UC Berkeley
UC Berkeley Electronic Theses and Dissertations
TitleSystem Design for Software Packet Processing
Permalink https://escholarship.org/uc/item/5qv03232 Author Han, Sangjin Publication Date 2019 Peer reviewed|Thesis/dissertation
eScholarship.org Powered by the California Digital Library
System Design for Software Packet Processing
By Sangjin Han
A dissertation submitted in partial satisfaction of the requirements for the degree of
Doctor of Philosophy in Computer Science in the Graduate Division of the
University of California, Berkeley
Committee in charge:
Professor Sylvia Ratnasamy, Chair Professor Scott Shenker Professor Dorit Hochbaum
System Design for Software Packet Processing
Copyright 2019 by Sangjin Han
1 Abstract
System Design for Software Packet Processing by
Sangjin Han
Doctor of Philosophy in Computer Science University of California, Berkeley Professor Sylvia Ratnasamy, Chair
The role of software in computer networks has never been more crucial than today, with the advent of Internet-scale services and cloud computing. The trend toward software-based network dataplane—as in network function virtualization—requires software packet processing to meet challenging performance requirements, such as supporting exponentially increasing link bandwidth and microsecond-order latency. Many architectural aspects of existing software systems for packet processing, however, are decades old and ill-suited to today’s network I/O workloads.
In this dissertation, we explore the design space of high-performance software packet processing systems in the context of two application domains. First, we start by discussing the limitations of BSD Socket, which is a de-facto standard in network I/O for server ap-plications. We quantify its performance limitations and propose a clean-slate API, called MegaPipe, as an alternative to BSD Socket. In the second part of this dissertation, we switch our focus to in-network software systems for network functions, such as network switches and middleboxes. We present Berkeley Extensible Software Switch (BESS), a modular frame-work for building extensible netframe-work functions. BESS introduces various novel techniques to achieve high-performance software packet processing, without compromising on either programmability or flexibility.
i
ii
Contents
List of Figures v
List of Tables vii
1 Introduction 1
1.1 Summary of Contributions . . . 3
1.2 Outline and Previously Published Work. . . 4
1.3 Research Projects Not Included in This Dissertation . . . 5
2 Background 7 2.1 Packet Processing under Multi-Core Environments. . . 7
2.2 Virtualization (of Everything) . . . 9
2.3 Network Stack Specialization. . . 9
3 MegaPipe: A New Programming Interface for Scalable Network I/O 11 3.1 Introduction . . . 11
3.2 Motivation . . . 12
3.2.1 Sources of Performance Inefficiency . . . 13
3.2.2 Performance of Message-Oriented Workloads . . . 14
3.3 Design . . . 17
3.3.1 Scope and Design Goals . . . 17
3.3.2 Completion Notification Model . . . 18
3.3.3 Architectural Overview . . . 18
3.3.4 Design Components. . . 19
3.3.5 Application Programming Interface . . . 23
3.3.6 Discussion: Thread-Based Servers . . . 24
3.4 Implementation . . . 25
3.4.1 Kernel Implementation . . . 25
3.4.2 User-Level Library . . . 26
3.5 Evaluation . . . 27
3.5.1 Multi-Core Scalability . . . 27
Contents iii
3.5.3 Impact of Message Size . . . 28
3.6 Conclusion . . . 29
4 Applications of MegaPipe 30 4.1 Adopting Existing Server Applications . . . 30
4.1.1 Porting memcached . . . 30
4.1.2 Porting nginx . . . 31
4.2 Macrobenchmark: memcached . . . 31
4.3 Macrobenchmark: nginx . . . 34
5 BESS: A Modular Framework for Extensible Network Dataplane 37 5.1 Motivation . . . 39
5.1.1 Software-Augmented Network Interface Card . . . 39
5.1.2 Hypervisor Virtual Switch . . . 41
5.1.3 Network Functions . . . 42
5.2 BESS Design Overview . . . 43
5.2.1 Design Goals . . . 43
5.2.2 Overall Architecture . . . 44
5.2.3 Modular Packet Processing Pipeline . . . 45
5.3 Dynamic Packet Metadata . . . 47
5.3.1 Problem: Metadata Bloat . . . 47
5.3.2 Metadata Support in BESS . . . 48
5.3.3 Attribute-Offset Assignment . . . 49
5.4 Resource Scheduling for Performance Guarantees . . . 51
5.5 Implementation Details . . . 53
5.5.1 Overview . . . 54
5.5.2 Core Dedication . . . 54
5.5.3 Pipeline Components . . . 55
5.5.4 BESS Scheduler . . . 56
5.5.5 Packet Buffers and Batched Packet Processing . . . 58
5.5.6 Multi-Core Scaling . . . 59 5.6 Performance Evaluation . . . 61 5.6.1 Experimental Setup. . . 61 5.6.2 End-to-End Latency . . . 61 5.6.3 Throughput . . . 63 5.6.4 Application-Level Performance. . . 63 6 Applications of BESS 65 6.1 Case Study: Advanced NIC features . . . 65
6.1.1 Segmentation Offloading for Tunneled Packets . . . 65
6.1.2 Scalable Rate Limiter. . . 66
Contents iv
6.1.4 Scaling Legacy Applications . . . 69
6.2 Research Projects Based on BESS . . . 70
6.2.1 E2: A Framework for NFV Applications . . . 71
6.2.2 S6: Elastic Scaling of Stateful Network Functions . . . 73
7 Related Work 76 7.1 MegaPipe . . . 76
7.1.1 Scaling with Concurrency . . . 76
7.1.2 Asynchronous I/O . . . 76
7.1.3 System Call Batching. . . 77
7.1.4 Kernel-Level Network Applications . . . 77
7.1.5 Multi-Core Scalability . . . 77
7.1.6 Similarities in Abstraction . . . 78
7.2 BESS. . . 78
7.2.1 Click . . . 78
7.2.2 High-performance packet I/O . . . 79
7.2.3 Hardware support for virtual network I/O . . . 79
7.2.4 Smart NICs . . . 79
7.2.5 Ideal hardware NIC model . . . 80
7.2.6 Alternative approaches . . . 80
v
List of Figures
2.1 Evolution of AMD and Intel microprocessors in terms of clock frequency and number of cores per processor (log-scaled). The raw data was obtained from
Stanford CPUDB [23]. . . 7
2.2 The parallel speedup of the Linux network stack, measured with a RPC-like work-load on a 8-core server. For the experiment we generated TCP client connections, each of which exchanges a pair of 64-byte dummy request and request. . . 8
3.1 Negative impact of message-oriented workload on network stack performance . . 15
3.2 MegaPipe architecture . . . 19
3.3 Comparison of parallel speedup . . . 27
3.4 Relative performance improvement with varying message size. . . 29
4.1 Throughput of memcached with and without MegaPipe . . . 32
4.2 50th and 99th percentile memcached latency.. . . 33
4.3 Evaluation of nginx throughput for various workloads. . . 35
5.1 Growing complexity of NIC hardware . . . 40
5.2 BESS architecture . . . 44
5.3 BESS dataflow graph example . . . 45
5.4 Per-packet metadata support in BESS . . . 48
5.5 Example of scope components of metadata attribute . . . 49
5.6 Construction of the scope graph from calculated scope components . . . 50
5.7 Optimal coloring for the scope graph shown in Figure 5.6(b) with three colors. In other words, for the given pipeline, three offsets are enough to accommodate all six attributes with multiplexing. . . 51
5.8 An example of high-level performance policy and its class tree representation . . 52
5.9 BESS multi-core scaling strategies . . . 59
5.10 Round-trip latency between two application processes. . . 62
5.11 BESS throughput and multi-core scalability. . . 63
6.1 System-wide CPU usage for 1M dummy transactions per second . . . 68
6.2 Snort tail latency with different load balancing schemes . . . 70 6.3 Transformations of a high-level policy graph (a) into an instance graph (b, c, d). 72
List of Figures vi
6.4 Distributed shared object (DSO) space, where object distribution is done in two layers: key and object layers. The key layer partitions the key space; each node keeps track of the current location of every object in the key partition. The object layer stores the actual binary of objects. The key layer provides indirect access to objects, allowing great flexibility in object placement. . . 74
vii
List of Tables
3.1 List of MegaPipe API functions for userspace applications . . . 22 3.2 Performance improvement from MegaPipe . . . 28 4.1 The amount of code change required for adapting applications to MegaPipe . . 30 5.1 Throughput and CPU usage of memcached in bare-metal and VM environments 64 6.1 TCP throughput and CPU usage breakdown over the VXLAN tunneling protocol 66 6.2 Accuracy comparison of packet scheduling between BESS and SENIC . . . 67
1
Chapter 1
Introduction
Many design choices of computer networking have been centered around the end-to-end principle [108], which can be roughly summarized as “keep the network simple, and implement application-specific functionality in end hosts.” The principle has provided a philosophical basis for the Internet architecture. Intermediary network nodes, such as switches and routers, merely performed simple packet forwarding, i.e., sending datagrams from one end host to
another. More sophisticated features, such as reliable file transfer, data encryption, streaming a live video, etc., were supposed to be implemented in end hosts. There is no denying that
this separation of roles have greatly contributed to the great success of the Internet. The simple “core” enabled the extraordinary growth of the Internet, as diverse networks were able to join the Internet with ease. Because of its simplicity and statelessness, in-network packet forwarding was easy to be implemented in specialized hardware network processors, enabling the exponential growth of Internet traffic. Beyond providing simple connectivity, the rest—implementation of high-level services—was left to software running on the general purpose host systems at the end. On end nodes, the flexibility and programmability of the software on general-purpose hosts enabled innovative applications, such as World Wide Web. While the end-to-end principle still stands up as an useful architectural guideline of computer networking, we have seen many trends that do not strictly adhere to the principle. In terms of where functionality should be placed, the boundary between “dumb, fast core in hardware” versus “smart, slow edge in software" is getting blurred. For instance, commercial ISPs are under constant pressure to provide value-added services, such as content distribution and virus scanning, to find a new source of revenue in the highly competitive market [61]. In enterprise networks, the growing need for security and reliability require the network to implement additional network features beyond simple packet forwarding, and hence has led to the proliferation of network middleboxes [113]. These trends have brought sophisticated functionality into the network. On the other hand, the advent of network virtualization and cloud computing has placed much of packet forwarding—VMs or cloud sites—on general-purpose servers in place of dedicated hardware appliances.
