LAB 01:
INTRODUCTION TO COMPILERS.
Theory
A compiler translates (or compiles) a program written in a high-level programming language that is suitable for human programmers into the low-level machine language that is required by computers. During this process, the compiler will also attempt to spot and report obvious programmer mistakes.
The name "compiler" is primarily used for programs that translate source code from a high-level programming language to a lower level language (e.g., assembly language or machine code). A program that translates between high-level languages is usually called a language translator, source to source translator, or language converter.
A compiler is likely to perform many or all of the following operations: lexical analysis, preprocessing, parsing, semantic analysis, code generation, and code optimization.
A compiler is a program that translates a source program written in some high-level programming language (such as Java) into machine code for some computer architecture. The generated machine code can be later executed many times against different data each time.
An interpreter reads an executable source program written in a high-level programming language as well as data for this program, and it runs the program against the data to produce some results. One example is the Unix shell interpreter, which runs operating system commands interactively.
will be analyzed and evaluated on every loop step. Some languages, such as Java and Lisp, come with both an interpreter and a compiler.
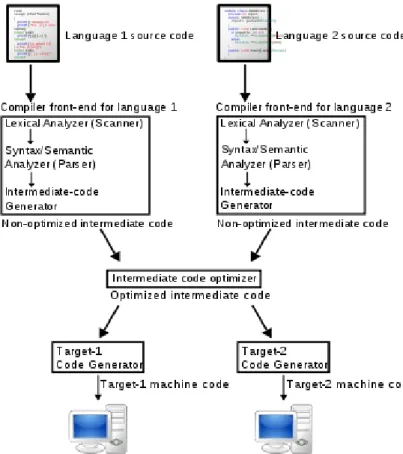
A diagram of the operation of a typical multi-language, multi-target compiler is shown in figure 1.
Lab Tasks:
1. Write a program that takes a string as input and stores and displays its characters.
2. Write a program that takes a string as input and:
a) Display the number of times a single character occurs within the input string.
LAB 02:
LEARNING COMPILER CONSTRUCTION TOOLS.
Theory
The compilation process is split into several phases with well-defined interfaces. Conceptually, these phases operate in sequence (though in practice, they are often interleaved), each phase (except the first) taking the output from the previous phase as its input. It is common to let each phase be handled by a separate module. Some of these modules are written by hand, while others may be generated from specifications. Often, some of the modules can be shared between several compilers.
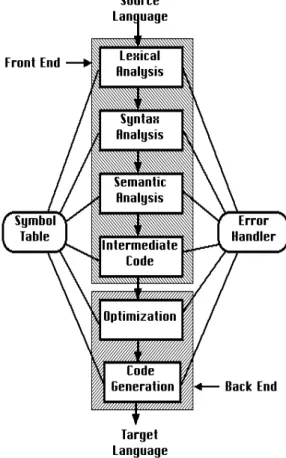
Different phases of a compiler are shown in figure 2 given below.
A common division into phases is described below. In some compilers, the ordering of phases may differ slightly, some phases may be combined or split into several phases or some extra phases may be inserted between those mentioned below.
Lexical analysis This is the initial part of reading and analyzing the program text. The text is read and divided into tokens, each of which corresponds to a symbol in the programming language, e.g., a variable name, keyword or number.
Syntax analysis This phase takes the list of tokens produced by the lexical analysis and arranges these in a tree-structure (called the syntax tree) that reflects the structure of the program. This phase is often called parsing.
Type checking This phase analyses the syntax tree to determine if the program violates certain consistency requirements, e.g., if a variable is used but not declared or if it is used in a context that doesn’t make sense given the type of the variable, such as trying to use a Boolean value as a function pointer.
Intermediate code generation The program is translated to a simple machine independent intermediate language.
Register allocation The symbolic variable names used in the intermediate code are translated to numbers, each of which corresponds to a register in the target machine code.
Machine code generation The intermediate language is translated to assembly language (a textual representation of machine code) for specific machine architecture.
Assembly and linking The assembly-language code is translated into binary representation and addresses of variables, functions, etc., are determined.
The first three phases are collectively called the frontend of the compiler and the last three phases are collectively called the backend. The middle part of the compiler is in this context only the intermediate code generation, but this often includes various optimizations and transformations on the intermediate code.
type checker can assume absence of syntax errors and the code generation can assume absence of type errors.
