An Approach to support Web Service Classification and Annotation
Marcello Bruno, Gerardo Canfora, Massimiliano Di Penta, and Rita Scognamiglio
[email protected], [email protected], [email protected], [email protected]
RCOST - Research Centre on Software Technology
University of Sannio, Department of Engineering
Palazzo ex Poste, Via Traiano 82100 Benevento, Italy
Abstract
The need for supporting the classification and semantic annotation of services constitutes an important challenge for service–centric software engineering. Late–binding and, in general, service matching approaches, require ser-vices to be semantically annotated. Such a semantic anno-tation may require, in turn, to be made in agreement to a specific ontology. Also, a service description needs to prop-erly relate with other similar services.
This paper proposes an approach to i) automatically classify services to specific domains and ii) identify key con-cepts inside service textual documentation, and build a lat-tice of relationships between service annotations. Support Vector Machines and Formal Concept Analysis have been used to perform the two tasks. Results obtained classifying a set of web services show that the approach can provide useful insights in both service publication and service re-trieval phases.
Keywords: Ontology Building, Service Classification,
Semantic Annotation
1
Introduction
One of the most relevant advantages of service–centric software engineering is the possibility a developer has to build his/her own system as a composition of one or more abstract services, i.e., semantic descriptions that can be matched at run–time with the description of one or more concrete services. The subsumption relationship between an abstract service and the concrete services is completed by means of matching algorithms integrated in the service broker [18]. The choice of the actual concrete service to bind to an abstract service can also consider concrete ser-vices’ Quality of Service (QoS) attributes.
The above described scenario requires that each service must have a semantic description, according to a specific
ontology1. Service semantic annotation is, however, a
dif-ficult task that, given the actual state–of–the–art, is often too expensive to be done in practice. Also the building and maintenance of ontologies requires expertise and budgets not always available. Unfortunately, very often the only source of information available is a pure–textual descrip-tion of the service, sometimes extracted from source code comments.
During service publication, it would be therefore useful to exploit this form of textual information to:
• permit the automatic classification of services to be published according to the broker’s service ontologi-cal classification;
• support building and maintenance of domain–specific ontologies;
• aid the semantic annotation of a service with respect to the ontology. By detecting concepts inside the service textual documentation, it would be possible to see how the service concepts can be identified in the ontology, and how the service can be cataloged with respect to other existing services.
The usefulness of a semi–automatic support for service classification and annotation is not limited to service publi-cation phase. In fact, it can also be used during service re-trieval. Let us suppose that a service integrator is querying (sending a free–text query) the broker to search for a service performing a particular task. Such an automatic classifica-tion mechanism can be applied to free-text queries to:
• identify the category (or the scored list of categories) in which any service matching the query can be found;
1There is work investigating the possibility of matching between
ser-vices described with different ontologies. This aspect, however, is out of scope for this paper and will not be further considered.
• ease the browsing among the available services, once the service integrator chooses a category. As it will be clearer later, the relationships between different ser-vices belonging to a specific domain can be repre-sented, with some simplifications, using a concept lat-tice. Thus, it would be useful to develop a mechanism able to identify the lattice region in which the service the integrator is searching for could be found.
This paper proposes an approach that, starting from ser-vice textual description, performs an automatic classifica-tion (to catalog services across specific domains, such as telecommunications, finance, etc.), and then identifies ser-vice key concepts and their relationships as a concept lat-tice. The approach relies on Support Vector Machines (SVM) [22] and Information Retrieval (IR) Vector Spaces [10] for service classification, and uses Formal Concept Analysis (FCA) [23] to build concept lattices from service descriptions. The results showed that, even if a totally au-tomatic construction of the lattice is not feasible, FCA still gives aids and useful insights to help the publisher annotat-ing the service and, when necessary, maintainannotat-ing the ontol-ogy.
The remainder of the paper is organized as follows. First, Section 2 provides an overview of the related literature and available tools. Then, Section 3 describes the proposed ap-proach and its application scenarios. The first results ob-tained are presented and discussed in Section 4. Finally, Section 5 concludes.
2
Related Work
Text classification has seen a great deal of success with the application of several studies addressed towards ma-chine learning [12, 15, 19, 24]. Among the many learn-ing algorithms, SVM [22] appears to be most promislearn-ing. The first application of text classification using SVM has been presented by Joachims [12]. The results were also confirmed by different other studies [12, 24]. Joachims et al. [13] developed a theoretical learning model of text classification for SVMs, which provides some explanation about SVMs performance in text classification. Di Lucca et al. [8] compared the effectiveness of different IR and ma-chine learning approaches for classifying software mainte-nance requests. As a result, SVM outperformed other ap-proaches.
