ACHARYA, MITHUN PUTHIGE. Mining API Specifications from Source Code for Improving Software Reliability. (Under the direction of Dr. Tao Xie).
A software system interacts with third-party libraries through various Application Pro-gram Interfaces (APIs). Using these APIs correctly often needs to follow certain proPro-gramming rules, i.e., API specifications. API specifications specify the required checks (on API input parameters and return values) and other APIs to be invoked before (preconditions) and after (postconditions) an API call. Incorrect usage of APIs (in short, API violations) can lead to security and robustness problems, two primary hindrances for the reliable operation of a software system. Hence, for a software sys-tem, adherence to the specifications, which govern the correct usage of APIs used by the syssys-tem, is paramount for software reliability.
Specifications, when known, can be formally written for third-party APIs and statically verified against a software system. This dissertation addresses two main problems faced by pro-grammers in effectively and correctly reusing third-party APIs. (1) Formal API specifications are complicated and lengthy mainly due to the various API details (such as input/return type, error-flag codes, and return values for APIs on success/failure) and language-specific syntax considerations required for the specification to be accurate and complete. Hence, manually writing a large number of formal API specifications, when known, for static verification is often inaccurate or incomplete, apart from being cumbersome. (2) API specifications are not well documented by the API de-velopers and are often not known to programmers who reuse third-party APIs in the first place. API specifications cut across procedural boundaries and an attempt to infer these specifications by manual inspection of source code (API client code) is often inefficient and inaccurate.
we then present novel applications of data mining techniques on the generated static traces for specification mining. Our approach allows mining of software systems that reuse APIs without requiring environment setup for system executions or availability of sufficiently high-quality system tests. We apply our trace mining approach on several popular open-source packages to mine API specifications and detect violations, without requiring any user input.
by
Mithun Puthige Acharya
A dissertation submitted to the Graduate Faculty of North Carolina State University
in partial fulfillment of the requirements for the Degree of
Doctor of Philosophy
Computer Science
Raleigh, North Carolina
2009
APPROVED BY:
Dr. Douglas Reeves Dr. David Thuente
Dr. Tao Xie Dr. Helen Gu
DEDICATION
BIOGRAPHY
ACKNOWLEDGMENTS
First, I thank my advisor, Tao Xie, for his technical guidance and financial support. His professional advice over the years, from useful tips on better technical writing and effective pre-sentation to career guidance, will continue to benefit me in my future career. Heartfelt gratitude to David Thuente, without whom my doctoral program was an impossibility. He is a great mentor and was a constant source of encouragement throughout my stay at NC State. I thank Helen Gu, Dou-glas Reeves, and David Thuente for serving on my dissertation committee and providing valuable feedback on my dissertation research.
I thank my internship mentors in the industry, who have immensely helped me expand my research to a broader scope: Dirk Westhoff and Joao Girao (NEC Europe Network Laboratories), Peri Tarr, Tim Klinger, Rosario Uceda-Sosa, and Peter Santhanam (IBM T. J. Watson Research Center), Vamshidhar Kommineni and Hunter Hudson (Microsoft Center for Software Excellence), and Corina Pasareanu (Java PathFinder team at NASA Ames Research). I thank Vamshidhar Kom-mineni, Peri Tarr, David Thuente, Dirk Westhoff, and Tao Xie for writing recommendation letters supporting my summer internship and full-time job applications.
I would like to gratefully acknowledge researchers who generously shared their research tools and results used in my dissertation. I thank Hao Chen (UC Davis) and David Wagner (UC Berkeley) for their MOPS push-down model checker, Glenn Ammons (IBM T. J. Watson Research Center) for sharing his results on dynamic specification mining, Jian Pei (Simon Fraser University, Canada) for providing his partial-order miner tool Frecpo, and Jianyong Wang and Jiawei Han (University of Illinois at Urbana Champagne) for their BIDE sequence mining tool. I also thank GrammaTech Inc. and its technical support team, especially Fletcher Hirtle, for providing their CodeSurfer static analysis tool. Gratitude to Jun Xu (Google), who guided my dissertation research during my first year, and Tanu Sharma, for her contributions to the results presented in Chapter 2 of this dissertation. I thank all my peers at the Automated Software Engineering group, Tao Xie’s research group at NC State of which I am very proud to be a part of, for their continuous and useful feedback on my research.
TABLE OF CONTENTS
LIST OF FIGURES . . . . viii
1 Introduction . . . . 1
1.1 Motivation . . . 1
1.2 Problems . . . 2
1.3 Solution Overview . . . 3
1.4 Contributions . . . 4
1.5 Scope . . . 5
1.6 Outline . . . 6
2 Generic Specifications for Static Verification . . . . 7
2.1 Introduction . . . 7
2.2 Approach . . . 9
2.2.1 API Details . . . 10
2.2.2 Generic Robustness Specifications . . . 11
2.2.3 API Database . . . 11
2.2.4 Pattern Database . . . 12
2.2.5 Generation of Formal Specifications . . . 13
2.3 Application of our Approach on POSIX APIs . . . 13
2.3.1 API Database for POSIX APIs . . . 14
2.3.2 Pattern Database for C . . . 16
2.3.3 Generic POSIX API Specifications . . . 17
2.3.4 Generation of Formal POSIX API Specifications . . . 17
2.4 Evaluation . . . 18
2.5 Discussion . . . 24
3 Static Trace Generation for Mining Specifications . . . . 25
3.1 Introduction . . . 25
3.2 Example . . . 27
3.3 Approach . . . 29
3.3.1 Partial and Total Order . . . 29
3.3.2 Frequent Closed Partial Orders (FCPO) . . . 30
3.3.3 Formalizing FCPO Mining from Program Traces . . . 31
3.3.4 Trace Generation . . . 32
3.3.5 Scenario Extraction . . . 34
3.3.6 Specification Mining . . . 35
3.3.7 Complexity . . . 36
3.4 Implementation . . . 37
3.6 Discussion . . . 41
4 Adapting Static Trace Generation for Mining API Error-Handling Specifications . . 49
4.1 Introduction . . . 49
4.2 Example . . . 51
4.3 Approach . . . 56
4.3.1 Error/Normal Trace Generation . . . 57
4.3.2 Specification Mining . . . 59
4.3.3 Verification . . . 60
4.4 Evaluation . . . 60
4.5 Discussion . . . 65
5 Mining API Specifications: An Empirical Perspective . . . . 69
5.1 Introduction . . . 69
5.2 Terminologies . . . 72
5.3 Preliminary Study . . . 74
5.4 Adapting Specification Mining and Violation Detection . . . 76
5.4.1 Specification Miner . . . 76
5.4.2 Violation Detector . . . 79
5.5 Evaluation . . . 81
5.6 Discussion . . . 83
6 Related Work . . . . 84
6.1 Robustness Testing . . . 84
6.2 Static Verification . . . 85
6.3 Static Specification Mining . . . 86
6.4 Dynamic Specification Mining . . . 88
6.5 Analyzing API Implementation Code . . . 89
7 Assessment and Conclusions . . . . 90
7.1 Summary of Contributions . . . 90
7.2 Lessons Learned and Future Work . . . 91
LIST OF FIGURES
Figure 2.1 Our approach for generating formal specifications . . . 9
Figure 2.2 Action patterns . . . 11
Figure 2.3 “checkshould always precedeuse” generic specification . . . 12
Figure 2.4 API classification based on return values . . . 15
Figure 2.5 Selected entries from POSIX API database (simplified for presentation) . . . 16
Figure 2.6 Formal UseBeforeCheck specification for the malloc API . . . . 18
Figure 2.7 malloc UseBeforeCheck violations in vixie-cron package . . . . 19
Figure 2.8 Simplified formal specification for the malloc API . . . . 21
Figure 2.9 Robustness violations detected in the analyzed open-source packages . . . 22
Figure 2.10 API violations across all analyzed packages . . . 23
Figure 2.11 malloc and setuid violations in all analyzed packages . . . . 23
Figure 3.1 A simple example illustrating our approach for mining partial orders from static traces . . . 42
Figure 3.2 A partial order and its transitive reduction . . . 43
Figure 3.3 Four ordersR1 ⊃R2 ⊃R3⊃R4. . . 43
Figure 3.4 Our approach for mining usage scenarios and specifications . . . 44
