CSEIT1725112 | Received : 01 Oct 2017 | Accepted : 17 Oct 2017 | September-October-2017 [(2)5: 746-750]
International Journal of Scientific Research in Computer Science, Engineering and Information Technology © 2017 IJSRCSEIT | Volume 2 | Issue 5 | ISSN : 2456-3307
746
Pattern Evaluation with Location Based Query Search
J. V. D Prasad
*1, M. Sri Mounica
2*1Assistant Professor, Computer Science Department, VR Siddhartha College, Vijayawada, Andhra Pradesh, India
2
Student, Computer Science Department, VR Siddhartha College, Vijayawada, Andhra Pradesh, India
ABSTRACT
Customers are increasingly seeking complex task-oriented goals on the Web, such as making routes, managing finances or planning purchases. To this end, they usually break down the duties into a few co-dependent actions and problem multiple concerns around these actions repeatedly over quite a very lengthy time. To better support users in their long-term details missions on the Web, google keep track of their concerns and clicks while searching on the internet. In this document, we study the problem of organizing a user’s historical concerns into categories in an energetic and automated fashion. Instantly determining question categories is helpful for a number of different online look for engine components and applications, such as query suggestions, result position, question alterations, sessionization, and collaborative look for. So in this document we propose to develop Customized Location based Query Search method for pattern evaluation in accessing customer preference location leads to relevant details look for in relational database. This procedure automatically retrieve customer prefer locations centred on their longitude and permission of each customer in relational database.
Keywords: Pattern evaluation, Relational database, Query suggestion, Location based search
I.
INTRODUCTION
Details mining is the main system with such as required look for information in realistic information event management features. Details elimination is the process
of getting relevant information from various
information current in the details warehouse.
Search result analysis of each client choices is the main concept in current content management features depending on the client choices. The process of getting information from client prepared information sets with such as the features on the details achievements current prepared information sets. Some of the research content management people may organize the process of the best position centred online look for engine results the client with references to the process of the location of each client. These results are obtained commercial information management online look for engine system progresses with information evens of all the related information current in the constructed data source.
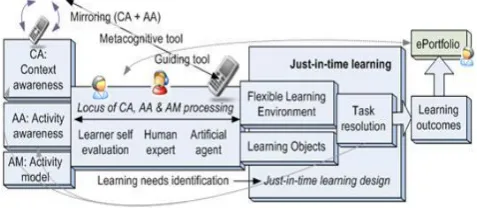
Figure 1 : Context awareness in application development.
Customized Mobile Look for Engine describes the process of customer server framework such as all the features in recent content management. In this program server maintain all the user/ customer details with referrals features present in the process of content management. Client delivers requirement to the server then server confirm customer requirement.
There are no rationally "correct" clustering
requirements, but as it was described, "clustering is in the eye of the viewer."[2] The most appropriate clustering requirements for a particular problem often needs to be chosen experimentally, unless there is a mathematical reason to prefer one group style over another. It should be described that a requirement that is designed for one kind of style has no chance on some details set that contains a significantly different kind of style. [2] For example, k-means cannot find non-convex groups.
In the above plan show efficient connections of each learning stage evaluation process such as efficient connections in each query reflection such as details process with required details. Our test results show efficient managing in query managing in appropriate details search data source integration.
II.
RELATED WORK
Hassan H. Malik, and Bob R. Kender described that the world design discovery step in current pattern-based requested clustering methods may result in an unexpected wide range of designs. In thispaper, we suggest IDHC, pattern-based requested clustering requirements that build a team framework without discovery for globally important designs. IDHC allows each example to "vote" for its affiliate size-2 designs in a way that assures an effective balance between local and globally design importance. The wide range of
designs selected for each example is dynamically identified using a local traditional difference based plan, and the rest of the group framework is obtained by following a unique recurring team improvement process.
Figure 2 : Pattern evaluation of the working process
By successfully using instance-to-clusterconnections, this process directly recognizes groups for each level in the framework, and successfully prunes duplicate groups. Furthermore, IDHC generates group brands that are more descriptive (patterns are not synthetically restricted), and adjusts a smooth clustering scheme that allows circumstances to are available in appropriate nodes at various levels in the cluster framework. We current outcomes of tests conducted on 16 standard text datasets, and display that IDHC almost always outperforms state-of-the-art hierarchical clustering techniques in terms of entropy, and accomplishes better FScores in most cases, without demanding adjusting of parameter principles.
highest-confidence rules protecting this example is involved in the ultimate concept set, which allows in helping the overall precision of the classifier. By introducing several novel look for techniques and trimming methods into the concept finding process, HARMONY also has high efficiency and good scalability. Our thorough performance study with some huge written text and particular information source has proven that HARMONY outperforms many well-known classifiers
in termsof both precision and computational
performance, and machines wellw.r.t. the information source size.
