LANGUAGES FOR SEMISTRUCTURED DATA
Pavel Hlousek and Jaroslav Pokorny
11. INTRODUCTION
Semistructured data can be explained as “schemaless” or “self-describing”, indicating that there is no separate description of the type or structure of the data. This is in contrast with the structured approaches, such, e.g. relational databases, where the data structure is usually designed first and described as a database schema. Semistructured data is data whose structure is irregular, is heterogeneous, is partial, has not a fixed format, and evolves quickly. These characteristics are typical for data available in the Web (HTML pages, e-mail message bases, bookmarks collections etc). The research of semistructured data aimed at extending the database management techniques to semistructured data in the late 90's (Suciu, 1998).
An independent but strongly relevant development of XML (W3C, 1998), the eXtensible Markup Language, resulted in an agreement that XML became the de facto representation for semistructured data. Consequently, the data base research focused on XML as a source of new database challenges (Pokorny, 2001). Particularly, new XML data models and XML query languages have appeared and so called “native XML databases” have come into common usage among companies (Bourret, 2001).
In the research community, initial work on the semistructured databases was based on simple graph-based data models such as the Object Exchange Model (OEM) (Papakonstantinou, et al, 1995). Though XML and OEM are similar, there are some differences, and one of the most significant of them concerns data ordering. OEM and other original semistructured data models are set-based: an object has a set of subobjects. However, since XML is a textual representation, any XML document specifies the order inherently: an element has a list of subelements. Of course, some applications may treat the order as an irrelevant artefact of the serialization “forced” by an XML representation. In other words, we can use OEM model as a simpler alternative for management of some semistructured data collections.
OEM model can be still simplified. In OEM, cycles in the data graph are allowed. Since query languages for this data need to count with a possibility of cycles, they
1 Dept. of Software Engineering, Faculty of Mathematics and Physics, Charles University, Malostranske nam. 25, Praha 1, Czech Republic, email: {hlousek|pokorny}@ksi.ms.mff.cuni.cz
become really complicated. Also the size of an answer to a query may contain data that are useless for the user, because with each node there is its whole subgraph returned. This is because the data in OEM model is held by nodes without outgoing edges.
On the other hand, data is often of a tree structure in terms of a part-of relationship.2 If the data is modeled by a graph, then cycles can appear to represent some added information.3
Therefore, in Section 2, we refine the OEM model not to lose the notion of part-of relationships in the cyclic graph. This affects answers to queries, which with each node no longer return its whole subgraph, i.e. all accessible nodes, but they rather return only nodes that represent just the node's subparts. Because part-of relationships form a tree, we do not have to bother with cycles any more, and can make our query language evaluation much simpler. This can be very suitable for query languages with emphasis on the semantics of the data represented in XML, where the part-of relationship corresponds to the element-subelement relationship and cycles are realized through IDREF(S) attributes.
The fact that we can work with data as if it were a tree, creates many possibilities for query languages for semistructured data. One of them – default structuring – is presented in Section 4. Where other similar languages, like Lorel (Abiteboul, et al, 1996), XML-QL (Deutsch, et al, 1998), UnQL (Buneman, et al, 1996), and recently XQuery (W3C, 2001), force the user to use some “construct” clause to explicitly specify the result structure (or the default structure of these languages is a set), our proposed language provides default structuring of the result nodes by keeping the minimal structural context which these nodes had in the source data graph.
In the following text, we use an email message base as an example of semistructured data, and associated query language MailQL, which was developed as the author's master thesis (Hlousek, 2000). In the email message base, part-of relationships are e.g. folder-subfolder, folder-message, message-fields, and cycles are caused by edges representing e.g. message threads (described later). There are many other areas in the semistructured data where part-of relationships can be found: image and its subregions, XML data with elements containing elements, etc.
1.1 Goals
The goal of this paper stated in a single word is “simplicity” and is divided into two subgoals.
One is to reduce the complexity of evaluation of query languages for semistructured data by letting the evaluation work with data in a tree instead of a cyclic graph (though the cycles are not lost). This is achieved by the OEM refinement.
The other is to utilize the refinement to find a simpler syntax of a query language for semistructured data. To be more precise, the current query languages usually provide some construct clause to specify the structure of the result. They also provide some default structuring of the result when the construct clause is omitted, which means the
2
By part-of relationship we mean the situation in part-subpart relationship, where parts may not appear in multiple aggregation. We can take a directory structure with files without any kind of links as a good example. Here a subdirectory (or file) is in a part-of relationship with its parent directory.