Figure 3.5 A property FSM where end1 and end2 are final states . . . 44
Figure 3.6 Trigger FSM that accepts the regular languagee(a1+a2+...+ak)∗x. . . 45
Figure 3.7 Scenario extraction example . . . 45
Figure 3.8 X11 client programs used in our evaluation . . . 46
Figure 3.10 Trigger used to generate function calls, APIs, and expressions related to
XCre-ateGC . . . . 46
Figure 3.11 Statistics for the specifications mined by our approach . . . 47
Figure 3.12 Statistics for the specifications mined around XOpenDisplay . . . . 47
Figure 3.13 A usage scenario around XOpenDisplay API as a partial order. Lower support values produce larger partial orders. Higher support values produce smaller partial orders (specifications). Specifications are shown with dotted lines. . . 48
Figure 4.1 Acronyms and definitions . . . 52
Figure 4.2 Code snippet from routed-0.17-14 . . . . 53
Figure 4.3 Code snippet from x11perf-R6.9.0 . . . . 54
Figure 4.4 Our approach for mining API error-handling specifications . . . 66
Figure 4.5 The algorithm for mining API error-handling specifications . . . 67
Figure 4.6 Evaluation results . . . 68
Figure 4.7 Multiple-API specifications for the clean up API XFree mined by our approach 68 Figure 5.1 Example code snippet and the corresponding CFG . . . 77
Figure 5.2 seals(c, P, E)in the violation detection algorithm (Algorithm 3) realized as an existence path-query (depicted as a Finite State Machine) . . . 81
Chapter 1
Introduction
1.1
Motivation
As computers penetrate every aspect of our daily life, reliability of software systems is becoming increasingly important. Software reliability is the probability of failure-free software operation for a specified period of time in a specified environment [1]. A software system inter-acts with its environment (memory, graphics card, network, operating system, other software, etc.) through Application Program Interfaces (APIs1). Using these APIs correctly often needs to follow certain programming rules, i.e., API specifications.
We identify two types of API specifications – preconditions and postconditions2. Precon-ditions for a given API specify the conPrecon-ditions required before the API is invoked. PreconPrecon-ditions specify the required conditional checks on API input parameters and other APIs to be invoked be-fore invoking the API. For example, the POSIX standard [2] states that the first parameter of the
bindAPI, the socket identifier, should come from thesocket API and should be non-negative. Postconditions for a given API specify the conditions required after the API is invoked. Postcon-ditions specify the required conditional checks on API return values and other APIs to be invoked after invoking the API. For example, the return value of thebindAPI should be non-negative and
1We overload the term API to mean both a set of related library procedures or a single library procedure in the set – the actual meaning should be evident from the context.
the socket identifier should beclosed along all paths. Postconditions also specify the correct han-dling of errors incurred after API invocations. Incorrect usage of APIs (in short, API violations) can lead to security and robustness problems [3], two primary hindrances for the reliable operation of a software system. Hence, for a software system, adherence to the specifications, which govern the correct usage of APIs used by the system to interact with its environment, is paramount for software reliability. Software testing [4, 5], and more recently, static verification [6–10] have been adopted by the industry to assure software reliability. However, there are several problems with these approaches, which are described next.
1.2
Problems
Software testing approaches [11–19] typically focus on issues such as correctness of func-tionality and performance and is often insufficient for assuring the absence of API violations. Most of these approaches consider a target software system as a black box and conduct testing with ran-dom or extreme input values. However, black-box testing approaches cannot easily generate values for testing such as incorrect input values and error return values for APIs.
Specifications, when known, can be formally written for third-party APIs and statically verified against a software system. The last decade has witnessed great advances in assuring high software reliability through static verification [10, 20–27]. However, there are two main problems, in successfully employing static verification in the software development cycle:
• Formal API specifications are complicated and lengthy mainly due to the various API details (such as input/return type, error-flag codes, and return values for APIs on success/failure) and language-specific syntax considerations required for the specifications to be accurate and complete. Hence, manually writing a large number of formal API specifications, when known, for static verification is often inaccurate or incomplete, apart from being cumbersome.
• API specifications are not well documented by the API developers and are often not known to programmers who reuse third-party APIs in the first place. API specifications cut across procedural boundaries and an attempt to infer these specifications by manual inspection of source code (API client code that uses the APIs) is often inefficient and inaccurate.
stat-ically, described in Section 3.2 in detail). Different from these approaches, our framework mines properties from source code of API clients. The practical applications of dynamic approaches in mining specifications are limited by the requirement of sufficiently high-quality system tests to ex-ercise various API behaviors comprehensively. Hence, the API violations in the analyzed programs might not be easily exposed. Furthermore, dynamic approaches require setup of costly runtime environments and test harnesses, not required by our framework.
1.3
Solution Overview
This dissertation proposes a novel framework to address the aforementioned problems faced by programmers in reusing third-party APIs. Our framework comprises related approaches to aid programmers in constructing API specifications for static verification.
When API specifications are known, to encourage the use of formal verification in the software development cycle, we present an approach to automatically construct formal API speci-fications for static verification from a few generic, user-specified specification templates [31]. Our approach allows specifying API specifications as templates at an abstract level that needs no knowl-edge of any language-specific syntax or API details. The templates support various patterns such as precedence (amuch precedeb) and response (amust followb), which are needed to represent API specifications. These generic, user-specified templates are then translated by our approach into con-crete, formal specifications, which can be directly used by static verifiers to verify API client code for API violations. The translation uses information about API details, provided by API developers, and language-specific syntax, provided in the form of Abstract Syntax Tree (AST) notation, with a one-time effort.
API call sites and their corresponding pre/postcondition enforcement points, the trace generation should be path-sensitive (at conditional branches, the trace generation should depend on the branch predicate). Finally, for mining API error-handling (proper handling of errors incurred after API invocation) specifications, the static trace generation and mining should be adapted to take into ac-count the fact that programmers often make mistakes in error-handling code [32–35]. Hence, we need techniques to generate and distinguish error traces (i.e., static traces with API errors along API error paths) and normal traces (i.e., static traces, without API errors), even when the API error behaviors are not known a priori. To generate static traces related to APIs of interest, we adapt push-down model checking [21], meeting the preceding requirements. We then present novel ap-plications of data mining techniques on the generated static traces for specification mining. We apply our approach on several popular open-source packages to mine API specifications and detect violations, without requiring any user input.
