NiuParser: A Chinese Syntactic and Semantic Parsing Toolkit
Jingbo Zhu Muhua Zhu∗ Qiang Wang Tong Xiao
Natural Language Processing Lab. Northeastern University
zhujingbo@mail.neu.edu.cn zhumuhua@gmail.com wangqiangneu@gmail.com xiaotong@mail.neu.edu.cn
Abstract
We present a new toolkit NiuParser -for Chinese syntactic and semantic anal-ysis. It can handle a wide range of Natural Language Processing (NLP) tasks in Chi-nese, including word segmentation, part-of-speech tagging, named entity recogni-tion, chunking, constituent parsing, depen-dency parsing, and semantic role label-ing. The NiuParser system runs fast and shows state-of-the-art performance on sev-eral benchmarks. Moreover, it is very easy to use for both research and industrial pur-poses. Advanced features include the Soft-ware Development Kit (SDK) interfaces and a multi-thread implementation for sys-tem speed-up.
1 Introduction
Chinese has been one of the most popular world languages for years. Due to its complexity and diverse underlying structures, processing this lan-guage is a challenging issue and has been clearly an important part of Natural Language Processing (NLP). Many tasks are proposed to analyze and understand Chinese, ranging from word segmen-tation to syntactic and/or semantic parsing, which can benefit a wide range of natural language ap-plications. To date, several systems have been developed for Chinese word segmentation, part-of-speech tagging and syntactic parsing (exam-ples include Stanford CoreNLP1, FudanNLP2, LT-P3 and etc.) though some of them are not opti-mized for Chinese.
∗This work was done during his Ph.D. study in
North-eastern University.
1http://nlp.stanford.edu/software/
corenlp.shtml
2http://fudannlp.googlecode.com 3http://www.ltp-cloud.com/intro/en/
In this paper we present a new toolkit for Chinese syntactic and semantic analysis (cal-l it NiuParser4). Unlike previous systems, the NiuParser toolkit can handle most of Chinese parsing-related tasks, including word segmenta-tion, part-of-speech tagging, named entity recog-nition, chunking, constituent parsing, dependency parsing, and semantic role labeling. To the best of our knowledge we are the first to report that all seven of these functions are supported in a single NLP package.
All subsystems in NiuParser are based on sta-tistical models and are learned automatically from data. Also, we optimize these systems for Chinese in several ways, including handcrafted rules used in pre/post-processing, heuristics used in various algorithms, and a number of tuned features. The systems are implemented with C++ and run fast. On several benchmarks, we demonstrate state-of-the-art performance in both accuracy/F1 score and speed.
In addition, NiuParser can be fit into large-scale tasks which are common in both research-oriented experiments and industrial applications. Several useful utilities are distributed with NiuParser, such as the Software Development Kit (SDK) inter-faces and a multi-thread implementation for sys-tem speed-up.
The rest of the demonstration is organized as follows. Section 2 describes the implementation details of each subsystem, including statistical ap-proaches and some enhancements with handcraft-ed rules and dictionaries. Section 3 represents the ways to use the toolkit. We also show the perfor-mance of the system in Section 4 and finally we conclude the demonstration and point out the fu-ture work of NiuParser in Section 5.
4http://www.niuparser.com/index.en.
html
Word
Segmentation TaggingPOS
Constituent Parsing
Named Entity Recognition Dependency
Parsing
Chunking
Semantic Role Labeling
NiuParser Subsystems
Conditional Random Fields
Averaged
Perceptron MaximumEntropy Neural NetworksRecurrent
[image:2.595.88.511.66.399.2]Machine Learning Models
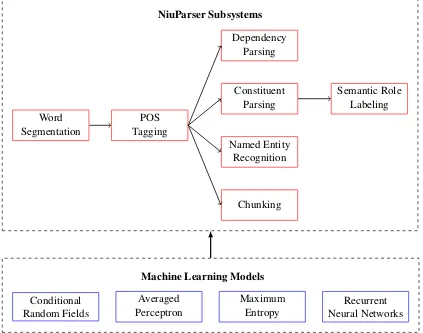
Figure 1: The system architecture of NiuParser.
