Recognizing and removing of similar Data for Information Processing and
Storing in Cloud
Gundluru Padmaja Kumari1, C. Govardhan2
1M.Tech, Department of Computer Science and Engineering, KMM Institute of Technology and Sciences,
Tirupati, Andhra Pradesh, India
2Assistant Professor, Department of Computer Science and Engineering, KMM Institute of Technology and
Sciences, Tirupati, Andhra Pradesh, India ABSTRACT
Attribute-based encryption (ABE) has been wide utilized in cloud computing wherever a data provider outsources his/her encrypted information to a cloud service provider, and might share the data with users possessing specific credentials (or attributes). However, the standard ABE system doesn't support secure deduplication, which is crucial for eliminating duplicate copies of identical data inorder to save lots of cupboard space and network information measure. During this paper, we have a tendency to gift DARE, a low-overhead Deduplication-Aware resemblance detection and Elimination theme that effectively exploits existing duplicate-adjacency data for extremely economical likeness detection in data deduplication based mostly backup/archiving storage systems. the most plan behind DARE is to use a theme, call Duplicate-Adjacency based mostly likeness Detection (DupAdj), by considering any 2 information chunks to be similar (i.e., candidates for delta compression) if their various adjacent information chunks are duplicate during a deduplication system, and so any enhance the resemblance detection efficiency by AN improved super-feature approach.
Keywords : Data deduplication, delta compression, storage system, index structure, performance evaluation, ABE
I.
INTRODUCTIONThe measure of computerized information is developing violently, as confirm to some extent by an expected measure of about 1.2 zettabytes and 1.8 zettabytes separately of information delivered in 2010 and 2011 [1], [2]. Accordingly “information storm", overseeing capacity and decreasing its expenses have turned out to be a standout amongst the most difficult and critical assignments in mass stockpiling frameworks. As per an ongoing IDC contemplate [3], just about 80% of partnerships studied showed that they were investigating information deduplication innovations in their capacity frameworks to expand capacity productivity.
store just a single duplicate of them to accomplish the objective of room investment funds.
While information deduplication has been generally conveyed in capacity frameworks for space investment funds, the unique mark based deduplication approaches have an inalienable disadvantage: they regularly neglect to identify the comparative lumps that are to a great extent indistinguishable aside from a couple of changed bytes, in light of the fact that their protected hash process will be entirely unexpected even just a single byte of an information lump was changed [4], [5]. It turns into a major test while applying information deduplication to capacity datasets and workloads that have regularly adjusted information, which requests a compelling and proficient approach to dispense with excess among regularly adjusted and along these lines comparable information.
Delta pressure, a proficient way to deal with evacuating repetition among comparative information lumps has increased expanding consideration away frameworks. For instance, if lump A2 is like piece A1 (the base-lump), the delta pressure approach ascertains and after that lone stores the distinctions (delta) and mapping connection amongst A2 and A1. Along these lines, it is viewed as a promising procedure that viably supplements the unique mark based deduplication approaches by identifying comparative information missed by the last mentioned. One of the fundamental difficulties confronting the application of delta pressure in deduplication frameworks is the secret to precisely recognize the most comparable contender for delta pressure with low overheads. The best in class arrangements recognize comparability for delta pressure by processing a few Rabin fingerprints as highlights and gathering them into super-fingerprints, too alluded to as super-highlights.
All things considered, to record a dataset of 80 TB and expecting a normal piece size of 8 KB and 16 bytes for every record section, for instance, around 200 GB worth of super-include record passages must be created, which will at present be as well substantial to fit in memory [12]. Since the irregular gets to on-plate file are much slower than that to RAM, the visit gets to on-plate super-highlights will cause the framework throughput to wind up unsatisfactorily low for the clients [6]. From our perception of copy and comparative information of reinforcement streams, we find that the non-copy lumps that are adjoining copy ones could be considered great delta pressure hopefuls in information deduplication frameworks. Along these lines we propose the approach of Duplicate Adjacency based Resemblance Detection, or DupAdj for short. Abusing this current deduplication data(i.e., copy contiguousness) not just keeps away from the high overhead of super-include calculation yet in addition decreases the span of record sections for similarity identification. On the other hand, our investigation of the current super-include approaches uncovers that the conventional super-include technique can be enhanced with less highlights per super-include, which works viably on deduplication frameworks when joined with the previously mentioned DupAdj approach.
few genuine workloads in information deduplication frameworks.