As a result, software is playing an increasingly crucial role in network dataplane architec-ture, with its new domain (network core as well as edge) and new use case (low-level network
2 functions as well as high-level services). The rise of software packet processing1, which we
define as software-based dataplane implementation running on general-purpose processors, can be attributed to two simple factors: necessity and feasibility.
1. Necessity: The network dataplane is desired to support new protocols, features, and applications. Software is inherently easier to program and more flexible to adopt new updates. In addition, virtualization decouples of logical services from the underlying physical infrastructure, which need specialized network appliances to be replaced with software running on general-purpose servers.
2. Feasibility: The common belief was that software is too slow to be a viable solution for packet processing. The recent progress in software packet processing, however, has made it as a viable approach. Improvements are from both hardware and software. Commodity off-the-shelf servers have greatly boosted I/O capacity with various archi-tectural improvements, such as multi-core processors, integrated memory controllers, and high-speed peripheral bus, to name a few [26]. Combined with efficient imple-mentations of network device drivers for low-overhead packet I/O, software packet processing has shown potential for processing 1–100s of Gbps on a single server [24, 34, 41,103], improving by orders of magnitude over the last decade.
Software packet processing comes with its own challenges to address. First, unlike the common assumptions, being software does not necessarily grant rapid development and de-ployment with new functionality. In order to introduce a new feature to legacy implemen-tations, such as network stacks in operating system kernel, one has to deal with large and complex existing codebase, convince “upstream” maintainers of its necessity and usefulness, and wait for a new release and its wide-spread deployment. This whole process may easily take several months, if not years. Second, building a high-performance software dataplane is rather like a black art: practiced with experience, rather than principled design; and driven by application-specific, ad-hoc techniques. There do exist specialized and streamlined dat-apath implementations for various use cases (e.g., [24, 41, 69, 73, 104]), showing that it
is possible for software packet processing to achieve high performance. However, a ques-tion still remains regarding whether we could achieve the same level of performance with: i) a wider spectrum of applications, beyond specialization; and ii) mature, fully-featured implementations, beyond streamlining.
In this dissertation, we present two systems for high-performance software packet process-ing, MegaPipe and BESS (Berkeley Extensible Software Switch). While these two systems focus on different layers of the network stack, they both aim to build a general-purpose framework that a variety of applications can be built upon. MegaPipe and BESS also share the same approach to system design; instead of extending the design of an existing system or improve its internal implementation, we took a clean-slate approach to avoid limitations
1Here we do not limit the use of the term “packet” for network datagrams. Rather, we use it as an
umbrella term for network traffic in general, from the lower, physical/datalink layers all the way up to the application layer in the network stack.
1.1. SUMMARY OF CONTRIBUTIONS 3
imposed by the legacy abstractions of existing systems. Many design aspects of the existing network stacks were founded decades ago, when the (literally) millionfold increase in network traffic volume and the diverse set of applications of today were beyond imagination. Consid-ering the growing importance of software packet processing, we believe that it is worthwhile to revisit its design space and explore ways to implement a high-performance dataplane, without sacrificing programmability or extensibility.
1.1
Summary of Contributions
We start the first half of this dissertation with MegaPipe, in Chapter3. The performance of network servers is heavily determined by the efficiency of underlying network I/O API. We examined BSD Socket API, the de-facto standard programming interface for network I/O, and evaluated its impact on network server performance. The API was designed three decades ago, when the processing power of servers were roughly a million times lower and the scale, usage, and application of network servers were far more primitive than today.
We make two research contributions with MegaPipe. Firstly, we identify and quantify the sources of performance inefficiency in BSD Socket API. We show that the API is suboptimal in terms of processor usage, especially when used for the use case that we define “message-oriented workload”. In this workload network connections have a short lifespan and carry small messages, as with HTTP, RPC, key-value database servers, etc. Such workloads expose three performance issues of BSD Socket API: 1) system calls are excessively invoked incurring high kernel-user mode switch cost, 2) fie descriptor abstraction imposes high overheads for network connections, and 3) the processor cache usage of the API is not multi-core friendly, causing congestion of cache coherent traffic on modern processors. We conclude that the root cause of these problems is that BSD Socket API was not designed with concurrency in mind, in terms of both workloads (concurrent client connections) and platforms (multi-core processors).
Secondly, we present a new network programming API for high-performance network I/O. In contrast to many existing work by others, MegaPipe takes a clean-slate approach; it is designed from scratch rather than extending the existing BSD Socket API, in order to eliminate fundamental performance limiting factors imposed by its legacy abstractions. Such limiting factors include use of file descriptors for network connections, polling-based event handling, and excessive system call invocation for I/O operations.
We propose “channel” as the key design concept of MegaPipe, which is a per-core, bidi-rectional pipe between the kernel space and user applications. The channel multiplexes asynchronous I/O requests and event notifications from concurrent network connections. As compared to the BSD Socket API, our channel-based design enables three key optimiza-tions: 1) the channel abstracts network connections as handles, which are much lighter than regular file descriptors; 2) requests and event notifications in the channel can be batched transparently (thus amortizing the cost of system calls), exploiting data parallelism from in-dependent network connections; and 3) since the channel is per-core, the system capacity can
1.2. OUTLINE AND PREVIOUSLY PUBLISHED WORK 4
scale linearly without cache contention in multi-core environments. We show that MegaPipe can boost the performance of network servers significantly, in terms of both per-core and aggregate throughput.
In the latter half of this dissertation we present BESS. BESS works at lower layers of the network stack than MegaPipe, mostly on Data Link (L2) and Network (L3) layers in the traditional OSI model. BESS is a modular framework to build dataplane for various types of network functions, such as software-augmented network interface card (NIC), virtual switches, and network middleboxes. BESS is designed to be not only highly programmable and extensible, but also readily deployable as it is backward compatible with existing com-modity off-the-shelf hardware. Its low overhead makes BESS suitable for high-performance network function dataplane.
