Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 547
A Robust analysis of Cloud Computing Framework with Machine
Learning Intentions for Industrial Applications
#1SRAVAN KUMAR VULCHI, M.Tech ,CSE, GVVR Institute Of Technology, Bhimavaram ,
#2JANARDHANA JNSS, Asst. Professor, Swarnandhra College of Engineering and Technology,
Narsapur
ABSTRACT- In this paper, a novel distributed
computing structure is given machine learning
(ML) calculations for aviation applications, for
example, condition-based support, recognizing
inconsistencies, foreseeing the beginning of part
disappointments, and diminishing aggregate
lifecycle costs. This cloud structure has been
created by utilizing MapReduce, HBase, and
Hadoop Distributed File System (HDFS)
innovations on a Hadoop bunch of OpenSUSE
Linux machines. Its ML calculations depend on
Mahout ML Library and its online interface is
fabricated utilizing JBoss and JDK. Essentially, the
huge information from different Honeywell
information sources are overseen by our HBase and
broke down by different ML calculations. Clients
can utilize this cloud based diagnostic toolset
through internet browsers whenever and anyplace.
More explanatory consequences of utilizing this
structure will be distributed later.
Keywords: Cloud Computing, Big Data Analytics,
Machine Learning, Algorithms, MapReduce.
I. INTRODUCTION
To manage information excess and data
over-burden, enormous information investigation and
distributed computing advancements are being
utilized by the world best IT and programming
organizations, for example, Google, IBM and
Microsoft [1]. As of now these innovations are
being received by different businesses. In this
paper, we exhibit our model of cloud structure with
machine learning (ML) calculations for aviation
applications, particularly, Condition Based
Maintenance (CBM), checking, diagnostics, and
item unwavering quality and execution. In
Honeywell, there are enormous (volume, speed,
assortment) information that are gathered and
spilled from a large number of flying machine
(operational datasets, support information, and so
forth.), test cells (several sensors and estimations,
and so forth.), and repair shops (records of gadgets,
flight, mechanical repairs, and so on.). For
example, one test cell can create 300 MB test
information every day per motor. Our approach is
to join the best qualities and cooperative energies
of both distributed computing and machine learning
advancements, with a specific end goal to
adequately investigate the enormous information
and create capacities of prescient examination,
significant data, better CBM and basic leadership.
In fact, by joining and utilizing distributed
computing and ML innovations, our significant
objectives are incorporated (not constrained to): (1)
identifying peculiarities from parts, segments and
frameworks, (2) foreseeing the beginning of
disappointments of parts (e.g., segments, LRUs,
and so on.) to amplify resource utilizations and
accessibility, limit the downtimes, and (3)
managing better and compelling CBM
arrangements, and (4) diminishing aggregate
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 548 systems. Our essential assignments are to
understand these objectives by examining the
enormous information and changing data into
learning. In our CBM applications, after we built
up our Hadoop bunch by utilizing Apache
environments [2], we have concentrated on
breaking down and mining our information sources
by utilizing open source ML calculations including
Mahout Library [3] and by building up our ML
calculations utilizing R dialect.
