Preserving Private Cloud Service Data Based on
Hypergraph Anonymization
Yuechuan Li, Yidong Li and Hong Shen
School of Computer and Information Technology, Beijing Jiaotong University, China {09283037, ydli, hshen}@bjtu.edu.cn
Abstract—Cloud computing is becoming increasingly popular due to its power in providing high-performance and flexible service capabilities. More and more internet users have accepted this innovative service model and been using various cloud-based services every day. However, these service-using data is quite valuable for marketing purposes, as it can reflect a user’s interest and service-using pattern. Therefore, the privacy issues have been brought out. Recently, many studies focus on access control and other traditional security problems in cloud, and little studied on the topic of the private service data publishing. In this paper, we study the private service data publishing problem by representing the data with a hypergraph, which is quite efficient to illustrate complex relationships among users. We first formulate the problem with a popular background knowledge attack model named rank attack , and then providean anonymization-based method to prevent the released data from such attacks. We also take data utility into consideration by defining specific information loss metrics. The performances of the methods have been validated by two sets of synthetic data.
I. INTRODUCTION
Services based on cloud computing has been widely pro-vided in IT industry recently. Unlike other innovative tech-nologies, cloud computing attracts not only service providers’ but traditional clients’ attentions with its capabilities of high-performance computation and flexible service model. By tak-ing Google as an example, there are 425 applications built
upon Google App Engine, including news, sports, travel, mu-sic, movies, business, entertainment, traffic, social, education, science, etc., which covers most aspects of our life. The use of these applications can sometimes reflect a user’s interest. For example, if you use 3D Hawaii, it is likely that you like traveling. If you use Discover Australia meanwhile, it adds the confidence of the assumption. However, such data is precious to product sellers, who will not hesitate to pay for the data. They can obtain valuable knowledge behind the data by using data analysis or data mining methods. Thus, the private data publishing, which has been well studied with transactional data, should be introduced for the scenario above.
Identity disclosure control is a critical problem in private data publishing. The idea behind is that an adversary can re-identify a user whose personal information is included in the released data by exploring the attributes. One of the most common attack is called background knowledge attack [1], [4], [8], which assumes the adversary has part of the target’s real information as prior knowledge. We use an example to show the reality of such an attack. Assume that Duke is conscious about his personal information, and provides fake
profiles in his Google account. However, he is in favor of traveling, and uses the cloud services of ’DC Circulator Map’ and ’DailyMotoRide’ with no hesitation. He is also interested in science, so it is likely that he uses the cloud applications of ’Code Hero’, ’Primer Labs’ and ’Parrot SA’. The combination of these interests is very personal. As the service data has high value for marketing, many companies like travel agencies are motivated to collect such information, which can help them to push customized advertisements to potential customers. The identifiers such as name or security number are usually removed before publishing. However, since different users have different interests and will choose applications according to their interests, there still exists high risk that the travel agency could recognize Duke from the published data. Then his other activities will be disclosed.
Many work has been done to prevent this kind of attack, but most focus on transactional data [1] or graphs [8]. However, the relation between users and applications is neither sufficient nor efficient to be presented as a simple graph, which can only illustrate pairwise relationships between objects. Therefore, we use hypergraph-based representation that allows to one edge to connect a set of nodes to model the grouping relations among objects. We use nodes and edges (hyperedges) to denote users and services respectively. Users using the same application will be connected by an edge. If an attacker has background information about users’ living habits, it is possible that some users are identified. Since more special characteristics are introduced in a hypergraph, it has been proved that the hypergraph-based model suffers from more background attacks in real-world cases [7].
In this paper, we discuss identity disclosure problem on hypergraph with a specific real-world case. We solve the problem by using the two-step framework proposed in [7]: rank anonymization and hypergraph reconstruction. We also provide quantitive metrics to measure data utility. While satisfying anonymity, we aims at minimizing information loss to maintain high data utility.
A. Our Contributions
• We discuss the identity disclosure problem on cloud
service data publishing with hypergraph-based represen-tation.We focus on protecting customer’s confident infor-mation from a popular and efficient background knowl-edge attack, named as rank attack.We show empirically how high the disclosure risk is with the attack to breach the real-world data.