Heavily inspired by Click [65], BESS adopts a modular pipeline architecture based on dataflow graph. BESS can be dynamically configured as a custom datapath at runtime, by composing small components called “modules”. Individual modules performs some module-specific packet processing, such as classification, forwarding, en/decapsulation, transforma-tion, monitoring, etc. Each module can be independently extensible and configurable.
BESS itself is neither pre-configured nor hard-coded to provide particular functionality, such as Ethernet bridging or traffic encryption. Instead, the modularity of BESS allows external applications, or controllers, to program their own packet processing datapath by combining modules, built-in or newly implemented. The controller can translate some high-level, application-specific network policy into a BESS dataflow graph in a declarative manner. For example, one can configure BESS to function as an IP router with built-in firewall functionality. Since the datapath can be highly streamlined for specific use cases and modules in the dataflow graph can be individually optimized, BESS is suitable for building a high-performance network dataplane.
BESS incorporates various novel design concepts to enable modular and flexible network functions without compromising on performance. Pervasive batch processing of packets boosts packet processing performance by amortizing per-packet overhead. Dynamic meta-data allows modules to exchange per-packet metameta-data in a safe, efficient, and modular man-ner. With dynamic metadata, modules can be added and evolve individually, without intro-ducing code bloat or complexity due to functionality coupling. BESS adopts “traffic class” as a first-class abstraction, allowing external controllers to control how processor and network resources are shared among traffic classes. This mechanism enables various service-level ob-jectives to be enforced, such as performance isolation, guarantee, and restriction, all of which are crucial for supporting diverse use cases. We illustrate the details of BESS in Chapter5.
1.2
Outline and Previously Published Work
The remainder of this dissertation is organized as follows. We introduce two systems that incorporate various novel techniques to support high-performance packet processing at two different layers: application-level upper layer and packet-level lower layer. Chapter 3
1.3. RESEARCH PROJECTS NOT INCLUDED IN THIS DISSERTATION 5
demonstrates MegaPipe, a new programming API for higher-layer network I/O operations at network endpoints, and Chapter4describes its applications. In Chapter5we present BESS, a modular framework to build lower-layer network functions running in-network. Chapter6 introduces BESS-based research projects in which the author participated. Finally Chapter8 concludes this dissertation and discusses suggestions for future work.
This dissertation includes previously published, co-authored material with their written permission. The material in Chapter 3 is adopted from [42], and the material in Chapter 5 is based on [40]. Chapter 5 briefly covers work published in [88, 135].
1.3
Research Projects Not Included in This Dissertation
As part of the graduate course, the author also worked on other topics that are not covered here, although they are broadly related to this dissertation under the common theme of high-performance networked systems. These topics and their resulting publications are listed as follows:• Expressive programming abstraction for next-generation datacenters [43]: The traditional servercentric architecture has determined the way in which the ex-isting dataintensive computation frameworks work. Popular largescale computation frameworks, such as MapReduce and its derivatives, rely on sequential access over large blocks to mitigate high interserver latency. The expressiveness of this batch-oriented programming model is limited by embarrassingly parallel operations, which are not applicable to interactive tasks based on random accesses to dataset.
The low-latency communication in the disaggregated datacenter architecture will en-able new kinds of applications that have never been possible in traditional datacenters. In this work we develop and present Celias, a concurrent programming model to fully leverage the “pool of resources” semantics and low endtoend latency of the new datacen-ter architecture. It provides intuitive yet powerful programming abstractions for large and complex tasks, while still providing elastic scaling and automatic fault tolerance. • Network support for resource disaggregation [35, 39]: Datacenters have
tra-ditionally been a collection of individual servers, each of which aggregates a fixed amount of computing, memory, storage, and network resources as an independent physical entity. Extrapolating from recent trends, this research work envisages that future datacenters will be architected in a drastically different manner: all computa-tional resources within a server will be disaggregated into standalone blades, and the datacenter network will directly interconnect them. This new architecture will enable sustainable evolution of hardware components, high utilization of datacenter resources, and high cost effectiveness.
The unified interconnect is the most critical piece to realize resource disaggregation. As communication that was previously contained within a server now hits the datacenter-wide fabric, resource disaggregation increases load on the network and makes the need
1.3. RESEARCH PROJECTS NOT INCLUDED IN THIS DISSERTATION 6
for strict performance guarantees. Our preliminary experiments with latency/band-width requirements for popular datacenter workloads indicate that the unified fabric might be within reach, even with current 10G/40G interconnect technologies.
• Safe and modular programming model for network functions [89]: The main premise of NFV, moving hardware network functions to virtualized software environ-ment, has proven more challenging than expected. We posit that the root cause of this delay in transition is twofold. First, developing new NFs is a time-consuming process that requires significant expertise. Developers have to rediscover and reapply the same set of optimization techniques, to build a high-performance network function. Today, building NFs lacks what modern data analytics frameworks (e.g., Spark [137] and Dryad [52]) provide: high-level, customizable network processing elements that can be used as building blocks for NFs. Second, the high overheads associated with hardware-provided isolations, VMs and containers, hinders meeting the performance requirements of network service providers and enterprises.
In this research project, we design and implement Netbricks, a safe and fast framework for network functions. NetBricks is a development framework that enables rapid im-plementation of new network functions, achieved with high-level abstractions tailored for network function dataplane. At the same time, Netbricks is also a runtime frame-work that allows various netframe-work functions to be safely chained, even if they are from multiple untrusted vendors and tenants, with theoretically minimal overheads. The key contribution of this work is the technique that we named “Zero-Copy Software Iso-lation” (ZCSI). ZCSI provides packet and state isolation for network functions with no performance penalty, not requiring any special isolation mechanisms from hardware.
7
Chapter 2
Background
In this chapter, we explore a few notable ongoing trends that are relevant to software packet processing, along with their motivations, implications, and challenges.
2.1
Packet Processing under Multi-Core Environments
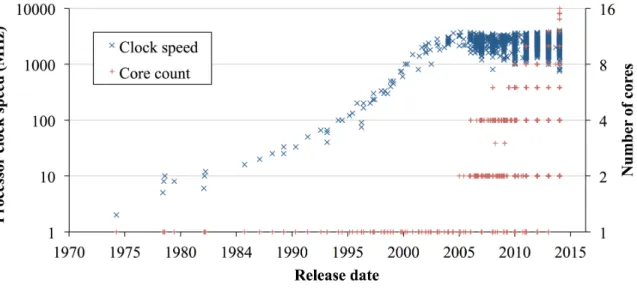
Microprocessor design paradigms have changed greatly over the last decades. In the past, processor performance improvement used to be in the form of an exponential increase in clock frequency (Figure2.1). Software performance improved with increase in clock speed without any extra effort on the part of the developer. The exponential increase in clock frequency stopped in the early 2000s due to physical limits such as power consumption (and thereforeFigure 2.1: Evolution of AMD and Intel microprocessors in terms of clock frequency and number of cores per processor (log-scaled). The raw data was obtained from Stanford CPUDB [23].
2.1. PACKET PROCESSING UNDER MULTI-CORE ENVIRONMENTS 8
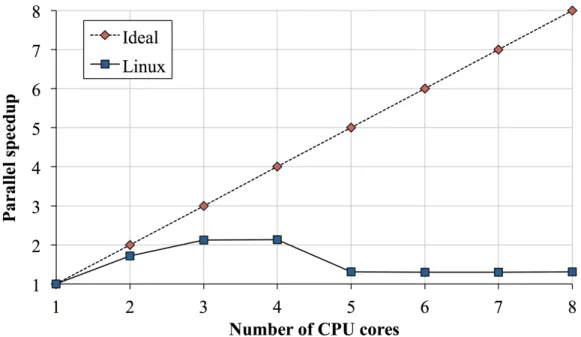
Figure 2.2: The parallel speedup of the Linux network stack, measured with a RPC-like workload on a 8-core server. For the experiment we generated TCP client connections, each of which exchanges a pair of 64-byte dummy request and request.
heat dissipation) and the current leakage problems. Instead, microprocessors started adopt-ing the multi-core architecture, i.e., incorporatadopt-ing multiple independent processadopt-ing units (cores) in a single processor package, to provide more processing power. Now multi-core processors have become the norm, and today typical high-end servers are equipped with two or four processors, each of which has 4-32 cores as of today.