Assembly and linking are typically done by programs supplied by the machine or operating system vendor, and are hence not part of the compiler itself.
Lab Tasks:
1. Write a program that takes an integer array as input and checks whether each of the elements in the array is even or odd, using recursion.
2. Write a program using a recursive function that takes an integer array as input and return the minimum and maximum value from the array elements.
LAB 03:
WORKINGWITH PARSERS.
Theory
When Lexical analysis splits the input into tokens, the purpose of syntax analysis (also known as parsing) is to recombine these tokens. Not back into a list of characters, but into a data structure called the syntax tree of the text. As the name indicates, this is a tree structure. The leaves of this tree are the tokens found by the lexical analysis, and if the leaves are read from left to right, the sequence is the same as in the input text. Hence, what is important in the syntax tree is how these leaves are combined to form the structure of the tree and how the interior nodes of the tree are labeled.
In addition to finding the structure of the input text, the syntax analysis must also reject invalid texts by reporting syntax errors.
The parsing process of a computer language is demonstrated that has three stages: lexical analysis, syntactic analysis and semantic parsing.
Lexical analysis:
The first stage is the token generation or lexical analysis by which the input character stream is split into meaningful symbols (tokens) defined by a grammar of regular expressions. For example, the lexical analyzer takes "12*(3+4) ^2" and splits it into the tokens 12, *, (, 3, +, 4, ), ^ and 2.
Syntax analysis:
This stage is parsing or syntactic analysis, which checks that the tokens form an allowable expression. This is usually done with reference to a Context Free Grammar. It cannot check (in a programming language) the types or proper declaration of identifiers.
Semantic parsing:
This is the final phase which works out the implications of the expression just validated and takes the appropriate actions. For examples, an interpreter will evaluate the expression, a compiler will generate code.
The task of the parser is essentially to determine if and how the input can be derived from the start symbol of the grammar. This can be done in essentially two ways:
Top-down parsing- Top-down parsing can be viewed as an attempt to find
left-most derivations of an input-stream by searching for parse trees using a top-down expansion of the given formal grammar rules. Tokens are consumed from left to right. Inclusive choice is used to accommodate ambiguity by expanding all alternative right-hand-sides of grammar rules.
Bottom-up parsing - A parser can start with the input and attempt to rewrite
Lab Tasks:
1. Write a program in a language of your choice that takes input an array, sort the elements of the array, and store them in another array.
2. Write a program that takes an array of integers as input and finds: a) The index of the given element.
b) The element at the given index.
LAB 04:
UNDERSTANDING GRAMMARAND FSMS.
Theory
Context-free grammars describe sets of strings, i.e., languages. Additionally, a context-free grammar also defines structure on the strings in the language it defines. A language is defined over some alphabet, for example the set of tokens produced by a lexical analyzer or the set of alphanumeric characters. The symbols in the alphabet are called terminals.
A context-free grammar recursively defines several sets of strings. Each set is denoted by a name, which is called a non-terminal. The set of non-terminals is disjoint from the set of terminals. One of the non-terminals is chosen to denote the language described by the grammar. This is called the start symbol of the grammar. The sets are described by a number of productions. Each production describes some of the possible strings that are contained in the set denoted by a non-terminal. A production has the form:
N X1 . . . Xn
where N is a non-terminal and X1 . . . Xn are zero or more symbols, each of which
is either a terminal or a non-terminal. The intended meaning of this notation is to say that the set denoted by N contains strings that are obtained by concatenating strings from the sets denoted by X1 . . . Xn. In this setting, a terminal denotes a
singleton set, just like alphabet characters in regular expressions. We will, when no confusion is likely, equate a non-terminal with the set of strings it denotes.
Some examples:
Aa
says that the set denoted by the non-terminal A contains the one-character string a.
AaA
that A contains all non-empty sequences of as and is hence (in the absence of other productions) equivalent to the regular expression a+.
We can define a grammar equivalent to the regular expression a* by the two
productions:
B
B aB
where the first production indicates that the empty string is part of the set B. Compare this grammar with the definition of s* in figure 4.
Figure 4: Regular expressions.
Productions with empty right-hand sides are called empty productions. These are sometimes written with an e on the right hand side instead of leaving it empty.
