Dissertations and Theses
7-2020
Monocular Visual Inertial Odometry using Learning-based
Monocular Visual Inertial Odometry using Learning-based
Methods
Methods
Yuan TianFollow this and additional works at: https://commons.erau.edu/edt Part of the Mechanical Engineering Commons
Scholarly Commons Citation Scholarly Commons Citation
Tian, Yuan, "Monocular Visual Inertial Odometry using Learning-based Methods" (2020). Dissertations and Theses. 527.
https://commons.erau.edu/edt/527
This Dissertation - Open Access is brought to you for free and open access by Scholarly Commons. It has been accepted for inclusion in Dissertations and Theses by an authorized administrator of Scholarly Commons. For more information, please contact [email protected].
MONOCULAR VISUAL INERTIAL ODOMETRY USING LEARNING-BASED METHODS
by
Yuan Tian
A Dissertation Submitted to the College of Engineering Department of Mechanical Engineering in Partial Fulfillment of the Requirements for the Degree of
Doctor of Philosophy in Mechanical Engineering
Embry-Riddle Aeronautical University Daytona Beach, Florida
MONOCULAR VISUAL INERTIAL ODOMETRY USING LEARNING-BASED METHODS
by
Yuan Tian
This thesis was prepared under the direction of the candidate's Dissertation Committee Chair, Dr. Marc Compere, Associate Professor, Daytona Beach Campus, and Dissertation
Committee Members Dr. Eric Coyle, Associate Professor, Daytona Beach Campus, Dr. Patrick Currier, Associate Professor, Daytona Beach Campus, Dr. Jianhua Liu, Associate Professor, Daytona Beach Campus, and Dr. Hongyun Chen, Assistant Professor, Daytona Beach Campus, and has been approved by the Dissertation Committee. It was submitted
to the Department of Mechanical Engineering in partial fulfillment of the requirements for the degree of Master of Science in Mechanical Engineering
Dissertation Review Committee:
Marc Compere
DigitallysignedbyMarcCompere Date: 2020.07.09 17 :34:22 -04'00'Marc Compere, Ph.D. Committee Chair
Eric Coyle
Digitally signed by Eric CoyleDate: 2020.07.14 14:17 :18 -04'00'
Eric Coyle, Ph.D. Committee Member
� 7/14/2020
----C,/
J .ll,,U . .Ll..1.\..1.U. .J...J.lU' ..I. J.J..LJ •(�----vvt-Committee Member
E
r
I•
C
C
Oy
I
e
Digitally signed by Eric Coyle Date: 2020.07.1414:17 :31 -04'00' Eric Coyle, Ph.D. Ph.D. Program Coordinator, /\ J /Me�hanical �ngineeringl1P-•-"-""""Q,>,,,,
Maj Mirmirani, Ph.D.Dean, College of Engineering
I
, • Digitally signed by Patrick Currier
Patnck Gurner
Date: 2020.07.1412 :51 :32-04'00' Patrick CmTier, Ph.D.
Committee Member
Hongyun Chen
DlgilallysignedbyHongyunChen Date: 2020.07.14 15:59:58-04'00' Hongyun Chen, Ph.D. Committee Member Eduardo Divo, Ph.D. Department Chair, Mechanical Engineering�r
Senior Vice President for Academics Affairs and Provost
7 -
'::r-,...
"20 DateAcknowledgements
First, I would like to take this opportunity to thank my advisor, Dr. Marc Compere, for his valuable advice and selfless help for both my coursework, research and even in the preparation of my dissertation during my stay at Emery-Riddle Aeronautical University. I still remember that I sat in his office, saying I would determine the research topic next week. After four and a half years, I have grown and become more cautious and mature towards research. I benefit from his high standard not only for academic research, but also for normal life.
Moreover, I would also like to thank other dissertation committee members, Dr. Eric. Coyle, Dr. Patrick Currier, Dr. Jianhua Liu and Dr. Hongyun Chen, for their valuable time and comments. Also, I want to thank Dr. Divo, the Mechanical Engineering department chair. He has always been so nice as to give any help he can. Thanks are also given to our department office assistant, Mrs. J. Gibbs, for her help either related to the study or normal office life.
I would also like to extend my thanks to my friends, Dancheng Yang, Mengyuan Cheng, Xinyu Zhao and Y aoyao Huang for your company and encouragement whenever I needed you.
Last, but most importantly, my parents are worthy of the greatest thanks. They have given me the freedom and selfless love to make me strong and brave. From the bottom of my heart, I hope you can live in happy forever.