• We provide an efficient algorithm to anonymize the rank
set of the data, which is based on the initial idea of rank anonymization. The method ensures the in-distinguish level of each tuple is at leastk.
• We propose a robust algorithm to guarantee the success of
constructing a hypergraph according to the anonymized rank set, while minimizing the effect on privacy.
• We show theoretically and empirically how the proposed
methods perform on both data privacy and utility. The remainder of this paper is organized as follows. Section II introduces related work about data privacy preservation and hypergraph anonymization. In Section III, we model the rank attack and provide a general metric for information loss. Section IV shows the detailed algorithms for rank anonymiza-tion and hypergraph construcanonymiza-tion. We perform extensive ex-periments, and present our results in Section V. Section VI concludes this paper.
II. RELATEDWORK
Cloud Computing has been envisioned as the next gener-ation architecture of IT Enterprise. It has the advantage of on-demand self-service, high elasticity and scalable, measured service. However, while we enjoy new features brought about by cloud computing, some new security and privacy issues come out. Since the cloud computing has the unique system ar-chitecture and service model, many traditional privacy preser-vation techniques cannot be applied to the cloud environment. Security and privacy issues are not sufficiently considered during the developing process of many cloud systems. This makes many enterprises hesitate to migrate their business into cloud, thus hindered the development of cloud computing.
Recently, as one of the most important aspects of security, data privacy preservation has attracted lots of attentions from both academia and industry. Cloud systems contain three elementary parties (i.e., Cloud service user, Cloud service provider/Cloud user, Cloud provider). Zhou et al. [15] point that released acts on privacy are out of date to protect users’ private information in the cloud environment since they are no longer applicable to the new relationship between users and providers. [12] point out that while outsourcing is the most charming feature of cloud computing, it brought about many privacy issues. Clients have little control over their data and computing process. Moreover, the cloud service provider is untrusted, even malicious. Another character of cloud is that it usually process big data, it has high demand on algorithm efficiency. Moreover, in cloud computing, data sets are updated frequently. It requires algorithms support dynamic data sets and incremental data sets. Related surveys on privacy preserving cloud computing can be found in [11], [13], [5], [2], [10], [15]. These papers introduce security and privacy issues in cloud computing, summarize existing solutions, and describe directions of future research work.
Identity disclosure is a serious problem in privacy preser-vation. Many works focus on ID issue on graph data. It is in [4] that the authors first pointed out that only removing the identifiers (or label) of the nodes does not always guarantee privacy. Various external information are studied. Two types
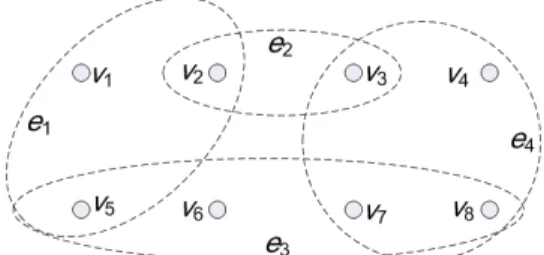
Figure 1. A hypergraph sample
Vertex Rank vector
v1 (3) v2 (3,2) v3 (4,2) v4 (4) v5 (4,3) v6 (4) v7 (4,4) v8 (4,4) Table I
RANK SET FOR THE SAMPLE HYPERGRAPH
of attack, namely neighborhood attack and degree attack, are modeled in [8] and [14]. Liu et al. [9] also take weights into consideration. The work in [1] describes subgraph attack, through which the attackers may learn whether edges exist or not between specific targeted pairs of nodes. To solve these privacy problem, anonymization method are widely used. The authors in [8] proposed a two-step framework (property anonymization and graph reconstruction), which is very useful to solve general anonymity problems on graphs. Recently, two general privacy preservation models, named k-automorphism anonymity [16] and k-isomorphism anonymity [3], are pro-posed to defend structural attacks in released networks.
