arxiv: v1 [stat.me] 2 Dec 2020
Full text
Figure
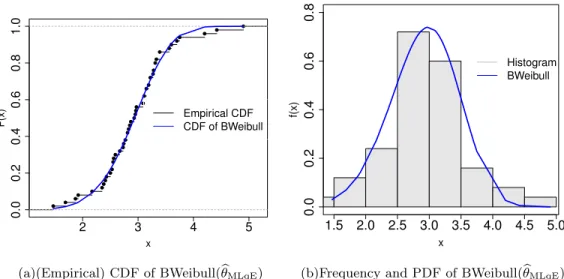
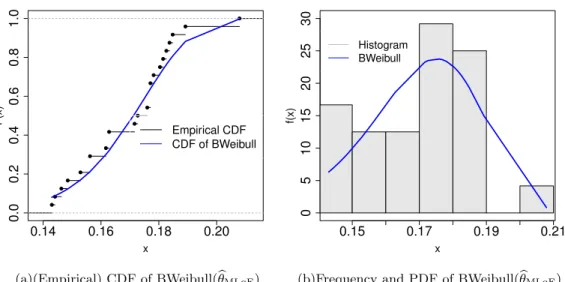


Related documents
For example, 100% of Internal Coaches agreed that their building used fluency-based screening measures, and approximately 85% agreed that teachers at their schools viewed
The company provides a wide range of insurance products and services such as accident & health insurance, life insurance, motor insurance, travel insurance, old age
Fixed Need Pool 10/24/14 Letter of Intent Filing Deadline 10/20/14 16-day Grace Period Letter of Intent Filing Deadline 11/05/14 CON Initial Application Filing Deadline
• Named lead for family with dedicated time from home agency • Intensive work with small caseloads of families e.g <5 • Less intensive.. work with larger
The summary accounts presented are designed to enable a rapid review to be made of (i) the main characteristics of the principal insect pests of agriculture that are believed to
Both the binned analysis of SH96 and the DP90 modelling suggest very firm evidence for a decline at low-redshifts, whereas the reasonably high relative likelihood of our model F
Technique 4: Real time transactions + digipass automation. Do real time transactions automatically and
The program offers practical information and discussions about many of the issues people experience after a diagnosis of cancer. Topics covered include: what cancer is,