The manual construction and maintenance of specific– domain ontologies is an expensive and complex work, re-quiring significant waste of effort and time, as well as a de-tailed knowledge of the domain to be modeled. Fridman Noy at al. [17] describe the knowledge model of Protege 2000 [3], an ontology–editing and knowledge-acquisition environment. Tao [21] developed a Protege 2000 FCA–
based plug–in for the building and maintenance of ontolo-gies.
Up to now, some work has been done in the field of au-tomatic support for ontology building. An example of using FCA in ontology merging has been proposed by Maedche et al. [16]. However, few papers investigated the possibility of using FCA in ontology building and structuring. Cimiano et al. [7] discuss how FCA can be used to support ontology engineering and how ontologies can be exploited in FCA applications. They present the method “FCA-Merge” for merging ontologies following a bottom–up approach. Hele-Mai Haav [11] presented an approach, based on Natural Language Processing (NLP), for the automatic or semiau-tomatic discovery of domain-specific ontologies from free text. Kim and Compton [14] propose an ontology browsing mechanism relying on FCA and incremental knowledge ac-quisition mechanisms. JBraindead Information Retrieval System [9] combines a free–text search engine that uses FCA to organize the results of a query. This work showed that conceptual lattices can be very useful to group relevant information in a free–text search task.
3
Approach Description
As stated in the introduction, the proposed free–text ser-vice classification approach aims at accomplishing a two-fold task: i) perform the automatic classification of a service description, i.e., determine to which category/domain a ser-vice belongs to; ii) locate a serser-vice description in a concept lattice.
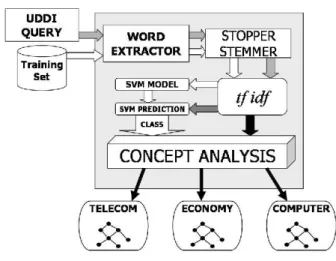
The remainder of this section will explain in details the three steps of the classification approach, depicted in Fig-ure 1.
3.1
Text Preprocessing
The first step aims to preprocess service textual descrip-tions. Textual description of web services might be in the form of Web Service Description Language (WSDL) docu-ments, coming from UDDI registries, as well as any other textual document provided as a documentation support for the service itself. Words are extracted from documents and then preprocessed. Successively, words are filtered by means of a stop–list, and normalized. The stop–list contains articles, prepositions, and in general words that are frequent in each query, and therefore not discriminant (”web”, ”ser-vice” or ”SOAP”). During the stemming phase, verbs are brought back to infinitive, plurals to singulars, etc. using the Wordnet dictionary [5] and its Java API.
3.2
Service Classification
The classification of services into domain–specific classes is performed using the SVM method. In our imple-mentation, the freely available LIBSVM tool [1] was used.
As stated in the introduction, automatic service classifi-cation both serves during service publiclassifi-cation (to classify the new service) and service retrieval (to identify the class(es) where to restrict the focus of the query). In this section’s context, both web service documentation and user queries are considered as a textual description to be classified (rep-resented as grey arrows in Figure 1).
Prior to apply SVM, sequences of words, obtained in the previous preprocessing phase, must be mapped onto vec-tors. In our approach, the mapping is achieved using IR techniques. Each element of the vector corresponds to a word (or term) in a vocabulary extracted from the docu-ments themselves. All words are weighted with tf-idf met-ric. In this way, each document is mapped onto a vector using an injective function. The whole document set is en-coded in a matrix, where rows represent documents (vec-tors) and columns are the weighted words. No information about the position or the meaning of the words is used, i.e., no semantic is known using this matrix.
A classification task using supervised algorithm such as SVM or ANN requires a training set. In other word, our SVM needs to be trained with a pre–classified set of docu-ments. This produces a ”model matrix” that will be used to “predict” to which class the document to be classified be-longs to.
3.3
Building the Concept Lattice
Once classified the service, or re–directed the query to a specific domain, key concepts need to be extracted from the service/query2 and their lattice needs to be built. Clearly,
2From this point we will refer both as “service” indistinctly.
such a lattice only represents a simplification of a domain ontology. FCA advantage comes from the way it shows how the presence or absence of attribute distinguishes ob-jects, i.e., by means of super–concept/sub–concept relation-ships. A concepts lattice can well represent services names and keywords belonging to a specific domain, highlighting “isA” relationships between concepts and attributes.
