2017 3rd International Conference on Electronic Information Technology and Intellectualization (ICEITI 2017) ISBN: 978-1-60595-512-4
An Improved Collaborative Filtering
Recommendation Algorithm
Maojie Lin and Yunjian Peng
ABSTRACT
In order to improve the quality of recommender system, a new method of similarity calculation is proposed in this paper. Compared with traditional method, more factors like individual tendency and confidence level are considered which brings out higher similarity accuracy. Moreover, user attribute information is involved to solve the cold start and data sparseness problem. Finally, the proposed mothed is verified on experiments using Movie Lens dataset.
INTRODUCTION
With the development of computer and network technology, our society has entered a prosperous information age. The internet has become a huge information space and more information is added to it at all times. The huge amount of information leads to an overload problem and makes people overwhelmed. In order to solve this problem, recommender system is invented. It can help finding out information that is needed in the ocean of information by tracking and analyzing the network behavior of a user.
Among all the recommendation algorithms, the collaborative filtering [1] is the most widely used method to recommend items for users [2]. It is based on the assumption that users with similar interests rate similarly on the same item and similar items receive close score from the same user. It makes recommendation according to similar users or items. The collaborative filtering includes memory ________________________
based method and model based method [3]. The memory based method calculates the similarity of different users and forms a similar neighbor set by the order of their similarity. Recommendations are made by using the ratings of the similar neighbors in a user’s neighbor set. The model based method builds up a model to describe the network behaviors of a user first and then predicts the ratings of this user according his behavior model. Compared with the model based method, the memory based method can achieve higher accuracy of recommendations. But as the number of users and items grows, the cost time of similarity calculation increases rapidly and it may fails to respond in real time. The model based method performs better in speed because most of the work is the off-line model-building work. Besides of collaborative filtering, there are other algorithms like content-based method technique[4], social recommendation[5] and semantic recommendation[6].
This paper focuses on the memory based method. The key of this method is the similarity calculation. Although the traditional recommendation algorithms have make some results, they are incapable of solving the problem of data sparseness [7] and the cold start problem is another challenge for traditional recommender system[8]. In this regard, a new method of similarity calculation and score prediction is put forward in this paper. This new method combines user attribute information and rating information which overcomes the shortcomings of the traditional algorithm. It is proved by experiments on Movie Lens dataset that this new algorithm can improve the quality of the recommender system and solve the cold start and data sparseness problem to some extent.
RELATED WORK
Existing similarity measures include the Pearson Correlation Coefficient (PCC) [9], the Constrained Pearson Correlation Coefficient (CPCC) [10], the cosine similarity (COS)[11], the adjusted cosine similarity (ACOS) [12] and the Jaccard similarity (Jaccard) [13]. They can be expressed as follow:
𝑠𝑖𝑚(𝑢, 𝑣)𝐶𝑃𝐶𝐶 = ∑𝑝∈𝐿(𝑟𝑢,𝑝−𝑟𝑚𝑖𝑑)(𝑟𝑣,𝑝−𝑟𝑚𝑖𝑑)
√∑ (𝑟𝑢,𝑝−𝑟𝑚𝑖𝑑) 2
𝑝∈𝐿 √∑ (𝑟𝑣,𝑝−𝑟𝑚𝑖𝑑) 2 𝑝∈𝐿
(1)
𝑠𝑖𝑚(𝑢, 𝑣)𝐶𝑂𝑆= ∑𝑝∈𝑀𝑟𝑢,𝑝·𝑟𝑣,𝑝
√∑𝑝∈𝑀𝑟𝑢,𝑝2√∑𝑝∈𝑀𝑟𝑣,𝑝2
(2)
𝑠𝑖𝑚(𝑢, 𝑣)𝐴𝐶𝑂𝑆 = ∑𝑝∈𝑀(𝑟𝑢,𝑝−𝑟̅̅̅)(𝑟𝑢 𝑣,𝑝−𝑟̅̅̅)𝑣
√∑𝑝∈𝑀(𝑟𝑢,𝑝−𝑟̅̅̅)𝑢 2√∑𝑝∈𝑀(𝑟𝑣,𝑝−𝑟̅̅̅)𝑣 2
(3)
𝑠𝑖𝑚(𝑢, 𝑣)𝐽𝑎𝑐𝑐𝑎𝑟𝑑 =|𝑁|𝑁 𝑢|∩|𝑁 𝑣|
𝑢|∪|𝑁 𝑣|
where 𝑟𝑢,𝑝represents the rating of user u to item p. 𝑟̅ 𝑢is the average rating of user u.