II.
Proposed SystemIn this section, we will first describe the architecture and key data structures of DARE, followed by detailed discussions of its design and implementation issues.
Architecture Overview:-
Set out is intended to enhance likeness discovery for extra information decrease in deduplication-based reinforcement/filing stockpiling frameworks. As appeared in Figure 3, the DARE engineering comprises of three utilitarian modules, to be specific, the Deduplication module, the DupAdj Discovery module, and the enhanced Super-Feature module. Furthermore, there are five key information structures in DARE, specifically, Dedupe Hash Table, SFeature Hash Table, Locality Cache, Container, Segment, and Chunk, which are characterized beneath:
• A chunk is the nuclear unit for information decrease. The non-copy lumps, recognized by their SHA1 fingerprints, will be set up for similarity location in DARE.
• A container is the settled size stockpiling unit that stores consecutive and NOT decreased information, for example, nonduplicate and non-comparable or delta pieces, for better capacity execution by utilizing huge I/Os [6].
• A segment comprises of the metadata of a number of consecutive pieces (e.g., 1MB size, for example, the piece fingerprints, estimate, and so on., which fills in as the nuclear unit in saving the reinforcement stream sensible area [36] for information lessening. Here DARE employments and information structure of doubly-connected rundown to record the lump contiguousness data for the DupAdj recognition. Note
that the SFeature in the portion may be pointless if the DupAdj module has as of now affirmed this lump as being comparative for delta pressure.
• Dedupe Hash Table serves to record fingerprints for copy discovery for the deduplication module.
• SFeature Hash Table serves to record the super features after the DupAdj similarity location. It deals with the super-highlights of copy and non-comparative lumps.
• Locality Cache contains the as of late got to information fragments and therefore protects the reinforcement stream territory in memory, to decrease gets to the ondisk file from either copy recognition or similarity location.
abused by DARE to recognize conceivable likeness among the non-copy information lumps, as itemized in the following subsection.
DupAdj: Duplicate-Adjacency based Resemblance Detection:-
As a remarkable element of DARE, the DupAdj approach recognizes similarity by abusing existing duplicate adjacency data of a deduplication framework. The principle thought behind this approach is to think about lump matches firmly contiguous any affirmed copy lump match between two information streams as taking after sets and consequently possibility for delta pressure, as reasonably represented in Figure 1.
As indicated by the depiction of the DARE information structures in Figure 3, DARE records the reinforcement stream sensible area of piece succession by a doubly-connected list, which permits a proficient pursuit of the duplicate adjacent lumps for similarity recognition by crossing to earlier or next pieces on the rundown, as appeared in Figure 1. At the point when the DupAdj Detection module of DARE forms an information portion, it will navigate every one of the pieces by the previously mentioned doubly-connected rundown to discover the as of now copy recognized pieces. In the event that piece of the info portion A was recognized to be a copy of piece of portion B, DARE will navigate the doubly-connected rundown of in the two headings (e.g.,
and and and ) looking for
possibly comparable lump matches between sections An and B, until a disparate piece or an officially identified copy or comparative lump is found. Note that the distinguished pieces here are considered different (i.e., NOT comparable) to others if their comparability degree (i.e., dela compacted measure lump measure) is littler than a predefined edge, for example, 0.25, a false positive for similarity discovery. In reality, the closeness degree of the DupAdj-identified lumps has a tendency to be high, bigger
than 0.88. When all is said in has done the overheads for the DupAdj based approaches are twofold:
• Memory overhead: Each piece will be related with two pointers (around 8 or 16 Bytes) for building the doubly-connected rundown when DARE stacks the portion into the region reserve. Be that as it may, when the fragment is removed from the reserve, the doubly-connected rundown will be instantly liberated. Along these lines, this RAM memory overhead is seemingly immaterial given the aggregate limit of the region reserve.