Since hypergraph is more powerful in representing multi-relations among objects, data publishing based on hypergraph is becoming increasingly popular. Li et al. [7] first systemat-ically studied privacy issues in publishing hypergraph data. They formalize a rank-based attack model, and developed a two-step algorithm, namely rank anonymization and hy-pergraph reconstruction, to anonymize hyhy-pergraph data. In their work, they take community detection as data utility, and use two metrics to quantify information loss incurred in the perturbation. Their algorithms run in near-quadratic time on hypergraph size, and protect data from rank attacks with almost the same utility preserved.
Vertex Rank vector v1 (4) v2 (4,2) v3 (4,2) v4 (4) v5 (4,4) v6 (4,4) v7 (4,4) v8 (4,4) Table II
RANK SET FOR THE ANONYMIZED HYPERGRAPH
III. PROBLEM STATEMENT A. Notations and Assumptions
Hypergraph is similar to graph except that it allows more than two vertices in one edge. That is, an edge is a set of vertices. Figure 1 is a sample of hypergraph. We use V to
denote vertex set andEto denote edge set, a hypergraph with
vertex set V and edge set E can be denoted as H(V, E).
An edge eis incident with a vertex v if v 2e. The number
of vertices in edge e is called rank, i.e., r(e) =| e |. As in graph, the number of incident edges of a vertex v is called
degree, denoted by dv. A path fromv1 tovk is an alternative sequence of vertices and edgesv1, e1, v2, e2,· · · , vk such that for 1 i k 1, vi 2 ei and vi+1 2 ei. The length of this path is k 1. The distance between two vertices vi and
vj is the length of the shortest path from vi to vj. If there is no path between vi andvj, their distance is infinity, and they are called unreachable from each other. Hypergraph H
is connected if there is a path between every pair of vertices. Rank is a basic attribute of edges in hypergraph. An edge can attach additional attributes, including weight and other descriptive information. Of course, publishing this additional attributes of edges may leads to more privacy leakage. Here in this paper, we neglect these additional attribute and assume that they are not published. We further assume that identifiers of vertices and edges are removed before publishing. This is a basic sanitation for data publishing.
B. Hypergraph-based Model for the Problem
First, we define rank vector for a vertex v is the
de-creasing rank sequence of its incident edges, i.e., Rv =
(r1, r2,· · · , rdv) where r1 r2 · · · rdv. Note that
we sort rank vector in descending order to eliminate the influence of rank order. Also, it is convenient to compare two rank vectors. For example, (3,4,3) is the same as (3,3,4). After sort, they are both (4,3,3). Table 1 is the rank set for hypergraph in Figure 1. The rank set of hypergraphHis the set of rank vector of all vertices, i.e., RH ={R1, R2,· · · , Rn}, wherenis the number of vertices in hypergraph H. Usually,
the dimensions of rank vector for each vertex are not all the same. Since vectors with different dimensions are not comparable, we need to unify the dimensions. Naturally, we choose the maximum degree as the common dimension, and add zero elements to short vectors. The added zero rank can be explained as virtual edge containing no vertex.
Based on the above definition, given a hypergraph H, we can educe its rank set RH. If there exists unique rank vector
Ri, we can identify vi fromH. This kink of attack is called rank attack. For the hypergraph in Figure 1, v1, v2, v3 and
v5 are unique. These vertices can be identified from the hypergraph. In real problems, the rank vector can be pretty diverse, thus entities have high risk of disclosure.
To prevent rank attack, we need to avoid unique rank vector. In general, this kind of technique is anonymization. To conduct a measurable anonymity, we introduce the term of k-rank anonymity. A hypergraphH is k-rank anonymous if for every
rank vector appeared in rank set RH, there exist at least k vertices with the corresponding rank vector.
We need to modify the original hypergraph to make it satisfy k-rank anonymity. This is achieved by adding or removing vertices from edges. We may also add or remove edges. In our example, by adding v6 to e1, we can achieve 2-rank anonymity (as shown in Table 2). Since the anonymization process will inevitably reduce the utility of the hypergraph, what we need to do is minimize the utility loss during the process of anonymization.