𝑟𝑚𝑖𝑑is the median of the rating range. 𝑁𝑢 is the set of items that have been rated by
user u. L is the common rating items of user u and user v.
Although we can use these methods to calculate the similarity of different users, there are problems of them that cannot be ignored:
(1) The above-mentioned methods are based on the assumption that all users have sufficient rating information and different users have enough common rating items. When the problem of sparseness happens, big deviation of similarity calculation will occur.
(2) Since there are no uniform standards, it is unavoidable that users will be influenced by their personal rating habit. Some may tend to give high scores while others may be stricter. This individual ranting tendency between different users will affect the accuracy of similarity calculation.
(3) Rating information is used as the only input to calculate user similarity which brings some limitations. There is much information to be discovered in the user attribute information. Therefore, more factors should be involved to describe the similarity of different users.
AN IMPROVED SIMILARITY MODEL
In order to overcome the shortcomings of traditional method of similarity calculation, optimization of rating similarity, individual tendency, confidence level and user attribute information will be taken in this section.
Assume that the rating score range is 1-5. When two users give close scores to the same item, it means they have close interest. If they give a same score, the similarity comes to the max value of 1. As the difference of their rating becomes bigger, the similarity between them gets smaller with a nonlinear tendency. Based on this idea, we can introduce an exponential function to describe the rating similarity of different users:
𝑠𝑖𝑚(𝑢, 𝑣, 𝑝) = 𝑎𝑒−𝑏|𝑟𝑢,𝑝−𝑟𝑣,𝑝| 𝑐
(5)
where 𝑟𝑢,𝑝and 𝑟𝑣,𝑝 represents respectively the rating of user u to p and the rating of v
to p. Parameters a, b and c determine the decay rate of the function. In this paper, we can let a=1, b=0.4, c=1.5.
𝐾𝑢 = {
1 1+𝑒−(
𝑟𝑢,𝑝−𝑟̅𝑢 𝑀−𝑟̅𝑢 ×𝑀)
, 𝑟𝑢,𝑝− 𝑟̅𝑢 ≥ 0
1 1+𝑒−(
𝑟 ̅𝑢−𝑟𝑢,𝑝
𝑟 ̅𝑢 ×𝑀)
, 𝑟𝑢,𝑝− 𝑟̅𝑢 < 0
(6)
K = max {𝐾𝑢, 𝐾𝑣} (7)
where 𝐾𝑢represents the rating tendency of user u. M is the max value of the rating
range. Here we have M=5.
Another factor that affects the similarity calculation is the number of common rating items. The Jaccard function can be used to describe the confidence level:
𝜎 =|𝐼𝑢∩𝐼𝑣|
|𝐼𝑢∪𝐼𝑣|
(8)
where |𝐼𝑢∩ 𝐼𝑣| is the number of common rating items of user u and v. |𝐼𝑢∪ 𝐼𝑣| is the number of items that user u or user v have rated.
Finally, the user rating similarity can be described as:
𝑠𝑖𝑚𝑠𝑐𝑜𝑟𝑒(𝑢, 𝑣) =|𝐿|𝜎 ∑𝑝∈𝐿𝑠𝑖𝑚(𝑢, 𝑣, 𝑝) ∙ 𝐾 (9)
where L represents the common rating items of user u and v.
