A C Q U I S I T I O N OF S E L E C T I O N A L P A T T E R N S
R A L P H G R I S H M A N a n d J O H N S T E R L I N G C o m p u t e r Science D e p a r t m e n t
New York University New York, NY 10003, U.S.A.
1
T h e P r o b l e m
For most natural language analysis systems, one of the major hurdles in porting the system to a new domain is the development of an appropri- ate set of semantic patterns. Such patterns are typically needed to guide syntactic analysis (as selectional constraints) and to control the trans- lation into a predicate-argument representation. As systems are ported to more complex domains, the set of patterns grows and the task of accumu- lating them manually becomes more formidable. There has therefore been increasing interest in acquiring such patterns automatically froin a sample of text in the domain, through an analysis of word co-occurrence patterns either in raw text (word sequences) or in parsed text. We briefly review some of this work later in the article. We have been specificaily concerned about the prac- ticality of using such techniques in place of man- ual encoding to develop the selectional patterns for new domains. In the experiments reported here, we have therefore been particularly con- cerned with the evaluation of our automatically generated patterns, in terms of their complete- hess and accuracy and in terms of their efficacy in performing selection during parsing.
2
P a t t e r n s a n d W o r d C l a s s e s
In principle, the semantic patterns could be stated in terms of individual words - this verb can meaningfully occur with this subject, etc. In practice, however, this would produce an unman- ageable number of patterns for even a small do- main. We therefore need to define semantic word classes for the domain and state our patterns in terms of these classes.
Ideally, then, a discovery proeednre for seman- tic patterns would acquire both the word classes and the patterns from an analysis of the word
co-occurrence patterns. In order to simplify the task, however, while we are exploring different strategies, we have divided it into separate tasks, that of acquiring word classes and that of ac- quiring semantic patterns (given a set of word classes). We have previously described [1] some experiments in which the principal word classes for a sublanguge were obtained through the clus- tering of words based on the contexts in which they occurred, and we expect to renew such ex- periments using the larger corpora now available. However, the experiments we report below are limited to the acquisition of semantic patterns given a set of manually prepared word classes.
3
P a t t e r n Acquisition
The basic mechanism of pattern acquisition is straightforward. A sample of text in a new do- main is parsed using a broad-coverage grammar (but without any semantic constraints). The re- sulting parse trees are then transformed into a regularized syntactic structm'e (similar to the f- structure of Lexical-Fnnctional Grammar). This regularization in particular reduces all different clausM forms (active, passive, questions, extra- posed forms, relative clauses, reduced relatives, etc.) into a uniform structure with the 'logical' subject and object explicitly marked. For exam- ple, the sentence
Fred ate fresh cheese from France. would produce the regularized syntactic struc- ture
(s eat (subject (np Fred))
(object (np cheese (a-pos fresh)
(from (np France)))))
W e then extract from this regularized structure a series of triples of the form
h e a d s y n t a c t i c - f u n c t i o n value
where - if t h e value is a n o t h e r N P or S - only the h e a d is recorded. For e x a m p l e , for the above s e n t e n c e we would g e t tile t r i p l e s
e a t s u b j e c t Fred e a t o b j e c t cheese cheese a-pos fresh cheese from bYance
Finally, we g e n e r a l i z e these t r i p l e s by r e p l a c i n g words by word classes. We h a d p r e v i o u s l y pre- p a r e d , by a p u r e l y m a n u a l a n a l y s i s of the corpus, a h i e r a r c h y of word classes a n d a set of s e m a n t i c p a t t e r n s for t h e corpus we were using. From this h i e r a r c h y we identified the classes which were m o s t f r e q u e n t l y referred to in t h e n l a n u a l l y pre- p a r e d p a t t e r n s . T h e g e n e r a l i z a t i o n process re- places a word by the m o s t specific class to which it belongs (since we have a h i e r a r c h y w i t h uested classes, a word will t y p i c a l l y belong to several classes). As we c x p l a i n in o u r e x p e r i m e n t sec- tion below, we m a d e some r u n s g e n e r a l i z i n g j u s t t h e value a n d o t h e r s g e n e r a l i z i n g both tlle head a n d t h e value.