II. ARCHITECTURE AND
COMPONENTS OF CLOUD-BASED
ML FRAMEWORK:
Our particular errands are to discover significant
experiences, examples and patterns in huge
information (expansive volume, speed, and
assortment) that can prompt noteworthy data, basic
leadership, forecast, circumstance mindfulness and
comprehension. To finish these specialized
undertakings, we have built up a cloud system with
machine learning advances for cyberlearning,
utilizing machine learning calculations (SVM,
irregular timberlands, PCA, K-implies, and so on.),
information mining, and learning serious critical
thinking. We built up our cloud-based ML system,
by building up a Cloud Controller, Cluster
Controllers, and Node Controllers on our Hadoop
group of Linux machines. We utilized Eucalyptus
cloud device [4] to build up our essential
programming system. The system engineering and
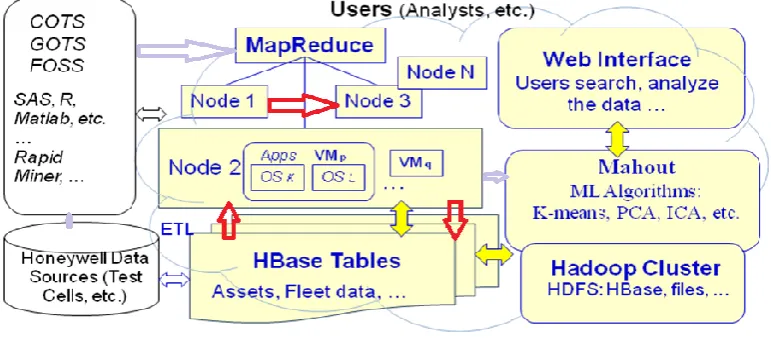
key segments are appeared in Figure 1. In Figure 1,
we executed the HBase that is an adaptable,
appropriated database and backings constant access
expansive information vaults, for example, Oracle,
MySQL, and so forth. At present, we have 5
noteworthy HBase tables (all the more enormous
tables can be made as required):
1. ML_use: This table oversees client
certifications and access benefits.
2. Field_reports: This table contains information
from working resources introduced on different
flying machines and working vehicles.
3. ListOfValues: This table contains factors
(normally vehicle introduced sensors) and
examined verifiable information. Every datum set
has an extraordinary timestamp related with it.
4. Repair_reports: This table contains information
gathered amid the repair of a part. Normally
information incorporates evacuation information,
field perceptions (free content), parts
supplanted/repaired, and shop perceptions (free
content)
5. Testcell_reports: This table contains information
from the research centre acknowledgment and
capability testing. The vast majority of the
segments we track experience an acknowledgment
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 549 Figure 1. Architecture and block diagram of our Cloud-based ML Framework.
When all is said in done, the HBase has two
specialized segments: (a) Convenient base classes
that help Hadoop MapReduce employments and
capacities with HBase tables; and (b) Query
predicate pushes down by means of server-side
sweep and gets channels that will choose related
information for track administration frameworks.
As found in Figure 1, HBase tables can work with
social databases, for example, SQL Server or
MySQL and accomplish the most noteworthy speed
in preparing and breaking down the huge
information. The accompanying is a case of the
code in Listing 1 for our HBase to get information
from our SQL Server, e.g., Honeywell Predictive
Trend Monitoring and Diagnostics (PTMD)
database, and others. Major existing information
sources incorporate stream datasets from test cells
of airplane motors, Auxiliary Power Units (APUs),
resources (e.g. electronic parts, repairman parts,
and so forth.) repair shops, and air ship armadas.
We have our SQL servers, MySQL databases, and
expository device. Recently created HBase tables
are populated by ETL, and the chose datasets from
existing RDBMS and the HBase give the
information segment families to Mahout ML
apparatuses to break down. A few definitions for
enormous information exist attributable to the
changed points of view and discernments with
which this idea is seen and comprehended.
Notwithstanding the wellspring of a definition,
most enormous information specialists have a
consistent perspective on the way that huge
information can't be confined just to the
measurement of volume. Numerous more
measurements, some of which might be application
or data source subordinate, should be investigated
before a far-reaching definition for enormous
information can be verbalized. The most
acknowledged meaning of enormous information
portrays it as gigantic volumes of exponentially
developing, heterogeneous information. Doug
Laney of Gartner, as the 3V Model, gave the
primary meaning of huge information (Gartner
2016). The basic huge information qualities
incorporated into this arrangement are volume,
assortment and speed. Be that as it may, enormous
information, as an innovation, got as of late after
the accessibility of open source advances like
NoSQL (Salinan 2012) and Hadoop1 , which have
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 550 for huge information stockpiling and preparing. In
like manner, the meaning of huge information was
changed to information that can't be put away,
oversaw and prepared by customary frameworks
and advancements. To upgrade the specialized
exactness of existing definitions, Shaun Connolly presented the terms exchanges, cooperation’s and
perceptions, which were added to the enormous
information definition (Samuel 1959). While
'exchanges' is a term used to depict information that
has just been gathered and investigated previously,
'associations' incorporate information that is
gathered from things and individuals. A class of
information missed by both these classifications is
the information that is consequently gathered and
constitutes 'perceptions'. Barry Devlin gave a
comparative, yet clearer meaning of huge
information, depicting it as far as
machine-produced information, human-sourced information
and process-interceded information (Ratner 2003).