1.4
Contributions
This dissertation makes the following main contributions:
• We propose an approach for effectively generating formal API specifications from a few generic, high-level, user-specified specification templates, which are free from language-specific syntax and API details. We implement our approach and apply it to the the well known POSIX APIs for verifying robustness specifications in several open-source applica-tions. Approximately, 1,000 formal specifications (>30,000 lines) were generated from 6 generic templates (<60 lines) for 280 POSIX APIs, highlighting the effectiveness of our ap-proach. We statically check 10Redhat-9.0packages (52 KLOC) against the generated for-mal robustness specifications by using an existing static verifier with our basic path-sensitivity extensions and detect 188 robustness violations in the analyzed packages.
basic data-flow extensions, and compare our approach with an existing dynamic specification-mining approach [28] in specification-mining X11 API specifications fromX11-R6.9.0distribution (208 KLOC).
• We adapt our trace generation approach to mine API error-handling specifications and detect API error-handling violations in 10 packages from theRedhat-9.0distribution (52 KLOC),
postfix-2.0.16(111 KLOC), andX11-R6.9.0distribution (208 KLOC). Our approach mines 62 error-handling specifications and detects 264 real error-handling defects from the analyzed packages.
• We conduct an empirical analysis of the characteristics of API specifications in practice (on four popular and large open source packages:gnuplot-4.0.0(91 KLOC),postfix-2.0.16 (111 KLOC),postgresql-7.3.20 (483 KLOC), andgcc-3.4.3(1.5 MLOC)), such as the distance (in terms of call graph edges, described in Section 5.2) of pre/postcondition en-forcement points in a program to their corresponding call sites and the extent of aliasing be-tween these points and call sites (involving API input parameters and return values). We con-firm our observations by studying the API specification characteristics among pre/postcondition-related bug fixes in a large and popular package (Mozilla) and the specifications and viola-tions discovered by an existing static specification-mining approach [36]. These characteris-tics, as we demonstrate, have implications on the cost and precision of the inter-procedural and alias analysis required for the specification mining and violation detection algorithms, and hence, on the scalability and the false-positive rate of the algorithms.
1.5
Scope
non-compilable, and incomplete code examples found on the web, our framework requires that the analyzed API client code is compilable and complete. An advantage of analyzing complete code is the availability of precise and inter-procedural information for specification mining and violation detection. However, a limitation of our framework surfaces when there are insufficient call sites for a given API in the analyzed source code. In such cases, we plan to explore how our framework can be complemented by approaches such asPARSEWeb[40], whose mining scope spans open-source code found in the web. Our trace mining approach does not mine iterative patterns [41] among API specifications. However, as we demonstrate in this dissertation, the non-iterative specifications (which can be represented using a Finite State Machine) [36, 42–47] that we mine are still very significant and so are their violations. Finally, like all static specification-mining approaches, we assume that the programmers correctly adhere to the API specifications in the analyzed programs most of the time and that the frequently occurring API patterns are very likely correct.
1.6
Outline
Chapter 2
Generic Specifications for Static
Verification
2.1
Introduction
The IEEE Standard Glossary of Software Engineering Terminology (IEEE STD 610.12-1990) [49] defines robustness as the “degree to which a system or a component can function cor-rectly in the presence of invalid inputs or stressful environment conditions.” Stressful environment conditions may occur in forms such as high computation load, memory exhaustion, process-related failures, network failures, file-system failures, and slow system response. These problems, how-ever rare, should be gracefully handled. Failure to adhere to robustness specifications might lead to undesirable consequences such as program crashes.
Traditional software testing focuses on correctness of functionality and is often insuffi-cient for assuring the absence of API robustness violations. Robustness testing has been especially conducted to test the robustness of a system. The Fuzz project [11–13] tested the robustness of UNIX utilities by generating random input streams. The Ballista project [14–16] uses extreme in-put parameter values to test the robustness of applications. Approaches [17–19] similar to Ballista have been applied for robustness testing of system libraries in Microsoft Windows. These existing approaches consider the target applications as a black box, and send random or exceptional input values for testing.
However, black-box testing approaches cannot easily generate values for testing such as incorrect input values and error return values for APIs automatically. To assure the absence of robustness problems related to APIs, we can manually specify robustness specifications and stati-cally verify them against a software system. However, manually specifying a large number of API robustness specifications for static verification is often inaccurate or incomplete, apart from being cumbersome.
The rest of this chapter is organized as follows. Section 2.2 presents our approach for generating formal robustness specifications. Section 2.3 illustrates the application of our approach on POSIX APIs. Section 2.4 presents our evaluation results on checking 10Redhat-9.0packages against the generated robustness specifications. Section 2.5 discusses limitations of our approach.
2.2
Approach
This section introduces our approach for generating formal API robustness specifications for static verification. The goal of our approach is to allow users to write generic robustness spec-ifications without the knowledge of the system, language, and API details. To abstract away these details from the users, we make use of two key observations about APIs and their robustness specifi-cations. The first observation is that related APIs have similar structural elements when specified at a certain abstraction level. The second observation is that most API robustness specifications can be specified as temporal orderings of certain actions that can be performed on an API or its elements.
API-DB AST-DB specEngine api status check result use called checked error
start api status
check result use called checked error start called checked error start p=malloc()
p != null !p
p == null
*p p[] p->x
called checked
error start p=malloc()
p != null !p
p == null
*p p[] p->x
called checked
error start p=malloc()
p != null !p
p == null
*p p[] p->x
called checked
error start p=malloc()
p != null !p
p == null
*p p[] p->x
called checked
error start p=malloc()
p != null !p
p == null
*p p[] p->x
called checked
error start p=malloc()
p != null !p
p == null
*p p[] p->x
Generic Specification Formal Specification
API details
AST patterns
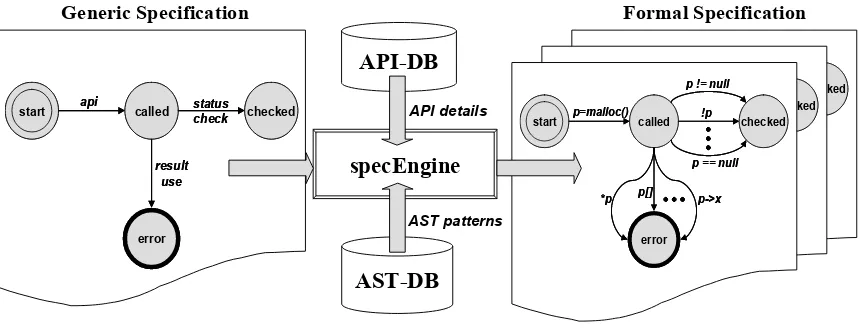
Figure 2.1: Our approach for generating formal specifications
programming-language-specific information. In the subsequent subsections, we identify the ele-ments and actions that characterize an API and show how generic templates are defined and formal specifications are derived from them.
2.2.1 API Details
APIs implemented for a specific purpose have similar structural details at a high level. We characterize an API with its structural elements (such as input parameters or returns) and actions that can be performed on them (such as checking an API’s return value for failure). The characterization allows us to systematically store the API details and language-specific patterns for these APIs in a database. For a given API, thespecEnginecan query the database on the keywords of elements or actions to get the low-level API details.