3 Providing symbolic links can result in cycles in our graph that represents the directory structure with files. However, the tree structure behind the cyclic graph is not lost.
result is a set of nodes. Our goal is to find more structurally expressive default structuring of the result by reflecting the structure of the nodes in the source.
1.1 Structure
In Section 2 we present the OEM model and its proposed refinement. Section 3 briefly explains the syntax of MailQL that is used in examples. Section 4 introduces our proposed default structuring of the result based on keeping the minimal structural context, which the result nodes had in the source data base. Finally, in Section 5 we give some conclusions.
2. DATA MODEL
In this section, we define the OEM model and its refinement.
2.1 OEM Model
The Object Exchange Model (OEM), first appearing in the TSIMMIS project (Papakonstantinou, et al, 1995), is the de facto standard in the modeling of semistructured data. The following definition of OEM is borrowed from (Abiteboul and Suciu, 2000).
Definition 1. An OEM object is a quadruple (label, oid, type, value), where label is a character string, oid is the object's unique identifier, and type is either complex or some identifier denoting an atomic type (like integer, string, etc.). When type is complex, then the object is called a complex object, and value is a set of oids. Otherwise, the object is an atomic object, and value is an atomic value of that type.
Thus the data represented by the OEM model is held by the OEM objects of atomic type that are referred to by the OEM objects of complex type.
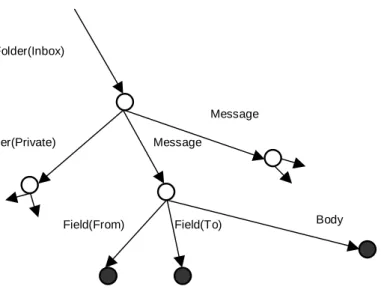
The OEM data is usually understood as an oriented graph with labeled nodes, where the OEM objects correspond to nodes, and for each node n representing the complex OEM object o = (label, oid, complex, value) there are edges leading from n to nodes that represent the OEM objects in o's value field. Figure 1 shows how this model can describe a part of our tree-like message base. It is also apparent from the picture that we use very common modification of the OEM model - labels are attached to edges, rather than to nodes. Thus we take our message base as an oriented edge-labeled data graph.
Definition 2. We say that m is an l-subobject of n if there exists an edge labeled l
leading from n to m.
Henceforth, the OEM objects are simply called objects. We should also note that in the following text we mix the terms node and object, while according to the OEM definition a node represents an object, and vice versa.
Figure 1. Part of a message base modeled by OEM. We can see folder Inbox which contains two messages, and
subfolder Private. One message contains fields From and To, and a node representing its body. (Other children are omitted.) The complex nodes are distinguished from the atomic ones by empty circles. Since it is not essential to distinguish these two types of nodes in the following figures, we draw all nodes using filled circles.
2.2 Refining OEM Model
Now let us turn our attention to our example of an email message base. Let us enrich the message base model (which so far consists only of part-of relationships like a folder-message), with edges providing us with some added information. Let us add to the model message threads, which help us organize email messages by dialogs in which these messages appeared. A bit more formally, a message thread of message m is a set of messages Tm that is generated by a reflexive, symmetric, and transitive closure of a binary
relation is-reply-to between messages from the message base.
In the message base model the message thread of m is expressed by edges labeled
thread, leading to all nodes that represent a message in the message's thread Tm. 4
We mentioned earlier that with each node there is its subgraph returned as an answer to a query in other OEM-oriented languages. So with each message, all messages from its thread must always be returned. However, this OEM specific behavior does not satisfy us, because we might be interested in the messages only, without caring about their threads, which can be in some cases very large, and so they could wastefully enlarge the size of the result.
Therefore we refine the OEM model to distinguish between two types of edges. This refinement is described by Definition 3.
4
In figures throughout this paper, we omit edges that represent identity.
Message Message
Folder(Private) Folder(Inbox)
Definition 3. (i) Core edges are edges describing the tree structure of data, given by
part-of relationships. (ii) Secondary edges are edges describing added information. Core (secondary) paths are oriented paths consisting only of core (secondary) edges.