As we process the corl)us , we kee t) a count of t h e frequency of each h e a d - f u n c t i o n wdue triple. In a d d i t i o n , we keep s e p a r a t e counts of the num- ber of t i m e s each word a p p e a r s as a head, and t h e n u m b e r of t i m e s eacll head-fitnction pair al)- p e a r s ( i n d e p e n d e n t of value).
4
Coping w i t h M u l t i p l e Parses
T h e p r o c e d u r e described a b o v e is sufficient if we are a b l e to o b t a i n ttlc correct parse for eacll sentence, l l o w e v e r , if we are p o r t i n g to a new d o m a i n a n d h a v e no s e m a n t i c c o n s t r a i n t s , we l n u s t rely e n t i r e l y u p o n s y n t a c t i c c o n s t r a i n t s a n d so will be confronted w i t h a large n u m b e r of i n c o r r e c t parses for each sentence, a l o n g w i t h ( h o p e f u l l y ) t h e correct one. We have exl)eri- m e n t e d w i t h several a p p r o a c h e s to d e a l i n g w i t h t h i s p r o b l e m :
1. If a s e n t e n c e has N parses, we can g e n e r a t e t r i p l e s front all the parses a n d tllen i n c l u d e each t r i p l e w i t h a w e i g h t of 1 / N .
2. We can g e n e r a t e a s t o c h a s t i c g r a m m a r t h r o u g h u n s u p e r v i s e d t r a i n i n g on a p o r t i o n of t h e corpus [2]. We can t h e n parse t h e cor- p u s w i t h t h i s s t o c h a s t i c g r a m m a r a t , l t a k e
o n l y t h e m o s t p r o b a b l e parse for each sen- tence. ]:or sentences which still g e n e r a t e d N > 1 e q u a l l y - p r o b a b l e parses, we would use a 1 / N w e i g h t ;us before.
3. In place of a 1 / N w e i g h t i n g , we can re- tine the w e i g h t s for a l t e r n a t i v e parse trees nsing an i t e r a t i v e p r o c e d u r e a n a l o g o u s to t h e i n s i d e - o u t s i d e a l g o r i t h m [3]. We he- gin by g e n e r a t i n g all parses, as in a p p r o a c h 1. T h e n , based on t h e c o u n t s o b t a i n e d ini- t i a l l y ( u s i n g 1 / N w e i g h t i n g ) , we can com- p u t e the p r o b a b i l i t y for the various triples attd from these tim p r o b a b i l i t i e s of t h e al- t e r n a t i v e parse trees. We can t h e n r e p e a t the process, r e c o m p u t i n g t h e c o u n t s w i t h w e i g h t i n g s based on these p r o b a b i l i t i e s .
All of these a p p r o a c h e s rely on the e x p e c t a t i o n t h a t correct p a t t e r n s a r i s i n g from correct parses will occur repeatedly, while t h e d i s t r i b u t i o n of incorrect p a t t e r n s from incorrect parses will be more s c a t t e r e d , a n d so over a sufficiently large c o r p u s - we cat, d i s t i n g u i s h correct from incor- rect p a t t e r n s on the basis of frequency.
5
E v a l u a t i o n M e t h o d s
~['o g a t h e r p a t t e r n s , we a n a l y z e d a series of arti- cles on t e r r o r i s m which were o b t a i n e d from tim Foreign l l r o a d c a s t l n h ) r m a t i o n Service a n d used as the d e v e l o p m e n t era'pus for the T h i r d Message U n d e r s t a n d i n g Confiwence (held in San Diego, CA, M a y 1991) [4]. l'br p a t t e r n collection, we used 1000 such a r t i c l e s w i t h a t o t a l of :14,196 sentences and 330,769 wor(ls. Not all sentences parsed, b o t h because of l i m i t a t i o n s in our g r a m - m a r and b e c a n s e we i n l p o s e a l i m i t on the search which the p a r s e r can perform for each sentence. W i t h i n t h e s e l i m i t s , we were able to parse a t o t a l of 7,455 s e n t e n c e s J
T h e m o s t clearly definable function of tbe triples we collect is to act as a selectional con- s t r a i n t : to differentiate between m e a n i n g f l d and m e a n i n g l e s s triples in new t e x t , a n d t h u s identify the correct attalysls.