For any APIi∈ I, whereIis a related family of APIs, we define API details asdet(i) = {is(i), rs(i), ss(i),R,S,Z}, whereis(i)is the set of input parameters passed to the invocation of i,rs(i)is the result set, the set of variables that store the return values of API invocation andss(i)
is the status set, the set of variables that store the failure status or type of failures of the API. Any variablev∈is(i)Srs(i)Sss(i)is called the element ofi.Ris a mapping fromrs(i)toZ, while S is a mapping fromss(i)toZ, whereZholds the values that members ofrs(i)andss(i)would assume on success or failure of API invocation. In setZ, for convenience, we assume that success values precede failure values. For a related family of APIs,I, we define an actionset as a set of actions that can be performed on the API itself or its elements.
2.2.2 Generic Robustness Specifications
Generic specifications for an APIi∈ Iare defined over the members of theactionset of I as templates. A generic specification is some ordering constraints on the members of theaction set. We use the template representation given by Dwyer et al. [31] (shown in Figure 2.2) to represent generic specifications. In the figure,AandBare considered to be API actions.
Property Patterns
Occurrence: Occurrence of a given action during system execution Absence: No A in scope
Universality: A throughout scope Existence: A must occur in scope
Bounded Existence: A occurs k times in scope Order: Relative order of actions during system execution
Precedence: A must precede B Response: A must follow B
Chain Precedence: mA’s should precede nB’s; m, n 0 Chain Response: mA’s should follow nB’s; m, n 0
Figure 2.2: Action patterns
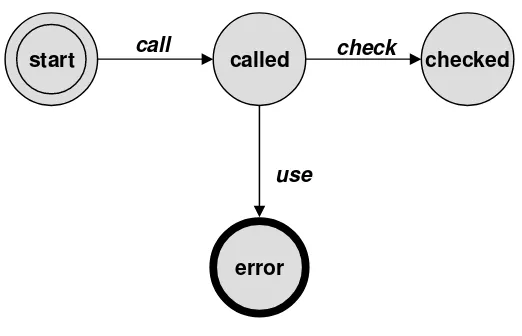
Most robustness specifications of interest can be typically specified using temporal logic or regular expressions. We do not consider specifications defined by templates such as Chain Prece-dence (m A’s should be followed byn B’s,m, n ≥0) that cannot be represented using a regular expression. We use a Finite State Machine (FSM) to graphically represent a generic specification. An FSM has a start state and an error state as well as other user-defined states. A sequence of ac-tions that violates the robustness specification represented by the FSM takes the FSM to the error state. The edges of the FSM are members from theactionset. For example, for themallocAPI, thecheckaction should always precede theuseaction. The FSM for such a specification is shown in Figure 2.3. Generic robustness specifications are specified by the users.
2.2.3 API Database
call check
use
called checked
error start
Figure 2.3: “checkshould always precedeuse” generic specification
the type of its input parameters asint, the return values to be 1 on success and -1 on failure, and the error flag to be set asEPERMon failure. The content in theAPI-DBis specified by the users.
2.2.4 Pattern Database
The pattern database (AST-DB) contains language-specific patterns, which can be ob-tained from the language’s grammar, of the elements for all i ∈ I and actions in the action set ofI. We use the Abstract Syntax Tree (AST) notation for storing patterns. The patterns for the useaction depend on the data type of the return value and the patterns for the checkaction de-pend both on the data type of the return and the success/failure indicator/type. TheAST-DBstores patterns for all members of theactionset for each data type, success/failure indicators, etc. As an example, the patterns for thecheckaction againstzerofor an integer variablepwould be(p==0), (p!=0),(p),(!p), and so on. The call patterns for themallocAPI would bei=malloc(...), if(i=malloc(...))!=NULL, and so on.
2.2.5 Generation of Formal Specifications
The user-specified generic robustness specifications are abstract and cannot be directly used by a static verifier. ThespecEngineparses a user-specified generic specification to extract the generic keywords. To generate the formal specification, thespecEnginequeries theAPI-DB to get the API details (such as input parameters and return types). These API details along with the generic keywords are sent by thespecEngineas a query to theAST-DB. TheAST-DBresponds back with corresponding patterns. The specEngine then translates the generic specification to formal specification by instantiating the extracted generic keywords and adding new states and edges to the FSM representing the generic specification. The formal specification can then be used by a static verifier to verify packages for robustness violations.
As an example, we apply the generic specification shown in Figure 2.3 to the malloc API. One of the generic keyword returned by the generic-specification parser in thespecEngine ischeck. To generate formal specification for themallocAPI,specEnginequeries theAPI-DB to obtain details about themallocAPI and learns that the return type of mallocis a pointer on success andNULLon failure. Based on this information, thespecEngineconstructs a query (to the AST-DB) that comprises the keywordcheck, the data type of the return variable, and values on success and failure (being a pointer in this case). TheAST-DBprocesses this query and returns patterns for all the possible ways a pointer variable can be checked againstNULL(or notNULL). The
specEngineinstantiates the generic keywordcheckwith language and API-specific patterns. The same procedure applies to the keyworduse.
2.3
Application of our Approach on POSIX APIs
UseBeforeCheck: A variable that holds the return value of themallocAPI call, which returns a memory pointer on success and aNULLpointer on failure, should always be checked before use or dereferencing.
2.3.1 API Database for POSIX APIs
We inspected 280 POSIX APIs to arrive at a common abstraction to characterize all these APIs. We defined the types for the variables in the sets ofis(i),rs(i), andss(i). We established the mappingsRandS, and the setZfor each of the 280 POSIX APIs. For an APIithat sets error flags on failure, the global variableerrno ∈ ss(i). The corresponding error status, if any, resides inZ. For example, if the APIsetuidfails, thenerrno ∈ss(setuid)is set toEPERM∈ Z. APIs have different return values on success and failure, error flag values, proper checking routines, and correct usage rules. Figure 2.4, for instance, classifies the 280 POSIX APIs into 11 classes based on their return values. For example,closedirbelongs to the class 0 : −1, which means that it returns 0on success and−1on failure. mallocbelongs to the classp : np, which means that it returns a pointer (p) on success and aNULLpointer (np) on failure. The values returned on success are shown to the left of “:” and values returned on failure are shown to the right of “:”. It is possible for an API to return different values on success. xrepresents any positive value. For example, the APIftellreturns the current file offset, denoted byx.
The action set for the POSIX APIs comprisesalias, call, check, F ALSE, f ailure, f ree,pass,return,success,T RU E, anduse. The meanings of the actions are self-evident. For
example, whenever a return variable is aliased, the action performed onv∈rs(i)(the return value of the API invocation) isalias. The action of invoking the API iscall. The action of checking the API return value or status against members inZischeck. Ifcheckfails, the action isF ALSE(for example, if the checkp==NULLfails, the action isF ALSE andpassumes non-NULLvalue). The API invocation can either be af ailureorsuccess. When the return variable is passed to another function, apass action is said to be performed. When the function in which the API is invoked returns, the action performed isreturn. Ifchecksucceeds, the action isT RU E. Finally, when the return value is used in program expressions, the action isuse. Details for each of the actions and elements are stored inAST-DB(to be discussed in the next section).