Without loss of generality, let us suppose we want to build a concept lattice from a set of service descriptions. First and foremost, we need to identify discriminant words, useful for the lattice. To this aim, we use the idf metric to eliminate words that do not appear in at least two or more, depending on the number of documents/services belonging to that domain/class. More formally:
A service context is a triple C=(S, K, I) where S is a set of service names (the objects), K is the set of service descrip-tion keywords (the attributes), and I the binary reladescrip-tionship which indicates the presence or absence of words into doc-uments.
The obtained lattice3 may be used to identify concepts for a specific domain, as well as the relationships between services belonging to a class. Such a lattice aids a service publisher when providing service semantic annotation, in that it tries, starting just a textual description, to discover the service “hidden semantic”.
4
Empirical Study
To validate and gain insights about the usefulness of the proposed approach, we performed an experiment aim-ing to classify a set of web service documentations, and to build lattices for services belonging to some particular classes/domains. Results are presented and discussed in this section.
4.1
Case Study Description
Getting a suitable and extensive case study for experi-ments dealing with web services is still a challenge. Al-though, at the time of writing, several UDDI registries exist and are available for querying, too often the set of services obtained is almost useless. Even the service are trivial, or their documentation is dummy.
We used, as a case study, a set of pre–classified ser-vices available on the net [4] and downloaded from some UDDI registries. Such a set was composed of 205 ser-vices, classified in 11 classes, representing domains such as news, weather, credit card, etc. As said, each service is provided with a short description, extracted from the WSDL
<documentation>tag. For example, a Credit Card Web Service presents a description as follows:
3A thorough example is available online at
”Will accept and validate a Credit Card Number. Re-turns True for a Valid Number and ReRe-turns False for a In-valid Number”
4.2
Service Classification Results
SVM service classification performances were measured using the leave–one–out validation [20]: each document (vector) in the set (matrix) was classified using a SVM model built using the remaining ones, and the percentage of correct classifications was measured. We found that differ-ent performances can be achieved by properly calibrating the SVM parameters, namely the kernel function and the gamma parameter.
Other than the first classification obtained for each ser-vice, we let the SVM find alternative classification, for which we also measured the correct classification ratio, in-crementally with respect to the first classification ratio. This permits to obtain, for each service, an ordered list of classes, to which the service has the highest likelihood to belong, according to our classification algorithm. In other words, the algorithm ensures that the service belongs, with a given likelihood, to the first class, with an higher likelihood to one of the two first classes, etc.
For our case study, precision for the first score position is of about 63%. This is not that high (up to 84% was obtained for software maintenance ticket classification by Di Lucca et al. [8]), however reasonable, considering the quality and quantity of the training set, and that the approach was able to classify across 11 classes. When looking further, to best– two and best–three class scores, we found that, clearly, per-formance increases, respectively to 73% and 83%. In con-clusion, although the approach could not always suggest the correct class, at least is able to indicate a limited group of classes to which the service could belong.
4.3
Building Service Concept Lattice
After classification was performed and thus services be-longing to each category identified, we built concept lattices for each category using FCA. As described in Section 3, words having high idf were pruned, in that they are consid-ered not relevant for building the concept lattice.
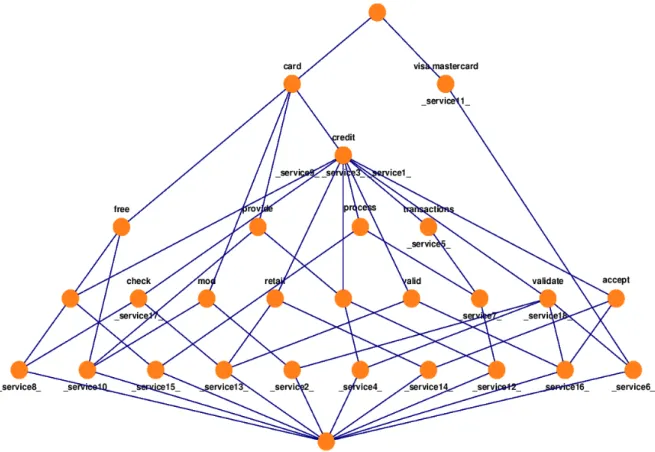
Figure 2 shows a lattice obtained applying FCA to doc-uments belonging to the “Credit Card” class. Each node in the lattice can show both concepts and objects. Concepts appear in the high part of the node, while objects in the low. In our case, concepts represent sets of keywords, while ob-jects represents services. Generic concepts (referred as top concepts) are placed in the high part of the lattice (card, credit, Visa, Mastercard, etc.). The lattice easy permits to find, for example, services that both support Visa or Mas-tercard (service11 and service6). service6 is considered to
be more specific than service11 because, according to its description, it can validate credit card numbers, while ser-vice11 does not advertise such a feature. Going further in our lattice analysis, it can be noted that service16 can be used to validate credit cards and it seems to be more spe-cific than service1. This reflects what is specified in their description:
• service1: “credit card (whole text is: Offering Loans And Credit Cards to Consumers)”
• service16: “accept card credit validate valid (whole text is ”Will accept and validate a Credit Card Number. Returns True for a Valid Number and Returns False for a Invalid Number”)”
Note that word relevance depends on the term document frequency. If a word appeared only in one document, it has been pruned (”loans”, ”consumer”, ”invalid”). Other words have also been stopped. According to the proposed approach, new concepts are added to the lattice when terms appear in more than one document. Therefore, if a new ser-vice description containing the word consumer is used to expand the lattice, a new concept will be added, and the lattice structure will change.