In order to solve the cold start problem, we can involve user attribute information. When a new user comes, we will use its attribute information to do the similarity calculation and make recommendation base on this calculation. As the number of his rating item grows, we will lower the proportion of attribution information in similarity calculation and gradually switch to rating similarity. The user attribute is described as Attru = (a1, a2, … , an) where n represents the number of user attribute. If user u and v share the same attribute i, then simAttr(u, v, i) = 1, else simAttr(u, v, i) = 0. User attribute similarity can be described as:
𝑠𝑖𝑚𝐴𝑡𝑡𝑟(𝑢, 𝑣) = ∑𝑖∈𝐴𝑡𝑡𝑟𝑤𝑖· 𝑠𝑖𝑚𝐴𝑡𝑡𝑟(𝑢, 𝑣, 𝑖) (10)
where 𝑤𝑖represents the weight of attribute i. We can now combine rating similarity
and attribute similarity together:
sim(𝑢, 𝑣) = 𝛼 ∙ 𝑠𝑖𝑚𝐴𝑡𝑡𝑟(𝑢, 𝑣) + 𝛽 ∙ 𝑠𝑖𝑚𝑠𝑐𝑜𝑟𝑒(𝑢, 𝑣) (11)
𝛼 = 2 ×(1 − 1
1+𝑒−|𝐼𝑢|) (12)
where 𝛼 and 𝛽 respectively determine the weight of user attribute similarity and user rating similarity. When user u hasn’t rated any item, that is, |𝐼𝑢| = 0, 𝛼 reaches its
maximum value 1. As |𝐼𝑢| grows up, 𝛼 becomes bigger and 𝛽 gets smaller until 0.
Therefore, the smooth switch between user attribute similarity and user rating similarity is realized.
EXPERIMENTS
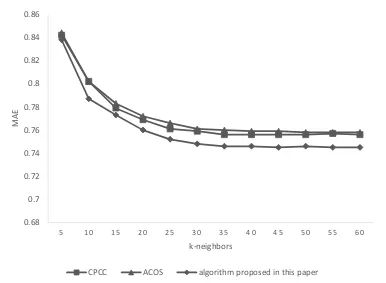
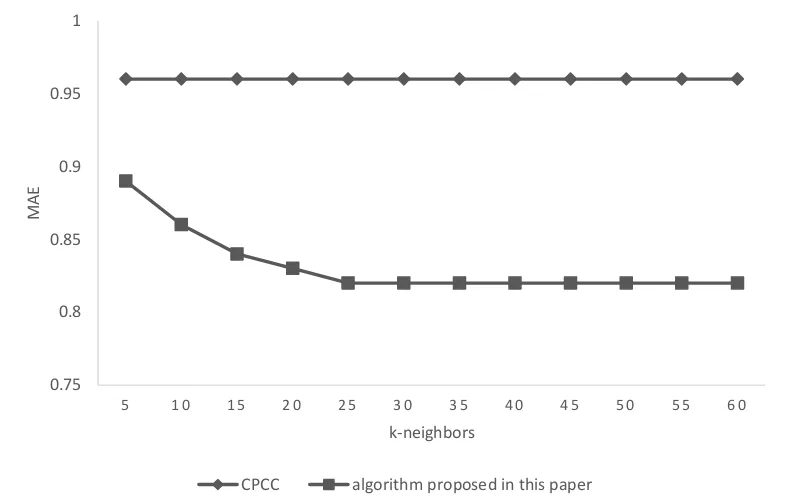
[image:5.612.106.492.326.609.2]The algorithm proposed in this paper is verified in experiments on MovieLens dataset which consists of 100005 ratings from 671 users to 9126 movies. User attribute information includes age, gender, occupation and postcode. These four attributes are used in experiments and the weights of them are set respectively as 0.4, 0.3, 0.2, 0.1 according to paper [14]. Mean absolute error (MAE) [15,16] is applied as the criterion of the quality of the recommender system. The results are shown in figure 1 and figure 2.