Generally, there are two approaches to the problem. The first is to modify the original hypergraph, with the object of k-rank anonymity. However, this approach is not practical because of the complex relation between hypergraph and rank set. We need to decide how to modify the hypergraph according to rank set, and such modifications in turn influence rank set. The second approach is to anonymize the rank set first. Then, a new hypergraph is constructed with the same vertex set and anonymized rank set. This approach avoid interactive influence between hypergraph and rank set. The key of this method is to maintain data utility during perturbation. In this paper, we adopt the second approach.
C. Data utility and related metrics
Our task is to anonymize data before publishing, while min-imizing the influence on data utility. Thus measurable infor-mation loss metrics are critical in the design of anonymization algorithm. Since our publication is not application-oriented (i.e., we don’t know how the published data is utilized), it is not practical to formulate a common metric of information loss. Preserving data utility can be implemented by minimizing modifications on original hypergraph. Since our anonymiza-tion is a two-step process, we need different metrics in these steps.
In anonymization progress, our processing object is rank set. It is natural that we need to make fewer modifications to rank set. For simplicity, we use Euclidean distance between original rank vector and perturbed rank vector. LetLA denote information loss in anonymization step, we have
LA= n X i=1 kRi R 0 ik2 where Ri and R 0
i denote the original and modified rank vector andnis number of vertices.
In the hypergraph construction step, we need to reconstruct hypergraph using perturbed rank set. However, not all rank
set can be used to construct hypergraph. In other words, for some rank set, we cannot construct a hypergraph to satisfy the rank set. Thus, to construct hypergraph, we have to do some necessary modification on rank set to make it constructible. We need to minimize this modification while preserving anonymity. Again, for simplicity, we use rank bias as information loss in this step. Let LC denote information loss in hypergraph construction step, we have
LC= n X i=1 m X j=1 kRij R 0 ij k whereRij andR 0
ij denote the original and modified rank.
n is number of vertices andmis maximum degree.
IV. ALGORITHMS
In this section, we discuss anonymization algorithm in detail. Based on algorithm proposed in [7], we made several refinement to the two-step algorithm.
A. Rank anonymization
As stated in [7], the rank anonymization problem is an optimization problem which has been proved NP-hard. To solve this problem in rational time, approximate algorithms are required. Intuitively, this problem can be described as dividing the vertex set into several groups whichcontain at least
k vertices, and unifying the rank vector within each group, while minimizes the information loss. In general, there are two strategies to develop algorithms for this problem: one is top-down partitioning and the other is bottom-up grouping. The top-down approach is not applicable since it is hard to constraint group sizes. The basic idea of the bottom-up grouping approach is to first regard vertices as single groups, and then iteratively merge groups to satisfy the constraint of the group size. We extend and refine the algorithm proposed in [7] as shown in Algorithm 1. First we formngroups, each
containing a single vertex. Then we find two vertices with the most distance, and merge them with the other k 1 closest
groups respectively. This is preprocess and can be removed. By first processing the most far away vertices, we can reduce the anonymization loss to some extents. The next step is iteratively merge two groups to satisfy k-rank anonymity. In each iteration, we calculate pairwise merging cost and sort the result in ascending order. To improve efficiency, we perform more than one merge operation in each iteration. The number of operations is a tunable fraction of the group number. This method reduces the number of iterations from O(n)
to O(logn). Note that some merge may not be successful,
as two groups may have been already merged in previous iterations. Finally, we calculate the anonymous rank vector for each group and reconstruct the rank set. Most operations of this algorithm are aggregated in merge iteration process. We have O(logn) iterations, O(n2) merge loss to compute, andO(m)basic operations to compute one merge loss. Thus
the complexity of this algorithm isO(n2mlogn).
Algorithm 1 The Algorithm for Rank Anonymization 1:Rankset Anonymize(HypergraphH, Integer k) 2: calculate rank setR from hypergraphH; 3: create n groupsG, each containing one vertex;
4: calculate distance matrixD among groups;
5: find vertexvs andvt such thatD[s][t] is the largest; 6: mergeGsandGtwithk 1closest vertices respectively; 7: while (there exist groups with size smaller than k)
8: calculate merge loss matrix M;
9: mergem pairs of groups with firstmleast merge
10: loss according toM;
11: calculate anonymous rank vector for each group; 12: construct anonymous rank set Ra;
13 returnRa.