A further example of lattice building, related to the mail domain, is reported in a technical report available online [6].
4.4
Discussion
Results obtained for service classification showed how the approach can be useful. It appears evident that the auto-matic classification helps, identifying, with a likelihood of 83%, the ordered list of 3 out of 11 classes among which the service may be classified.
The service publisher can exploit this result from several points of view. First and foremost, he/she can accept one of the classifications proposed by the automatic tool, possibly manually refining the choice. In this case, the tool helps in reducing the publisher classification degrees of freedom across a limited number of service classes/domains.
It may happen that the proposed classes may be com-pletely different than publisher expectancies. If a “weather” service is classified in the “finance” or “mail” domain, it means that the service description may be ambiguous. In this case the tool raises the publisher’s attention to the prob-lem, highlighting the need for correcting the deployed ser-vice documentation. This will reduce the risk that, during service search, the service is never found by queries related to its own features and, instead, it is found by queries related to other kind of features.
Regarding concept lattice building, it appears immedi-ately clear that a completely automatic ontology or seman-tic annotation building is unfeasible. This, however, was not
Figure 2. Concept lattice of services: the credit card example
our purpose. Instead, we found that, while human supervi-sion and intervention cannot be avoided, useful insights can be obtained from service lattices. In fact, by highlighting relationships between services, it can help to build and re-fine the service semantic annotation. By looking to the lat-tice, the publisher can found that some keyword may sim-ply make the service annotation heavier, or even mislead-ing. Thus, it can be decided to remove or replace these keywords. When a service developer publishes some ser-vices, he/she is aware of the genericity/specificity of the services. If this is not reflected in the lattice, it means that service descriptions are misleading or incomplete. More generally, if the web service textual description is incom-plete, too generic or containing phrases not properly related to the service features, it may be hard to automatically clas-sify it and to find the correct position in the concept lattice. Much in the same way, let us suppose that some domain– specific services have been already published and semanti-cally annotated according to a specific ontology, and that we want to publish a new service. By using proper tools, such as the FCA plug-in for Protege 2000 [2], it can be possi-ble to extract a context from the ontology. If we add a row, representing our service keywords, to such a context, and
then we build a lattice using FCA, we will be able to im-mediately highlight how our service can be annotated with respect to the ontology.
The second consideration we can make about the useful-ness of these concept lattices is related to ontology building. As stated in the introduction, service annotations coherent with ontologies may be necessary to allow automatic ser-vice matching for late–binding. The concept identification made by FCA, as well as the lattice structure of these con-cepts, although giving a limited view of an ontology, can in-deed be useful for its building, completion or maintenance. In fact, when publishing new service, new concepts may need to be added, especially if the ontology is not yet com-plete.
Conversely, when a user performs a query to retrieve a service, the following scenario can happen. First and fore-most, the user is guided, by the SVM classifier, to focus on some particular domains. In these domains, the portion of lattice of interest is highlighted, significantly easing the ser-vice search. Finally, our studies suggested that lattices ap-pear to be useful when focusing to well restricted domains. Wide domains and upper ontologies would generate, in fact, unmanageable and difficult to understand lattices.
5
Conclusions
This paper presented an approach, based on machine– learning techniques, to support service classification and annotation. Starting from free–text service documentation, services are automatically classified in classes/domains us-ing Support Vector Machines. Successively, Formal Con-cept Analysis is used to build service conCon-cept lattice for each specific domain.
