Storage Management in Big Data Using Hadoop
Full text
Figure


Related documents
One customer example, a financial services firm, moved processing of applications and reports from an operational data warehouse to Hadoop Hbase; they were able
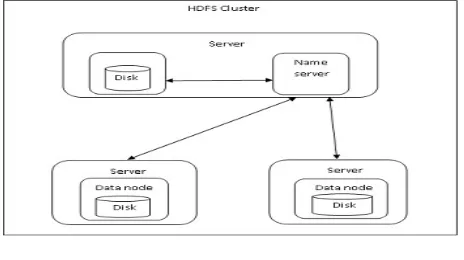
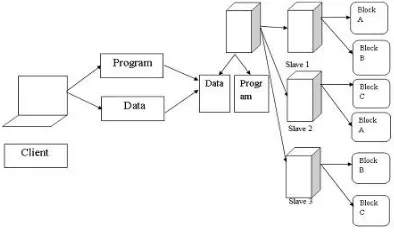
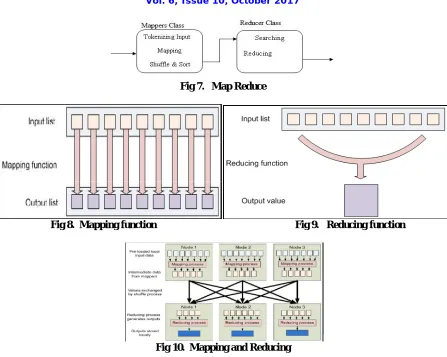
This system presents an efficient data storage approach to push work out to many nodes in a cluster using Hadoop File System (HDFS) with variable chunk size to
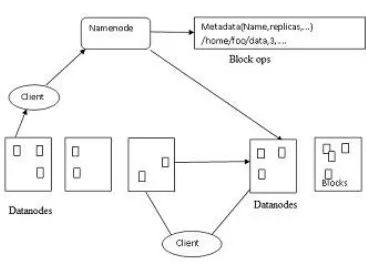
HDFS handles failure of nodes, so it achieves reliability by duplicating data across multiple nodes.HDFS is a Hadoop distributed file system based on java that provides not
YARN based Hadoop architecture, supports parallel processing of huge data sets and MapReduce provides the framework for easily writing applications on thousands of
– Push subsets of data to a final platform for processing • Hadoop 2.0 takes Hadoop beyond “Batch”. – 2.0 YARN based architecture enabling mixed use
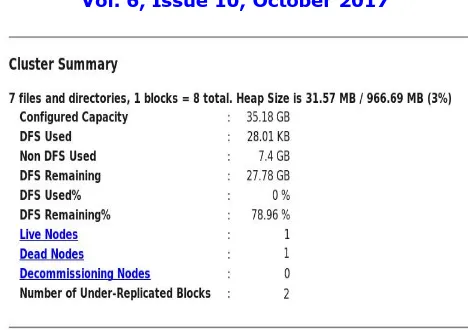
A Hadoop cluster has 10 nodes with 300GB of storage per node with the default HDFS setup (replication factor 3,.
This reference architecture captures the installation and configuration of a six-node Hadoop cluster that has two master nodes and four data nodes (sometimes called slave nodes)..
A Hadoop cluster with one master node, four data nodes, eight compute nodes, and one client node must be created using the previously specified BDE local and shared storage