No. API class Sub-classes Examples
0:-1 closedir
x, 0:-1 mblen
I 0:-1
fd, flag, fd_owner, signal, 0:-1 fcntl
-1, 1, 0:-1 sysconf
II 0, 1, -1:-1
1, 0:-1 readdir
0:EOF fflush
x, 0:EOF scanf
III 0:EOF
0:EOF, undefined fclose
0:x ttyname_r
x, 0:0 strftime
x, 0:: isupper
0:0 sem_wait
0:any_number setvbuf
0, non_zero : 0, non_zero setjmp
second, 0:: alarm
IV 0:x
x, p, 0:-x, 0 strtod
V 1,0:: 1, 0:: isatty
VI np, -1, 0, x:np, -1, 0, x np, -1, 0, x:np, -1, 0, x wctomb
p:np malloc
p, np:p, np strtok
VII p:np
p, np:np realloc
x:-1 ftell
::-1 feof
no_return:-1 execve
VIII x:-1
x, -1:-1 pathconf
IX x:EOF x:EOF putchar
X x, EOF:np x, EOF:np getchar
XI x:negative x:negative printf
input, output, and error details for all the POSIX APIs. The entries in the database show the input parameters for the API call, return value types, status on success/failure, and the different error flags set on failures. We built theAPI-DBdatabase for 280 POSIX APIs manually by inspecting the UNIX manual pages. The database can be used by our approach as well as other research projects. Similar databases can be built for different API families.
return value
API parameter list return
type on success on failure errno
chmod const char * path , … int 0 -1 EPERM, …
open const char * pathname, … int fd -1 EEXIST, …
malloc size_t size void * pointer null pointer
fsetpos FILE * stream , … int 0 -1 EBADF, …
remove const char * pathname int 0 -1 EFAULT, …
Figure 2.5: Selected entries from POSIX API database (simplified for presentation)
Given an API, the specEnginequeries the API-DBto get the API’s input, output and error details in a standard format. For example, for themallocAPI, when thespecEnginequeries theAPI-DBto get the details, theAPI-DBwould inform thespecEnginethat themallocAPI call accepts size information (size t), which is of the integer type. It also informs that themallocAPI returns a pointer on success andNULLpointer on failure. No error flag is set in this case.
2.3.2 Pattern Database for C
The abstract keywords (e.g., check and use) on FSM edges bear no language-level se-mantic. A static verifier needs concrete source-code level information for these transitions in order to check them. The static verifier works at the Abstract Syntax Tree (AST) level. We specify the language-level semantics for these abstract API elements and actions using AST patterns. The
For the UseBeforeCheck example, the malloc API call returns a memory pointer on success and aNULLpointer on failure. Assume that the return value of themalloccall is stored in a pointer variable p. Because the failure value is NULL, check of the failure status means a comparison ofpwith theNULLvalue. InC, a pointer variable can be compared toNULLin different ways such as(p == NULL),(!p),(p),(p != NULL), and so on. When queried using the check keyword and theNULL-pointer type, theAST-DBreturns all possible patterns for checking aNULL -pointer. Similarly, because the return value is a memory pointer, the use ofpcan be in the forms p->x,*p,p[x], and so on. TheAST-DBcan also be instantiated to other languages such as C++ and Java.
2.3.3 Generic POSIX API Specifications
Once the API elements and actions are characterized in theAPI-DBand source-code-level details provided for them in theAST-DB, generic specifications can be specified by the user using the templates proposed by Dwyer et al. [31]. The simple FSM shown in Figure 2.3 for UseBeforeCheck has a transition from the initial start state to called state, whenever a particular API is called. For the UseBeforeCheck generic specification, the generic state checked (which indicates the presence of an error-handling routine) is a safe state whereas error is a violation state. The keywords used in specifying the generic specifications are abstract in that they hide the API and source-code-level details from the user.
2.3.4 Generation of Formal POSIX API Specifications
A generic specification is too abstract to be used by a static verifier, which requires lan-guage and API-level details in the specification for checking. Given a generic specification, the
called checked
error
start p=malloc()
p != null
!p
p == null
*p p[ ] p->x
Figure 2.6: Formal UseBeforeCheck specification for the malloc API
of the return variable (sayv) across different execution paths is important. When the static verifier checks a package for such a specification, if the verifier encounters a statementif (v == NULL), it should make a transition to thev=NULLstate on theTRUEpath andv!=NULLstate on theFALSE path. In such cases, a vertex split is said to happen along with an edge split. Different edges have the same source node but different destination nodes in the event of a vertex split.
We analyzedmalloc’s UseBeforeCheck formal specification against the vixie-cron-3.0.1-74 package in theRedhat-9.0distribution. Figure 2.7 shows the code snippets from the vixie-cron source files that violatemalloc’s UseBeforeCheck specification. The pointer that holdsmalloc’s return value is a field in the first two cases and an array in the third case.
2.4
Evaluation
specifi-vixie-cron-3.0.1-74
I /* job.c, lines [48, 49], variable j field referenced without check */ for (j=jhead; j; j=j->next)
if (j->e == e && j->u == u) { return; } /* build a job queue element */
j = (job*)malloc(sizeof(job)); j->next = (job*) NULL;
j->e = e; j->u = u;
II /* user.c, lines [66, 67] ,u field referenced without check */
u = (user *) malloc(sizeof(user)); u->name = strdup(name);
u->crontab = NULL;
III /* env.c, [57, 59], [57, 60], p array referenced without check */
p = (char **) malloc((count+1) * sizeof(char *)); /* 1 for the NULL */
for (i = 0; i < count; i++) p[i] = strdup(envp[i]);
p[count] = NULL;
return (p);
Figure 2.7: malloc UseBeforeCheck violations in vixie-cron package
cations, which were checked against the open-source packages. These specifications pertain to the safe usage of memory pointers.
• UseBeforeCheck: If the return value of an API call is a memory pointer on success and a NULLpointer on failure (we call this API call a p:np API call), a variable that holds the return value should always be checked before use or dereferencing.
• CheckDoesNotExist: If an API call returns only an integer status value upon success or failure (e.g.,setuidreturns 0 on success and -1 on failure), the status value should be checked for failure.
• NullPointerFree: A variable that holds the return value of a p:np API call should not be free’d on aNULLpath.
• FreePointerDereferencing: A pointer variable that isfree’d should not be dereferenced.
• DoubleFree: A pointer variable is neverfree’d more than once along all execution paths.
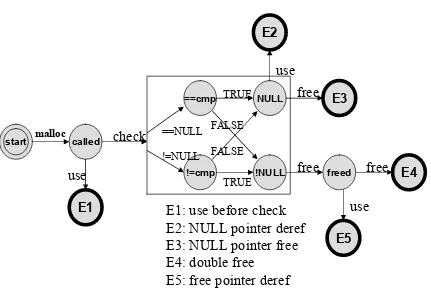
Figure 2.8 shows a highly simplified formal specification generated for themallocAPI. The specification governs the correct usage of pointer return variables. Simplified details (shown in the box) are shown only for one keyword,check, which is split into multiple edges and states by thespecEngineusing return value information from the API database. The “==NULL” transition denotes a comparison withNULLand the “!=NULL” transition denotes a comparison with non-NULL. The “==cmp” state denotes that the return variable is compared withNULLand “!=cmp” denotes that the return variable is compared with non-NULL. The “==cmp” state has a transition to theNULLstate onTRUEindicating that the return variable isNULLon theTRUEpath. Aderefaction (same asuse) in theNULLstate causes a NullPointerDereferencing violation. The meanings of other keywords are self-evident. StatesE1−E5are all error states.