2 The NiuParser System
2.1 What is NiuParser
The NiuParser system is a sentence-level syntactic and semantic parsing toolkit developed by Natu-ral Language Processing Laboratory in Northeast-ern University of China. The system is designed specifically to process the Chinese language. Sub-systems of NiuParser include word segmentation, POS tagging, named entity recognition, shallow syntactic parsing (chunking), constituent parsing, dependency parsing, and constituent parse-based semantic role labeling. Figure 1 shows the archi-tecture of the NiuParser system. As we can see from the figure, subsystems in NiuParser are orga-nized in a pipeline structure. A given sentence is first segmented into a word sequence, each word in which is assigned a POS tag by the POS tag-ging subsystem. Based on the POS tagtag-ging result, we can choose to do named entity recognition or syntactic parsing. Finally, shallow semantic struc-tures are generated by semantic role labeling on the base of constituent parsing.
2.2 Statistical Approaches to Subsystems 2.2.1 Sequence Labeling
The subsystems of word segmentation, POS tag-ging, named entity recognition, and chunking in NiuParser are based on statistical sequence label-ing models. Specifically, we adopt linear-chain Conditional Random Fields (CRF) (Lafferty et al., 2001) as the method for sequence labeling. Given an input sampleX = x1, x2, . . . , xL and its cor-responding sequenceY = y1, y2, . . . , yL, Condi-tional Random Fields are defined as follows.
Pw(Y|X) = Zw(1X)exp(WTΦ(X, Y))) (1)
whereZw(X)denotes the normalization constant and Φ(X, Y) are manually defined feature func-tions. In the testing phase, the Viterbi algorithm is applied to find an optimal label sequence or a
k-best list for a testing instance.
between a segmented sentence and its correspond-ing label sequence (Zhao et al., 2005). Specifical-ly,B, B2, B3denotes the first, the second, and the third character in a word, respectively. I means that the character is inside in a word, andEmeans that the character is at the end of a word. Finally, O denotes a single-character word. Features in-clude the characters (and their combinations) in a sliding window.
As mentioned above, the NiuParser system uti-lizes the pipeline method to integrate all the sub-systems. That is, POS tagging, named enti-ty recognition, andchunking take the output of the preceding subsystem as input. For POS tag-ging, we obtain training data from Penn Chinese Treebank (CTB) (Xue et al., 2005), which has 32 POS tags. The named entity recognition subsys-tem takes the guideline of OntoNotes (Pradhan et al., 2007). Named entities annotated in OntoNotes have 18 entity types in total, including person names, organization names, andevents, etc. Ta-ble 1 presents a complete list of the entity types in OntoNotes. Chunking uses training data derived from constituent parse trees in CTB. In NiuParser, we consider phrase types including noun phrase (NP),verbal phrase (VP),quantifier phrase (QP), prepositional phrase (PP),adjective phrase (AD-JP), andclassifier phrase (CLP), etc. Features for the three subsystems are words (and their combi-nations) in a sliding window. Prefix and suffix of words are also used as features for better system generalization.