• Computation overhead: Confirming the likeness level of the DupAdj-distinguished pieces may present extra yet omitted calculation overhead. To begin with, the delta encoding comes about for the affirmed looking like (i.e., comparable) pieces will be straightforwardly utilized as the last delta lump for capacity. Second, the genuine additional calculation overhead happens at the point when the DupAdj-distinguished pieces are NOT comparable, which is an exceptionally uncommon occasion as talked about in the past section.
On the whole, the DupAdj identification approach just includes a doubly-connected rundown to a current deduplication framework, Set out evades the calculation and ordering overheads of the ordinary super-highlight approach. On the off chance that where the copy nearness data is inadequate, restricted, or hindered because of activities, for example, record content inclusions/cancellations or new record affixing, DARE will utilize an enhanced super-include way to deal with further distinguish and dispose of similarity as talked about in the next segment.
Improved Super-Feature Approach
instance, of a piece (length = N), is particularly created with a haphazardly pre-characterized esteem match and and N Rabin fingerprints as takes after:
A super-feature of this chunk, can then be calculated by several such features as follows:
For instance, to produce two super-highlights with k=4 includes every, we should first create 8 highlights, in particular, highlights 0...3 for and highlights 4...7 for . For comparable pieces that contrast just in a small portion of bytes, the vast majority of their highlights will be indistinguishable because of the irregular appropriation of the lump's maximal-highlight positions. In this way two information lumps can be viewed as fundamentally the same as if any of their super features matches. The cutting edge examines on delta pressure and similarity location prescribe the utilization of at least 4 highlights to produce a super-component to limit bogus positives of similarity recognition.
Be that as it may, our hypothetical investigation and trial perceptions recommend that the likelihood of false positives coming about because of highlight impact is to a great degree low yet expanding the quantity of highlights per super-include really diminishes the effectiveness of similarity identification. In the first place, the bogus positives of 64-bit Rabin fingerprints tend to be low. This implies two pieces will have a similar substance of hashing district (32 or 48 bytes) with a high likelihood in the event that they have the same Rabin unique finger impression. Next, the likelihood of two comparative pieces having a similar element is exceedingly subordinate upon their closeness degree as indicated by Broder's hypothesis. The less comparative two
information lumps are to each other, the littler the likelihood there will be of them having a similar component. Hence, the likelihood of two information pieces S1 and S2 being recognized as looking like to each other by N highlights can be registered as takes after.
This likelihood is unmistakably diminishing as an element of the quantity of highlights utilized as a part of a super-include, as demonstrated by the above likelihood articulation. By and by, every single ongoing examination on delta pressure recommend to increment the quantity of super-highlights. On the off chance that any one of the super-highlights of two information lumps coordinates, the two pieces are viewed as like each other. In this way, the likelihood of likeness identification, communicated as
, can be expanded by the quantity of superfeatures, M.
For straightforwardness, accept that the closeness degree γ takes after a uniform appropriation in the range [0, 1] (take note of that the real appropriation might be substantially more confounded in genuine workloads), the normal estimation of likeness identification can be communicated as an element of the number of highlights per super-include and the quantity of super features under the previously mentioned suspicion as:
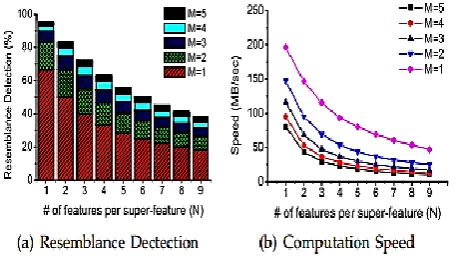
M. The need to increment the quantity of super-highlights recommended in Figure 1(a) is predictable with the finish of the most recent investigation of SIDC [12], while the proposed inclination for a littler number of highlights per super-include is steady with furthermore, confirmed by our exploratory assessment point by point in this paper. If you don't mind take note of that the calculation overhead of the super-highlight based similarity approach is corresponding to the aggregate number of highlights N*M, as outlined in Figure 1(b).