Definition 3 says that core edges are edges describing part-of relationships (e.g. edges from the message to its fields), while secondary edges are edges describing other than part-of relationships (e.g. edges from message to its message thread).
Definition 4. By core data tree of data graph G = (V, E) we denote its subgraph G' =
(V, E'), where E' ⊆ E consists of all core edges.
We should note that the data graph and the core data tree share the same nodes. The only difference is that the core data tree is composed exclusively of core edges, and therefore it is always a tree, because the core edges represent the part-of relationships, while the complete data graph can contain cycles which are caused by the presence of secondary edges.5
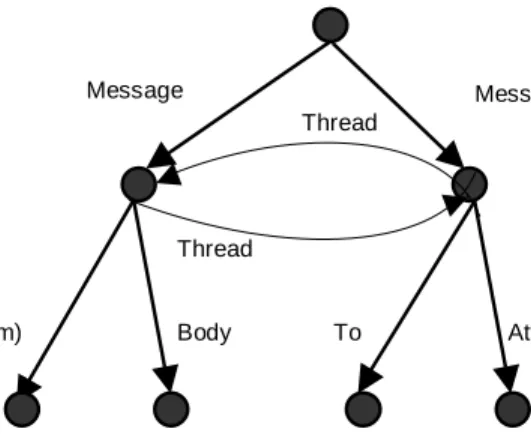
We should also note that the refined OEM model can hold the information about the types of edges, but the information about an edge type must come from the outside world. Now back to our example. It is clear that the thread edges will be marked as secondary. By enriching the treelike message base model by these edges (that provide some additional information to the hierarchical structure of data), the data graph is no longer a tree: it is a cyclic graph. But using Definition 3 and Definition 4, we do not lose the notion of the previous tree in the data graph (due to the core edges). Figure 2 illustrates this situation on our message base model enriched by thread-edges.
The introduced refinement was done to achieve this feature: let the query language evaluator work with the core data tree instead of working with the (possibly cyclic) data graph. Specifically, with each result node there will be its subgraph from the core data tree in the result. So asking for a message, we will not put the messages from its thread in the result, as is the case in OEM. Furthermore, the result, just before being shipped to the user, will be provided with those secondary edges where both nodes of each secondary edge were preserved. Thus the messages from some message's thread that got into the result, will remain connected with the thread-edges as they were in the source data base.
2.3 Path Expressions
Now that our semistructured data model has been refined, we need a way to navigate through the data graph. Nowadays, the most suitable tool seems to be path expressions. Their presence in languages for the semistructured data is almost a rule because of their navigational syntax.
If o is object and l is label, then by expression o.l we denote the set of l-subobjects of o. We should notice that o.l always denotes a set of objects. This semantics of path expressions is typical for semistructured data.
5
Here we have made a simplification talking about a data tree. Instead of tree, we might talk more generally about a rooted acyclic graph, but there is no major consequence for this paper in distinguishing these two but the number of roots. Henceforth, by the root of a data tree we will understand any root in the rooted acyclic graph.
Figure 2. Part of a message base with core edges (drawn with thicker lines) and secondary edges (drawn with
thinner lines). Here one message is a reply to the other. The message-nodes have their outgoing edges heavily reduced in order to simplify the figure; normally, there would be many more of them.
Simple path expression is expression r.l1… ln, where r is root node and l1… ln are
edge labels. Data path is a sequence of o0, l1, o1,…, ln, on, where oi are objects, and for
each i there is an edge between oi-1 and oi labeled li. According to these definitions we
can see that there can be more than one data path that satisfies some simple path expression.
Semantics of simple path expressions is very intuitive. We will explain it on the example of root.A.B. Expression root denotes the starting object. Expression root.A
denotes set X of all objects for which there exists an edge leading to them from root and labeled A. Expression root.A.B denotes then set Y of all objects for which there exists an edge leading to them from any object in X and labeled B.
Thus each simple path expression denotes a set of objects, even if there is no data path satisfying it. In such a case, the path expression denotes an empty set.
General path expressions enhance the power of simple path expressions by enabling use of wild cards and regular expressions in path expressions.
With a wild card we can substitute either an edge label (using %) or a sequence of edge labels (using *). Thus expression root.%.B means root.any_label.B, and expression
root.*.Z means root.any_path.Z.
Regular expressions enable use of path expressions such as root(.A|.C).B which matches two simple path expressions root.A.B and root.C.B and so it results in the union of two sets of objects.