2.2.2 Transition-based Parsing
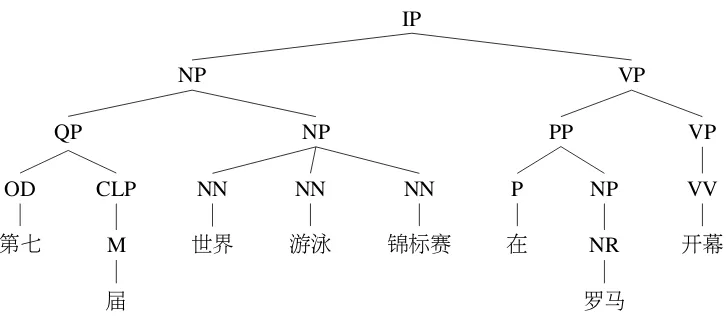
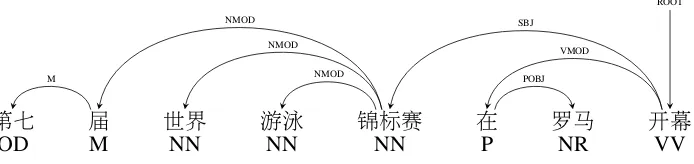
Syntactic parsers can be grouped into two cate-gories according to decoding algorithms: dynam-ic programming-based and transition-based. For the purpose of efficiency, we implement the con-stituent and two versions of dependency parsers in the NiuParser system with transition-based meth-ods (Zhu et al., 2013; Zhang and Nivre, 2011; Chen and Manning, 2014). Specifically, parser-s are variantparser-s of parser-shift-reduce parparser-serparser-s, which parser-start from an initial state and reach a final state by per-forming an action in each stage transition. Fig-ure 2 and FigFig-ure 3 present an example parse of the two parsers, respectively.
One version of the dependency parsers follows the work in (Chen and Manning, 2014), regarding the state transition process as a sequence of clas-sification decisions. In each transition, a best ac-tion is chosen by a Neural Network classifier. The
other parses (the constituent parser and the other version of dependency parser) utilize exactly the same framework, where both training and decod-ing phases are formalized as a beam search pro-cess. In the decoding phase, the candidate parse with the highest score in the beam will be picked as the parsing result once the beam search process terminates. In the training phase, a beam search-based global online training method is adopted. The training process iterates through the whole training data by decoding the sentences sequent-ly. On each sentence, parameters will be updated immediately once the gold parse is pruned off the beam. In the NiuParser system, we utilize aver-aged perceptron to learn parameters.
2.2.3 Two-Stage Classification
Researchers in semantic role labeling have ex-plored diverse syntactic structures (chunks, con-stituent parses, and dependency parses) as input. The semantic role labeling subsystem in NiuPars-er considNiuPars-ers constituent parse trees as input. The subsystem can recognize constituents in a parse tree as arguments with respect to a specified pred-icate (See Figure 4). Here, semantic role labeling is formalized as a two-stage classification prob-lem. The first stage (calledidentification) conduct-s a binary claconduct-sconduct-sification to decide whether a con-stituent in a parse tree is an argument. After the first stage, a set of constituents is fed to the sec-ond stage (calledclassification) classifier which is a multi-class classifier, used for assigning each ar-gument an appropriate semantic label.
The statistical model used in the semantic role labeling subsystem is Maximum Entropy (Berg-er et al., 1996), which provides classification de-cisions with corresponding probabilities. With such probabilities, the identification stage applies the algorithm of enforcing non-overlapping argu-ments (Jiang and Ng, 2006) to maximize the log-probability of the entire labeled parse tree. In the classification stage, the classifier assigns labels to arguments independently.
2.3 Improvements and Advanced Features 2.3.1 Word Segmentation
PERSON peopel, including fictional NORP nationalities or religious or political groups FACILITY building, airports, highways, etc. ORGANIZATION companies, agencies, etc.
GPE countries, cities, states LOCATION non-GPE, mountain ranges, bodies of water PRODUCT vehicles, weapons, foods, etc. EVENT named hurricanes, battles, wars, sports events WORD OF ART titles or books, songs, etc. LAW named documents made into laws
LANGUAGE named language DATE absolute or relative dates or periods TIME times smaller than a day PERCENT percentage *including ”%”
[image:4.595.75.534.61.157.2]MONEY monetary values, including unit QUANTITY measurements, as of weight or distances ORDINAL ”first”, ”second” CARDINAL numerals that do not fall under another type
Table 1: Named entity types in OntoNotes
IP
VP
VP VV
开幕
PP NP NR 罗马 P
在 NP
NP
NN 锦标赛 NN
游泳 NN
世界 QP
CLP M 届 OD
第七
Figure 2: Example of constituent parsing in NiuParser.
data. Fortunately, such words generally have some regular patterns and can be recognized by regular expressions. The NiuParser system provides a regular expression engine to do preprocessing for the CRF-based segmenter.
