High order hp adaptive discontinuous Galerkin finite element methods for compressible fluid flows
Full text
Figure



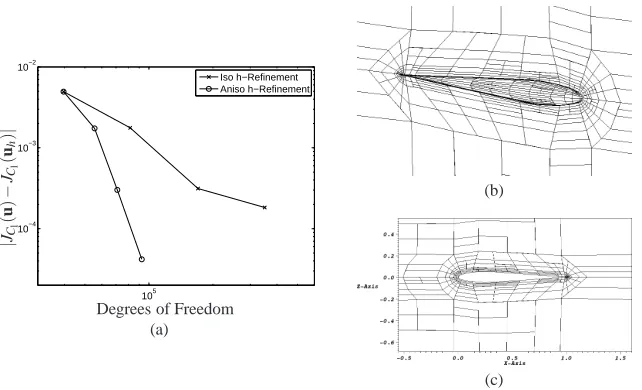
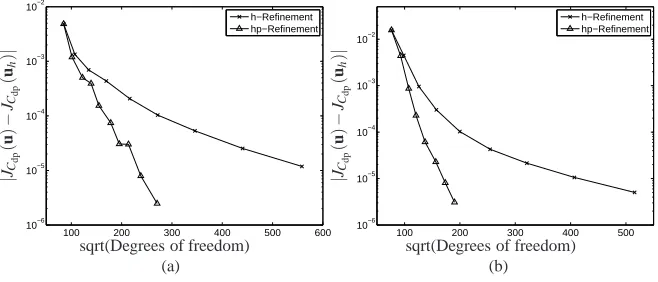


Related documents
(b) Aggregate ability is calculated using principal component analysis on the literacy and numeracy evaluation domains (for CAPS) and the memory, numeracy, attention, and
We use your personal information to keep you informed about Peel Children Centre’s services and activities, as well as fundraising and volunteer opportunities. If you wish
When regimes are not known with certainty, the European-style option value is a weighted average of the two conditional option values at the seed node, where initial regime
As will be discussed later with regard to the CoR and the Council, the inefficiency of the institutional channels of territorial representation available for the regions at
In this case the time-invariant predictive matrices are calculated which represent dependency between normal walk of a subject and different possible extra covariates of the
170 Figure 7.3 Combined number of visible crown buds and crown shoots per plant of ‘Diva’ Experiment One for the; A main effect of duration from last treatment applicationx, B
For example, when optimizing the Rosenbrock function using the free gradient-enhanced model, the speedup is nearly linear, whereas in the “adjoint gradient” model- based optimization
Combined with the peptide structure and the screening results, the segment was again divided into different short peptides, which were constructed into different