B. Hypergraph reconstruction
So far, we have the rank set anonymized. The next step is to construct a new hypergraph with the perturbed rank set. Compared to graph construction according to properties such as degree [8] and weight bag [6], hypergraph construction is relatively challenging due to the nature of hypergraph and anonymity constraints. Clearly, the vertex set is the same as original hypergraph. What we need to do is to add edges to the hypergraph. A critical problem is that not all rank set can be used to construct a hypergraph. If there exists at least one hypergraph that has the same rank set withR, thenR is realizable. For example, the rank set in Table II is realizable, whereas the rank set in Table III are unrealizable.
For the anonymized rank set, it is possible that it is not realizable. Dealing with this case is a big challenge. Note that the original rank set is realizable. It is the perturbation process that make it unrealizable. If we guarantee that after each step of modification on rank set, it is realizable, then the result rank set is realizable. However, one modification on hypergraph may bring about more than one changes on rank set(See the anonymization example), it is not practical to trace every modification on rank set.
For an element Rsi in rank set R, it means that vertex
vs is attached to an edge containing Rsi vertices. Our basic operation in constructing hypergraph is to find all vertices containing rank value Rsi, and create several edges, each containingRsivertices. The trouble is that such vertices will not be used up to form edges when the number of such vertices (denoted byM) cannot be exactly divided byRsi.In this case, we have to enforce some modifications. Our object is let Rsi be a divisor ofM. Apparently there are two approach. The first approach is changing M. However, to maintain anonymity, we must modify rank set by group. Under this constraint, one modification will be followed with a series of modification. Even if we can find a solution in the end, its complexity is too high. For example, the rank 5 in Table III, it cannot be
modified to be realizable, unless we change the value itself. In our algorithm, we adopt the second approach, in which we change Rsito a closest divisor of M(denoted by R
0
si). This approach avoids the influence on other elements. Note that there may be multiple ranks in one rank vector. If so, in each
Vertex Rank vector v1 (5,3) v2 (5,3) v3 (5,3) v4 (5,2) v5 (5,2) v6 (5,2) Table III
EXAMPLE OF UNREALIZABLE RANK SET
Algorithm 2 The Algorithm for Hypergraph Reconstruction 1:Hypergraph Reconstruct(Rank setR)
2: for each non-zero rank value Rij inR
3: find a vertex setS, where there exists a rank value equal
4: toRij;
5: find an integerd, where |S|modd=0and|Rij d|is 6: minimal;
7: create |S|
d edges, each containingdvertices;
8: for eachv2S, set one occurrence of value Rij to0; 9: compute approximation error;
10: return H.
iteration, we only process one of these ranks. In this way, we can preserve anonymity.
In Algorithm 2, we iteratively process each element in the perturbed rank set, which has a complexity ofO(nm), where
nis the number of vertices andmis the maximum degree. In each iteration, we iteratively find the equal ranks, which has a complexity ofO(nm). Thus the total complexity of Algorithm
2 isO(n2m2).
