A CONCEPTUAL FRAMEWORK FOR
ONTOLOGY BASED INFORMATION
RETRIEVAL
J.UMA MAHESWARI
Lecturer, Department of Computer Science and Engineering, PSG College of Technology, Coimbatore, Tamilnadu - 641004,
Dr. G.R.KARPAGAM
Professor, Department of Computer Science and Engineering, PSG College of Technology, Coimbatore, Tamilnadu 641004, Abstract :
Improving Information retrieval by employing the use of ontologies to overcome the limitations of syntactic search has been one of the inspirations since its emergence. This paper proposes a conceptual framework to exploit ontology based Information retrieval. This framework constitutes of five phases namely Query parsing, word stemming, ontology matching, weight assignment, ranking and Information retrieval. In the first phase, the user query is parsed into sequence of words. The parsed contents are curtailed to identify the significant word by ignoring superfluous terms such as “to”, “is”,”ed”, “about” and the like in the stemming phase. The objective of the stemming phase is to throttle feature descriptors to root words, which in turn will increase efficiency; this reduces the time consumed for searching the superfluous terms, which may not significantly influence the effectiveness of the retrieval process. In the third phase ontology matching is carried out by matching the parsed words with the relevant terms in the existing ontology. If the ontology does not exist, it is recommended to generate the required ontology. In the fourth phase the weights are assigned based on the distance between the stemmed words and the terms in the ontology uses improved matchmaking algorithm. The range of weights varies from 0 to 1 based on the level of distance in the ontology (superclass-subclass). The aggregate weights are calculated for the all the combination of stemmed words. The combination with the highest score is ranked as the best and the corresponding information is retrieved. The conceptual workflow is illustrated with an e-governance case study Academic Information System.
Key words: Ontology, Information retrieval, Ranking, Weight calculation.
1. Introduction
For thousands of years people have realized the importance of archiving and finding information. With the advent of computers, it became possible to store large amounts of information and finding useful information from such collections became a necessity. The field of Information Retrieval (IR) was born to facilitate the fast and relevant retrieval. Over the last forty years, the field has matured considerably. Several IR systems are used on an everyday basis by a wide variety of users. For efficient retrieval of information there is a necessary to consider the semantics of the web. The use of ontology to overcome the limitations of keyword-based search has been put forward as one of the motivations of the Semantic Web since its emergence in the late 90’s. While there have been contributions in this direction in the last few years, most achievements so far either make partial use of the full expressive power of an ontology-based knowledge representation[1], or are based on Boolean retrieval models, and therefore lack an appropriate ranking model needed for scaling up to massive information sources.
competent method to solve the problems of retrieving the documents based on the keywords in the document. The proposed mechanism has to extract the contents from the web, based on the context of user’s query.
Semantic web is developed to overcome the following limitations of a normal web. (i) The web lacks in proper structure of information representation.
(ii) Lack of intelligence in understanding the user query by a machine (iii) Unable to deal with enormous users and their trust level.
(iv) The language used to develop the web content does not have any intended semantics.
Therefore, there is a need of a mechanism that should use ontology-based technique in Information retrieval
.
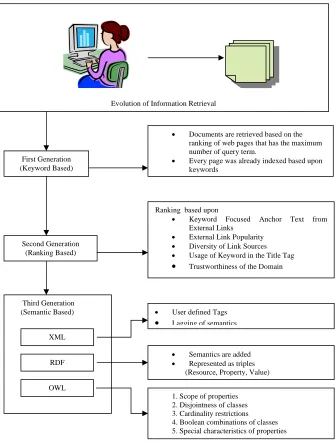
1.1. Evolution of Information Retrieval
Since the 1940s the problem of Information Retrieval (IR) has attracted increasing attention, especially because of the dramatically growing availability of documents. IR is the process of determining relevant documents from a collection of documents, based on a query presented by the user. The Fig.1. shows the evolution of Information Retrieval. This section describes the third generation of information retrieval processing. The third generation searching uses various semantic related stipulations called Meta data (XML), RDF and OWL. This is designed to combine the scalability of existing internet search engines with new and improved relevancy models.