From the business-adequacy point of view,
exchange information hold little importance in
perspective of the way that it is old information and
when, it is gathered and broke down, the outcomes
end up out of date or lesser significant. Despite
what might be expected, new information should be
broke down proficiently to give forecasts, which
can be utilized to make auspicious intercessions.
Supposition investigation is an application that
takes a shot at this point of view and uses huge
information as signs. This was formalized into a
planning and goal-based grouping of huge
information (Buyya 2016). Other than the
previously mentioned, there have been a few
different perspectives and points of view on huge
information. Researchers like Matt Aslett sees huge
information as a chance to investigate the
capability of information that was already
overlooked because of restricted capacities of
customary frameworks while some others call it
another term for old applications and innovations
like Business Intelligence (Abu-Mostafa,
Magdon-Ismail, and Lin 2012). Notwithstanding the huge
information definition, one takes after, nothing can
take away the way that huge information opens
ways to boundless openings and keeping in mind
the end goal to make utilization of this hold, we
have to grow new or adjust the current instruments
and advances.
III. CLOUD COMPUTING FOR BIG
DATA ANALYTICS
John McCarthy gave the world the idea of 'utility
figuring', amid the MIT Centennial talk 1961, when
he transparently talked about the eventual fate of
this industry and how processing will impart screen
to utilities like power and water, and be filled in
that capacity (Qian et al. 2009). From that point
forward, Cloud Computing has made considerable
progress to end up the innovation that changes
McCarthy's thoughts into the real world.
Notwithstanding, it was not until the point when
2006 that this innovation achieved the business
field. The presentation of arrangements like
Amazon's Elastic Compute Cloud (Amazon EC27)
and Google App Engine8 have been memorable
turning points in the historical backdrop of Cloud
Computing. A standout amongst the most starting
meanings of Cloud Computing was given by
Gartner, which portrayed this innovation as a
processing style that conveys adaptable and
versatile IT-empowered abilities to clients, as an
administration, with the help of Internet
advancements (Gartner n.d.). This definition
couldn't be viewed as a standard for the sheer
straightforwardness and equivocalness that it
involves. National Institute of Standards and
Technology (NIST) gave the business standard
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 551 2011). As indicated by this definition, Cloud
Computing is an innovation that permits
on-request, helpful and pervasive system access to
figuring assets that can be designed with
insignificant prerequisite of administration and
cooperation with the specialist co-op. The NIST
definition additionally specified the five key
qualities, organization models and conveyance
models for Cloud Computing. A diagram of the
NIST meaning of Cloud Computing is outlined in
Fig. 4. There are three fundamental parts of the
Cloud Computing Ecosystem to be specific,
end-client or purchaser, circulated server and server
farm. The cloud supplier arrangements the IT assets
to the end-client with the assistance of circulated
server and server farm.
Figure2. Cloud Computing Model Defined big-data
IV. MAHOUT MACHINE LEARNING
ALGORITHMS
A sub-field of computerized reasoning, machine
learning enables frameworks to learn and advance
utilizing observational information. Therefore,
smart basic leadership is essential to any
framework that executes machine learning. Be that
as it may, in the huge information setting, standard
machine learning calculations should be scaled up
to adapt to huge information prerequisites.
Profound learning is an ongoing field that is
drawing in colossal research consideration recently.
A few Hadoop-based structures like Mahout are
accessible for scaling up machine learning
calculations. In any case, a few fields of machine
learning like characteristic dialect handling and
recommender frameworks, aside from a few others,
confront versatility issues that should be alleviated
for advancement of nonexclusive and in addition
productive application-particular arrangements.