III. BACKGROUND APPROACH
Design for CUSTOMIZED LOCATION QUERY by implementing the meta look for approach which depends on one of the commercial search engines, such as Google, Google, or Google, to perform an actual look for.
A customization structure that runs on the user’s content choices and place choices as well as the GPS places in customizing look for outcomes. The customer information for particular customers are saved on the CUSTOMIZED LOCATION QUERY customers, thus protecting comfort to the customers. CUSTOMIZED LOCATION QUERY has been prototyped with CUSTOMIZED LOCATION QUERY customers on the. The customer information for particular customers are saved on the CUSTOMIZED LOCATION QUERY customers, thus protecting comfort to the customers. CUSTOMIZED LOCATION QUERY has been prototyped with CUSTOMIZED LOCATION QUERY customers on the GOOGLE Server. CUSTOMIZED LOCATION QUERY has a user’s physical places in the customization process. We perform tests to study the influence of a user’s GPS places in customization. The outcomes show that GPS places help improve recovery efficiency for place concerns (i.e., concerns that recover lots of place information).
Figure 2: Architecture for query processing in relevant data process.
CUSTOMIZED LOCATION QUERY information both of the user’s material and place choices in the ontology centred user profiles, which are instantly discovered from the just click through and GPS information without requiring extra initiatives from the
customer .CUSTOMIZED LOCATION QUERY
details this problem by managing the amount of information in the client’s customer profile being revealed to the CUSTOMIZED LOCATION QUERY server using two comfort factors, which can management privacysmoothly, while keeping good position high quality.
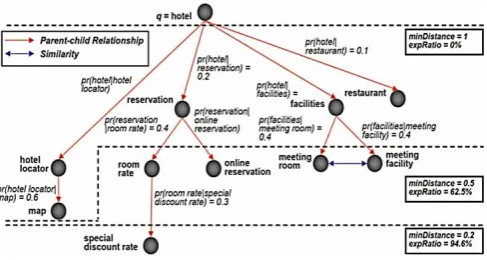
Figure 3 : Query evaluation of example hotel query processing.
CUSTOMIZED LOCATION QUERY has a user’s actual physical places in the customization process. We perform tests to research the impact of a user’s GPS places in customization.
IV. PROPOSED SYSTEM
In this area we explain the interaction of the information question design with simulator of every activity of the question handling recent database integration. For doing this work efficiently we procedure the location based search procedure by determining the longitude and permission reflection procedure. The technique apply in suggested approach may achieve information systems functions with
relevant information and allocated connection
Figure 4: Query pattern evaluation procedure with relational data sets.
This function may represent the result process in
convenient and other semantic reflection.This
combination may perform effective reflection of the question pattern by collection printed group with relevant function handling functions.
Figure 5: Query pattern evaluation process.
By mixing the functions of the information research we process searching technique by standard getting information principles with sufficient and entertaining information reflection. By applying some question clustering here, we recommend to develop efficient handling in recent database integration.
V.
EXPERIMENTAL RESULTS
We determine that a wide trial outcome gives us it is a pattern-based group framework for category. CPHC first uses the ordered framework to recognize nodes that contain the analyse example, and then uses
appearance of co-existing coaching circumstances, with a weight of them by node pattern-lengths (i.e., by growing the node pattern-interestingness value with the pattern-length) to acquire category label(s) for the analyse example. By Using CPHC we can categorize analyse circumstances and we can remove the improved coaching set.
Figure 5: Client server key specification based with sufficient results.
By that results can show efficient managing of each query marketing in training details set.
For example, we post to draw out different details places present in the managing content management. In this document we make the location look for managing with equivalent issue talking about using longitude and authorization concepts of each query significance design evaluation. As proven in the above we access to make different keyword and search term and search term look for programs with relative details activities and other modern figure features. The causing research of the issue managing will take more time complexness when evaluating to content based look for the process. This program may figure out adequate and other function development of every query submission.
In this situation of the development process may figure out efficient and getting details from the data source. We already store details in the form of place query representation of each query handling.
VI. CONCLUSION
the need to practice a classifier on an improved coaching set.
In addition, this tactic uses a novel operate choice method that assures that all coaching and evaluate conditions are secured by the chosen functions, uses factors that work across datasets with different functions, and also has the beneficial complication of helping it is likely that determining divided evaluate conditions on unusual coaching details by causing a form of operate transitivity. Finally, this tactic is extremely efficient on unusual coaching details.
VII.