Context-free grammars are, capable of expressing much more complex languages. The language {anbn | n >0} is not regular. It is, however, easily described by the
S
S aSb
The second production ensures that the as and bs are paired symmetrically around the middle of the string, ensuring that they occur in equal number.
The examples have used only one terminal per grammar. When several non-terminals are used, we must make it clear which of these is the start symbol. By convention (if nothing else is stated), the non-terminal on the left-hand side of the first production is the start symbol. As an example, the grammar:
T R T aTa R b
R bR
has T as start symbol and denotes the set of strings that start with any number of as followed by a non-zero number of bs and then the same number of as with which it started.
Sometimes, a shorthand notation is used where all the productions of the same non-terminal are combined to a single rule, using the alternative symbol (|) from regular expressions to separate the right-hand sides. In this notation, the above grammar would read:
T R | aTa R b | bR
There are still four productions in the grammar, even though the arrow symbol is only used twice.
Each sub-expression of the regular expression is numbered and sub-expression si is
assigned a non-terminal Ni. The productions for Ni depend on the shape of si as
Figure 5: From regular expressions to context free grammars.
A regular expression can systematically be rewritten as a context free grammar by using a non-terminal for every sub-expression in the regular expression and using one or two productions for each non-terminal. The construction is shown in figure 5. So, if we can think of a way of expressing a language as a regular expression, it is easy to make a grammar for it. However, we will also want to use grammars to describe non-regular languages. An example is the kind of arithmetic expressions that are part of most programming languages
Lab Tasks:
1. Consider the context free grammar:
S -> SS + | SS * | a
Show how the string aa+a* can be generated by this grammar.
LAB 05:
WORKINGON LEXICAL ANALYSIS.
Theory
Lexical analysis or scanning is the process where the stream of characters making up the source program is read from left-to-right and grouped into tokens. Tokens are sequences of characters with a collective meaning. There are usually only a small number of tokens for a programming language: constants (integer, double, char, string, etc.), operators (arithmetic, relational, logical), punctuation, and reserved words.
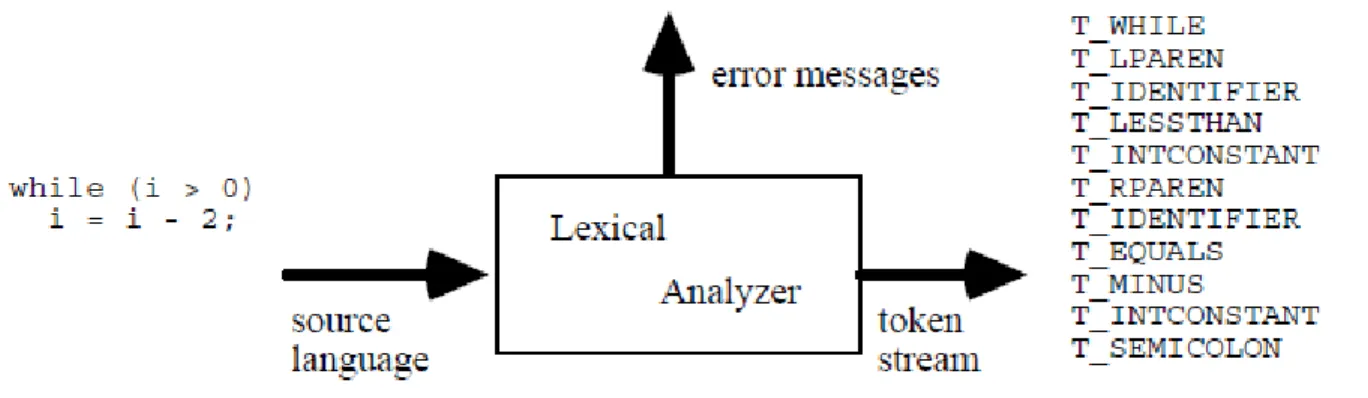
Figure 6: The Lexical Analysis Process.