Picture investigation and example acknowledgment
are set up utilizations of Artificial Neural Networks
(ANN). As the quantity of hubs increment; the
precision of the outcome shows signs of
improvement. In any case, the expansion in hub
number lifts the unpredictability of the neural
system, both as far as memory utilization and
figuring necessities. Keeping in mind the end goal
to battle these difficulties, the neural system should
be scaled utilizing dispersed and parallel strategies.
Parallel preparing usage procedures can be utilized
with profound learning for handling enormous
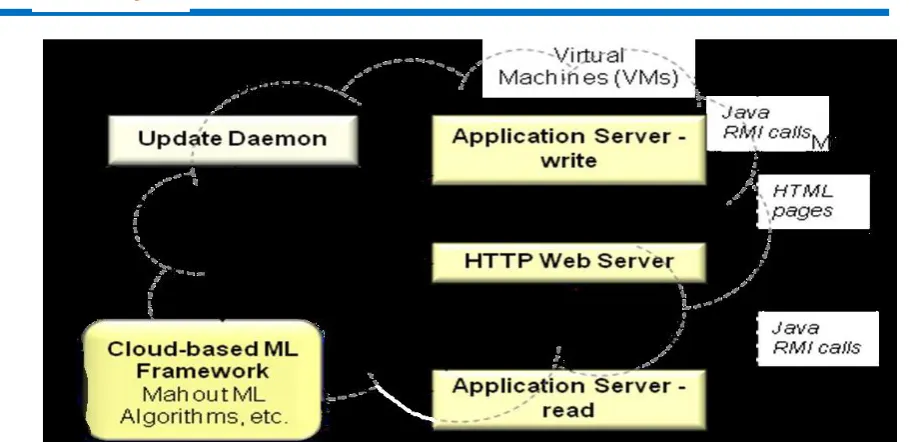
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 552 Figure 3. Workflow of the Cloud-based ML Framework Analytics.
Most critical applications utilizing the Mahout ML
calculations incorporate arrangement, grouping and
proposal, alongside Pattern Mining, Regression,
Dimension Reduction, and Evolutionary
Algorithms. By breaking down more than 100 a
large number of information cases [5] effectively,
Mahout turns out to be more imperative ML device
to use with Hadoop and MapReduce. Along these
lines we chose to coordinate Mahout ML
calculations into our cloud-based ML structure for
true applications, for example, peculiarity
discovery, blame mode forecast, and so forth. The
Mahout machine learning calculations are
composed utilizing MapReduce worldview:
(an) administered learning calculations including
neural systems, bolster vector machines (SVMs),
Naive Bayesian classifiers, choice trees, arbitrary
backwoods, and strategic relapse;
(b) unsupervised learning calculations including
k-implies, various leveled grouping, self-arranging
maps, fluffy k-implies, Dirichlet, PCA, ICA, desire
expansion, and mean-move, and so on.. We found
that Mahout ML calculations can be utilized for
better grouping by working with ZooKeeper. All
the more particularly, while serializing stochastic
angle drop ML models for organization as
classifiers, it is typically best to just serialize the
best performing sub-demonstrate from Adaptive
Logistic Regression. The subsequent serialized
document will be 100 times littler [5] than would
come about because of serializing the whole group
of models contained in the Adaptive Logistic
Regression protest. Mahout ML calculations are
incorporated into our cloud-based ML system
including, Support Vector Machines, and Naive
Bayes classifiers, K-Means, various levelled
bunching, and self-arranging maps, fluffy k-Means,
Dirichlet, and Mean-Shift. Every one of these
calculations are composed in Map-Reduce
worldview.Specifically, we tried Mahout
calculations against our information sources, for
example, PTMD datasets, test cells, and others.
One of our examinations was to test Mahout
K-Means for the PTMD information. Points of
interest are informed in the accompanying. One of
the models we need to manufacture is a pattern
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 553 as an element of the APU age (e.g., flightpath’s,
and so forth.), by utilizing the PTMD information.
We trust this the flight.TAT is an irregular
annoyance to this model.