Figure 1. The predicted data reduction efficiency and computation throughput of the super-feature approach as a function of the number of features per feature (N, x-axis) and the number of super-features (M, segments on each bar in (a) or lines in (b)).
As a rule, utilizing less highlights per super-include not just decreases the calculation overhead yet in addition recognizes more likeness. Along these lines, DARE utilizes a made strides super-highlight approach with less highlights per super feature furthermore, keeps the quantity of super-highlights stable to viably supplement the DupAdj likeness location. What's more, our trial comes about propose that a design of 3 super-highlights and two highlights per super-include seems to hit the "sweet spot" of similarity identification in deduplication frameworks in wording of cost viability.
Delta Compression
To lessen information excess among comparable lumps, Xdelta [23], a streamlined delta pressure calculation, is received in DARE after a delta pressure applicant is identified by DARE's likeness recognition. Set out likewise just completes the one-level delta pressure for comparative information as utilized in DERD [15] and SIDC [12]. This is on account of we mean to limit the information fracture issue that would cause a solitary read demand to issue different read tasks to various information lumps, a reasonable situation if multi-level delta pressure is utilized. As such, in DARE, delta pressure won't be connected to a lump that has as of now been delta packed to maintain a strategic distance from recursive in reverse referencing. Furthermore, DARE records the closeness degree as the proportion of packed size unique size after delta pressure (take note of that "packed size" here alludes to the extent of excess information diminished by delta pressure).
base-lumps are still unavoidable as talked about in [17] and in our assessment.
Putting It All Together:
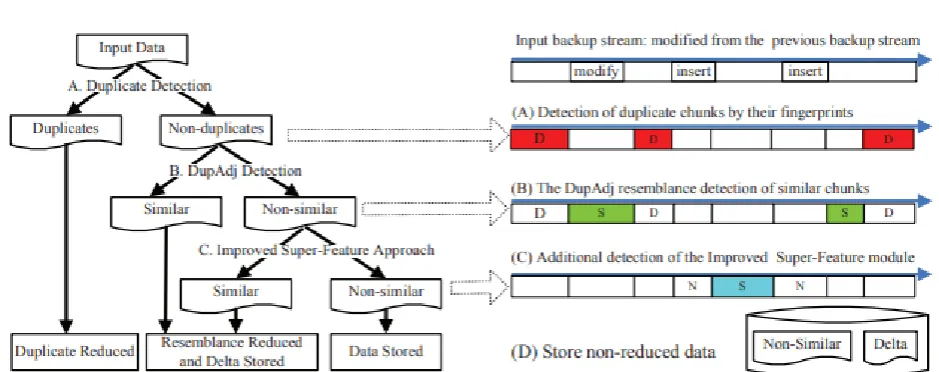
To place things in context, Figure 2 demonstrates a point by point instance of the procedures of DARE framework. For an approaching reinforcement stream, DARE experiences the accompanying four key advances:
Figure 2. The data reduction workflow of DARE, showing an example of resemblance detection for delta compression first by the DupAdj approach and then by the super-feature approach. ‘D’, ‘S’ and ‘N’ here refer to a duplicate chunk, a similar chunk, and a chunk that is neither duplicate nor similar, respectively.
1) Duplicate Detection. The information stream is first lumped, fingerprinted, copy identified, and afterward assembled into sections of successive pieces to protect the reinforcement stream coherent territory [36]. Note that the territory data will be misused by the accompanying DupAdj similarity recognition.
2) Resemblance Detection. The DupAdj similarity location module in DARE initially distinguishes duplicate adjacent pieces in the fragments framed in step (1). From that point onward, DARE's enhanced super-include module additionally recognizes comparative pieces in the remaining non-copy and non-comparative lumps that may have been missed by the DupAdj discovery module at the point when the copy contiguousness data is inadequate or then again powerless.