Researcher: Yuan Tian
Abstract
Title: Monocular Visual-Inertial Odometry using Learning-based Methods
Institution: Embry-Riddle Aeronautical University
Degree: Doctor of Philosophy in Mechanical Engineering
Year: 2020
Precise pose information 1s a fundamental prerequisite for numerous applications in robotics, Artificial Intelligent and mobile computing. Many well-developed algorithms
have been established using a single sensor or multiple sensors. Visual Inertial Odometry
(VIO) uses images and inertial measurements to estimate the motion and is considered a key technology for GPS-denied localization in the real world and also virtual reality and augmented reality.
This study develops three novel learning-based approaches to odometry estimation using a monocular camera and inertial measurement unit. The networks are well-trained on standard datasets, KITTI and EuROC, and a custom dataset using supervised, unsupervised and semi-supervised training methods. Compared to traditional methods, the deep-learning methods presented here do not require precise manual synchronization of the camera and IMU or explicit camera calibration.
To the best of our knowledge, the proposed supervised method is a novel end-to-end
trainable Visual-Inertial Odometry method with an IMU pre-integration module, that
simplifies the network architecture and reduces the computation cost. Meanwhile, the unsupervised Visual-Inertial Odometry method shows its novelty in achieving outstanding
accuracy in odometry estimation while training with monocular images and inertial
measurements only. Last but not least, the semi-supervised method is the first Visual Inertial Odometry approach that uses a semi-supervised training technique in the literature, allowing the network to learn from both labeled and unlabeled datasets.
Through our qualitative and quantitative experimentation on a wide range of datasets, we conclude that the proposed methods can be used to obtain accurate visual localization information to a wide variety of consumer devices and robotic platforms.
4.2.2 Depth Estimation
a. Methodology
As it is known to all, depth estimation from images is an important tool in a variety of applications, especially in robotics. One big problem for monocular visual-inertial odometry is the lack of one-dimension information, scale, that makes depth estimation an important part. For example, although VIOLearner[56] claims that it is an unsupervised VIO approach, it requires the ground-truth depth map for training. Although several dedicated ranging sensors, such as LIDAR and structured light sensors, provide superior depth detection compared, they are not suited for all applications, such as hand-held devices [36]. Moreover, LID AR units are usually high-cost, while structured light sensors suffer from poor detection range [36]. Cameras remain a cost-friendly and competitive sensor choice for small robotic platforms. Traditionally, stereo or multiple cameras are used, and depth is calculated as the inverse of image disparity.
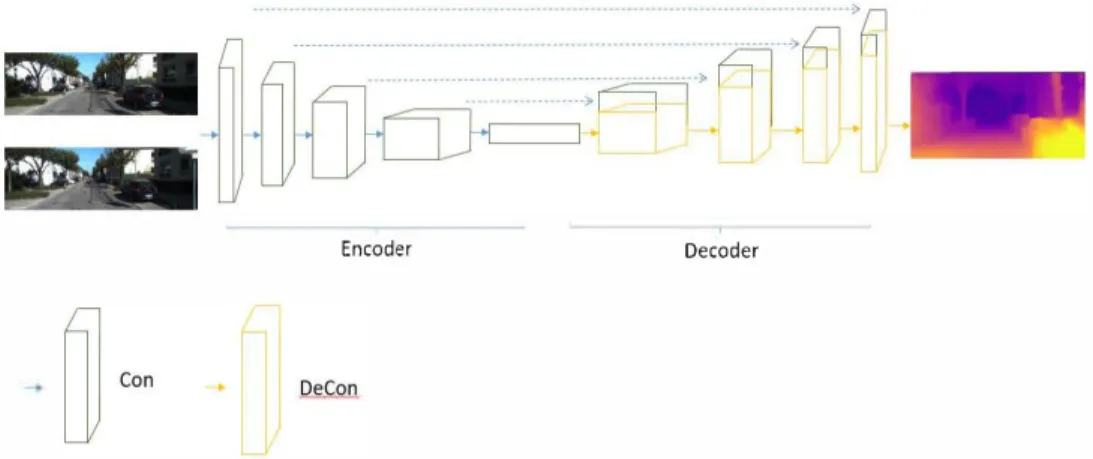
Encoder Decoder
Figure 4.2. Scheme of Depth Estimation Network
In this research, a DepthNet that is recreated from [73] is proposed to generate depth
information from consecutive monocular images, as shown in Figure 4.3. Depth estimation
The first interesting finding is that learning-based methods outperform traditional methods. The reasonable explanation is that traditional methods cannot handle the raw IMU data without synchronization. Moreover, proposed SemiVIO beats other VIO learningbased methods, VIOLearner and SfMLearner in translation. However, our results could not successfully beat Deep VIO on KITTI sequence 10 [32], which requires stereo cameras for training.