Post-processing: Besides the word types
handled in the preprocessing step, a CRF-based segmenter has a low accuracy in recogniz-ing out-of-vocabulary words. The NiuParser system implements a double-array trie for post-processing. Users can add entries (each entry is a string of characters and its corresponding segments) into a dictionary. String of characters in the dictionary will be assured to be segmented according to its corresponding segments.
2.3.2 Named Entity Recognition
In academics, named entity recognition often suf-fers from limited training data. In contrast, practi-tioners generally seek to mine a large-vocabulary entity dictionary from the Web, and then use the entity dictionary to recognize entities as a maxi-mum matching problem. This approach, howev-er, fails to resolve ambiguities. The improvement here is to combine dictionary-based methods and statistical methods.
We first use the forward maximum matching ap-proach to recognize entities in an input sentence by using an entity dictionary. The recognition re-sult is then sent to a CRF-based recognizer. Here each word is assigned a label (start of an entity, in-side an entity, or end of an entity) according to the maximum matching result. The labels are used as additional features in the CRF-based recognizer. This approach is similar to the stacking method.
2.3.3 System Speed-up
In addition to fast algorithms (e.g., shift-reduce parsing), NiuParser also supports a multithread-ing mode to make full advantage of computers with more than one CPU or core. In general, the speed can be improved when multiple threads are involved. However, it does not run faster when too many threads are used (e.g., run with more than 8 threads) due to the increased cost of scheduling.
2.4 Usage
The NiuParser system supports three ways to use the functionalities in the toolkit.
[image:4.595.118.481.190.351.2]第七 届 世界 游泳 锦标赛 在 罗马 开幕
OD M NN NN NN P NR VV
ROOT
M
NMOD NMOD
NMOD
SBJ
VMOD
[image:5.595.128.475.67.149.2]POBJ
Figure 3: Example of dependency parsing in NiuParser. IP
VP
VP VV
开幕
PP 在罗马 NP
[image:5.595.164.429.181.328.2]第七届世界游泳锦标赛
Figure 4: Example of semantic role labeling in NiuParser.
be used are specified as command line arguments. Second, all the functionalities in NiuParser can be integrated into users’ own applications or busi-ness process by using the toolkit’s SDK interfaces. The SDK supports both Windows and Linux plat-forms. In contrast to web services, SDK is more suitable to be deployed in the server side.
Third, a demo web page is provided for users to view the analysis results intuitively.5 All the analysis results are presented graphically.
3 Experiments
We ran our system on several benchmarks. Specif-ically, we trained and tested word segmentation, POS tagging, chunking, and constituent parsing on CTB5.1: articles 001-270 and 440-1151 were used for training and articles 271-300 were used for testing. The performance of named entity recog-nition was reported on OntoNotes, where 49,011 sentences were used for training and 1,340 sen-tences were used for testing. For semantic role labeling, we adopted the same data set and split-ting as in (Xue, 2008). Finally, the data set and splitting in (Zhang and Clark, 2011) were used to evaluate the performance of dependency parsing.