Any software needs to be fundamentally redesigned in order to exploit the multi-core architecture, and software packet processing is no exception. The network stack must be parallelized to keep pace with increase in network bandwidth, as individual cores are unlikely to get significantly faster in the foreseeable future. The current best practice of network stack parallelization is to duplicate the processing pipeline across cores, ensuring consistent access to shared data structures (e.g., TCP connection states or IP forwarding table) with explicit
locks and other synchronization mechanisms [24, 133]. While implementing this scheme is straightforward, its performance is known to be suboptimal due to inter-core synchronization costs, such as serialization and cache coherence traffic [12].
Figure 2.2 shows the non-ideal scaling behavior of the Linux TCP/IP stack. The “Ideal” line represents desired linear scalability, i.e., speedup by a factor of N with N cores. The actual scaling behavior of Linux is far worse than the ideal case, showing only 2.13x speedup with 3 cores at peak. The aggregate throughput collapses as we add more cores. This motivating example clearly indicates that the current architecture cannot effectively exploit multi-core processors. For optimal performance with near-linear scalability, we need to use design principles which minimize inter-core communication in our network stack.
2.2. VIRTUALIZATION (OF EVERYTHING) 9
2.2
Virtualization (of Everything)
The basic processing unit of the current datacenter is a virtual machine (or containers, as a lightweight form of server virtualization). With server virtualization, one physical server can be divided into multiple, isolated virtual machines. Each virtual server acts like an independent physical device, being capable of running its own operating system. Server virtualization brings a few obvious advantages. First, the resource utilization of physical resources is inherently higher than that of bare-metal servers, since multiple virtual machines can be consolidated into one server. Second, the physical infrastructure of datacenters can be highly homogeneous; a large array of inexpensive, commodity servers can be utilized to run a wide range of applications under a virtualized environment. Third, in the presence of workload fluctuation, resources can be assigned elastically by adjusting the number of virtual servers, as physical servers and applications running on them are decoupled.
Server virtualization brings a few challenges to the network fabric of datacenters, in order to achieve its full potential. Virtual machine instances basic network connectivity network connectivity, which used to be solely delivered via dedicated physical network appliances. Network virtualization achieves them by creating an abstracted view of virtual network re-sources from the underlying network infrastructure, consisting of both hardware and software components. This virtualized network must meet not only the requirements of traditional networks, but also ones that are specific to virtualized environments, such as VM mobility, multi-tenancy, and performance isolation.
Network function virtualization (NFV) takes network virtualization one step further, both in its application domain (not only datacenters but also wide-area networks) and its scope (advanced network functions beyond basic network connectivity). NFV aims to virtualize a wide variety of network functions including switches and routers, as well as layer 4-7 middleboxes such as load balancers, firewalls, WAN accelerators, and VPNs, and interconnect them to create a service chain. The transition from proprietary, purpose-built network gears to network functions running on general-purpose computing platforms aims to enable more open, flexible, and economical networking. From the dataplane perspective, NFV adds significant burden to software packet processing. Server virtualization already introduces inherent overheads over bare-metal computing (e.g.,IO emulation and VM exit). In addition
to that, NFV requires not only fast packet processing in each NF, but also an efficient way to relay packets across NFs.
2.3
Network Stack Specialization
Many recent research projects report that specialized network stacks can achieve very
high performance: an order of magnitude or two higher than the performance we can expect from general-purpose network stacks, in terms of throughput and/or latency. Examples include software routers [24,41], web servers [54], DNS servers [74], and key-value stores [60, 69]. We note two common themes for achieving high performance in the design of these
2.3. NETWORK STACK SPECIALIZATION 10
specialized systems. First, they tightly couple every layer of the network stack in a monolithic architecture: from the NIC device driver, through the (streamlined) protocol suite, up to the application logic – which used to be a separate entity in general-purpose systems – itself. This approach is amenable to aggressive cross-layer optimizations. Second, their dataplane implementations bypass the operating system (and its general-purpose network stack) and make exclusive use of hardware resources; i.e., NICs and processor cores.
The performance improvement from these specialized network stacks comes at the cost of generality. One obvious drawback of application-specific optimizations is that they do not readily benefit other existing (thousands of) network applications, unless we heavily modify each application. Also, the holistic approach adopted by the specialized systems rules out the traditional roles of operating systems in networking: regulating use of shared hardware resources, maintaining the global view of the system, (de-)multiplexing data stream across protocols and applications, providing stable APIs for portability, and so on. Many research papers claim that this issue can be avoided by offloading such OS features onto NIC hardware. However, as we will discuss in Chapter5, it is unrealistic to assume that NIC hardware would provide all functionality required for a variety of applications in a timely manner.
Although the reported performance of specialized network stacks is impressive, we argue that the following question has been overlooked in the systems research community: how much of the speedup of those systems is fundamental to the design (e.g., monolithic
ar-chitecture with cross-layer optimizations) and how much is from artifacts (e.g., suboptimal
implementation of existing general-purpose network stacks)? In other words, is it possible to have a general-purpose network stack with the performance of specialized systems? To answer this question, this dissertation examines 1) how and when are the individual tech-niques developed for specialized systems are particularly effective? 2) how many of them can be back-ported to general-purpose network stacks? 3) what would be the fundamental trade-off between generality and performance?
11
Chapter 3
MegaPipe: A New Programming
Interface for Scalable Network I/O
3.1
Introduction
Existing network APIs on multi-core systems have difficulties scaling to high connection rates and are inefficient for “message-oriented” workloads, by which we mean workloads with short connections1 and/or small messages. Such message-oriented workloads include HTTP,
RPC, key-value stores with small objects (e.g., RAMCloud [86]), etc. Several research efforts have addressed aspects of these performance problems, proposing new techniques that offer valuable performance improvements.
However, they all innovate within the confines of the traditional socket-based networking APIs, by eitheri)modifying the internal implementation but leaving the APIs untouched [20, 91, 119], or ii) adding new APIs to complement the existing APIs [10, 30, 31, 68, 134].
While these approaches have the benefit of maintaining backward compatibility for existing applications, the need to maintain thegenerality of the existing API – e.g., its reliance on file
descriptors, support for blocking and nonblocking communication, asynchronous I/O, event polling, and so forth – limits the extent to which it can be optimized for performance. In contrast, a clean-slate redesign offers the opportunity to present an API that is specialized for high performance network I/O.
An ideal network API must offer not only high performance but also a simple and intuitive programming abstraction. In modern network servers, achieving high performance requires efficient support for concurrent I/O so as to enable scaling to large numbers of connections
per thread, multiple cores, etc. The original socket API was not designed to support such concurrency. Consequently, a number of new programming abstractions (e.g.,epoll,kqueue, etc.) have been introduced to support concurrent operation without overhauling the socket API. Thus, even though the basic socket API is simple and easy to use, programmers face the
1We use “short connection” to refer to a connection with a small number of messages exchanged; this is
3.2. MOTIVATION 12
unavoidable and tedious burden of layering several abstractions for the sake of concurrency. Once again, a clean-slate design of network APIs offers the opportunity to design a network API from the ground up with support for concurrent I/O.
Given the central role of networking in modern applications, we posit that it is worthwhile to explore the benefits of a clean-slate design of network APIs aimed at achieving both high performance and ease of programming. In this chapter we present MegaPipe, a new API for efficient, scalable network I/O. The core abstraction MegaPipe introduces is that of a
channel – a per-core, bi-directional pipe between the kernel and user space that is used
to exchange both asynchronous I/O requests and completion notifications. Using channels,
MegaPipe achieves high performance through three design contributions under the roof of a single unified abstraction:
• Partitioned listening sockets: Instead of a single listening socket shared across cores, MegaPipe allows applications to clone a listening socket and partition its asso-ciated queue across cores. Such partitioning improves performance with multiple cores while giving applications control over their use of parallelism.