The lexical analyzer takes a source program as input, and produces a stream of tokens as output. The lexical analyzer might recognize particular instances of tokens such as:
3 or 255 for an integer constant token
"Fred" or "Wilma" for a string constant token numTickets or queue for a variable token
A lexical analyzer or Lexer for short, will as its input take a string of individual letters and divide this string into tokens. Additionally, it will filter out whatever separates the tokens (the so-called white-space), i.e., lay-out characters (spaces, newlines etc.) and comments.
be made an integral part of syntax analysis, and in simple systems this is indeed often done. However, there are reasons for keeping the phases separate:
Efficiency: A lexer may do the simple parts of the work faster than the more general parser can. Furthermore, the size of a system that is split in two may be smaller than a combined system. This may seem paradoxical but, as we shall see, there is a non-linear factor involved which may make a separated system smaller than a combined system.
Modularity: The syntactical description of the language need not be cluttered with small lexical details such as white-space and comments.
Tradition: Languages are often designed with separate lexical and syntactical phases in mind, and the standard documents of such languages typically separate lexical and syntactical elements of the languages.
Lexers are normally constructed by Lexer generators, which transform human-readable specifications of tokens and white-space into efficient programs. For lexical analysis, specifications are traditionally written using regular expressions: An algebraic notation for describing sets of strings. The generated lexers are in a class of extremely simple programs called finite automata.
Some issues related to Lexer are addressed below:
A lexer has to distinguish between several different types of tokens, e.g., numbers, variables and keywords. Each of these is described by its own regular expression.
A lexer does not check if its entire input is included in the languages defined by the regular expressions. Instead, it has to cut the input into pieces (tokens), each of which is included in one of the languages.
If there are several ways to split the input into legal tokens, the lexer has to decide which of these it should use.
1. Write a program that opens a file and creates character tokens (class and value) of the whole file. Creating tokens means to break the file into tokens according to the class and value.
LAB 06:
IMPLEMENTATION OF TOP DOWN PARSING.
Theory
The syntax analysis phase of a compiler will take a string of tokens produced by the lexical analyzer, and from this construct a syntax tree for the string by finding a derivation of the string from the start symbol of the grammar. There are two major parsing approaches: top-down and bottom-up.
Top-down parsing can be viewed as an attempt to find left-most derivations of an input-stream by searching for parse-trees using a top-down expansion of the given formal grammar rules. Tokens are consumed from left to right. Inclusive choice is used to accommodate ambiguity by expanding all alternative right-hand-sides of grammar rules. In top-down parsing, we start with the start symbol and apply the productions until we arrive at the desired string.
This simple grammar recognizes strings consisting of any number of a’s followed by at least one (and possibly more) b’s:
S AB A aA | ε
B b | bB
Here is a top-down parse of aaab. While using the Top-down parsing
approach, we begin with the start symbol and at each step, expand one of the remaining non-terminals by replacing it with the right side of one of its productions. We repeat until only terminals remain. The top-down parse produces a leftmost derivation of the sentence.
S
AB S AB
aAB A aA
aaAB A aA
aaaAB A aA
aaaεB A ε
Lab Tasks:
1. Using Push down Automata, i.e. stack implementation, make a program in the language of your choice that checks the validity of the left and right braces ‘(‘& ‘(‘used in mathematical equation.
LAB 07:
IMPLEMENTATION OF BOTTOM UPPARSING.
Theory
The syntax analysis phase of a compiler verifies that the sequence of tokens extracted by the scanner represents a valid sentence in the grammar of the programming language. One of the parsing approaches is Bottom-up parsing (also known as shift-reduce parsing). It is a strategy for analyzing unknown data relationships that attempts to identify the most fundamental units first, and then to infer higher-order structures from them. It attempts to build trees upward toward the start symbol.
In bottom-up parsing, we start with the string and reduce it to the start symbol by applying the productions backwards. It works by identifying terminal symbols first, and combines them successively to produce non-terminals. The productions of the parser can be used to build a parse tree of a program written in human-readable source code.
Using the following grammar for recognizing strings consisting of any number of a’s followed by at least one b:
S AB A aA | ε
B b | bB
The bottom-up parse of aaab produces the following rightmost derivation of the sentence.
aaab
aaaεb (insert ε)
aaaAb A ε
aaAb A aA
aAb A aA
Ab A aA
AB B b
We begin with the sentence of terminals and each step applies a production in reverse, replacing a substring that matches the right side with the non-terminal on the left. We continue until we have substituted our way back to the start symbol. If we read from the bottom to top, the bottom-up parse prints out a rightmost derivation of the sentence.