1.1.1. XML
The emerging web is developed using XML rather than HTML. XML (Extensible Markup Language) is a general-purpose specification for creating custom markup languages. Rather than waiting for standard bodies to adopt tag set enhancements, or for browser companies to adopt each other's standards, with XML, the user is allowed to create their own set of tags like
<lecturer>
<name> David</name> . <dept> CSE</dept>
</lecturer>
If the user is interested in knowing “Name of the faculties in University”, In XML view point the returned result is semantically unsatisfactory.
<University>
< lecturer> David </lecturer> < professor> Billington </professor> < faculty> Raj </faculty>
</University>
Human can predict the answer as David, Billington and Raj. But for the machine it is very difficult to understand that lecturers and professors are also types of faculty. This kind of information makes use of the semantic model of the particular domain, and cannot be represented in XML [3] efficiently.
Fig. 1. Evolution of Information Retrieval
1.1.2. RDF
RDF (Resource Description Framework) makes semantic information as machine accessible information. It is a standard model for data interchange on the Web. RDF has features that facilitate data merging even if the underlying schemas differ, and it specifically supports the evolution of schemas over time.
RDF extends the linking structure of the Web to use URIs to name the relationship between things as well as the two ends of the link (this is usually referred to as a “triple”). Using this simple model, it allows structured and semi-structured data to be mixed, exposed, and shared across different applications.
This linking structure forms a directed, labeled graph, where the edges represent the named link between two resources, represented by the graph nodes. This graph view is the easiest possible model for RDF[3] and is often used in easy-to-understand visual explanations.
Evolution of Information Retrieval
First Generation (Keyword Based)
Documents are retrieved based on the ranking of web pages that has the maximum number of query term.
Every page was already indexed based upon keywords
Second Generation (Ranking Based)
Ranking based upon
Keyword Focused Anchor Text from
External Links External Link Popularity Diversity of Link Sources Usage of Keyword in the Title Tag Trustworthiness of the Domain
Third Generation (Semantic Based)
XML
RDF
OWL
User defined Tags Lagging of semantics
Semantics are added Represented as triples
(Resource, Property, Value)
1.1.2.1 Node elements and property elements
Fig. 2. RDF Graph – Representation of nodes and properties
An RDF graph is given in Fig. 2, where the nodes are represented as ovals denote classes and the edge represents the properties. The class and properties can be some other resources.
1.1.2.2.2. Limitations of the expressive power of RDF Schema
RDF and RDFS allow the representation of some ontological knowledge. The main modeling primitives of RDF/RDFS concern the organization of vocabularies in typed hierarchies: subclass and sub property relationships, domain and range restrictions, and instances of classes. However a number of other features are missing. They are
Local scope of properties: rdfs: range denotes the range of a property, Consider the sentence “Animal eat plants”. This rule is applied to all classes of animals. Thus in RDF Schema it is not possible to apply range restrictions only to certain classes. For example according to the previous rule saying cows eat only plants, while other animals may eat meat is an invalid statement.
Disjointness of classes: Sometimes there is a need to say that classes are disjoint. For example, male and female are disjoint. But in RDF Schema is used to represent subclass relationships for example female is a subclass of person.
Boolean combinations of classes: Sometimes there is a need to build new classes by combining other classes using union, intersection and complement. For example, denote the class person to be the disjoint union of the classes male and female. RDF Schema does not allow such definitions.
Cardinality restrictions: Restrictions on how many distinct values a property may or must take is represented as cardinality ratio. For example, a person has exactly two parents, and that a course is taught by at least one lecturer. Again, such restrictions are impossible to express in RDF Schema.