Results of a classification experiment on a set of 205 ser-vices downloaded from the web shown the feasibility of the approach. Although needing user guidance, automatic clas-sification, by proposing the nearest–three classes out of 11 with a likelihood of 83%, can ease and support the service publication and annotation. Much in the same way, the ob-tained concept lattices highlighted relationships existing be-tween services, and aided the identification of domain key concepts. Finally, we showed with some examples how the same approach can also be integrated in the service retrieval mechanism.
Work–in–progress is devoted to further improve the pro-posed technique, to confirm the obtained results with other case studies, and to integrate the approach in a service bro-ker we are developing in a project in cooperation with an Italian software company.
References
[1] Libsvm tool. http://www.csie.ntu.edu.tw/ cjlin/libsvm/. [2] Plugin for protege–2000. http://www.ntu.edu.sg/. [3] Protege–2000. http://protege.stanford.edu/.
[4] Textual documentation of web services and classified ser-vices. http://moguntia.ucd.ie/repository/ws2003/.
[5] Wordnet dictionary. http://www.cogsci.princeton.edu/∼wn/. [6] M. Bruno, G. Canfora, M. Di Penta, and R. Scognamiglio. An approach to support web service classification and an-notation. Technical report, RCOST - University of Sannio, Italy, Sep 2004.
[7] S. P. Cimiano, J. Staab, and Tane. Deriving concept hier-archies from text by smooth formal concept analysis. In
Proceedings of the GI Workshop Lehren Lerner Wissen -Adaptivitat (LLWA), 2003.
[8] G. Di Lucca, M. Di Penta, and S. Gradara. An approach to classify software maintenance requests. In Proceedings of
IEEE International Conference on Software Maintenance,
pages 93–102, Montr´eal, QC, Canada, Oct 2002.
[9] P. W. Eklund, editor. Browsing Search Results via For-mal Concept Analysis: Automatic Selection of Attributes,
volume 2961/2004 of Lecture Notes in Computer Science. Springer, feb 2004.
[10] W. B. Frakes and R. Baeza-Yates. Information Retrieval:
Data Structures and Algorithms. Prentice-Hall, Englewood
Cliffs, NJ, 1992.
[11] H.-M. Haav. An application of inductive concept analysis to construction of domain-specific ontologies. In B. Thal-heim and G. Fiedler, editors, Emerging Database Research
in East Europe, Proceedings of the Pre-Conference Work-shop of VLDB 2003, volume 14/03 of Computer Science Re-ports, pages 63–67. Brandenburg University of Technology
at Cottbus, nov 2003.
[12] T. Joachims. Text categorization with support vector ma-chines: learning with many relevant features. European Conf. Mach. Learning, ECML98, Apr. 1998.
[13] T. Joachims. A statistical learning model of text classifica-tion for support vector machines. In Proceedings of the 24th
Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 128–136,
2001.
[14] M. Kim and P. Compton. Formal concept analysis for domain-specific document retrieval systems. Lecture Notes
in Computer Science, 2256, 2001.
[15] D. D. Lewis. Representation and learning in information
re-trieval. PhD thesis, Department of Computer Science,
Uni-versity of Massachusetts, Amherst, US, 1992.
[16] E. Maedche and G. Stumme. FCA-MERGE: Bottom-up merging of ontologies. Jan. 06 2001.
[17] N. F. Noy, R. W. Fergerson, and M. A. Musen. The knowl-edge model of Prot´eg´e-2000: Combining interoperability and flexibility. Lecture Notes in Computer Science, 1937, 2000.
[18] M. Paolucci, T. Kawamura, T. R. Payne, and K. Sycara. Se-mantic matching of web services capabilities. In First
In-ternational Semantic Web Conference (ISWC 2002), volume
2348, pages 333–347. Springer-Verlag, June 2002. [19] F. Sebastiani. Machine learning in automated text
cate-gorization. ACM Computing Surveys (CSUR), 34(1):1–47, 2002.
[20] M. Stone. Cross-validatory choice and assesment of statisti-cal predictions (with discussion). Journal of the Royal
Sta-tistical Society B, 36:111–147, 1974.
[21] G. Tao. Using formal concept analysis for ontology
struc-turing and building. PhD thesis, 1992.
[22] V. N. Vapnik. Statistical Learning Theory. John Wiley, Sept. 1998.
[23] B. G. R. Wille. Formal Concept Analysis. Mathematical Foundations, Springer Verlag, 1999.
[24] Y. Yang and X. Liu. A re-examination of text categoriza-tion methods. In M. A. Hearst, F. Gey, and R. Tong, ed-itors, Proceedings of SIGIR-99, 22nd ACM International
Conference on Research and Development in Information Retrieval, pages 42–49, Berkeley, US, 1999. ACM Press,