• Lightweight sockets: Sockets are represented by file descriptors and hence inherit some unnecessary file-related overheads. MegaPipe instead introduces lwsocket, a lightweight socket abstraction that is not wrapped in file-related data structures and thus is free from system-wide synchronization.
• System Call Batching: MegaPipe amortizes system call overheads by batching asyn-chronous I/O requests and completion notifications within a channel.
We implemented MegaPipe in Linux and adapted two popular applications – mem-cached [Memcached] and the nginx [123] – to use MegaPipe. In our microbenchmark tests on an 8-core server with 64 B messages, we show that MegaPipe outperforms the baseline Linux networking stack between 29% (for long connections) and 582% (for short connec-tions). MegaPipe improves the performance of a modified version of memcached between 15% and 320%. For a workload based on real-world HTTP traffic traces, MegaPipe improves the performance of nginx by 75%.
The rest of the chapter is organized as follows. We expand on the limitations of existing network stacks in §3.2, then present the design and implementation of MegaPipe in §5.2 and §3.4, respectively. We evaluate MegaPipe with microbenchmarks and macrobenchmarks in §3.5, and review related work in §7.1.
3.2
Motivation
Bulk transfer network I/O workloads are known to be inexpensive on modern commodity servers; one can easily saturate a 10 Gigabit (10G) link utilizing only a single CPU core. In contrast, we show that message-oriented network I/O workloads are very CPU-intensive
3.2. MOTIVATION 13
and may significantly degrade throughput. In this section, we discuss limitations of the current BSD socket API (§3.2.1) and then quantify the performance with message-oriented workloads with a series of RPC-like microbenchmark experiments (§3.2.2).
3.2.1
Sources of Performance Inefficiency
In what follows, we discuss known sources of inefficiency in the BSD socket API. Some of these inefficiencies are general, in that they occur even in the case of a single core, while others manifest only when scaling to multiple cores – we highlight this distinction in our discussion.
Issues Common to Both Single-Core and Multi-Core Envronments
• File Descriptors: The POSIX standard requires that a newly allocated file descriptor be the lowest integer not currently used by the process [124]. Finding ‘the first hole’ in a file table is an expensive operation, particularly when the application maintains many connections. Even worse, the search process uses an explicit per-process lock (as files are shared within the process), limiting the scalability of multi-threaded applications. In our socket() microbenchmark on an 8-core server, the cost of allocating a single FD is roughly 16% greater when there are 1,000 existing sockets as compared to when there are no existing sockets.
• System Calls: Previous work has shown that system calls are expensive and nega-tively impact performance, both directly (mode switching) and indirectly (cache pollu-tion) [119]. This performance overhead is exacerbated for message-oriented workloads with small messages that result in a large number of I/O operations.
Issues Specific to Multi-Core Scaling
• VFS: In UNIX-like operating systems, network sockets are abstracted in the same way as other file types in the kernel; the Virtual File System (VFS) [64] associates each socket with corresponding file instance, inode, and dentry data structures. For message-oriented workloads with short connections, where sockets are frequently opened as new connections arrive, servers quickly become overloaded since those globally visible objects cause system-wide synchronization cost [20]. In our microbenchmark, the VFS overhead for socket allocation on eight cores was 4.2 times higher than the single-core case.
• Contention on Accept Queue: As explained in previous work [20, 91], a single lis-tening socket (with its accept() backlog queue and exclusive lock) forces CPU cores to serialize queue access requests; this hotspot negatively impacts the performance of both producers (kernel threads) enqueueing new connections and consumers (applica-tion threads) accepting new connec(applica-tions. It also causes CPU cache conten(applica-tion on the shared listening socket.
3.2. MOTIVATION 14
• Lack of Connection Affinity: In Linux, incoming packets are distributed across CPU cores on a flow basis (hash over the 5-tuple), either by hardware (RSS [102]) or software (RPS [45]); all receive-side processing for the flow is done on a core. On the other hand, the transmit-side processing happens on the core at which the application thread for the flow resides. Because of the serialization in the listening socket, an application thread calling accept()may accept a new connection that came through a remote core; RX/TX processing for the flow occurs on two different cores, causing expensive cache bouncing on the TCP control block (TCB) between those cores [91]. While the per-flow redirection mechanism [50] in NICs eventually resolves this core disparity, short connections cannot benefit since the mechanism is based on packet sampling.
In parallel with our work, the Affinity-Accept project [91] has recently identified and solved the first two issues, both of which are caused by the shared listening socket. We discuss our approach (partitioning) and its differences in §3.3.4. To address other issues, we introduce the concept of lwsocket (§3.3.4, for FD and VFS overhead) and batching (§3.3.4, for system call overhead).
3.2.2
Performance of Message-Oriented Workloads
While it would be ideal to separate the aforementioned inefficiencies and quantify the cost of each, tight coupling in semantics between those issues and complex dynamics of synchronization/cache make it challenging to isolate individual costs.
Rather, we quantify their compound performance impact with a series of
microbench-marks in this work. As we noted, the inefficiencies manifest themselves primarily in workloads that involve short connections orsmall-sized messages, particularly with increasing numbers
of CPU cores. Our microbenchmark tests thus focus on these problematic scenarios. Experimental Setup
For our tests, we wrote a pair of client and server microbenchmark tools that emulate RPC-like workloads. The client initiates a TCP connection, exchanges multiple request and response messages with the server and then closes the connection.2 We refer to a single
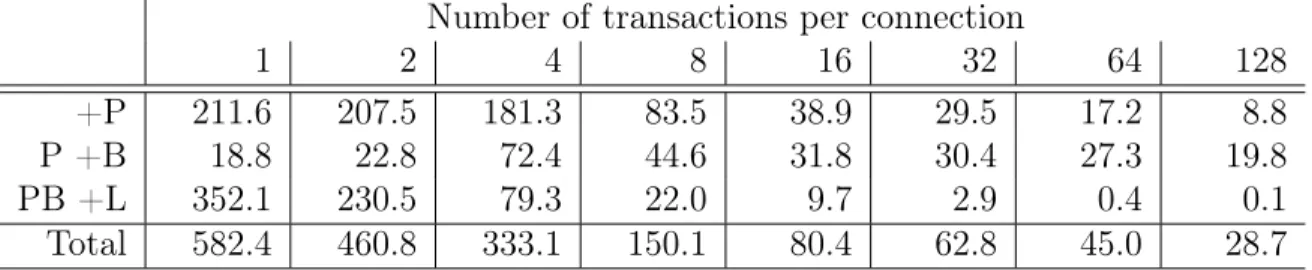
request-response exchange as atransaction. Default parameters are 64 B per message and 10
transactions per connection, unless otherwise stated. Each client maintains 256 concurrent connections, and we confirmed that the client is never the bottleneck. The server creates a single listening socket shared by eight threads, with each thread pinned to one CPU core. Each event-driven thread is implemented with epoll [30] and the non-blocking socket API. Although synthetic, this workload lets us focus on the low-level details of network I/O overhead without interference from application-specific logic. We use a single server and
2In this experiment, we closed connections with RST, to avoid exhaustion of client ports caused by
3.2. MOTIVATION 15 0 0.3 0.6 0.9 1.2 1.5 1.8 1 2 4 8 16 32 64 128 Th rou gh p u t (1M tr an s/ s)
# of Transactions per Connection
Baseline Throughput MegaPipe
0 20 40 60 80 100 0 2 4 6 8 10 64 128 256 512 1K 2K 4K 8K 16K C P U U sage (%) Th rou gh p u t (G b p s) Message Size (B)
Baseline CPU Usage MegaPipe
0 20 40 60 80 100 0 0.3 0.6 0.9 1.2 1.5 1 2 3 4 5 6 7 8 Effi ci en cy (%) Th rou gh p u t (1M tr an s/ s) # of CPU Cores
Baseline Per-Core Efficiency MegaPipe
(a) Connection lifespan
0 0.3 0.6 0.9 1.2 1.5 1.8 1 2 4 8 16 32 64 128 Th rou gh p u t (1M tr an s/ s)
# of Transactions per Connection
Baseline Throughput MegaPipe
0 20 40 60 80 100 0 2 4 6 8 10 64 128 256 512 1K 2K 4K 8K 16K C P U U sage (%) Th rou gh p u t (G b p s) Message Size (B)
Baseline CPU Usage MegaPipe
0 20 40 60 80 100 0 0.3 0.6 0.9 1.2 1.5 1 2 3 4 5 6 7 8 Effi ci en cy (%) Th rou gh p u t (1M tr an s/ s) # of CPU Cores
Baseline Per-Core Efficiency MegaPipe
(b) Message size 0 0.3 0.6 0.9 1.2 1.5 1.8 1 2 4 8 16 32 64 128 Th rou gh p u t (1M tr an s/ s)
# of Transactions per Connection
Baseline Throughput MegaPipe
0 20 40 60 80 100 0 2 4 6 8 10 64 128 256 512 1K 2K 4K 8K 16K C P U U sage (%) Th rou gh p u t (G b p s) Message Size (B)
Baseline CPU Usage MegaPipe
0 20 40 60 80 100 0 0.3 0.6 0.9 1.2 1.5 1 2 3 4 5 6 7 8 Effi ci en cy (%) Th rou gh p u t (1M tr an s/ s) # of CPU Cores
Baseline Per-Core Efficiency MegaPipe
(c) Number of cores
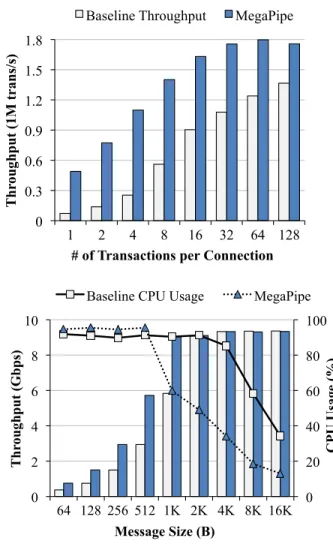
Figure 3.1: The negative impact in performance from each of varying factor. The default parameters are 64 B messages, 10 transactions per connection, and 8 cores.