REFERENCES
[1]. R. Baeza-Yates, C. Hurtado, and M. Mendoza, "Query recommendation using query logs in search engines," in Proc. Int. Conf. Current Trends SIGIR Conf. Res. Develop. Inf. Retrieval, 2007, pp. 239–246.
[5]. Q. Mei, D. Zhou, and K. Church, "Query suggestion using hitting time," in Proc. 17th ACM Conf. Inf. Knowl. Manage., 2008, pp. 469–478. [6]. Y. Song and L.-W. He, "Optimal rare query
suggestion with implicit user feedback," in Proc. 19th Int. Conf. World Wide Web, 2010, pp. 901– 910.
[7]. T. Miyanishi and T. Sakai, "Time-aware structured query suggestion," in Proc. 36th Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2013, pp. 809– 812.
[8]. A. Anagnostopoulos, L. Becchetti, C. Castillo, and A. Gionis, "An optimization framework for query recommendation," in Proc. ACM Int. Conf. Web Search Data Mining, 2010, pp. 161–170.
[9]. P. Boldi, F. Bonchi, C. Castillo, D. Donato, A. Gionis, and S. Vigna, "The query-flow graph: Model and applications," in Proc. 17th ACM Conf. Inf. Knowl. Manage., 2008, pp. 609–618.
[10]. Y. Song, D. Zhou, and L.-w. He, "Query suggestion by constructing term-transition graphs," in Proc. 5th ACM Int. Conf. Web Search Data Mining, 2012, pp. 353–362.
[11]. L. Li, G. Xu, Z. Yang, P. Dolog, Y. Zhang, and M. Kitsuregawa, "An efficient approach to suggesting topically related web queries using hidden topic model," World Wide Web, vol. 16, pp. 273–297, 2013.
[12]. D. Wu, M. L. Yiu, and C. S. Jensen, "Moving spatial keyword queries: Formulation, methods, and analysis," ACM Trans. Database Syst., vol. 38, no. 1, pp. 7:1–7:47, 2013.
[13]. D. Wu, G. Cong, and C. S. Jensen, "A framework for efficient spatial web object retrieval," VLDB J., vol. 21, no. 6, pp. 797–822, 2012.
[14]. J. Fan, G. Li, L. Zhou, S. Chen, and J. Hu, "SEAL: Spatio-textual similarity search," Proc. VLDB Endowment, vol. 5, no. 9, pp. 824– 835, 2012. [15]. P. Bouros, S. Ge, and N. Mamoulis, "Spatio-textual
similarity joins," Proc. VLDB Endowment, vol. 6, no. 1, pp. 1–12, 2012.
[16]. Y. Lu, J. Lu, G. Cong, W. Wu, and C. Shahabi, "Efficient algorithms and cost models for reverse spatial-keyword k-nearest neighbor search," ACM Trans. Database Syst., vol. 39, no. 2, pp. 13:1– 13:46, 2014.
[17]. S. Basu Roy and K. Chakrabarti, "Location-aware type ahead search on spatial databases: Semantics and efficiency," in Proc. ACM SIGMOD Int. Conf. Manage. Data, 2011, pp. 361–372.
[18]. R. Zhong, J. Fan, G. Li, K.-L. Tan, and L. Zhou, "Location-aware instant search," in Proc. 21st ACM Conf. Inf. Knowl. Manage., 2012, pp. 385–394. [19]. I. Miliou and A. Vlachou, "Location-aware tag
recommendations for flickr," in Proc. 25th Int. Conf. Database Expert Syst. Appl., 2014, pp. 97– 104.
[20]. H. Tong, C. Faloutsos, and J.-Y. Pan, "Fast random walk with restart and its applications," in Proc. 6th Int. Conf. Data Mining, 2006, pp. 613–622.
[21]. Y. Fujiwara, M. Nakatsuji, M. Onizuka, and M. Kitsuregawa, "Fast and exact top-k search for random walk with restart," Proc. VLDB Endowment, vol. 5, no. 5, pp. 442–453, Jan. 2012. [22]. D. Fogaras, B. R_acz, K. Csalog_any, and T.
Sarl_os, "Towards scaling fully personalized PageRank: Algorithms, lower bounds, and experiments," Internet Math., vol. 2, no. 3, pp. 333– 358, 2005.
[23]. B. Bahmani, A. Chowdhury, and A. Goel, "Fast incremental and personalized PageRank," Proc. VLDB Endowment, vol. 4, no. 3, pp. 173–184, Dec. 2010.
[24]. K. Avrachenkov, N. Litvak, D. Nemirovsky, E. Smirnova, and M. Sokol, "Quick detection of top-k personalized PageRank lists," in Proc. 8th Int. Workshop Algorithms Models Web Graph, 2011, vol. 6732, pp. 50–61.