohibitively large amounts training data or system development time to make automatically are taken over by the human annotator. Annotation decisions which are easily automated and tedious for humans are shouldered by the computer. Using our method we can process and annotate the data approximately ten times faster that it was possible by hand. The data is downloaded and the transcripts are normalized by a series of filters as well as a semi-automatic digit to text conversion. Then, the system makes use of the Bayesian Information Criterion (BIC) to segment the audio data and Automatic Speech Recognition (ASR) to forced-alignment of the speech signal with written transcripts. We demonstrate the method with the concrete example of our Deutsche Welle database of programs from the Kalenderblatt radio series.
1.
Introduction
The highest hurdle in the development of pattern recog-nition applications is often the creation of annotated data sets of a size adequate to test and train the system. Progress in the area of German-language broadcast news has been impeded by the difficulty of compiling an audio database with corresponding reference transcriptions of the quality and scope required for spoken document retrieval.
The Internet is a valuable source of audio data, and many available audio resources have accompanying tran-scripts. These transcripts tend to be radio broadcast or parliamentary transcripts, and are intended to represent the semantic content, rather than a literal transcription of the audio. In this paper we present a semi-automatic method that allows such data sets to be upgraded with a modest commitment of human hours, into audio databases with aligned literal transcriptions. Our approach consists of an integrated bundle of data processing tools, which support the human annotator in the creation of an annotated data set specialized for research in the area of spoken docu-ment classification and retrieval. We demonstrate these tools on the concrete example of our Deutsche Welle
Kalen-derblatt database. This database was created for use within
a multimedia information portal project called Pi-AVIda (Personalized Interactive Audio, Voice and Video Informa-tion for Media Analysis and Multimedia Portals) funded by the German Federal Ministry of Education and Research.
Deutsche Welle has expressed its interested support of our
use of the resource.
We developed our semi-automatic approach to data an-notation with an eye to optimizing our investment of hu-man effort. At the onset we carefully considered the po-tentials and limitations of available automatic technologies.
Annotation decisions that would require prohibitively large amounts training data or system development time to make automatically are taken over by the human annotator. An-notation decisions which are easily automated and tedious for humans are shouldered by the computer.
We also paid close attention to the balance between in-vested human hours and the final research value of the re-source. Those parts of the database necessary for devel-opment and testing were segmented by hand and subjected to rigorous checking, whereas those parts of the database that were reserved for training, were processed only to the resolution necessary for model training.
The section 2 gives a brief overview of Deutsche Welle
Kalenderblatt website and describes the download process
by which we acquired the raw contents of our database. Section 3 concerns the processing of the transcripts in-cluding the text normalization filter and the semi-automatic digit-to-text conversion that we have developed. Section 4 describes the processing of the audio documents including their segmentation with the Bayesian Information Criterion (BIC). Section 5 explains the alignment of the transcripts to the audio, supported by Automatic Speech Recognition (ASR) and a graphic user interface, which allows the hu-man annotator to easily check and correct the recognizer output. Section 6 introduces the manner in which the data set was annotated with topic categories. Conclusions and outlook are presented in Section 7.
2.
An Internet resource: Deutsche Welle
Kalenderblatt
The Deutsche Welle Kalenderblatt website (http://www. kalenderblatt.de) contains radio programs of the
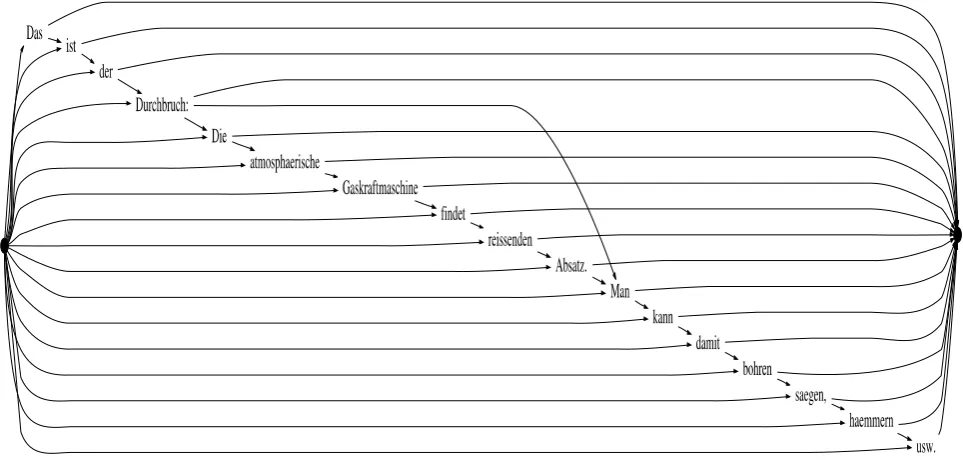
Figure 1: Example lattice for a short text.
pose the word, a statistical decomposition is applied as last resort.
5.2. Calculation of confidence measures
In order to focus in on unreliable regions, we have de-veloped a word and utterance verification algorithm which calculates a word confidence. The posterior probability for each aligned word is calculated using the Bayes formula and the two-best approximation (Dolfing and Wendemuth, 1998):
P(W|O) = P
0(O|W)P(W)
P0(O|W)P(W) +P0(O|Walt)P(Walt)
(2)
W is the aligned word,Waltis a alternative word used for the normalization of the probability. Ois the sequence of 39 dimensional feature vectors containing the MFCC coef-ficients, the energy, delta features, and delta-delta features. The a priori probabilities P(W) andP(Walt)are equal. The probabilitiesP0(O|W)andP0(O|Walt)are scaled by the number of vectors in the Otimes 0.8. This is essen-tial because the independence assumption, which does not hold, is used in speech recognition and results in probabili-ties near zero.
logP0(O|W) =logP(O|W)
0.8·T (3)
withTthe number of feature vectors inO.