V. EXPERIMENTS
We implements the algorithms proposed in this paper, and conducted a series of experiments to verify the efficiency of our algorithm. All the experiments are conducted on a computer with 3.30 GHz Intel Core i3-2120 CPU and 4GB memory running Microsoft Windows 7 operating system. The algorithm is implemented with Java, and run on JRE 1.7. A. Data sets and disclosure risk
We use two sets of synthetic data. The data is generated randomly, with 1000 vertices and 25 edges. The ranks obey
uniform distribution and normal distribution respectively. We evaluate the disclosure risk for the synthetic data. It is shown in our experiments that in this setup, there are about750vertices
has unique rank vector, which means 75%of vertices can be
identified uniquely with rank attack. B. Results on anonymization cost
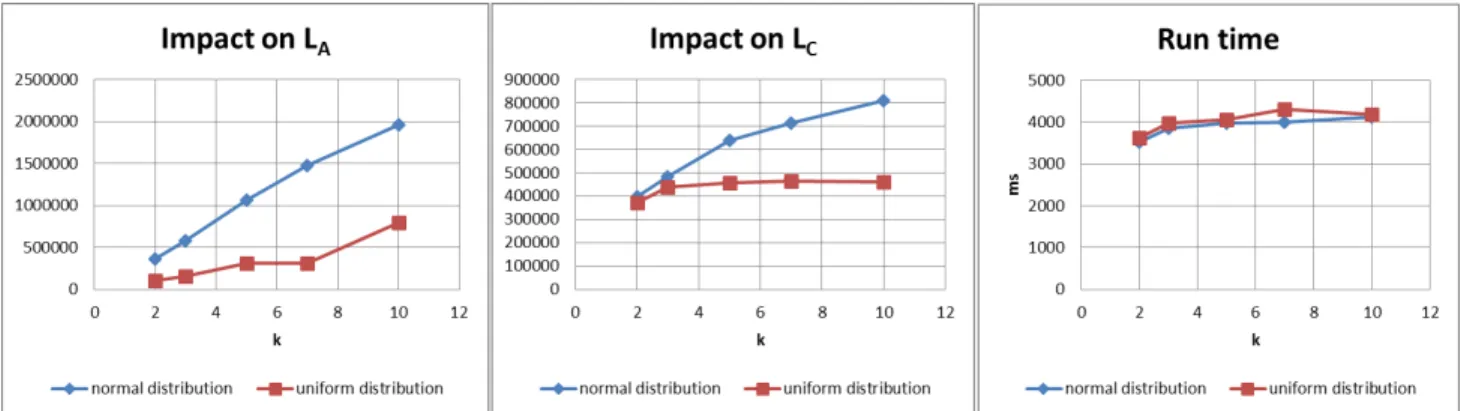
We evaluate the cost in each step of anonymization, namely,
LAandLC, with various in-distinguishing levelk. Usually,k is not supposed to be very large. k = 10 is enough in most
cases. Thus our evaluation range for k is 2 to 10. Figure 3
gives the impact on LAandLC, and the running time for the two-step anonymization process. From the chart we can see
that with the increase ofk, the information loss grows steadily as expected. The result for uniform distribution is better than normal distribution. As for run time, its increase is slight with the increasing of k. It is shown that our algorithm is quite efficient.
C. Results on utility
To evaluate the impact on data utility, we choose some hypergraph properties as metrics. Specifically, we evaluated hypergraph diameter and average distance for original graph and reconstructed graph respectively. The diameter for a hyper-graph is the largest distance of any pair of vertices. Here, we excluded the unreachable pairs in case that the hypergraph is not connected. The result is shown in Figure 4. Note thatk= 1
corresponds to the original hypergraph. With the increase ofk,
the diameter and average distance varies slightly and steadily. The average distance distance increases because in hypergraph reconstruction stage, reducing on rank is more than increasing, leading to fewer edges.
VI. CONCLUSION AND FUTURE WORK
In this paper, we studied a specific kind of background knowledge attack on hypergraphs in cloud environment. We have shown the high risk of identity disclosure when publish-ing cloud service data and formulated rank attack model. Then we developed a two-step schema to anonymize hypergraph data with the impact on data utility as little as possible. Finally, we conducted a series of experiments to evaluate our algorithm.
As a new studies field, there are many issues to be ad-dressed in future work. First, the anonymization method is a trade off among privacy, utility and efficiency. In order to preserve utility, our concept in this work is to minimize modifications on a rank set. To some extents, preserving rank set means preserving hypergraph itself. But they are not equal. To show the anonymization impact on data itself, we also evaluated some hypergraph properties such as diameter and average distance. How to preserve hypergraph properties during anonymization process is a challenging issue. For example, there are cases in which original hypergraph is connected, but reconstructed hypergraph is not. Amending connectivity might break anonymity very likely, or bring about huge cost. Second, in our experiments, we use a random hypergraph with 1000 vertices and 25 edges, and it has about 75% vertices that has unique rank vector. With the increase of edges or rank, the number of unique vertices increases rapidly. For example, if we generate 30 edges, about 90% vertices have unique rank vector. Such cases are inevitable sometimes. Anonymizing such hypergraph may lead to huge information loss. Third, we neglected edge weight in this work. Actually, there can be many critical properties attached with edges, which are valuable in data analysis, and are highly expected to be published. In this case, the identity disclosure problem is much more serious.