We used two m e t h o d s to e v a l u a t e the effec- tiveness of tile triples we g e n e r a t e d . T h e first IF or these runs we disabled several heuristics in our
systelll which increase tile nulnbef of sentences which can
be parsed at some cost m the average quality of parses; hence the relatively low percentage of sentences which ob- tained parses.
method involved a comparison with manually- classified triples. We took 10 articles (not in the training corpus), generated all parses, and pro- duced the triples from each parse. These triples were stated in terms of words, and were not generalized to word classes. We classified each triple as semantically valid or invalid (a triple was counted as valid if we believed that this pair of words could meaningfully occur in this rela- tionship, even if this was not the intended rela- tionship in this particular text). This produced a test set containing a total of 1169 distinct triples, of which 716 were valid and 453 were invalid.
We then established a threshold T for the weighted triples counts in our training set, and defined
v+ number of triples in test set which were clas- sified as valid and which appeared in train- ing set with count > T
v_ number of triples in test set which were clas- sified ms valid and which appeared in train- ing set with count < T
i+ number of triples in test set which were classi- fied ms invalid and which appeared in train- ing set with count > T
i_ number of triples in test set which were classi- fied as invalid and which appeared in train- ing set with count < T
and then defined
recall - v+
v++v_
precision - v+
v+ + i+ i+ error rate -
i++i_
By varying tim threshold, we can plot graphs of recall vs. precision or recall vs. error-rate. These plots can then be compared among differ- ent strategies for collecting triples and for gen- eralizing triples. The precision figures are some- what misleading because of the relatively small number of invalid triples in the test set: since only 39% of the triples are invalid, a filter which accepted all the triples in the test set would still be accounted as having 61% precision, We have therefore used the error rate in the figures below (plotting recall against l ~ r r o r - r a t e ) .
The second evaluation method involves the use of the triples in selection and a comparison of the parses produced against a set of known correct parses. In this case the known correct parses were prepared manually by the Univer- sity of Pennsylvania as part of their "'Free Bank" project. For this evaluation, we used a set of 317 sentences, again distinct from the training set, In comparing the parser output against the stan- dard trees, we measured the degree to which the tree structures coincide, stated as recall, preci- sion, and number of crossings. These measures have been defined in earlier papers [5,6,7].
6 R e s u l t s
Our first set of experiments were conducted to compare three methods of coping with multiple parses. These methods, as described in section 4, are (1) generating all N parses of a sentence, and weighting each by
l/N;
(2)selecting the N most likely parses as determined by a stochastic gram- mar, and weighting those each by1/N;
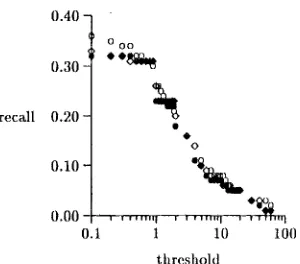
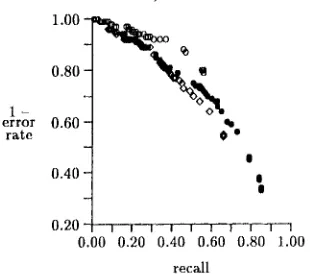
(3) gen- erating all parses, but assigning weights to alter- native parses using a form of the inside-outside procedure. These experiments were conducted using a smaller training set, a set of 727 sen- tences drawn from 90 articles. We generated a set of triples using each of the three methods and then evaluated them against our hand-classified triples, as described in section 5. We show in Figure 1 the threshold vs. recM1 curves for the three methods; in Figure 2 the recall vs. 1-error rate curves.These experiments showed only very small dif- ferences between the three methods (the inside- outside method showed slightly better accuracy at some levels of recall). Based on this, we decided to use method 2 (statistical grammar) for subsequent experiments. Other ttfings being equal, method 2 hms the virtue of generating far fewer parses (an average of 1.5 per sentence, vs. 37 per sentence when all parses are produced), and hence a far smaller file of regularized parses (about 10 MB for our entire training corpus of 1000 articles, vs. somewhat over 200 MB which would have been required if all parses were gener- ated). Using method 2, therefore, we generated the triples for our 1000-article training corpus.