Our underlying advances include:
(1) Mahout Vectors are changed over as a Hadoop
grouping record, by utilizing subdirectory
instrument to change over content document into a
Hadoop arrangement petition for Mahout to run;
(2) highlight vectors are made with three
measurements,
(3) RandomSparseAccess vector is utilized for
vectorizing the information, and
(4) the reasonable arrangement record is spared in
Hadoop. In fact, we
(a) got 17 information documents from our HDFS;
(b) vectorized the information (for making Mahout
to comprehend the information):
• parsed estimations of assortment, mesone.EGTA
and algout.EGT_MARGIN from the information
records
• took normal of the qualities, since every one of
this parameter has a variety of twofold qualities.
• predated include vectors with 3
measurements.RandomSparseAccessvector was
utilized for vectorizing the information
• cleared in Hadoop justifiable grouping record(c)
distinguished starting bunches – K-Means
commands speculating introductory centroids.
Since the datasets have 17 records, we speculated
only two centroids(d) ran the K-Means calculation – utilizing joining delta as 0.0001, number of
emphases as 10, and bunch arrangement edge as
0.5. We got the aftereffect of two arrangements; 5
documents fall under the characterization "1" and
remaining 12 in grouping "0" effectively. Our
future work and errands will incorporate the
accompanying regions:
Classification: anticipating a class, e.g., discrete,
limited qualities with no requesting Regression:
foreseeing a numeric amount, e.g., consistent,
limitless qualities with requesting.
With our information sources (e.g. PTMD, and so
on.), we will assess and select the best of the ML
calculations, including Linear Regression, Logistic
Regression, Linear and Logistic Regression with
regularization, Neural Networks, Support Vector
Machine, Naive Bayes, Nearest Neighbour,
Decision Tree, Random Forest, and Gradient
Boosted Trees. Moreover, we have additionally
tried surely understood open source ML
apparatuses, for example, Rapid Miner and Weka.
Albeit Rapid Miner and Weka are not intended for
distributed computing and enormous information
investigation, we have tried them keeping in mind
the end goal to assess and select the most ideal ML
calculations for our CBM applications.
V. CONCLUSIONS
In this paper, our cloud-based ML system is
produced by utilizing Apache Hadoop,
MapReduce, HBase, and others in Apache
biological system. Mahout Machine learning
calculations are coordinated with this system
keeping in mind the end goal to dissect genuine
word information sources from Honeywell motors,
assistant power units (APUs), line replaceable units
(LRUs), and numerous different items. We found
that distributed computing instruments: Apache
Hadoop, MapReduce, and cloud programming
OpenStack or Eucalyptus, can be utilized to create
cloud-based examination devices for different
ventures including aviation and assembling
merchants, with a specific end goal to give huge
information investigation abilities. They can
supplement conventional RDBMS and examination
advances that are as of now useful for various
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 554 forth.). Our future work will centre around
assessing and enhancing more ML calculations for
particular errands and datasets. Significantly more
information will be gotten tied up with our cloud
and broke down by our huge information
investigation devices utilizing our best machine
learning calculations all the more adequately and
productively.
REFERENCES
[1] D. Bailey and E. Wright, Practical SCADA for
industry. Newnes, 2003.
[2] O. Sporns and G. Tononi, “Classes of network connectivity and dynamics,” in Complexity, vol. 7,
pp. 28–38, 2001.
[3] M. van de Wal and B. de Jager, “Control structure design: a survey,” in Proceedings of the
1995 American Control Conference, vol. 1, pp.
225–229 vol.1, Jun 1995.
[4] L. Atzori, A. Iera, and G. Morabito, “The internet of things: A survey,” Computer networks,
vol. 54, no. 15, pp. 2787–2805, 2010.
[5] S. Skogestad, “Plantwide control: the search for
the self-optimizing control structure,” Journal of
Process Control, vol. 10, pp. 487–507, October
2000.
[6] W. L. Luyben, B. D. Tyreus, and M. L.
Luyben, Plant-wide process control. McGraw-Hill,
1998.