We used our approach to analyze open-source packages written inCfrom theRedhat-9.0 distribution. In our experiments, we used a Pentium IV machine with 2.8GHz processor speed and 1GB RAM running on the Fedora Core 3 2.6.9-1.667smp kernel. In the experiments, we selected 10 widely used open-source packages from the Redhat-9.0distribution; these 10 packages in-clude near 100K lines ofCcode. For static verification, we used a publicly available static verifier called MOPS [23, 50], which employs push-down model checking (details in Chapter 3) to detect control-flow errors at compile time. It constructs a Push Down Automaton (PDA) for aCprogram from its Control Flow Graph (CFG). It then generates a new PDA by composing the property FSM to be checked and the program PDA. The new PDA is model checked [21] to see if there is any path in the program that takes the new PDA to an error configuration. If there exists such a path in the program, the static checker reports the path as an error trace that violates the specification.
E1
E5
E4
E3
E2
start
freed !NULL
NULL
!=cmp ==cmp
called
malloc
use
==NULL
!=NULL
FALSE
TRUE FALSE
TRUE
use
free
free
free
use
E1: use before check
E2: NULL pointer deref
E3: NULL pointer free
E4: double free
E5: free pointer deref
check
Figure 2.8: Simplified formal specification for the malloc API
conditional constructs that check the return value of an API call, we write extensions to the static analysis in MOPS to track the value of variables that take the return status of an API call along different branches of conditional constructs. For each possible execution sequence, our extensions associate a value to the variable that is being tracked using MOPS’s pattern matching. The formal specifications (in the form of FSMs) generated by thespecEngineare given to the static verifier enhanced with our path-sensitivity extensions. We evaluate the effectiveness and usefulness of our approach as follows.
Effectiveness: A user needs to specify only a small set of generic specifications at a high
fre-quently used in applications and their safe and robust usages are critical for system reliability and security. For these 60 APIs, more than 300 formal specifications were generated and they were checked against the 10Redhat-9.0open-source packages for robustness violations.
Usefulness: Figure 2.9(a) presents the total number of robustness violations that our
tool found for each of the checked packages. We found around 200 robustness violations in 10
Redhat-9.0open-source packages. We have shown the API-level violation breakdown for one se-lected package (SysVinit-2.84-13) in Figure 2.9(b). Of the 60 analyzed APIs, 19 of them gave violations with this package. Figure 2.10 shows the API violations reported across all the packages. Figure 2.11 showsmallocandsetuidviolations1found in the analyzed packages. Themalloc API is a standard memory-allocation routine. If it returnsNULLand is used without check, then it can cause memory corruption leading to a security hole. ThesetuidAPI failure is another danger-ous case because this case could indicate that a root privilege may not be properly dropped before executing dangerous user routines. From Figure 2.11, we observed that 7 out of 10 packages were detected withmallocviolations and 4 out of 10 packages were detected withsetuidviolations.
package #violations
ftp-0.17-17 18
ncompress-4.2.4-33 6 routed-0.17-14 15
rsh-0.17-14 9
sysklogd-1.3.31-3 27 sysstat-4.0.7-3 24 SysVinit-2.84-13 64
tftp-0.32-4 14
traceroute-1.4a12-9 7 zlib-1.1.3-3 4
(a) Overall violations of 10 Packages (b) Violations from SysVinit-2.84-13
API #violations API #violations
fdopen 1 chdir 2 closedir 1 fstat 3 fflush 2 malloc 1 fileno 1 open 2 fputc 1 fclose 12 fputs 2 putchar 1 fseek 2 unlink 4 ftell 1 write 4 getpwuid 1 setuid 1 close 26
Figure 2.9: Robustness violations detected in the analyzed open-source packages
API call #violations
close 42 closedir 4
chdir 3 fseek 4 fdopen 3 fgets 1 fclose 47 fflush 23 fputc 2 fputs 6 fileno 8 ftell 1 fstat 4 getenv 1 getpwuid 1 malloc 8 open 2 putchar 8 puts 2 setuid 5 unlink 7 write 9
Figure 2.10: API violations across all analyzed packages
packages #malloc violations
ncompress-4.2.4-33 1 dos2unix-3.1-15 1 routed-0.17-14 1 ftp-0.17-17 3 ltrace-0.3.29-1 1 SysVinit-2.84-13 1 vixie-cron-3.0.1-74 3
packages #setuid violations
traceroute-1.4a12-9 1 rsh-0.17-14 1 ghttpd-1.4 2 SysVinit-2.84-13 1
Most of the violations found were UseBeforeCheck violations for the p:np class of API calls and checkDoesNotExist violations for APIs that return an integer to indicate the success or failure status. All theRedhat-9.0packages that we have analyzed so far are compliant with the other specifications applicable to the p:np class of API calls apart from UseBeforeCheck.
2.5
Discussion
Chapter 3
Static Trace Generation for Mining
Specifications
3.1
Introduction
In the previous chapter, we present our approach for automatically generating formal spec-ifications directly verifiable by static checkers, when users could provide generic specspec-ifications as templates. The approach in the previous chapter assumed that the users have some knowledge about the specifications. To address this limitation, in this chapter, we present our novel approach [52] for mining specifications automatically by analyzing the API client code. The mined generic specifica-tions are then presented to the users. For verification, the mined specificaspecifica-tions can be used in their formal form. To mine specifications, the approach presented in this chapter generates static traces related to APIs of interest, directly from source code (API client code). Frequent API patterns are then mined from the generated static traces.
API patterns are often not documented by the API developers. Hence, it is difficult for the system developers to effectively or correctly reuse these APIs during system development or verify the correct usage of these APIs after the system has been built, necessitating automated specification mining. In this chapter, we present our approach for mining API patterns from static traces as partial orders (see Section 3.3). We adapt a model checker to generate inter-procedural control-flow-sensitive static traces related to the APIs of interest. In Chapter 4, we show how our approach is adapted for mining API error-handling specifications. In Chapter 5, we explore the utility of alias analysis for specification mining and violation detection. Next, we describe the motivation for mining API patterns as partial orders.
Previous approaches have mined likely API patterns from software systems that reuse APIs. Some approaches [35, 53–57] exploit the static program information extracted from system source code, whereas other approaches [28, 29, 58] exploit the dynamic program information ex-tracted from system executions, which require setup of runtime environments and availability of sufficient system tests. API patterns mined by most of these previous approaches are in the form of frequent association rules, itemsets, or subsequences. Association rules [53, 56, 59] characterize pairs of API calls that are often used together without considering their orders. Frequent item-sets [54, 60] characterize item-sets of API calls that are often used together without considering their orders. Frequent subsequences [61, 62] characterize sequences of API calls that are often used together while considering their orders. Although these mined API patterns have been shown to be useful to some extent, they cannot completely capture some useful orderings shared by APIs, especially when multiple APIs are involved across different procedures.
To address the issues faced by previous approaches in mining API patterns, we develop an approach to automatically mine frequent partial orders among user-specified APIs, directly from the source code (API client code). Frequent partial orders summarize important ordering informa-tion from sequential patterns. Frequent partial orders provide more general and more concise API ordering information than the sequential patterns. The mined partial orders among APIs can assist the correct and effective API reuse by the programmers.