3) Delta Compression. For every one of the looking like pieces identified in step (2), DARE peruses its base lump, at that point delta encodes their disparities. All together to decrease circle peruses, a LRU and
locality preserved reserve is executed here to prefetch the base-lumps as information portions.
4) Storage Management. The information NOT diminished, i.e., non-comparative and delta lumps, will be put away as compartments on the circle. The record mapping connections among the copy lumps, looking like pieces, what's more, non-comparative pieces will likewise be recorded as the record formulas [28], [44] to encourage future information reestablish tasks in DARE.
the overheads of similarity location in existing deduplication frameworks.
III.
CONCLUSIONIn this paper, we tend to gift DARE, a deduplication-aware, low-overhead alikeness detection and elimination scheme for data reduction in backup/archiving storage systems. DARE uses a unique approach, DupAdj, which exploits the duplicate-adjacency data for economical resemblance detection in existing deduplication systems, and employs AN improved super-feature approach to additional sleuthing alikeness once the duplicate adjacency information is lacking or restricted. Results from experiments driven by real-world and synthetic backup datasets counsel that DARE is a powerful and economical tool for increasing data reduction by additional sleuthing resembling knowledge with low overheads. Specifically, DARE solely consumes concerning ¼ and 1/2 severally of the computation and categorization overheads needed by the standard super-feature approaches while sleuthing 2-10% additional redundancy and achieving a better output. what is more, the DARE enhanced data reduction approach is shown to be capable of rising the data-restore performance, speeding up the deduplication-only approach by an element of 2(2X) by using delta compression to additional eliminate redundancy and effectively enlarge the logical area of the restoration cache.
IV.
REFERENCES[1]. G P. Shaikh, S. D. Chaudhary, P. Paygude, and D. Bhattacharyya, "Achieving secure deduplication by using private cloud and public cloud," International Journal of Security and Its Applications, vol. 10, no. 5, pp. 17-26, 2016.
[2]. G. P. Shaikh, "De-duplication with authorization in hybrid cloud approach for security," International Journal of Computer Sciences and Engineering, vol. 4, special issue 4, pp. 1-4, 2016.
[3]. G P. Shaikh, Prof. S. D. Chaudhary, and Prof. P. S. Paygude, "Achieving data confidentiality by usage of hybrid cloud and deduplication," International Journal of Computer Science and Mobile Computing, vol. 5, issue 7, pp. 245-252, 2016.
[4]. G Shaikh, "A survey on deduplication strategies and storage systems," IOSR Journal of Computer Engineering (IOSR-JCE), pp. 85-90, 2015.
[5]. A Ka, A. Ganesha, and Sunitha C, "A study on deduplication techniques over encrypted data," Procedia Computer Science, vol. 87, pp. 38-43, 2016.
[6]. D T. Meyer and W. J. Bolosky, "A study of practical deduplication," ACM Transactions on Storage (TOS), vol. 7, issue 4, pp. 14, 2012.
[7]. Halevi, D. Harnik, B. Pinkas, and A. Shulman-Peleg, "Proofs of ownership in remote storage systems," Proc. ACM Conf. Comput. Commun. Security, pp. 491-500, 2011.
[8]. J R. Douceur, A. Adya, W. J. Bolosky, D. Simon, and M. Theimer. "Reclaiming space from duplicate files in a serverless distributed file system," IEEE Proceedings 22nd International Conference on Distributed Computing Systems, pp. 617-624, 2002.
[9]. P Anderson and L. Zhang, "Fast and secure laptop backups with encrypted de-duplication," Proc. 24th Int. Conf. Large Installation Syst. Admin., pp. 29-40, 2010.
[10].B. Choudhary and A. Dravid "A study on authorized deduplication techniques in cloud computing," International Journal of Advanced Research in Computer Engineering & Technology (IJARCET), vol. 3, issue 12, pp. 4191-4194, 2014.
[11].Yingdan Shang and Huiba Li, "Data