Usually, there are many more constructs that are typical for regular expressions, and the usage of wild cards could be widened much more. But talking about this is not the goal of our paper.
Using path expressions, we often refer to a common prefix of two or more path expressions. First we define predicate IsPrefix, a definition of a common prefix follows. We should note that by a common prefix we always mean the longest common prefix.
Message Attachment Thread Thread Message Field(From) Body To
Definition 5. Let pe1 and pe2 be path expressions. The IsPrefix(pe1, pe2) predicate is
true if pe1 = X.l1…ln and pe2 = X.l1…ln+m, where n ≥ 0 and m ≥ 0.
Definition 6. Let pe1 and pe2 be path expressions. By common prefix we denote path
expression pe = X.l1…lk, where both IsPrefix(pe, pe1) and IsPrefix(pe, pe2) are true, and
there is no such path expression pe' = pe.lk+1 for which both IsPrefix(pe', pe1) and
IsPrefix(pe', pe2) would be true.
3. EXAMPLE SYNTAX
As introduced earlier, MailQL is a query language for an email message base which we use here as an example of the semistructured data modeled by the refined OEM model. MailQL queries borrow their syntax from OQL (Cattel et al, 2000) and its semistructured-data-oriented successor Lorel (Abiteboul et al, 1996).
SELECT list_of_path_expressions
FROM list_of_aliases_for_path_expressions WHERE boolean expression
The following example shows a simple query in MailQL, which returns fields From
and Date of all messages that contain string 'MailQL' in its Subject field.
SELECT m.From, m.Date FROM Inbox.Message: m
WHERE m.Subject CONTAINS 'MailQL'
Note that FROM clause in a MailQL query plays a different role than in other syntactically similar languages: here it only defines aliases (m) for path expressions (Inbox.Message). Before the query is executed, all occurrences of aliases are substituted by appropriate path expressions in the SELECT and WHERE clause, therefore the FROM clause is no longer needed after that.
4. AUTOMATIC CONSTRUCTION OF THE RESULT STRUCTURE
In this section, we introduce an interesting use of the OEM refinement. So far, we considered what to return with nodes specified in the SELECT clause. It means we were inspecting the part of the core data tree on the path from these nodes to leaves. Now we switch our attention to the other part of the core data tree: the path from the root to nodes specified in the SELECT clause. The question is: In what structural relationships should the nodes, specified in the SELECT clause of a query, be?
Current languages for semistructured data usually provide some “construct”' clause, which explicitly defines the structure of the result. Some of them provide default structuring, which means returning a set of tuples. But having the core data tree, we can improve the default structuring by keeping the minimal structural context which the specified nodes had in the source data tree. Simply said, the path expressions from the SELECT clause specify nodes in the data graph. All these nodes will be returned (with
their subgraphs, as described in Section 2). And we also want all these nodes to stay in the same structural relationships to each other as they did in the source data tree. This could be surely realized even in such a way that we would preserve the whole paths leading to these nodes from the root of the core data tree. But our solution vertically reduces these paths and keeps from them only the “interesting” nodes, i.e. nodes, in which the path forks to reach the specified nodes.
Compared with other languages for semistructured data, we might miss the strong result restructuring features, but we think that in many cases the user needs to see the minimal structural context of the data, which is just what our language provides. Furthermore, all introduced features of our language could be incorporated into any query language with strong formatting options and thus provide default structuring of the result.
4.1 Minimal Structural Context
Let us first formalize vertical reduction.
Definition 7. Let T = (V, E) be a tree where V is a set of nodes, and E is a set of
edges. We say that tree T' = (V', E') is a vertically reduced tree of T if both the following conditions are true:
i) V' ⊆ V
ii) for each e' = (v'1, v'2) ∈ E' it is true that either (a) e' ∈ E (an edge preserved from
T); or (b) there exists sequence e1,…,en of edges from E \ E' and sequence
vk2,…, vkn of nodes from V \ V', such that v'1, e1, vk2,…, vkn, en, v'2 is a path in T.
Definition 7 says that T’ was obtained from T by leaving out some nodes in such a way that if there was a path between two nodes in T and if both nodes were preserved in T', then there must exist a path between them in T', as well. (T' is sometimes called a minor of T in the graph theory.)