Static API Trace Generation: We adapt a model checker to generate inter-procedural
control-flow-sensitive static traces related to the APIs of interest. Our approach allows mining of open-source systems that reuse the APIs of interest without requiring environment setup for system executions or availability of sufficient system tests.
Scenario Extraction: A single static trace from the model checker might involve several
API scenarios, being often interspersed. We present an algorithm, which considers the data flow between program statements in terms of shared variables, to separate different scenarios from a given trace, so that each scenario can be fed separately to the miner.
API Partial-Order Mining: We present novel applications of a miner in mining partial
orders among APIs from static traces. The mined partial orders provide important, useful API ordering information that is not provided by patterns mined by previous approaches.
We describe an implementation of our approach by adapting a publicly available model checker called MOPS [23] and adopting a miner called FRECPO [63]. We apply our approach on 72 clients of X11 with 208 KLOC in total and compare our approach with an existing dynamic specification miner. Our results highlight the unique benefits of our approach and show that the extracted API partial orders are useful in assisting effective API reuse and checking.
The remainder of this chapter is structured as follows. Section 3.2 starts with an example that motivates our approach. Section 3.3 introduces the formal approach for mining API partial orders and describes the various components in our approach in detail. Section 3.4 presents the implementation details. Section 3.5 reports our experience of comparing our approach with an existing dynamic specification miner. Section 3.6 discusses limitations of our approach.
3.2
Example
a programmer wants to investigate whether there are some ordering patterns among the APIs from <abcdef.h>.
Figure 3.1(b) shows five program traces involving these APIs along different possible control-flow paths in the program. Given a support threshold min sup, a sequential pattern is a sequencesthat appears as subsequences of at leastmin supsequences. For example, letmin sup be4. The four sequences shown in Figure 3.1(c) are sequential patterns since they are subsequences of Sequences2,3,4, and5(all excepta→f→e→c). Sequential patterns capture the frequent call patterns shared by program traces. However, the four sequential patterns cannot completely capture the ordering shared by APIsa, b,c,d,e, andf. It is easy to see that the partial orderR shown in Figure 3.1(d) is shared by the four program traces. We can make the following interesting observations from the partial orderR:
• The partial orderRsummarizes the four sequential patterns: the four sequential patterns are paths in the partial orderR. Note that the only sequences with a support greater than 4 area →f,a→e, anda→c, each with a support of 5.
• The partial orderRprovides more information about the ordering than the sequential patterns. For example, R indicates that band c are called in any order, but often before d. Hence the mined partial order R effectively summarizes the sequential patterns among APIs and provides more general and more concise API ordering information to the programmers.
• If themin sup is sufficiently high, the partial order provides strong hints on likely speci-fications that should be true for the correct operation of the program. For example, if the partial orderRwas mined from traces with a very high support, then with high confidence, “dshould always followa along any path” is a specification that should be satisfied by all programs using the APIsaandd.
example,a→a→b→ccould be two separate scenarios,a→banda→c, instead of one). Each scenario has to be extracted separately before being fed to the miner. We address these issues in the next section, where we present our approach for mining partial orders from static program traces.
3.3
Approach
In this section, we formalize the notions introduced in the previous section. We define partial order, total order, and frequent closed partial order (FCPO) [63], and formalize the problem of mining frequent closed partial orders from program traces. After the necessary foundations have been laid, we present the various components of our approach. We conclude this section by providing a complexity analysis of the different components in our approach.
3.3.1 Partial and Total Order
A partial order is a binary relation that is reflexive, antisymmetric, and transitive. A total order (or called linear order) is a partial orderRsuch that for any two itemsxandy, ifx6=ythen eitherR(x, y)orR(y, x)holds.
A partial orderRcan be expressed in a Directed Acyclic Graph (DAG): the items are the vertices in the graph and x → y is an edge if and only if(x, y) ∈ Randx 6= y. We also write an edgex → yas(x, y)orxy. For example, Figure 3.2(a) shows a partial orderR, which has13 edges.
Since a partial order is transitive, some edges can be derived from the others and thus are redundant. For example, in Figure 3.2(a), edgea→ dis redundant given edgesa→ bandb→d. Generally, an edgex→yis redundant if there is a path fromxtoyand this path does not contain the edge. For a partial orderR, the transitive reduction ofR can be drawn in a Hasse diagram: for(x, y) ∈ R andx =6 y,xis positioned higher thany; edgex → y is drawn if and only if the edge is not redundant. Figure 3.2(b) shows the transitive reduction of the same partial orderRin Figure 3.2(a). The transitive reduction has only6edges. For an order R, the transitive reduction may have much fewer edges.
LetV be a set of items, which serves as the domain of our string database. A string defines a global order on a subset ofV. A string can be written ass = x1· · ·xl, wherex1, . . . , xl ∈ V.
ldenotes the length of string s, i.e., len(s) = l. For strings s = x1· · ·xl ands′ = y1· · ·ym,s
denotes a super-string ofs′ ands′denotes a sub-string ofsif (1)m≤land (2) there exist integers 1 ≤i1 <· · · < im ≤ lsuch thatxij =yj (1 ≤j ≤ m). We also sayscontainss′. For a string
database SDB (set of strings), the support of a strings, denoted bysup(s), is the number of strings in SDB that are super-strings ofs.
The transitive closure of a binary relation R is the minimal transitive relation R′ that containsR. Thus,(x, y)∈Rprovided that there existz1, . . . , znsuch that(x, z1)∈R,(zn, y)∈R,
and(zi, zi+1)∈Rfor all1≤i < n.
The total order defined by strings= x1· · ·xlcan be written in the transitive closure of
s, denoted byC(s) = {(xi, xj)|1 ≤ i < j ≤ l}. Note that, in the transitive closure, we omit
the trivial pairs(xi, xi). For example, for strings = abcd, len(s) = 4. The transitive closure is
C(s) = {(a, b), (a, c), (a, d), (b, c), (b, d), (c, d)}. Here, we omit the trivial pairs (a, a), (b, b), (c, c), and(d, d).
The order containment relation is defined as, for two partial ordersR1andR2, ifR1 ⊂ R2, then R1 is said to be weaker than R2, and R2 is stronger than R1. Intuitively, a partially ordered set (or poset for short) satisfying R2 will also satisfy R1. For example, in Figure 3.3, R4 ⊂ R3 ⊂ R2 ⊂ R1. Note that R4 covers fewer items than the other three partial orders. Trivially, we can add the missing items into the DAG as isolated vertices so that every DAG covers the same set of items. To keep the DAG simple and easy to read, we omit such isolated items.
3.3.2 Frequent Closed Partial Orders (FCPO)
A string databaseSDBis a multiset of strings. For a partial orderR, a stringsis said to supportRifR⊆C(s). The support ofRinSDB, denoted bysup(R), is the number of strings in SDB that supportR. Given a minimum support thresholdmin sup, a partial orderRis frequent
Let us consider the program traces in Figure 3.1 again. The four sequential patterns can be regarded as frequent partial orders, which are supported by Traces2,3,4, and5. As discussed before, given that the partial orderRis also supported by Strings2,3,4, and5, the four sequential patterns as frequent partial orders are redundant. There does not exist another partial orderR′such thatR′ is stronger than R in Figure 3.1 and is also supported by Strings2, 3, 4, and 5. In other words, Ris the strongest one among all frequent partial orders supported by Strings 2, 3,4, and 5. Thus, the partial orderRis not redundant and can be used as the representative of the frequent
partial orders supported by Strings2,3,4, and5. Technically,Ris a frequent closed partial order. A partial orderRis closed in a string databaseSDBif there exists no partial orderR′ ⊃R such that sup(R) = sup(R′). A partial order R is a frequent closed partial order if it is both frequent and closed. We next formalize the process of mining FCPOs from program traces.