Figure 1. Comparison of three algorithms. 0.68
0.7 0.72 0.74 0.76 0.78 0.8 0.82 0.84 0.86
5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 4 5 5 0 5 5 6 0
MA
E
k-neighbors
The first experiment compared the recommendation performance of the CPCC, ACOS and the new method proposed in this paper with full ratings. The results in figure 1 are positive for the new method proposed in this paper. Over the range of number of neighbors from 5 to 60, this new method is showing the overall best performance with lowest mean absolute error. When the number of neighbor K is less than 30, the MAE of three method are all very high and showing a downward trend. When K is larger than 30, the MAE of three method becomes steady and shows the quality of the recommendation. The second experiment is conducted in cold start condition in order to test the cold start performance of the new algorithm. Figure 2 shows the comparison of cold start performance of the CPCC and the new method proposed in this paper. The latter method is clearly outperforming the former one with lower MAE. From these results, it can be concluded that the new algorithm proposed in this paper shows advantage over the traditional method in full ratings and is performing better in cold start condition.
Figure 2. Performance under cold start condition.
CONCLUSIONS
A new method of similarity calculation is proposed to improve the accuracy of recommender systems. Optimization is realized suing rating similarity, individual tendency and confidence level. Moreover, the combination of rating similarity and
0.75 0.8 0.85 0.9 0.95 1
5 1 0 1 5 2 0 2 5 3 0 3 5 4 0 4 5 5 0 5 5 6 0
MA
E
k-neighbors
information should be discovered in the user attribute to contribute to the user attribute similarity calculation and further research will be done.
ACKNOWLEDGMENTS
This project is supported by National Natural Science Foundation of China (61573154, 60904032) and Science & technology planning project of Guangdong Province (2015A010106003).
REFERENCES
1. Breese J S, Heckerman D, Kadie C. Empirical analysis of predictive algorithms for collaborative
filtering[C]// Fourteenth Conference on Uncertainty in Artificial Intelligence. Morgan Kaufmann Publishers Inc. 1998:43-52.
2. GB/T 7714 Dongting sun, Tao He, Fuhai Zhang. Survey of Cold-start Problem in Collaborative
Filtering Recommender System[J]. Computer and Modernization, 2012(5):59-63.
3. Cacheda F, Formoso V. Comparison of collaborative filtering algorithms: Limitations of current
techniques and proposals for scalable, high-performance recommender systems[J]. ACM Transactions on the Web, 2011, 5(1):1-33.
4. M.J. Pazzani, D. Billsus, Content-based recommendation systems, The Adaptive Web (2007)
325-341.
5. Huang J, Cheng X Q, Guo J, et al. Social Recommendation with Interpersonal Influence[C]//
Conference on ECAI 2010:, European Conference on Artificial Intelligence. IOS Press, 2010:601-606.
6. Xu Y, Shambour Q, Lin Q, et al. BizSeeker: A hybrid semantic recommendation system for
personalized government‐to‐business e‐services[J]. Internet Research, 2010, 20(3):342-365.
7. Bobadilla J, Ortega F, Hernando A, et al. A collaborative filtering approach to mitigate the new
user cold start problem[J]. Knowledge-Based Systems, 2012, 26:225-238.
8. Niemann K, Wolpers M. A new collaborative filtering approach for increasing the aggregate
diversity of recommender systems[C]// ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2013:955-963.
9. Choi K, Suh Y. A new similarity function for selecting neighbors for each target item in
collaborative filtering[J]. Knowledge-Based Systems, 2013, 37(1):146-153.
10.Koren Y, Bell R. Advances in Collaborative Filtering[J]. Recommender Systems Handbook,
2011:145-186.
11.Bobadilla J, Serradilla F, Hernando A. Collaborative filtering adapted to recommender systems of
e-learning[J]. Knowledge-Based Systems, 2009, 22(4):261-265.
12.Gao M. User rank for item-based collaborative filtering recommendation [J]. Information
Processing Letters, 2011, 111(9):440-446.
13.Koutrika G, Bercovitz B, Garcia-Molina H. FlexRecs: expressing and combining flexible
recommendations[C]// ACM SIGMOD International Conference on Management of Data. ACM, 2009:745-758.
14.Pengfei Li, Weimin Wu. Optimized Implementation of Hybrid Recommendation Algorithm[J].
Computer Science, 2014, 41(2):68-71.
15.Ahn H J. A new similarity measure for collaborative filtering to alleviate the new user
cold-starting problem[J]. Information Sciences, 2008, 178(1):37-51.