The probabilityP(O|Walt)of the second best word is determined by extracting the feature vectors belonging to the aligned word from the vector sequence and performing a phone recognition on these features.
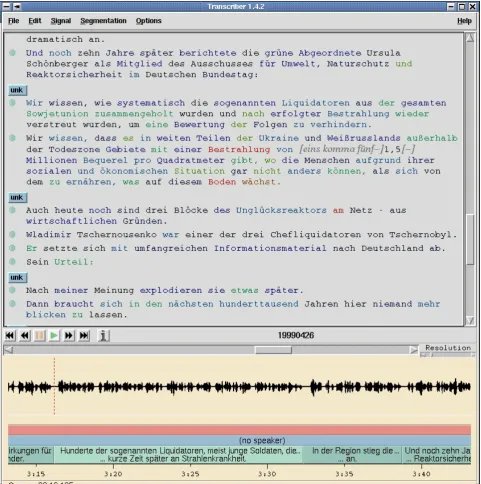
5.3. Visualization of results
The words scores are then graphically depicted in an annotation visualization environment directly underneath the speech signal which they represent. For this purpose
we use the Transcriber annotation toolkit (Barras et al., 2000) with a modified Document Type Definition (DTD) and the TCL/TK visualization program. The confidence of the aligned word is displayed with a graduation of colors. Words that were recognized with high confidence are de-picted in black and the human annotator can skip them. Words with low confidence are depicted in red, and the annotator is alerted to the fact that there is a definite mis-match between the audio and the transcripts at these places that needs to be corrected. Blue and green words are words that were recognized with medium context, and the annota-tor can click into the audio and listen only to these sections to determine if there indeed is a word that needs to be in-serted, deleted or otherwise corrected. The corrections are made by the annotator in the text window of the visual en-vironment, but the changes are automatically added to the XML file format in which the transcripts are stored.
The visual environment can also be used by the annota-tor to insert or correct segment boundaries. As was men-tioned above, the test set and the development set were carefully checked through again by hand, and any boundary mistakes that might have been committed by the BIC-based segmentation algorithm were corrected. Additionally, in the test and the development set, sentence boundaries were all set manually, in order to allow the spoken document re-trieval system to be thoroughly baselined in the test phase. The annotation visualization environment played an essen-tial role in this work, allowing the annotator to see the ex-act time correspondences between the word and the signal. When the annotator moves the segment boundary by drag-ging with the mouse, the appropriate change in the time stamp is made in the XML file in which the correspon-dences between text and signal are stored.
Figure 2: Result of automatic transcription displayed in modified transcriber tool.
aligned words.
6.
Classification of topics
Since the databank is to be used to develop classification and information retrieval methods, it is necessary to classify all the texts into reference categories in order to train and test such systems. In final step of database preparation, we use the first level categories of the subject reference sys-tem of the International Press Telecommunications Coun-cil (IPTC) (http://www.iptc.org) to tag the documents with reference categories. A voting procedure between three hu-man taggers decides which category is chosen as the ref-erence class for each document in the database in order to insure that reference tags reflect average human intuitions
about category membership.
7.
Conclusions
doc-uments by human annotators.
The method we present here reduces the amount to time necessary to annotate a database for research and develop-ment activities in spoken docudevelop-ment classification and re-trieval by a factor of ten. This decrease in annotation time allows us to annotate more data for the given research bud-get. An additional benefit of our semi-automatic method, is that the work of annotation is less tedious, making the of-ten dreary task of annotation an all together more pleasant experience.
8.
References
Claude Barras, Edouard Geoffrois, Zhibiao Wu, and Mark Liberman. 2000. Transcriber: Development and Use of a Tool for Assisting Speech Corpora Production. Speech
Communication special issue on Speech Annotation and Corpus Tools, 33(1-2), jan.
J. G. A. Dolfing and A. Wendemuth. 1998. Combination of Confidence Measures in Isolated Word Recognition. In
5th International Conference on Spoken Language Pro-cesssing, pages 3237–3240, Sydney, December.
A. Ganapathiraju, N. Deshmukh, J. Zhao, X. Zhang, Y. Wu, J. Hamaker, and J. Picone. 1999. The ISIP Public Domain Decoder for Large Vocabulary Conversational Speech Recognition. Technical report, Institute for Sig-nal and Information Processing, Mississippi State Uni-versity, May.
Esther Klabbers, Karlheinz St¨ober, Raymond Veldhuis, Pe-tra Wagner, and Stefan Breuer. 2001. Speech Synthe-sis Development Made Easy: The Bonn Open SyntheSynthe-sis System. In Proc. EUROSPEECH, Aalborg, Denmark. Karlheinz St¨ober, Petra Wagner, J¨org Helbig, Stefanie
K¨oster, David Stall, Matthias Thomae, Jens Blauert, Wolfgang Hess, R¨udiger Hoffmann, and Helmut Man-gold. 2000. Speech Synthesis by Multilevel Selection and Concatenation of Units from Large Speech Corpora. In Wolfgang Wahlster, editor, Verbmobil: Foundations
of Speech-to-Speech Translation, Artificial Intelligence,
pages 519–537. Springer, Berlin.
Alain Tritschler and Ramesh Gopinath. 1999. Improved Speaker Segmentation and Segments Clustering Us-ing the Bayesian Information Criterion. In Proc.