3.3.3 Formalizing FCPO Mining from Program Traces
Informally, our approach mines FCPOs for the APIs specified by the user from the pro-gram source code. Our approach addresses the following problems:
• Generating sequences of API invocations along different program paths. These sequences are stored as a string multiset database. However, generating all traces along all execution paths is an uncomputable problem and a trace can be of infinite size.
• Finding the complete set of frequent closed partial orders from the API sequence database with respect to a minimum support thresholdmin sup.
Formally, letΣbe the set of valid program statements in the given program source code. LetAbe the set of APIs specified by the user. A tracet∈Σ∗, a sequence of statements executed by a pathp, is feasible if pathpis feasible in the program. LetT⊂Σ∗be the set of all feasible traces in the program. To simplify the definitions, let us assume that all APIs inAare empty methods, do not take any arguments, and returnvoid1. For a givent∈T, letA(t)∈A∗be the API invocations along the tracetexpressed as a string. A(t)can be an empty string iftdoes not have any invocation of
APIs from the setA. LetT′⊆T be the set of all feasible traces such that ift∈T′,A(t)is not empty. However, the setT′is uncomputable andt∈T′ can be of infinite size. Our approach initially does the following steps:
• Generate the computable approximation ofT′ from the program and extractA(t)for alltin the approximate set. The extractedA(t)’s are stored in a string database, say,V.
• Extract the set of FCPOs among APIs inA fromV, with respect to a minimum threshold min sup.
The high-level overview of our approach is shown in Figure 3.4. Our approach has three main components: trace generator, scenario extractor, and specification miner. The user specifies a set of APIs from which Triggers (explained in Section 3.3.4) are generated. The Triggers are then used with push-down model checking for trace generation. This process also recommends more APIs related to the user-specified set of APIs. The scenario extractor extracts various API scenarios (explained in Section 3.3.5) from the traces. The specification miner feeds the extracted scenarios to a FCPO miner [63] to output specifications and usage scenarios as partial orders. Each process is described in detail in the subsections below. We first explain the process of trace generation.
3.3.4 Trace Generation
We first briefly summarize the Push-Down Model Checking (PDMC) process [21, 64], which we adapt for trace generation. To generate API invocation sequences along different program paths, we introduce the concept ofT riggers. Finally, we discuss the soundness of our approach.
Push-Down Model Checking (PDMC)
Informally, given a property represented using a Finite State Machine (FSM), PDMC [21] checks to see if there is any path in the program that puts the FSM in its final state. For example, if the property FSM is specified as shown in Figure 3.5, PDMC reports all program paths in which
be a final configuration, ifq belongs to the set of final states in the FSM. If a final configuration is reachable, PDMC outputs the paths (in the program) that cause the resultant PDA to reach this final configuration. We next describe our Triggers technique that adapts PDMC to generate API invocation sequences in a program.
Triggers
Our goal is to generate the set T′⊆T from the program and extract A(t) for all t∈T′, A(t)∈A∗, A = {a1, a2, a3, ..., a
k}, whereai,1≤i≤k, are the APIs specified by the user. Let us
assume that we give the FSM shown in Figure 3.6 to PDMC to be verified against a programP. The FSM in Figure 3.6 accepts any string of the forme(Pi=1,2,...,kai)∗x, whereeandx are any
two points in the program. Given this Trigger FSM, PDMC outputs all program paths that begin witheand end withxin the program. By settingeas the entry point of themainroutine andxas any exit point in the program, we can collect sequences of API along paths that begin at themain routine and ends at exit points.
• We have producedTex, the set of traces (in the program) that begin witheand end withx
instead ofT′⊆T.
• The knowledge ofA={a1, a2, a3, ..., ak}allows us to extractA(t)from anyt∈Tex.
Soundness
The consequence of using a context-free language forTintroduces imprecision but retains the soundness of analysis. Infeasible traces might occur (being incomplete) because of data-flow insensitivity of the PDMC process, but all the program traces that put the FSM in its final state are reported (being sound). Since determining ifT∩B = φis undecidable, no tool can be sound and complete at the same time. Consequently, there could be some infeasible API sequences in the database being fed to the FCPO miner. For example, in Figure 3.1, the variableimight never assume value1; therefore, the tracea→f→e→cis infeasible in the program. Also, along some feasible paths, the implicit API ordering rules might be violated and APIs could be used incorrectly (producing buggy traces with actual errors). Hence the API sequence database might contain certain wrong API sequences. However, we assume that most programs that we analyze are well written. Hence, we expect only few feasible paths to be buggy, if at all. We expect to handle infeasible and buggy traces by selecting appropriatemin supvalue. The traces generated by PDMC with Triggers can still be of infinite size in the presence of loops. We address this problem in Section 3.4.
3.3.5 Scenario Extraction
A single static trace from the model checker might involve several API usage scenarios, being often interspersed. We have to separate different usage scenarios from a given trace, so that each scenario can be fed separately to the miner. A naive algorithm for scenario extraction would be to remove all duplicate APIs in a given trace and feed the resulting API sequence as a single scenario to the miner. But most traces have multiple scenarios around the same set of APIs. Furthermore, these different scenarios represent different usage patterns among the API set. The naive algorithm of deleting duplicates leads to loss of API ordering information and a drastic decrease in the number of scenarios fed to the miner.
API to form a chain) among APIs in the trace. The algorithm (henceforth called as the PC-Chain al-gorithm) is based on the assumption that related APIs have some form of data dependencies between them in the form of shared variables. In short, the PC-Chain algorithm first identifies PC-chains among APIs in traces and outputs them as scenarios. Isolated partial orders are then constructed among APIs in related PC-chains. Finally, partial orders are computed between heads of PC-chains, and these partial orders form partial order clusters. As an example, consider three sets of APIs (a, b, c, d),(e, f, g), and (h, i, j). The first API in each set produces a value that is consumed by
the remaining APIs in the set. Figure 3.7(a) shows two traces produced by the model checker. The APIs are all interspersed and there are three scenarios in each trace. The arrows in Figure 3.7(a) show the PC-chains among related APIs. Figure 3.7(b) shows six different scenarios extracted from two traces. Figure 3.7(c) summarizes the six different API scenarios compactly as three isolated partial orders. Finally, Figure 3.7(d) merges the isolated partial orders into one big partial order. Algorithm 1 summarizes the PC-Chain scenario extraction algorithm.
Input: static traces
Output: partial order clusters
Identify all producers;
foreach producer do
Identify consumers; Construct PC-chain;
Output PC-chain as a scenario;
end
Construct isolated partial orders from scenarios; Collect the head APIs from isolated partial orders;
Construct partial order among head APIs to form partial order clusters;
return patial order clusters;
Algorithm 1: The PC-Chain algorithm for scenario extraction
3.3.6 Specification Mining