Lab Tasks:
1. Design a primitive push down recognizer for each of the following sets of sequences:
1. { an bm } where n > m > 0;
2. { an bm } where n >= m >= 0;
3. { an bm } where n < m & n, m > 0;
4. { an bm } where n is odd, m is even;
2. For each of the following input string, indicate whether it will encounter a shift/ reduce conflict or no conflict when parsing.
a) b c b) b b c a b c) b a c b
Use the grammar given below:
LAB 08:
UNDERSTANDING SYNTAX DIRECTED TRANSLATION.
Theory
Syntax-directed translation refers to a method of compiler implementation where the source language translation is completely driven by the parser. In other words, the parsing process and parse trees are used to direct semantic analysis and the translation of the source program. This can be a separate phase of a compiler or we can augment our conventional grammar with information to control the semantic analysis and translation. Such grammars are called attribute grammars. It has three components: a source language grammar, a set of attributes, and a set of semantic actions.
We augment a grammar by associating attributes with each grammar symbol that describes its properties. An attribute has a name and an associated value: a string, a number, a type, a memory location or an assigned register. With each production in a grammar, we give semantic rules or actions, which describe how to compute the attribute values associated with each grammar symbol in a production. The attribute value for a parse node may depend on information from its children nodes below or its siblings and parent node above.
There are two types of attributes we might encounter: synthesized or inherited. Synthesized attributes are those attributes that are passed up a parse tree, i.e., the left side attribute is computed from the right-side attributes. The lexical analyzer usually supplies the attributes of terminals and the synthesized ones are built up for the nonterminals and passed up the tree as shown in figure 7.
Figure 7: Synthesized attributes in a parse tree.
These attributes are used for passing information about the context to nodes further down the tree.
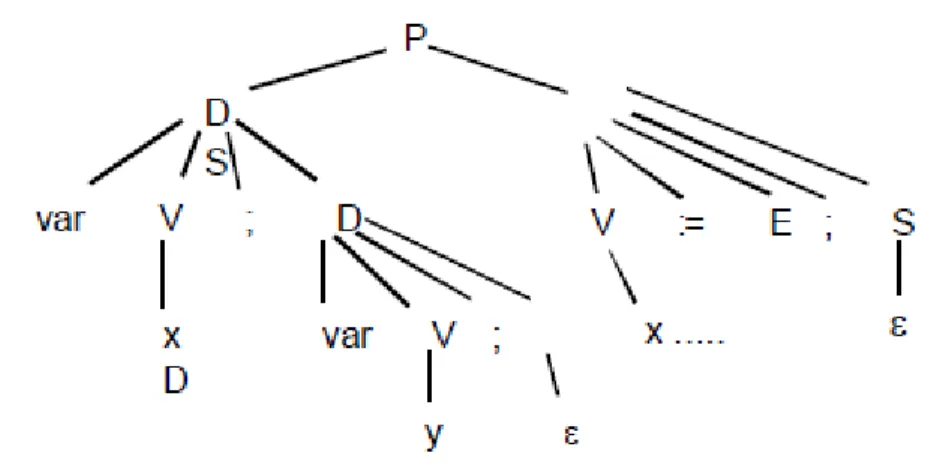
Consider the following grammar that defines declarations and simple expressions in a Pascal-like syntax:
P DS
D var V; D | ε
S V := E; S | ε
V x | y | z
Now we add two attributes to this grammar, name and dl, for the name of a variable and the list of declarations. Each time a new variable is declared, a synthesized attribute for its name is attached to it. That name is added to a list of variables declared so far in the synthesized attribute dl that is created from the declaration block. The list of variables is then passed as an inherited attribute to the statements following the declarations for use in checking that variables are declared before use.
If we parse the following code, its attribute structure would look as given in figure 8:
y := ...;
Figure 8: Attribute Structure of the code.
Use Table 1 as format for writing syntax-directed definitions.
Table 1: Format for writing Syntax-directed Definitions.
Where, E.val is one of the attributes of E.
Lab Tasks:
1. Write a program in a language of your choice that checks the validity of any arithmetic equation, and solves the equation. You also have to create the tokens.
LAB 09:
UNDERSTANDING TYPE CHECKING.
Theory
Lexical analyzing and parsing will reject many texts as not being correct programs. However, many languages have well-formedness requirements that can not be handled exclusively by simple techniques. These requirements can, for example, be static type-correctness or a requirement that pattern-matching or case-statements are exhaustive.