Now let us turn our attention to the “interesting” nodes. As declared at the beginning of this section, the only nodes that are preserved from paths leading to the queried data are those, where these paths fork. Given two path expressions, we can determine the path expression of nodes where the paths fork by finding out the common prefix of these two path expressions. So by the “interesting” nodes we understand those nodes that are represented by the common prefixes of path expressions from the SELECT clause.
To describe the minimal structural context of the result nodes, we use a data structure called a result structure tree (RST), which helps us specify the (vertically reduced) structure of the result. Formally, a result structure tr ee is a tree RST = (V, E) with mapping PEI(path expression infix) defined for all its nodes. Each node is mapped by PEI to a part of path expression in such a way that the common prefix is empty for each pair of siblings in RST. PEI of the root node always maps to an empty path expression.6
To get the structure of the result for a certain query, we take all path expressions from the SELECT clause of the query and construct an appropriate RST of them. The construction is directed by the common prefixes of path expressions. We start with the
6
If the data tree forms a rooted acyclic graph, then the RST forms a rooted acyclic graph as well, but it has always just one root, which represents an empty path expression. So if there are more roots getting to result from the source data graph, then they are represented as children of the root in RST.
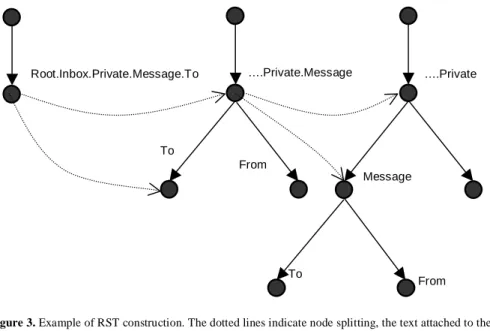
root node which is always present and is always assigned an empty path expression. The first path expression will be represented by a child node of root, where PEI of that node will be the path expression itself. When adding every other path expression to the RST, we find its common prefix with each of the path expressions that are already represented by RST. If there is a non-empty common prefix, then some splitting must take place in order not to violate the definition of RST. Figure 3 illustrates in three steps how RST is created for the set of path expressions {Inbox.Private.Message.To,
Inbox.Private.Message.From, Inbox.Private.Name}.
Now, the inner nodes of RST, which represent common prefixes of a path expression in the SELECT clause of a query, represent the path expressions of the “interesting” nodes that we spoke about above – they are the ones which express the minimal structural context of the returned data – while the leaf nodes represent the data which are to be returned.
Henceforth, we will denote the structure of the result using XML-like syntax (according to Buneman at al, 1996). So the structure of the final tree in Fig. 3 will be written down like this:
{<Inbox.Private> {<Name>...</>} {<Message> {<To>...</>} {<From>...</>} </Message>} </Inbox.Private>} 4.2 Structure-Forcing Operator
Sometimes, it may be convenient to keep more of the structure in the result. For example, for the query
SELECT Inbox.Message.To
the result structure will be a set of recipients {<Inbox.Message.To>...</>}. But we may want to distinguish the recipients according to the messages they come from. Therefore we introduce a structure-forcing operator <...>, which forces the “interestingness” of a path expression. Thus the desired query can be formulated
SELECT <Inbox.Message>.To
4.3 From RST To Result
Once we have the RST representing the result structure, we can easily generate its result tree. Each node from RST may correspond to several nodes of the core data tree (e.g. Inbox.Message denotes a set of messages). Thus the result for RST in Fig. 3 can look in XML syntax like this:
Figure 3. Example of RST construction. The dotted lines indicate node splitting, the text attached to the node is
the value of the node's PEI. The three dots in the second and the third RST are an abbreviation for Root.Inbox.
<Inbox.Private> <Name>Private</> <Message> <To>[email protected]</> <From>[email protected]</> </Message> <Message> <To>[email protected]</> <To>[email protected]</> <From>[email protected]</> </Message> </Inbox.Private>
4.4 The Added Value
At the beginning of this section, we stated that the MailQL query language is simpler than other languages for the semistructured data, because it provides a feature of keeping the minimal structural context of the queried data. To demonstrate this fact, we compare here the syntax of two queries, which we write in MailQL and Lorel, to get the result structure of the final tree in Fig. 3.
