Pucsek Dean Msc 2013 pdf
97
0
0
Full text
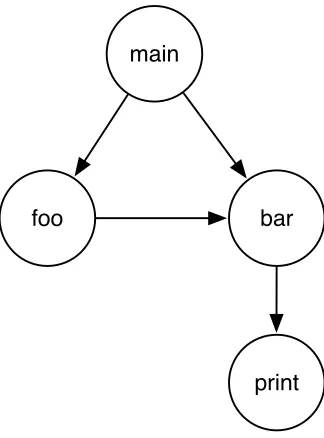
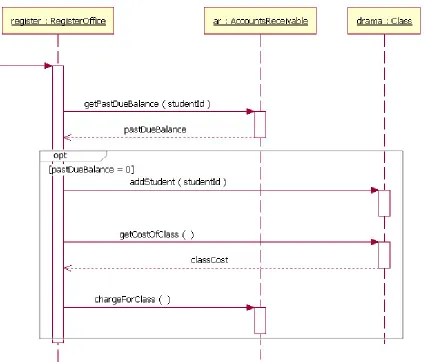
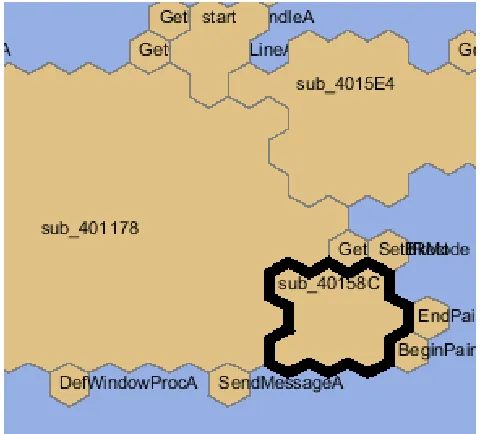
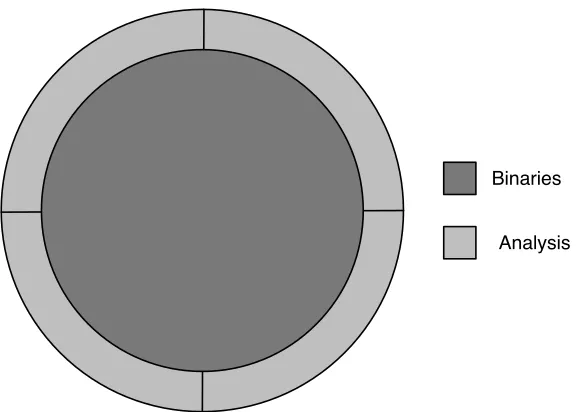
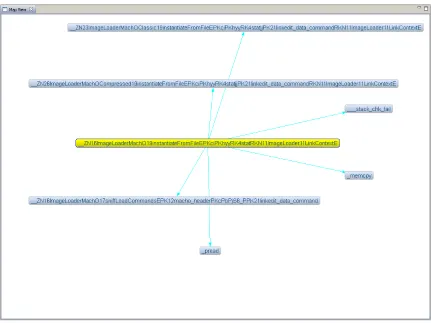
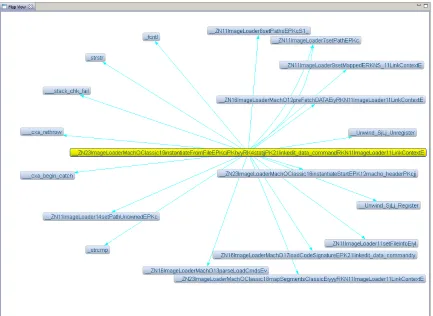
Figure
+7
Related documents