Figure 3. Results on anonymization cost
Figure 4. Results on utility
Acknowledgment
This work is supported by National Science Foundation of China under its General Projects funding #61170232,
Fundamental Research Funds for the Central Universi-ties #2012JBZ017 and #2012JBM035, State Key Labo-ratory of Rail Traffic Control and Safety Research Grant
#RCS2011ZT009 and RS2012K011. The corresponding au-thor is Yidong Li.
REFERENCES
[1] Lars Backstrom, Cynthia Dwork, and Jon Kleinberg. Wherefore art thou r3579x?: anonymized social networks, hidden patterns, and structural steganography. InProceedings of the 16th international conference on World Wide Web, pages 181–190. ACM, 2007.
[2] Deyan Chen and Hong Zhao. Data security and privacy protection issues in cloud computing. InComputer Science and Electronics Engineering (ICCSEE), 2012 International Conference on, volume 1, pages 647–651. IEEE, 2012.
[3] James Cheng, Ada Wai-chee Fu, and Jia Liu. K-isomorphism: privacy preserving network publication against structural attacks. InProceedings of the 2010 ACM SIGMOD International Conference on Management of data, pages 459–470. ACM, 2010.
[4] Michael Hay, Gerome Miklau, David Jensen, Philipp Weis, and Sid-dharth Srivastava. Anonymizing social networks. Computer Science Department Faculty Publication Series, page 180, 2007.
[5] S-U Lar, Xiaofeng Liao, and Syed Ali Abbas. Cloud computing privacy & security global issues, challenges, & mechanisms. InCommunications and Networking in China (CHINACOM), 2011 6th International ICST Conference on, pages 1240–1245. IEEE, 2011.
[6] Yidong Li and Hong Shen. Anonymizing graphs against weight-based attacks. InData Mining Workshops (ICDMW), 2010 IEEE International Conference on, pages 491–498. IEEE, 2010.
[7] Yidong Li and Hong Shen. On identity disclosure control for hypergraph-based data publishing.IEEE TRANSACTIONS ON INFOR-MATION FORENSICS AND SECURITY, 8(8):1384–1396, 2013.
[8] Kun Liu and Evimaria Terzi. Towards identity anonymization on graphs. InProceedings of the 2008 ACM SIGMOD international conference on Management of data, pages 93–106. ACM, 2008.
[9] Lian Liu, Jie Wang, Jinze Liu, and Jun Zhang. Privacy preservation in social networks with sensitive edge weights. InSDM, pages 954–965, 2009.
[10] Hassan Takabi, James BD Joshi, and Gail-Joon Ahn. Security and privacy challenges in cloud computing environments. Security & Privacy, IEEE, 8(6):24–31, 2010.
[11] Jian Wang, Yan Zhao, Shuo Jiang, and Jiajin Le. Providing privacy preserving in cloud computing. In Test and Measurement, 2009. ICTM’09. International Conference on, volume 2, pages 213–216. IEEE, 2009.
[12] Ziyuan Wang. Security and privacy issues within the cloud computing. InComputational and Information Sciences (ICCIS), 2011 International Conference on, pages 175–178. IEEE, 2011.
[13] Zhifeng Xiao and Yang Xiao. Security and privacy in cloud computing.
Communications Surveys Tutorials, IEEE, 15(2):843–859, 2013. [14] Bin Zhou and Jian Pei. Preserving privacy in social networks against
neighborhood attacks. InData Engineering, 2008. ICDE 2008. IEEE 24th International Conference on, pages 506–515. IEEE, 2008. [15] Minqi Zhou, Rong Zhang, Wei Xie, Weining Qian, and Aoying Zhou.
Security and privacy in cloud computing: A survey. In Semantics Knowledge and Grid (SKG), 2010 Sixth International Conference on, pages 105–112. IEEE, 2010.
[16] Lei Zou, Lei Chen, and M Tamer Özsu. K-automorphism: A general framework for privacy preserving network publication. Proceedings of the VLDB Endowment, 2(1):946–957, 2009.