These properties are most often not context-free, i.e., they can not be checked by membership of a context-free language. Consequently, they are checked by a phase that (conceptually) comes after syntax analysis (though it may be interleaved with it). These checks may happen in a phase that does nothing else, or they may be combined with the actual translation. Often, the translator may exploit or depend on type information, which makes it natural to combine calculation of types with the actual translation.
Type checking checks and enforces the rules of the type system to prevent type errors from happening. A type error happens when an expression produces a value outside the set of values it is supposed to have.
The type checking may be:
Strong, weak, or something in between
At compile time, run time, or something in between
Strong type checking prevents all type errors from happening. The checking may happen at compile time or at run time or partly at compile time and partly at run time. A strongly-typed language is one that uses strong type checking.
Weak type checking does not prevent type errors from happening. A weakly-typed language is one that uses weak type checking.
Run-time type checking is more expressive since it rejects fewer programs than compile-time type checking.
Run-time type checking may slow down the program since it introduces checks that must be performed at run time.
Since there is no one clear winner between compile-time checking and run-time checking most modern languages do a bit of both. Java, for example, checks for many errors at compile times and for others at run time.
Lab Tasks:
1. Write type expressions for an array of integers with index ranging from 1 to 100.
2. For expressions with the operators +, -, *, div and mod, in the language of your choice, write type checking rules that assign to each sub
LAB 10:
UNDERSTANDING NAME SEARCH ALGORITHMS.
Theory
During type checking we need to answer whether two type expressions s or t are the same or not. This can be answered by deciding the equivalence between the two types. There are two different categories of equivalence – name equivalence and structural equivalence.
1. Name equivalence: Two types are name equivalent if they have the same name or label. For example, consider the following few type and variable declarations:
typedef int Value
typedef int Total
…
Value var1, var2
Total var3, var4
Here, the variables var1 and var2 are name equivalent, so are var3 and var4. However, var1 and var4 are not name equivalent, because their type names are different.
2. Structural equivalence: it checks the structure of the type and determines equivalence based on whether or not the types have had the same constructor applied to structurally equivalent types. It is checked recursively. For example, the types array (I1, T1) and array (I2,
T2) are structurally equivalent if I1 and I2 are equal and T1 and T2 are
Lab Task:
1. Read and understand the following code carefully and develop test conditions to check the efficiency of the code in terns of compilation:
datarecord *search(key,list)
typekey key; datarecord *list;
{
datarecord *p;
for(p=list; p!=NULL && key !=pk; p=pnext);
return (p);
LAB 11:
UNDERSTANDING RUN TIME ENVIRONMENT.
Theory
Runtime environment refers to the program snap-shot during execution. A program has three main segments:
Code for the program
Static and global variables
Local variables and arguments.
Each segment needs proper allocation of memory to hold their values. Thus, three kinds of entities are to be managed at the runtime. The entities are:
1. Generated Code: For various procedures and programs that form text or code segment. The size of this segment is known at compile time. Thus, the space can be allocated statically before the execution commences.
2. Data Objects: they can be of different types:
a. Global variables/constants: The size of the total space required by global variables or constants is known at compile time.
b. Local Variables: For local variables also, the size is known at compile time.
c. Variables created dynamically: These variables correspond to the space created in response to the memory allocation requests from the program during execution. Since it depends on the execution sequence of the program, the size is unknown at compile time. The dynamic allocation is done in heap.
3. Stack: To keep track of procedure activations.
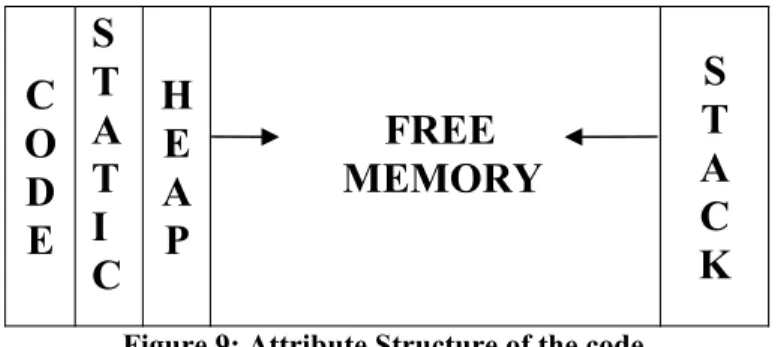
The logical address space of a program can be viewed as in Figure 9. The code occupies the lowest portion. The global variables are allocated in the static portion. In the remaining chunk of the address space, stack and heap are allocated from the opposite ends to have maximum flexibility.
nested procedure calls. The reverse may also become true for some other program. Thus, allocating stack and heap from the opposite ends is justified.