Our second series of experiments compared three different ways of accumulating data from the triples:
0.40 -
, 00o
0.30 - * * ~ ' ~
recall 0.20 - ' ~ O
O 0.10 - ' ~ l ~
0 . 0 0 - --, ... , , ~ ... *, , -'~,,,I 0.1 1 10 100
t h r e s h o l d
F i g u r e 1: C o m p a r i s o n of m e t h o d s for d e a l i n g w i t h m u l t i p l e parses in p a t t e r n collection, us- ing t r a i n i n g c o r p u s of 90 articles. T h r e s h o k l vs. recall for o = all parses; o = all parses + inside-outside; • = m o s t t)robable parses from s t o c h a s t i c g r a m m a r .
1.00 -**** o o o 0.95 - me
o O ] •
e r r o r 0 . 9 0 - r a t e
0.85 -
o o5 moo
o
%
0.80" ' ' , , i - - 7
0.00 0.10 0.20 0.30 0.40 recall
F i g u r e 2: C o m p a r i s o n of m e t h o d s for d e a l i n g w i t h m u l t i p l e parses in p a t t e r n collection, using t r a i n i n g corpus of 90 articles. RecM1 vs. l - e r rot r a t e for o = all parses; o = all parses + i n s i d e - o u t s i d e ; • = m o s t p r o b a b l e parses from s t o c h a s t i c g r a m m a r .
1 . 0 0
• ~mmo
0.80 . m
o. o
\
recall %
0.40 0 o ~ O
(I.20
0.00 ... ~ ... 0.1 l 10 100
t h r e s h o l d
F i g u r e 3: C o m p a r i s o n of p a t t e r n g e n e r a l i z a t i o n techniques, u s i n g t r a i n i n g c o r p u s of 1000 arti- cles. T h r e s h o l d vs. recall for o = t r i p l e s w i t h o u t generalized heads; o = triples w i t h generalized heads; • = 1)airs.
1. g e n e r a l i z i n g the value in a head-flmction- value t r i p l e to a word class, b u t n o t gen- e r a l i z i n g tile head
2. g e n e r a l i z i n g h o t h t h e value a n d t h e head
3. i g n o r i n g the value field e n t i r e l y in a h e a d - f u n c t i o n - v a l u e triple, ,~n(l a c c u m u l a t - ing c o u n t s of h e a d - f i m c t i o n pairs ( w i t h no g e n e r a l i z a t i o n a p p l i e d to the head); a m a t c h w i t h the h a n d - m a r k e d triples is therefore recorded if t h e head a n d flmction fields m a t c h
A g a i n , we e v a l u a t e d t h e p a t t e r n s produced by each m e t h o d a g a i n s t tile h a n d - m a r k e d triples. F i g u r e 3 shows the t h r e s h o h l vs. recall curves for each m e t h o d ; F i g u r e 4 the recM1 vs. 1-error r a t e curves. F i g u r e 3 i n d i c a t e s t h a t using pairs yields the h i g h e s t recall for a given threshold, triples w i t h g e n e r a l i z e d ]leads an i n t e r m e d i a t e value, a n d triples w i t h o u t generalized heads the lowest recall. T h e error r a t e vs. recall curves of ligure 4 do n o t show a g r e a t difference be- tween mcdLods, b u t t h e y do i n d i c a t e t t l a t , over tile r a n g e of recalls for which t h e y overlap, using triples w i t h o u t g e n e r a l i z e d h e a d s l)roduces the lowest error r a t e .
Finally, we conducted a series of e x p e r i m e n t s to c o m p a r e the effectiveness of the triples in se- l e c t i n g the correct parse, in effect, the selection procedure works as follows, l'br each sentence in the test corpus, the s y s t e m g e n e r a t e s all possible
[image:4.432.224.371.14.143.2] [image:4.432.44.194.38.170.2] [image:4.432.43.196.294.424.2]1 - e r r o r
r a t e 1 . 0 0 -
0 . 8 0 -
0 . 6 0
0.40
0.20
0 o |
| |
I I ' I I I I ' I" "1 I" '1 L00 0.20 0.40 0.60 0.80 ].00
recall
F i g u r e 4: C o m p a r i s o n of p a t t e r n g e n e r a l i z a t i o n techniques, using t r a i n i n g corpus of 1000 articles. Recall vs. 1 - e r r o r r a t e for o = triples w i t h o u t generalized beads; o = t r i p l e s w i t h generalized heads; • = pairs.