Special characteristics of properties: Sometimes it is useful to say that a property is transitive (like “greater than"), unique (like “is mother of"), or the inverse of another property (like “eats" and “is eaten by"). RDF does not allow specifying these kinds of features.
1.1.2 OWL
The OWL Web Ontology Language is designed for applications that need to process the content of information instead of just presenting information to humans. OWL [3] facilitates greater machine interpretability of Web content than that supported by XML, RDF, and RDF Schema (RDF-S) by providing additional vocabulary along with a formal semantics. OWL has three increasingly expressive sublanguages: OWL Lite, OWL DL, and OWL Full. OWL supports complement, disjoint, functional properties and it also allow the overlapping of classes and properties. OWL is also used for the specification of ontology.
1.1.3 Ontology
Ontology is an explicit specification of a conceptualization. The representational primitives are typically classes (or sets), attributes (or properties), and relationships (or relations among class members). The definitions of the representational primitives include information about their meaning and constraints on their logically consistent application. The ontology is a set of concepts - such as things, events, and relations - that are specified in some way (such as specific natural language) in order to create an agreed-upon vocabulary for exchanging
information. Domain Ontology: models a specific domain. It represents the particular meanings of terms as they apply to that domain (ex. CHEMICALS, Gene Ontology). The proposed method uses all the above concepts to improve the efficiency of the search.
www.example.com David
is created by
2. Related Work
Fig. 3. Hybrid approach for information retrieval
The above diagram shows the organization of the proposed approach which combines some of the techniques from syntax based search and some concepts related to semantics like ontology navigation and distance based calculation. This Hybrid framework is used for efficient retrieval of information from the web based on the semantics of the user query.
FINDUR[2] system at AT&T is ontology based information retrieval system. The basic notion of FINDUR was query expansion, which is, taking synonyms or hyponyms (more specific terms) and including them in the input terms, thereby expanding the query. FINDUR system represents a simple ontology containing mostly thesaurus information built in a description logic (CLASSIC) using the most basic notions of Wordnet (synsets and hyper/hyponyms). But the ontology used in FINDUR is too simple, and terms defined in ontology aren’t be used to markup the web’s content, so we can’t obtain logical views of documents by using semantic index terms.
In [10], an information retrieval server based on ontology and multi-agent is introduced, which integrates several kinds of agents, such as inference agent, preprocessing agent, information processing agent, etc. The system also uses ontologies to classify the domains of documents and assist user to normalize their queries. In [5], MELISA - MEdical Literature Search Agent – a prototype of an ontology-based information retrieval agent is introduced. But both these researches don’t use formal ontology language to generate ontology used for information retrieval, the inference capability about ontology is weak.
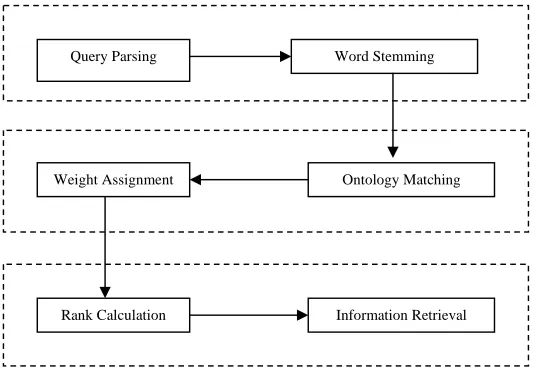
3. Conceptual Framework for Ontology based Information Retrieval
The Fig. 4. shows the different level of architecture for ontology based information retrieval. The first level is called user level because the operations query parsing and word stemming is performed on the user query. The second level is called as ontology level because for matching the stemmed words and to assign the weights the relevant ontology is needed according to the user query. The third level is called as document level because the combinational score is used for ranking to get the best documents from the web.
Search Algorithm
Syntax based Semantics based
Graph Traversal Stemming
String Match Distance Based
Calculation
Fig. 4. Framework for Ontology based Information Retrieval
The steps involved in these layers are 3.1 Query parsing
To retrieve the information for the need of user, get the query from them. Split the query into meaningful words and apply the word stemming process.