3.2. MOTIVATION 16
three client machines, connected through a dedicated 10G Ethernet switch. All test systems use the Linux 3.1.3 kernel and ixgbe 3.8.21 10G Ethernet device driver [49] (with interrupt coalescing turned on). Each machine has a dual-port Intel 82599 10G NIC, 12 GB of DRAM, and two Intel Xeon X5560 processors, each of which has four 2.80 GHz cores. We enabled the multi-queue feature of the NICs with RSS [102] and FlowDirector [50], and assigned each RX/TX queue to one CPU core.
In this section, we discuss the result of the experiments Figure 3.1 labeled as “Baseline.” For comparison, we also include the results with our new API, labeled as “MegaPipe,” from the same experiments.
Performance with Short Connections
TCP connection establishment involves a series of time-consuming steps: the 3-way hand-shake, socket allocation, and interaction with the user-space application. For workloads with short connections, the costs of connection establishment are not amortized by sufficient data transfer and hence this workload serves to highlight the overhead due to costly connection establishment.
We show how connection lifespan affects the throughput by varying the number of trans-actions per connection in Figure 3.1(a), measured with eight CPU cores. Total throughput is significantly lower with relatively few (1–8) transactions per connection. The cost of con-nection establishment eventually becomes insignificant for 128+ transactions per concon-nection, and we observe that throughput in single-transaction connections is roughly 19 times lower than that of long connections!
Performance with Small Messages
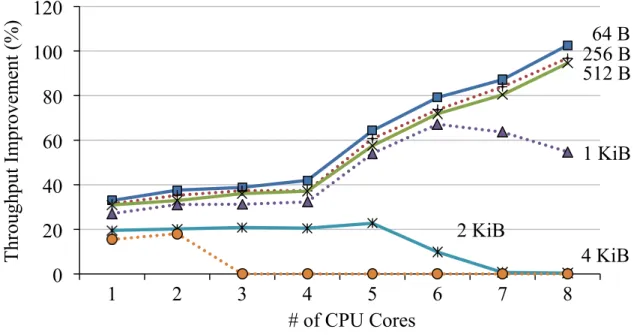
Small messages result in greater relative network I/O overhead in comparison to larger messages. In fact, the per-message overhead remains roughly constant and thus, independent of message size; in comparison with a 64 B message, a 1 KiB message adds only about 2% overhead due to the copying between user and kernel on our system, despite the large size difference.
To measure this effect, we perform a second microbenchmark with response sizes varying from 64 B to 64 KiB (varying the request size in lieu of or in addition to the response size had almost the same effects). Figure 3.1(b) shows the measured throughput (in Gbps) and CPU usage for various message sizes. It is clear that connections with small-sized messages adversely affect the throughput. For small messages (≤ 1 KiB) the server does not even saturate the 10G link. For medium-sized messages (2–4 KiB), the CPU utilization is extremely high, leaving few CPU cycles for further application processing.
Performance Scaling with Multiple Cores
Ideally, throughput for a CPU-intensive system should scale linearly with CPU cores. In reality, throughput is limited by shared hardware (e.g., cache, memory buses) and/or
3.3. DESIGN 17
software implementation (e.g., cache locality, serialization). In Figure 3.1(c), we plot the throughput for increasing numbers of CPU cores. To constrain the number of cores, we adjust the number of server threads and RX/TX queues of the NIC. The lines labeled “Efficiency” represent the measured per-core throughput, normalized to the case of perfect scaling, where N cores yield a speedup of N.
We see that throughput scales relatively well for up to four cores – the likely reason being that, since each processor has four cores, expensive off-chip communication does not take place up to this point. Beyond four cores, the marginal performance gain with each additional core quickly diminishes, and with eight cores, speedup is only 4.6. Furthermore, it is clear from the growth trend that speedup would not increase much in the presence of additional cores. Finally, it is worth noting that the observed scaling behavior of Linux highly depends on connection duration, further confirming the results in Figure3.1(a). With only one transaction per connection (instead of the default 10 used in this experiment), the speedup with eight cores was only 1.3, while longer connections of 128 transactions yielded a speedup of 6.7.
3.3
Design
MegaPipe is a new programming interface for high-performance network I/O that ad-dresses the inefficiencies highlighted in the previous section and provides an easy and intuitive approach to programming high concurrency network servers. In this section, we present the design goals, approach, and contributions of MegaPipe.
3.3.1
Scope and Design Goals
MegaPipe aims to accelerate the performance of message-oriented workloads, where con-nections are short and/or message sizes are small. Some possible approaches to this problem would be to extend the BSD Socket API or to improve its internal implementation. It is hard to achieve optimal performance with these approaches, as many optimization opportunities can be limited by the legacy abstractions. For instance: i)sockets represented as files inherit
the overheads of files in the kernel; ii)it is difficult to aggregate BSD socket operations from
concurrent connections to amortize system call overheads. We leave optimizing the message-oriented workloads with those dirty-slate (minimally disruptive to existing API semantics and legacy applications) alternatives as an open problem. Instead, we take a clean-slate approach in this work by designing a new API from scratch.
We design MegaPipe to be conceptually simple, self-contained, and applicable to existing event-driven server applications with moderate efforts. The MegaPipe API provides a unified interface for various I/O types, such as TCP connections, UNIX domain sockets, pipes, and disk files, based on the completion notification model (§3.3.2) We particularly focus on the performance of network I/O in this chapter. We introduce three key design concepts of MegaPipe for high-performance network I/O: partitioning (§3.3.4), lwsocket (§3.3.4), and
3.3. DESIGN 18
batching (§3.3.4), for reduced per-message overheads and near-linear multi-core scalability. In this work, we mostly focus on an efficient interface between kernel and network appli-cations; we do not address device driver overheads, the TCP/IP stack, or application-specific logic.