parses a n d t h e n g e n e r a t e s a set of triples from each parse. E a c h t r i p l e is assigned a score; the score for t h e parse is the p r o d u c t of the scores of t h e t r i p l e s o b t a i n e d from t h e parse ( t h e use of p r o d u c t s is c o n s i s t e n t w i t h t h e i d e a t h a t the score for a t r i p l e to some degree reflects t h e prob- a b i l i t y t h a t t h i s t r i p l e is s e m a n t i c a l l y valid). T h e parse or parses w i t h t h e h i g h e s t t o t a l score are t h e n selected for e v a l u a t i o n .
We t e s t e d three a p p r o a c h e s t o a s s i g n i n g a score to a triple:
1. We used t h e frequency of head-function- value t r i p l e s r e l a t i v e to t h e frequency of the h e a d as an e s t i m a t e of t h e p r o b a b i l i t y t h a t this head would a p p e a r w i t h t h i s function- value c o m b i n a t i o n . We used the " e x p e c t e d l i k e l i h o o d e s t i m a t e " [8] in order to assure t h a t t r i p l e s which do n o t a p p e a r in the train- ing corpus are still a s s i g n e d non-zero proba- bility; t h i s s i m p l e e s t i m a t o r a d d s 1 / 2 to each observed frequency:
freq. of triple + 0.5 score =
freq. of head + 0.5
2. We a p p l i e d a t h r e s h o l d to o u r set of col- l e c t e d triples: if a t r i p l e a p p e a r e d w i t h a frequency above the t h r e s h o l d i t was as- signed one score; if at or below t h e thresh- old, a lower score. We selected a t h r e s h o l d of 0.9, so t h a t a n y t r i p l e which a p p e a r e d u n a m b i g u o u s l y in at l e a s t one sentence of
the t r a i n i n g corpus was included. For our scores, we used t h e results of our previ- ous set of e x p e r i m e n t s . T h e s e e x p e r i m e n t s showed t h a t a t a t h r e s h o l d of 0.9, 82% of the t r i p l e s above t h e t h r e s h o l d were seman- t i c a l l y valid, while 47% of the triples below t h e t h r e s h o l d were v a l i d 3 T h u s we used
score = 0.82 if freq. of t r i p l e > 0.9 0.47 if freq. of t r i p l e < 0.9
We e x p a n d e d on m e t h o d 2 by u s i n g b o t h triples and p a i r s i n f o r m a t i o n . To assign a score to a h e a d - f u n c t i o n - v a l u e triple, we first a s c e r t a i n w h e t h e r t h i s t r i p l e a p p e a r s w i t h frequency > T in the collected pat- terns; if so, we assign a h i g h score to t h e triple. If not, we d e t e r m i n e w h e t h e r the h e a d - f u n c t i o n pair a p p e a r s w i t h frequency > T in t h e collected p a t t e r n s . If so, we assign an i n t e r m e d i a t e score to t h e triple; if not, we assign a low score t o t h e triple. A g a i n , we chose a t h r e s h o l d of 0.9 for b o t h triples a n d pairs. Our earlier e x p e r i m e n t s i n d i c a t e d t h a t , of t h o s e h e a d - f u n c t i o n - v a l u e triples for which the t r i p l e was below t h e t h r e s h o l d for triples frequency b u t the head- function p a i r was above the t h r e s h o l d for pair frequency, 52% were s e m a n t i c a i l y valid. Of those for which t h e h e a d - f u n c t i o n pair was below t h e t h r e s h o l d for p a i r frequency, 40% were s e m a n t i c a l l y valid. T h u s we used
score = 0.82 if freq. of t r i p l e > 0.9, else 0.52 if freq. of pair > 0.9, else
0.40 if freq. of p a i r < 0.9
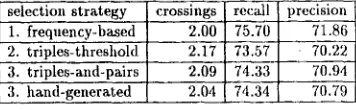
Using these t h r e e scoring f l m c t i o n s for selec- tion, we parsed o u r t e s t set of sentences a n d then scored the r e s u l t i n g parses a g a i n s t o u r " s t a n d a r d parses". As a f u r t h e r c o m p a r i s o n , we also p a r s e d t h e same set u s i n g selectional c o n s t r a i n t s which h a d been p r e v i o u s l y m a n u M l y p r e p a r e d for t h i s d o m a i n . T h e parses were scored a g a i n s t t h e stan- d a r d in t e r m s of a v e r a g e recall, precision, and n u m b e r of crossings; t h e results are s h o w n in Ta- ble 1. 3 A b e t t e r m a t c h to t h e correct parses 2"Fhe actual value of the scores only matters in cases where one parse generates more triples than another.