[7] F. Bonomi, R. Milito, J. Zhu, and S. Addepalli, “Fog computing and its role in the internet of things,” in Proceedings of the first edition of the
MCC workshop on Mobile cloud computing, pp.
13–16, ACM, 2012.
[8] T. White, Hadoop: The definitive guide. ” O’Reilly Media, Inc.”, 2012.
[9] M. Zaharia, M. Chowdhury, M. J. Franklin, S. Shenker, and I. Stoica, “Spark: Cluster computing with working sets.,” HotCloud, vol. 10, no. 10-10,
p. 95, 2010.
[10] J. Allaire, “Rstudio: Integrated development environment for r,” Boston, MA, 2012.
[11] X. Meng, J. Bradley, B. Yavuz, E. Sparks, S.
Venkataraman, D. Liu, J. Freeman, D. Tsai, M. Amde, S. Owen, et al., “Mllib: Machine learning in apache spark,” Journal of Machine Learning
Research, vol. 17, no. 34, pp. 1–7, 2016. [12] N.
Garg, Apache Kafka. Packt Publishing Ltd, 2013.
[13] H. S. Ko, J.-S. Kim, T.-W. Yoon, M. Lim, D. R. Yang, and I. S. Jun, “Modeling and predictive control of a reheating furnace,” in American
Control Conference, 2000. Proceedings of the
2000, vol. 4, pp. 2725– 2729, IEEE, 2000.
[14] B. Leden, “A control system for fuel optimization of reheating furnaces,” Scand. J.
Metall., vol. 15, no. 1, pp. 16–24, 1986.
[15] J. Srisertpol, S. Tantrairatn, P. Tragrunwong, and V. Khomphis, “Estimation of the mathematical
model of the reheating furnace walking hearth type in heating curve up process,”.
AUTHOR'S :
Sravan Kumar Vulchi has completed his B.E. in Electronics and Communications Engineering in 2002 from University of Mysore. He is pursuing his M.Tech in Computer Science & Engineering in GVVR Institute of Technology at Bhimavaram, affiliated to JNT University Kakinada. He is working on his thesis "Combining Supervised and Unsupervised Learning" under the
supervision of Dr.K.S.N.Prasad and
Dr.Venugopala Rao Manneni. His passion towards Artificial Intelligence and Softcomputing inspired him to focus towards research field. He is having an experience of 12+ yrs in Software Industry with emphasis on Business / Artificial Intelligence, Deep Learning and Distributed Scalable Machine Learning, Neural networks,
Available online: https://edupediapublications.org/journals/index.php/IJR/ P a g e | 555
regression models, Bayesian networks,
Collaborative Filtering, Feature
selection/regularization, Boosting Methodologies, Numerical and Monte Carlo Approximation, Data
Visualization, Advanced Implementations of
Operator Algebras, Probability Theory and Statistics.
Research Interests:
Neural Network Learning Algorithms.
Data Mining with Biometric and Medical
Applications.
Design of a Semi-Supervised Neuro-fuzzy
systems.
Ensemble Learning of Classifiers.
Optimization of softcomputing
frameworks.
Binary Neural Network Learning with
Quantum Processing.
Softcomputing Techniques based
Classifiers (which includes Neural
Network Learning Algorithms, Genetic Programming, Support vector machine, Fuzzy sets, Rough sets etc.)
Society Memberships:
Institute of Electrical and Electronics
Engineers (IEEE).
Indian Society of Analytical Scientists - Hyderabad Chapter, CSIR-Indian Institute of Chemical Technology.
Janardhana JNSS is an Asst. Professor in the Computer Science & Engineering department in
Swarnandhra College of Engineering and
Technology at Narsapur, Autonomous College under JNT University Kakinada. He received his M.Tech. degree in Sathyabama Institute of Science and Technology, deemed to be University, Chennai. His research (aspirations) and teaching activities focuses on Data Mining and enabling the combination of Big Data and Cloud Computing. His passion towards Artificial Intelligence and Soft Computing inspired him to focus towards research field.
Research Interests:
Neural Network Learning Algorithms.
Data Mining
Big Data