3.3.2
Completion Notification Model
The current best practice for event-driven server programming is based on the readiness model. Applications poll the readiness of interested sockets with select/poll/epoll and issue non-blocking I/O commands on the those sockets. The alternative is the completion notification model. In this model, applications issue asynchronous I/O commands, and the kernel notifies the applications when the commands are complete. This model has rarely been used for network servers in practice, though, mainly because of the lack of socket-specific operations such asaccept/connect/shutdown(e.g., POSIX AIO [124]) or poor mechanisms for notification delivery (e.g., SIGIO signals).
MegaPipe adopts the completion notification model over the readiness model for three reasons. First, it allows transparent batching of I/O commands and their notifications. Batching of non-blocking I/O commands in the readiness model is very difficult without the explicit assistance from applications. Second, it is compatible with not only sockets but also disk files, allowing a unified interface for any type of I/O. Lastly, it greatly simplifies the complexity of I/O multiplexing. Since the kernel controls the rate of I/O with comple-tion events, applicacomple-tions can blindly issue I/O operacomple-tions without tracking the readiness of sockets.
3.3.3
Architectural Overview
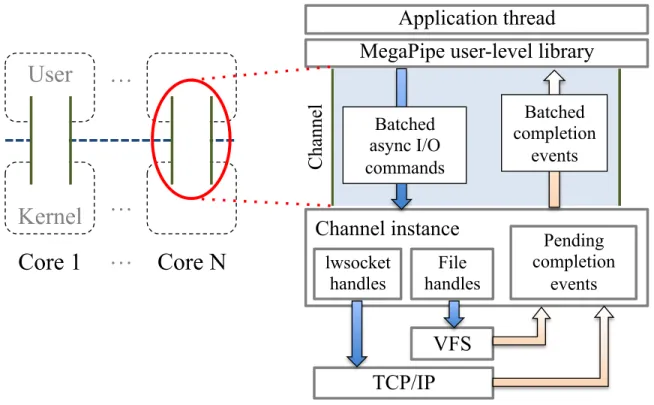
MegaPipe involves both a user-space library and Linux kernel modifications. Figure 3.2 illustrates the architecture and highlights key abstractions of the MegaPipe design. The left side of the figure shows how a multi-threaded application interacts with the kernel via MegaPipe channels. With MegaPipe, an application thread running on each core opens
a separate channel for communication between the kernel and user-space. The application thread registers ahandle (socket or other file type) to the channel, and each channel
multi-plexes its own set of handles for their asynchronous I/O requests and completion notification events.
When a listening socket is registered, MegaPipe internally spawns an independent accept queue for the channel, which is responsible for incoming connections to the core. In this way, the listening socket is not shared by all threads, butpartitioned (§3.3.4) to avoid serialization
and remote cache access.
A handle can be either a regular file descriptor or a lightweight socket, lwsocket (§3.3.4).
lwsocket provides a direct shortcut to the TCB in the kernel, to avoid the VFS overhead of traditional sockets; thus lwsockets are only visible within the associated channel.
3.3. DESIGN 19
Core 1
Kernel
User
…
…
Core N
Channel instance
File handles lwsocket handles Pending completion eventsVFS
TCP/IP
MegaPipe user-level library
Application thread
Batched async I/O commands Batched completion events…
Cha
nne
l
Figure 3.2: MegaPipe architecture
Each channel is composed of two message streams: a request stream and a completion stream. User-level applications issue asynchronous I/O requests to the kernel via the request stream. Once the asynchronous I/O request is done, the completion notification of the request is delivered to user-space via the completion stream. This process is done in a
batched (§3.3.4) manner, to minimize the context switch between user and kernel. The
MegaPipe user-level library is fully responsible for transparent batching; MegaPipe does not need to be aware of batching.
3.3.4
Design Components
Listening Socket Partitioning
As discussed in §3.2.1, the shared listening socket causes two issues in the multi-core context: i)contention on the accept queue andii)cache bouncing between RX and TX cores
for a flow. Affinity-Accept [91] proposes two key ideas to solve these issues. First, a listening socket has per-core accept queues instead of the shared one. Second, application threads that callaccept()prioritize their local accept queue. In this way, connection establishment becomes completely parallelizable and independent, and all the connection establishment, data transfer, and application logic for a flow are contained in the same core.
In MegaPipe, we achieve essentially the same goals but with a more controlled approach. When an application thread associates a listening socket to a channel, MegaPipe spawns a
3.3. DESIGN 20
separate listening socket. The new listening socket has its own accept queue which is only responsible for connections established on a particular subset of cores that are explicitly specified by an optionalcpu_maskparameter. After a shared listening socket is registered to MegaPipe channels with disjoint cpu_mask parameters, all channels (and thus cores) have completely partitioned backlog queues. Upon receipt of an incoming TCP handshaking packet, which is distributed across cores either by RSS [102] or RPS [45], the kernel finds a “local” accept queue among the partitioned set, whose cpu_mask includes the current core. On the application side, an application thread accepts pending connections from its local queue. In this way, cores no longer contend for the shared accept queue, and connection establishment is vertically partitioned (from the TCP/IP stack up to the application layer). We briefly discuss the main difference between our technique and that of Affinity-Accept. Our technique requires user-level applications to partition a listening socket explicitly, rather than transparently. The downside is that legacy applications do not benefit. However, explicit partitioning provides more flexibility for user applications (e.g., to forgo partitioning for single-thread applications, to establish one accept queue for each physical core in SMT systems [127], etc.) Our approach follows the design philosophy of the Corey operating system, in a way that “applications should control sharing” [19].
Partitioning of a listening socket may cause potential load imbalance between cores [91]. Affinity-Accept handles two types of load imbalance. For short-term load imbalance, a non-busy core running accept()may steal a connection from the remote accept queue on a busy CPU core. For long-term load imbalance, the flow group migration mechanism lets the NIC to distribute more flows to non-busy cores. While the current implementation of MegaPipe does not support load balancing of incoming connections between cores, the techniques made in Affinity-Accept are complementary to MegaPipe. We leave the implementation and evaluation of connection load balancing as future work.
lwsocket: Lightweight Socket
accept()ing an established connection is an expensive process in the context of the VFS layer. In Unix-like operating systems, many different types of open files (disk files, sockets, pipes, devices, etc.) are identified by afile descriptor. A file descriptor is an integer identifier
used as an indirect reference to an opened file instance, which maintains the status (e.g.,
access mode, offset, and flags such as O_DIRECT and O_SYNC) of the opened file. Multiple file instances may point to the sameinode, which represents a unique, permanent file object.
An inode points to an actual type-specific kernel object, such as TCB.
These layers of abstraction offer clear advantages. The kernel can seamlessly support various file systems and file types, while retaining a unified interface (e.g., read() and write()) to user-level applications. The CPU overhead that comes with the abstraction is tolerable for regular disk files, as file I/O is typically bound by low disk bandwidth or high seek latency. For network sockets, however, we claim that these layers of abstraction could be overkill for the following reasons:
3.3. DESIGN 21
same open file or independently open the same permanent file. The layer of indirection that file objects offer between the file table and inodes is useful in such cases. In contrast, since network sockets are rarely shared by multiple processes (HTTP socket redirected to a CGI process is such an exception) and not opened multiple times, this indirection is typically unnecessary.
2. Sockets are ephemeral. Unlike permanent disk-backed files, the lifetime of network
sockets ends when they are closed. Every time a new connection is established or torn down, its FD, file instance, inode, and dentry are newly allocated and freed. In contrast to disk files whose inode and dentry objects are cached [64], socket inode and dentry cannot benefit from caching since sockets are ephemeral. The cost of frequent (de)allocation of those objects is exacerbated on multi-core systems since the kernel maintains the inode and dentry as globally visible data structures [20].
To address these issues, we propose lightweight sockets – lwsocket. Unlike regular files,
a lwsocket is identified by an arbitrary integer within the channel, not the lowest possible integer within the process. The lwsocket is a common-case optimization for network con-nections; it does not create a corresponding file instance, inode, or dentry, but provides a straight shortcut to the TCB in the kernel. A lwsocket is only locally visible within the associated MegaPipe channel, which avoids global synchronization between cores.