3.2 Word stemming
Linguistically, words follow morphological rules that allow a person to derive variants of a same idea to evoke an action (verb), an object or concept (noun) or the property of something (adjective). For instance, the following words are derived from the same stem and share an abstract meaning of action and movement.
Activate Activates, Activated
The word “Activate” is used to represent the words “Activates and Activated”. Stemming does the reverse process: it deduces the stem from a fully suffixed word according to its morphological rules. These rules concern morphological and inflectional suffixes. The former type usually changes the lexical category of words whereas the latter indicates plural and gender and it also removes the unwanted words like a, an, the etc. The sample code for removal of stop words and stemming (Porter Stemmer [6]) is as follows
<?php
/*Create a list of stem words for a article title */
require_once 'libs/PorterStemmer.php'; $title = "blogging tips for late workers"; /* Stop words to filter out */
$stop_words = array("the", "and", "a", "to", "of", "in", "i", "is", "that", "it", "on", "you", "this", "for", "but", "with", "are", "have", "be", "at", "or", "as", "was", "so", "if", "out", "not");
$words = explode(" ", $title); foreach($words as $word) {
$stem = PorterStemmer::Stem($word); /* Remove stop words */
if(!in_array($stem, $stop_words)) {
$stem_words[] = $stem;} } print_r($stem_words); }
Array (
[0] => blog [1] => tip
Query Parsing Word Stemming
Ontology Matching Weight Assignment
Rank Calculation Information Retrieval
Document Level User Level
Ontology level
[2] => late [3] => worker) 3.3 Ontology Matching
After splitting the query into meaningful words, each word should be checked against the ontology. All the combination of words is taken for processing. Specific domain ontology is taken to verify whether the word is present in that ontology. If yes then the relationship of the words are taken into the consideration.
3.4 Weight Assignment
The weight is assigned to each word with respect to other word according to the relationship in ontology like superclass, immediate subclass, subclass etc based on improved matching [4] algorithm.
3.5 Rank Calculation and Information retrieval
The cumulative weight is calculated for each combination of words based on improved matching algorithm. The best document gets the minimum score. The documents are arranged in ascending order according to their cumulative score.
4. Implementation of Ontology Based Information Retrieval - E-Governance In Academics – A Case Study
4.1 E-Governance
E-Governance creates comfortable, transparent, and make interaction for the people who need online information about the system.
4.2 Need for E-Governance in Academics
Generally administrative systems in an academic environment are disjoint and support independent queries. The objective in this work is to semantically connect these independent systems to provide support to queries run on the integrated platform. The proposed framework, by enriching educational material in the legacy systems, provides a value added semantics layer where activities such as query, reasoning and efficient information retrieval can be carried out to support management requirements.
Large and eminent academic institution needs enormous amounts of documents to be maintained. Once if the document maintenance is made automated then it is very easy for the academician to retrieve the relevant documents. Any academic institution has to maintain the documents like (i) Admission Details (ii) Course Details (iii) Department Details (iv) List of programmes conducted by each department (v) Student details (vi) Staff Details (vii)Accounts (viii)Conferences and workshops organized (ix)Placement details (x) Examination details etc.
The Semantic Web is a web of machine processable meanings underpinned by shared and formally defined ontologies. In order to coordinate different semantic web activities, an educational ontology is explicitly defined to share a contextual conceptualization of the educational domain. This allows the users to make their resources more machine processable by collaboratively constructing an enriched layer of the semantic web that
Criteria 1: If the two stemmed words are not present in the ontology or any one word is not present in the ontology then the weight is assigned as zero.
Criteria 2: If the root word is a direct superclass of another word and the then the weight assigned is 1
Criteria 3: If the root word is a direct subclass of another word and the then the weight assigned is 0.5
Criteria 4: If the root word is a subclass of another word and the then the weight assigned is 1/level of relationship.