3These averages are calculated only over the subset of test sentences which yielded a parse with o u r granunar within the edge limit alloted.
[image:5.432.47.202.24.161.2]selection strategy crossings rec',di precision
1. frequency-based 2.00 75.70 71.86
2. triples-threshold 2.17 73.57 70.22
3. triples-and-pairs ° 2-09 74:33 70.94-
3. hand-generated 2.04 "t4.34 i
Table 1: A comparison of the effect of different selection strategies on the quality of parses gen- erated.
is reflected in higher recall and precision and lower number of crossings. These results indi- cate that the frequency-based scores performed better than either the threshold-ha.qed scores or the manually-prepared selection.
7 R e l a t e d W o r k
At NYU we have long been interested in the pos- sibilities of automatically acquiring sublanguage (semantic) word classes and patterns from text corpora. In 1975 we reported on experiments -- using a few hundred manuMly prepared reg- ularized parses --- for clustering words based on their co-occurrence patterns and thus generat- ing the principal sublanguage word classes for a domain [1]. In the early 1980's we performed experiments, again with relatively small corpora and machine-generated (but manually selected) parses, for collecting snblanguage patterns, simi- lar to the work reported here [9]. By studying the growth curves of size of text sample vs. number of patterns, we attempted to estimate at that time the completeness of the subtanguage patterns we obtained.
More recently there has been a surge of in- terest in such corpus-based studies of lexicai co occurrence patterns (e.g., [1{},11,12,13]). The re- cent volume edited by Zernik [14] reviews many of these efforts. We mention only two of these here, one seeking a similar range of patterns, the other using several ewduation methods.
Velardi et al. [11] are using co-occurence data to build a "semantic lexicon" with information about the conceptual classes of the arguments and modifiers of lexical items. This informa- tlon is closely related to our selectional patterns, although the function'a] relations are semantic or conceptual whereas ours are syntactic. They use manually-encoded coarse-grained selectional
constraints to limit the patterns which are gen- erated. No evaluation results are yet reported.
IIindle aml Rooth [10] h~ve used co-occurrence data to determine whether prepositional phrases should be attached to a preceding noun or verb. Unambiguous cases in the corpus are identified first; co-occurrence statistics based on these are then used iteratively to resolve ambiguous cases. A detailed evaluation of the predictive power of the resulting p~tterns is provided, comparing the patterns against human judgements over a set of 1909 sentences, aud analyzing the error rate in terms of the type of verh and noun association.
8 C o n c l u s i o n
We have described two different approaches to evahtating automatically collected selectional patterns: by comparison to a set of manually- classified patterns and in terms of their effective- hess in selecting correct parses. We have shown that, without any manual selection of the parses or patterns ilt our trMning set, we are able to obtain selectioual p~tterns of quite satisfactory recall and precision, and which perform better than a set of manual selectional patterns in se~ lecting correct parses. We are not aware of any comparable etlorts to evaluate a hdl range of au- tomatically acquired selectional patterns.
Further studies are clearly needed, particularly of the best way in which the collected triples can be used for selection. The expected likelihood estimator is quite crude and more robust estima- tors should be tried, particularly given the sparse nature of tim data. We should experiment with better ways of combining of triples and pairs data to give estimates of semantic validity. Finally, we need to explore ways of combining these auto- tactically collected patterns with manually gen- erated selectional patterns, which will probably have narrower coverage but may be more precise and complete for the w~rbs covered.