In MegaPipe, applications can choose whether to fetch a new connection as a regular socket or as a lwsocket. Since a lwsocket is associated with a specific channel, one cannot use it with other channels or for general system calls, such as sendmsg(). In cases where applications need the full generality of file descriptors, MegaPipe provides a fall-back API function to convert a lwsocket into a regular file descriptor.
System Call Batching
Recent research efforts report that system calls are expensive not only due to the cost of mode switching, but also because of the negative effect on cache locality in both user and kernel space [119]. To amortize system call costs, MegaPipe batches multiple I/O requests and their completion notifications into a single system call. The key observation here is that batching can exploit connection-level parallelism, extracting multiple independent requests and notifications from concurrent connections.
Batching is transparently done by the MegaPipe user-level library for both directions user → kernel and kernel →user. Application programmers need not be aware of batching. Instead, application threads issue one request at a time, and the user-level library accumu-lates them. When i) the number of accumulated requests reaches the batching threshold, ii) there are not any more pending completion events from the kernel, or iii) the
applica-tion explicitly asks to flush, then the collected requests are flushed to the kernel in a batch through the channel. Similarly, application threads dispatch a completion notification from the user-level library one by one. When the user-level library has no more completion noti-fications to feed the application thread, it fetches multiple pending notinoti-fications from kernel
3.3. DESIGN 22
Function Parameters Description
mp_create() Create a new MegaPipe channel instance.
mp_destroy() channel Close a MegaPipe channel instance and clean up associated
resources.
mp_register() channel, fd,
cookie, cpu_mask
Create a MegaPipe handle for the specified file descriptor (either regular or lightweight) in the given channel. If a given file descriptor is a listening socket, an optional CPU mask parameter can be used to designate the set of CPU cores which will respond to incoming connections for that handle.
mp_unregister() handle Remove the target handle from the channel. All pending
completion notifications for the handle are canceled.
mp_accept() handle,
count, is_lwsocket
Accept one or more new connections from a given listening handle asynchronously. The application specifies whether to accept a connection as a regular socket or a lwsocket. The completion event will report a new FD/lwsocket and the number of pending connections in the accept queue.
mp_read() mp_write()
handle, buf,
size Issue an asynchronous I/O request. The completion eventwill report the number of bytes actually read/written.
mp_writev() handle, iovec,
iovcnt Issue an asynchronous, vectored write with multiple buffers(“gather output”)
mp_close() handle Close the connection (if still connected) and free up the
handle.
mp_disconnect() handle Close the connection in a similar manner toshutdown(). It
does not deallocate or unregister the handle.
mp_close() handle Close the connection if necessary, and free up the handle. mp_flush() channel For the given channel, push any pending asynchronous I/O
commands to the kernel immediately, rather than waiting for automatic flush events.
mp_dispatch() channel,
timeout Poll for a single completion notification from the given chan-nel. If there is no pending notification event, the call blocks until the specified timer expires. The timeout can be 0 (non-blocking) or -1 (indefinite (non-blocking)
Table 3.1: List of MegaPipe API functions for userspace applications. All I/O functions are enqueued in the channel—instead of individually invoking a system call—and are deliviered to kernel in a batch.
3.3. DESIGN 23
in a batch. We set the default batching threshold to 32 (adjustable), as we found that the marginal performance gain beyond that point is negligible.
One potential concern is that batching may affect the latency of network servers since I/O requests are queued. However, batching happens only when the server is overloaded, so it does not affect latency when underloaded. Even if the server is overloaded, the additional latency should be minimal because the batch threshold is fairly small, compared to the large queues (thousands of packets) of modern NICs[50].
3.3.5
Application Programming Interface
The MegaPipe user-level library provides a set of API functions to hide the complexity of batching and the internal implementation details. Table 3.1 presents a partial list of MegaPipe API functions. Due to lack of space, we highlight some interesting aspects of some functions rather than enumerating all of them.
The application associates a handle (either a regular file descriptor or a lwsocket) with the specified channel withmp_register(). All further I/O commands and completion noti-fications for the registered handle are done through only the associated channel. A cookie, an opaque pointer for developer use, is also passed to the kernel with handle registration. This cookie is attached in the completion events for the handle, so the application can easily identify which handle fired each event. The application calls mp_unregister() to end the membership. Once unregistered, the application can continue to use the regular FD with general system calls. In contrast, lwsockets are immediately deallocated from the kernel memory.
When a listening TCP socket is registered with the cpu_mask parameter, MegaPipe internally spawns an accept queue for incoming connections on the specified set of CPU cores. The original listening socket (now responsible for the remaining CPU cores) can be registered to other MegaPipe channels with a disjoint set of cores – so each thread can have a completely partitioned view of the listening socket.
mp_read() and mp_write() issue asynchronous I/O commands. The application should not use the provided buffer for any other purpose until the completion event, as the ownership of the buffer has been delegated to the kernel, like in other asynchronous I/O APIs. The completion notification is fired when the I/O is actually completed, i.e., all data has been copied from the receive queue for read or copied to the send queue for write. In adapting nginx and memcached, we found that vectored I/O operations (multiple buffers for a single I/O operation) are helpful for optimal performance. For example, the unmodified version of nginx invokes the writev()system call to transmit separate buffers for a HTTP header and body at once. MegaPipe supports the counterpart, mp_writev(), to avoid issuing multiple mp_write() calls or aggregating scattered buffers into one contiguous buffer.
mp_dispatch()returns one completion event as astruct mp_event. This data structure contains: i) a completed command type (e.g., read/write/accept/etc.), ii) a cookie, iii) a
result field that indicates success or failure (such as broken pipe or connection reset) with the corresponding errno value, and iv) aunion of command-specific return values.
3.3. DESIGN 24 ch = m p _ c r e a t e () h a n d l e = m p _ r e g i s t e r ( ch , l i s t e n _ s d , mask =0 x01 ) m p _ a c c e p t ( h a n d l e ) w h i l e true : ev = m p _ d i s p a t c h ( ch ) conn = ev . c o o k i e if ev . cmd == A C C E P T : m p _ a c c e p t ( conn . h a n d l e ) conn = new C o n n e c t i o n () conn . h a n d l e = m p _ r e g i s t e r ( ch , ev . fd , c o o k i e = conn ) m p _ r e a d ( conn . handle , conn . buf , R E A D S I Z E )
elif ev . cmd == READ :
m p _ w r i t e ( conn . handle , conn . buf , ev . size ) elif ev . cmd == W R I T E :
m p _ r e a d ( conn . handle , conn . buf , R E A D S I Z E ) elif ev . cmd == D I S C O N N E C T :
m p _ u n r e g i s t e r ( ch , conn . h a n d l e ) d e l e t e conn
Listing 3.1: Pseudocode for ping-pong server event loop
Listing 3.1 presents simplified pseudocode of a ping-pong server to illustrate how ap-plications use MegaPipe. An application thread initially creates a MegaPipe channel and registers a listening socket (listen_sd in this example) with cpu_mask 0x01 (first bit is set) which means that the handle is only interested in new connections established on the first core (core 0). The application then invokes mp_accept() and is ready to accept new connections. The body of the event loop is fairly simple; given an event, the server performs any appropriate tasks (barely anything in this ping-pong example) and then fires new I/O operations.
Currently MegaPipe provides only I/O-related functionality. We note that this asyn-chronous communication between kernel and user applications can be applied to other types of system calls as well. For example, we could invoke the futex() system call, which is not related to file operations, to grab a lock asynchronously. One natural approach to support general system calls in MegaPipe would be having a new API functionmp_syscall(syscall number, arg1, ...).
3.3.6
Discussion: Thread-Based Servers
The MegaPipe design naturally fits event-driven servers based on callback or event-loop mechanisms, for example, Flash [87] and SEDA [132]. We mostly focus on event-driven servers in this work. On the other hand, MegaPipe is also applicable to thread-based servers,