Secondly, among three methods, our supervisedVIO shows the best performances with the lowest average translational and rotational error on most of training datasets ( sequence
00-08), as shown in Figure 6.1. The possible reason for that is the training processes are
done on the same sequences. A conclusion can be drawn that within the same or highly similar environments, supervised method, training with ground truth, can provide the most accurate estimates. However, the test on sequence 09 and 10, semiVIO outperforms both supervised and unsupervised VIO. It is possible that the supervised method suffers from overfitting, that makes it perfect for training set but less accurate for testing. The improvement from semiVIO to unsupervisedVIO demonstrates that finetuning with ground truth is an effective way to boost the performance of the network.
One more thing that worth noting is that, on sequence 10, suprevisedVIO beats unsupervisedVIO while on sequence 09, the performance is opposite. With a deeper study of the KITTI dataset, we find that on sequence 10, there are several edge cases such as the forward vehicle moving backward and large moving objects. The unsupervised method partially relies on depth estimation and theses special cases degrade the performance of
Table 6.4. Absolute Trajectory Error (ATE) on KITTI odometry dataset. The results of other baselines are taken from[26],[56]
Method Sequence 09 Sequence IO
ORB-SLAM 0.014 ± 0.008 0.012 ± 0.01 I SfM-Learner 0.016 ± 0.009 0.013 ± 0.009 VIOLearner 0.012 0.012 Supervised VIO 0.01 I ± 0.005 0.010 ± 0.009 Unsupervised VIO 0.010 ± 0.006 0.01 I ± 0.007 Semi-supervised VIO 0.010 ± 0.003 0.009 ± 0.008
6.3 Results on EuROC dataset
Additionally, we successfully run three proposed methods on EuROC dataset [53]. KITTI dataset is famous for the outdoor environment and EuROC is famous for the indoor environment. The network configuration and training parameters and strategies are the same as Chapter 2-4. EuROC dataset is divided into a training set (80%) and a validation
set (20%).
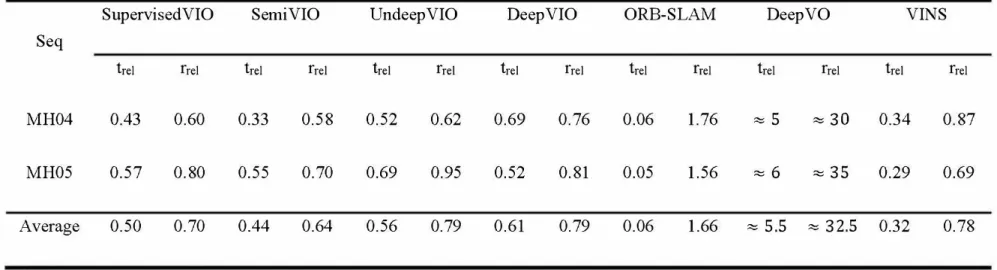
Table 6.5 reports the results on MH04 and MH05. Results of other methods are reproduced from [59]. It is obvious that all the VIO methods outperform Deep VO because of combining IMU data with a camera. Moreover, semiVIO outperforms all other methods in terms of rotational accuracy. However, compared with the results on KITTI dataset, learning-based methods' strengths are limited in terms of translational accuracy. Traditional methods, ORB-SLAM and VINS, outperforms not only proposed methods, but also other learning-based approaches on translational accuracy.
Table 6.5. Comparison of trajectories estimation performance with existing approaches on EuROC dataset.
SupervisedVIO SemiVIO UndeepVIO DeepVIO ORB-SLAM DeepVO VINS
Seq
1rel frel 1rel frel trel frel trel frel 1rel frel 1rel frel 1rel frel
MH04 0.43 0.60 0.33 0.58 0.52 0.62 0.69 0.76 0.06 1.76 :::::5 ::::: 30 0.34 0.87
MH05 0.57 0.80 0.55 0.70 0.69 0.95 0.52 0.81 0.05 1.56 ::::: 6 ::::: 35 0.29 0.69
Average 0.50 0.70 0.44 0.64 0.56 0.79 0.61 0.79 0.06 1.66 ::::: 5.5 ::::: 32.5 0.32 0.78
![Table 6.4. Absolute Trajectory Error (ATE) on KITTI odometry dataset. The results of other baselines are taken from[26],[56]](https://thumb-us.123doks.com/thumbv2/123dok_us/1290783.2673102/112.918.175.811.159.462/table-absolute-trajectory-error-odometry-dataset-results-baselines.webp)