9 . A c k n o w l e d g e m e n t s
Thi~ report is based upon work supported by the Defense Advanced Research Projects Agency under Grant N00014-9O-J-1851 from the Office of Naval Research and by the National Science l:oun(lation under Grant 11H-89-02304.
[image:6.432.45.223.26.81.2]R e f e r e n c e s
[1] Lynette ttirschman, Ralph Grishman, and Naomi Sager. Grammatically-based auto- matic word class formation. Information Processing and Management, 11(1/2):39- 57, 1975.
[2] Mahesh Chitrao and Ralph Grishman. Sta- tistical parsing of messages. In Proceedings of the Speech and Natural Language Work- shop, pages 263--266, Hidden Valley, PA, June 1990. Morgan Kaufmann.
[3] J. K. Baker. Trainable grammars for speech recognition. In D. H. Klatt and J. J. Wolf, editors, Speech Communication Papers for the 97th Meeting of the Acoustic Society of America, 1979.
[4] Beth Sundheim. Third message under-
standing evaluation and conference (MUC- 3): t'hase 1 statns report. In Proceedings of the Speech and Natural Language Workshop,
pages 301-305, Pacific Grove, CA, 1,'ebruary 1991. Morgan Kaufmann.
[5] Ezra Black, Steven Abney, Dan Flickenger, Claudia Gdaniec, Ralph Grishman, Philip tlarrison, Donald Hindle, Robert Ingria, Fred Jelinek, Judith Klavans, Mark Liber- man, Mitch Marcus, Salim Roukos, Beatrice Santorini, and Tomek Strzalkowski. A pro- cedure for quantitatively comparing the syn- tactic coverage of English. In Proceedings of the Speech and Natural Language Workshop,
pages 306-311, Pacitic Grove, CA, February 1991. Morgan Kaufinann.
[6] Philip tlarrison, Steven Abney, Ezr,~ Black, Dan Flickinger, Claudia Gdaniec, Ralph Grishman, Donald ltindle, Robert lngria, Mitch Marcus, Beatrice Santorini, and
Toiuek Strzalkowski. Evaluating syntax
performance of parser/grammars. In Pra- ceedings of the Natural Language Process- ing Systems Evaluation Workshop, Berke- ley, CA, June 1991. To be published as a Rome Laboratory Technical Report. [7] Ralph Grishman, Catherine Macleod, and
John Sterling. Evaluating parsing strate- gies using standardized parse files. In Proe. Third Conf. on Applied Natural Language Processing, Treuto, Italy, April 1992.
[8] William Gale and Kenneth Church. Poor estimates of context are worse than none. In Proceedings of the Speech and Natural Language Workshop, pages 283 287, tlidden Valley, PA, June 1990. Morgan Kaufmann. [9] R. Grishman, L. Hirschman, and N.T.
Nhan. Discovery procedures for sub-
language selectional patterns: Initial ex-
periments. Computational Linguistics,
12(3):205-16, 1986.
[10] Donald IIindle and Mats Rooth. Structural ambiguity and lexical relations. In P~aceed~ ings of the 29th Annual Meeting of the Assn. for Computational Linguistics, pages 229 236, Berkeley, CA, June 1991.
[11] Paota Velardi, Maria Teresa Pazienza, and Michela Fasolo. How to encode semantic knowledge: A method for meaning repre- sentation and computer-aided acquisition.
Computational Linguistics, 17(2):153-170, 1991.
[12] Frank Smadja. From n-grams to colloca- tions: An evaluation of xtract. In Proceed- ings of the 29th Annual Meeting of the Assn. for Computational Linguistics, pages 279-- 284, Berkeley, CA, June 1991.
[13] Nicolette Calzolari and Remo Bindi. Acqui- sition of lexical information from a large tex- tual italian corpus. In Proc. 13th Int'l Conf. Computational Linguistics (COLING-90),
pages 54-59, Iletsinki, Finland, August 1990.
[ld] Uri Zernik, editor. Lexical Acquisition: Ex- ploiting On-Line Resou~ves to Build a Lex- icon. Lawrence Erlbaum Assoc., tlillsdale, N J, 1991.