Using MailQL, we have two basic options to express the query. One that uses the FROM clause
SELECT P.name, M.to, M.from FROM inbox.private: P, P.message: M
….Private.Message To From vroot vroot Root.Inbox.Private.Message.To Message ….Private To From vroot Name
or the other without the FROM clause
SELECT inbox.private.name, inbox.private.message.to, inbox.private.message.from
Both of them have the same output of the desired structure.
To get the same result in Lorel, we have to write a query that is much more complex, because (i) we have to specify the structure of the result in the SELECT clause of the query and (ii) in the FROM clause we have to specify all the bounding variables to keep the structure of the queried data.
SELECT inbox.private: {name: N, message: {to: T, from: F}} FROM inbox.private: P
P.name: N, P.message: M, M.to: T M.from: F
It is obvious that our query language wins in all situations where the result structure has to reflect the structure of the queried data. And on the other hand, MailQL looses in all situations where some major restructuring of the queried data is needed. Therefore we propose the mechanism of the automatic creation of the result structure to be used as part of some query language with stronger restructuring capabilities.
5. CONCLUSIONS
Leaning on the fact that most semistructured data (e.g. XML data) is of tree structure in terms of part-of relationships, we refined the OEM model not to lose the notion of this tree in a complex data graph with cycles. This refinement allows us, and generally all languages for the semistructured data, to work with the data as if it were a tree, and so it allows us not to bother with the complexity caused by cycles in the data graph. As other use of our OEM refinement, we introduced bases of a query language that provides default structuring of a query result based on keeping the minimal structural context as a different approach to the default result structuring of languages for the semistructured data.
It also has to be said that our refinement is useful in cases, in which there is a rule helping us decide, whether an edge is a core one or a secondary one. Here, XML can serve as a good example with the rule: let us represent the element-subelement relationships by core edges, and let us represent the cycles-causing IDREF and IDREFS attributes by secondary edges.
The query language presented here (originally MailQL) was designed and implemented for an email message base as part of a master thesis and is further under development.
6. ACKNOWLEDGEMENT
This work was supported in part by the GACR grant No. 201/00/1031.
7. REFERENCES
Abiteboul, S., Quass, D., McHugh, J., Widom, J., and Wiener, J., 1996, The Lorel query language for semistructured data, International Journal on Digital Libraries. 1(1), pp. 68-88.
Abiteboul, S., and Suciu, D., 2000, Data on the Web: From Relations to Semistructured Data and XML, Data Management Systems, 1st edition, Morgan Kaufmann.
Bourret, R., 2001, XML and Databases; http://www.rpbourret.com/xml/ /XMLAndDatabases.htm.
Buneman, P., Davidson, S., Hillebrand, G., and Suciu, D., 1996, A query language and optimization techniques for unstructured data, (JAGADISH, H.V. and MUMICK, I.S. Eds.), SIGMOD, pp. 505-516. ACM Press.
Bray, T., Paoli, J., and Sperberg-McQueen, C. M., 1998, Extensible Markup Language (XML) 1.0, February 1998; http://www.w3.org/TR/1998/REC-xml-19980210. Cattell, R.G.G. et al., 2000, The Object Database Standard: ODMG 3.0, Morgan
Kaufmann Publishers, Inc.
Deutsch, A., Fernandez, M., Florescu, F., Levy, A., and Suciu, D., 1998, XML-QL: A query language for XML;
http://www.w3.org/TR/1998/NOTE-xml-ql-19980819.html.
Hlousek, P., 2000, MailQL, query language for an email message base, Master's thesis, Charles University, Prague. In Czech.
Papakonstantinou, Y., Garcia-Molina, H., and Widom, J., 1995, Object exchange across heterogeneous information sources, in Proceedings of the Eleventh International Conference on Data Engineering, Yu, Ph. S. and Chen, A.L.P. eds., pp. 251-260, IEEE Comp. Soc.
Pokorny, J., 2001, XML: a challenge for databases? Chap. 13 in: Contemporary Trends in Systems Development, Sein, M. et al, eds., Kluwer Academic Publishers, Boston, pp. 147-164.
Suciu, D., 1998, An Overview of Semistructured Data, SIGACTN: SIGACT News (ACM Special Interest Group on Automata and Computability Theory), 29.
W3C, 1998, Extensible Markup Language (XML) 1.0; http://www.w3.org/TR/REC-xml W3C, 2001, XQuery 1.0: An XML Query Language W3C Working Draft 07;