Fig. 5. Ontology for E-Governance in Academics
The Fig. 5 shows the ontology for academic services[8]. The Ontology is created by having the root node as “thing” then follows the various categories like Administration, Controller of examination, Academic departments, and placement. Each sub category has many other nodes related to it. The academic ontology is created using protégé 3.1.
4.3 Sample Query Processing
This section shows how the above described conceptual frame work helps in efficient retrieval of documents for the query “I want to know the cse department details of psgtech”
Query Parsing “i want to know the cse department details of psgtech”
Word Stemming
“want” “know” “cse” “department” “details”
Ontology Matching Weight Assignment
Fig. 6. Work Flow for ontology Based information retrieval
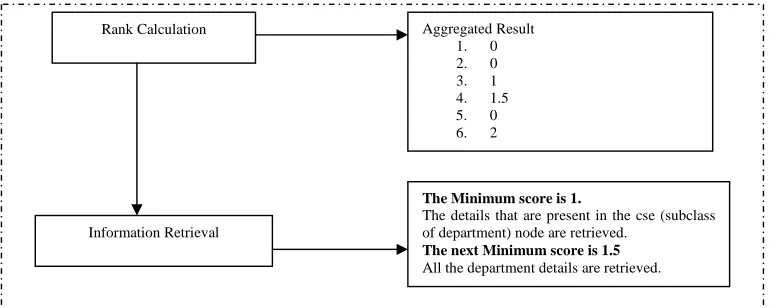
The above figure shows the diagrammatic representation of the proposed framework. The output of each phase is also shown in Fig 6. In weight assignment phase for each combination of words the score is calculated depending upon the criteria specified in section 3.4.In ranking the aggregated weight is calculated for each combinations and it is sorted in ascending order. In our example the minimum score is 1. So the document which comes under departmentcse is retrieved. The user also needs the same.
5. CONCLUSION
This method provides the new way of searching the contents on the web. It finds the relevant document for the user query using the techniques called word stemming, ontology matching, weight assignment, rank calculation etc. In the ontology matching phase an improved matching algorithm is used to improve the relevancy of retrieval. All these phases are explained with a case study called E-Governance in academics. The Query parsing and word stemming phase is further extended by including query expansion technique, rest of the phases are improved further by adding social annotations and phrase level matching.
References
[1] David Vallet, Miriam Fernández, and Pablo Castells , An Ontology-Based Information Retrieval. Model. [2] Deborah L.McGuinness, Harley Manning and Thomas W.Beattie, Knowledge assisted search.
[3] Grigoris Antoniou and Frank Van Harmelen, A Semantic Web Primer.
[4] Hui Peng, Zhongzhi Shi1, Liang Chang, Wenjia Niu, Improving Grade Match to Value Match for Semantic Web Service Discovery, Fourth International Conference on Natural Computation IEEE,2008.
[5] Jose Maria Abasolo, Mario Gomez, MELISA. An ontology- based agent for information retreival in Medicine, Proceedings of the First International Workshop on the Semantic Web
[6] Michael Fuller JustinZobel , Conation-based Comparison of Stemming Algorithms [7] http://www.mindswap.org/
[8] Qurban A Memon and Shakeel a.Khoja, Academic Program Administration via Semantic Web – A case Study, World Academy of Science, Engineering and Technology ,2009.
[9] Rajendra Akerkar, Foundations of the Semantic web, Narosa Publishing House Pvt.Ltd, 2009
[10] Wu Chenggang, Jiao Wenpin and Tian Qijia , An information retrieval server based on ontology and multiagent, Journal of computer research & development, 2001, 38(6), pp. 641-647.
Rank Calculation Aggregated Result
1. 0 2. 0 3. 1 4. 1.5 5. 0 6. 2
Information Retrieval
The Minimum score is 1.
The details that are present in the cse (subclass of department) node are retrieved.
The next Minimum score is 1.5 All the department details are retrieved.