C O D E S T A T I C H E A P FREE MEMORY S T A C K
Figure 9: Attribute Structure of the code.
Associated with each activation of a procedure, some storage space is needed for the variables. This storage is called activation record or frame. A typical activation record contains the following things:
Parameters passed to the procedure.
Bookkeeping information, including the return address.
Space for local variables.
Space for local temporaries, generated by the compiler to hold sub expression values.
An organization is shown in figure 10. The size of the bookkeeping information is fixed and is same for all the procedures. The compiler can determine the size of the other segments.
Space for arguments (Parameters) Space for bookkeeping
information including return address Space for Local data
Space for local temporaries
Processor registers are also part of runtime environment. They are used to store temporaries, local variables, global variables and some other special information. For example, the program counter points to the statement to be executed next while the stack pointer points to the top of the stack. A few registers are used to keep track of procedure activations:
Frame Pointer (fp): It points to the current activation record.
Argument Pointer (ap): It points to the area of activation record reserved for arguments.
The structure of the activation record, that is, fields contained in it, may vary depending upon the language. If a language supports nested definition of procedures, the access to the variables is defined by certain scope rules.
Two different classes of runtime environment and their associated activation record structures are:
1. Stack based environment without local procedures. 2. Stack based environment with local procedures.
Lab Task:
1. What is printed by the following program, assuming:
(a) Call by Value (b) Call by Reference (c) Call by Name
Program main(input, output);
Procedure p (x,y,z);
begin
y := y + 1;
z := z + x;
end;
begin
a := 2;
b := 3;
p(a+b, a, a);
print a;
LAB 12:
WORKINGWITH CODE OPTIMIZATION.
Theory
Optimization is the process of transforming a piece of code to make more efficient (either in terms of time or space) without changing its output or side-effects. The only difference visible to the code’s user should be that it runs faster and/or consumes less memory. It is really a misnomer that the name implies you are finding an "optimal" solution— in truth, optimization aims to improve, not perfect, the result.
Optimizations can be done by a compiler in three places: In the source code (i.e. on the abstract syntax), in the intermediate code and in the machine code. Some optimizations can be specific to the source language or the machine language, but it makes sense to perform optimizations mainly in the intermediate language, as the optimizations hence can be shared among all the compilers that use the same intermediate language. Also, the intermediate language is typically simpler than both the source language and the machine language, making the effort of doing optimizations smaller.
Optimizations performed exclusively within a basic block are called "local optimizations". These are typically the easiest to perform since we do not consider any control flow information; we just work with the statements within the block. Many of the local optimizations have corresponding global optimizations that operate on the same principle, but require additional analysis to perform.
Optimizing compilers have a wide array of optimizations that they can employ, but here only few are mentioned and how they can be implemented.
Common Sub-expression Elimination
Code Motion
Code motion (also called code hoisting) unifies sequences of code common to one or more basic blocks to reduce code size and potentially avoid expensive re-evaluation. The most common form of code motion is loop-invariant code motion that moves statements that evaluate to the same value every iteration of the loop to somewhere outside the loop.
Constant Propagation
Some variables may, at some points in the program, have values that are always equal to some constant. If these variables are used in calculations, these calculations may be done at compile-time. Furthermore, the variables that hold the results of these computations may now also become constant, which may enable even more compile-time calculations. Constant propagation algorithms first trace the flow of constant values through the program and then eliminate calculations. The more advanced methods look at conditions, so they can exploit that after a test on, e.g., x==0, x is indeed the constant 0.
Index-check Elimination
Lab Task:
1. Read and understand the following piece of code:
begin
for i:= 1 to n do
for j:= 1 to n do
c[i,j] :=0;
for i:= 1 to n do
for j:= 1 to n do
for k:= 1 to n do
c[i , j] := c[i , j] + a[i , k] * b[k , j]
end;