All results were reported on a machine with a
5http://demo.niuparser.com/index.en.
html
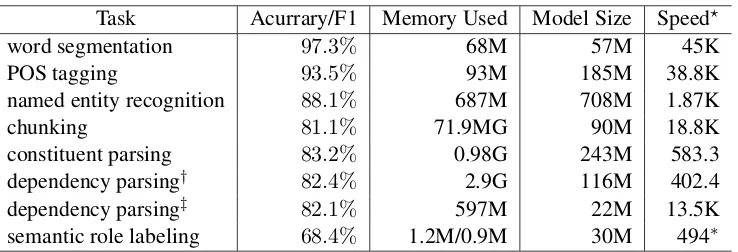
800MHz CPU and 4GB memory. See Table 2 for results of acurracy/F1 scores, memory use, mod-el sizes and speed. Note that we evaluated the speed with a single thread and the accuracies were achieved with statistical models only.
From the results we can see that most of the sub-systems achieve state-of-the-art performance, (the chunking subsystem is an exception, whose accu-racy still have some room left for further improve-ments.). In addition, the memory use of dependen-cy parsing is extremely heavy. We will optimize the implementation of dependency parsing in our future work.
4 Conclusions and Future Work
We have presented the NiuParser Chinese syntac-tic and semansyntac-tic analysis toolkit. It can handle several parsing tasks for Chinese, including word segmentation, part-of-speech tagging, named enti-ty recognition, chunking, constituent parsing, de-pendency parsing, and constituent parser-based se-mantic role labeling. The NiuParser system is fast and shows state-of-the-art performance on sever-al benchmarks. Moreover, it supports seversever-al ad-vanced features, such as the Software Develop-ment Kit (SDK) interfaces and the multi-thread implementation for system speed-up.
function-Task Acurrary/F1 Memory Used Model Size Speed?
word segmentation 97.3% 68M 57M 45K
POS tagging 93.5% 93M 185M 38.8K
named entity recognition 88.1% 687M 708M 1.87K
chunking 81.1% 71.9MG 90M 18.8K
constituent parsing 83.2% 0.98G 243M 583.3
dependency parsing† 82.4% 2.9G 116M 402.4
dependency parsing‡ 82.1% 597M 22M 13.5K
[image:6.595.117.486.71.197.2]semantic role labeling 68.4% 1.2M/0.9M 30M 494∗
Table 2: Evaluation of NiuParser on various tasks. †beam search-based global training method. ‡classification-based method with Neural Networks.?characters per second.∗ predicates per second.
alities to NiuParser. First of all, we will integrate a new subsystem which conducts dependency-based semantic role labeling. In addition, we will de-velop a faster constituent parsers by using Recur-rent Neural Network. According to the previous work (Chen and Manning, 2014) (and its clone in the NiuParser system), this method reduces the cost of feature extraction and thus shows the ad-vantage in speed. We expect the same approach can be adapted to constituent parsing.
Acknowledges
This work was supported in part by the National Science Foundation of China (Grants 61272376, 61300097, and 61432013).
References
Adam L. Berger, Stephen A. Della Pietra, and Vincent J. Dealla Pietra. 1996. A maximum entropy ap-proach to natural language processing. Computa-tional Linguics, 22:39–71.
Danqi Chen and Christopher D. Manning. 2014. A fast and accurate dependency parser using neural net-works. Proc. of EMNLP 2014, pages 740–750. Zheng Ping Jiang and Hwee Tou Ng. 2006.
Seman-tic role labeling of nombank: a maximum entropy approach.Proc. of EMNLP 2006, pages 138–145. John D. Lafferty, Andrew McCallum, and Fernando
C. N. Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling se-quence data.Proc. of ICML 2001.
Sameer S. Pradhan, Hovy Eduard, Mitch Mar-cus, Martha Palmer, Lance Ramshaw, and Ralph Weischedel. 2007. Ontonotes: A unified relation-al semantic representation. Proc. of ICSC 2007. Nianwen Xue, Fei Xia, Chiou Fu-Dong, and Palmer
Martha. 2005. The penn chinese treebank: Phrase
structure annotation of a large corpus. Natural Lan-guage Engineering, 11:207–238.
Nianwen Xue. 2008. Labeling chinese predicates with semantic roles. Computational Linguistics, 32:225– 255.
Yue Zhang and Stephen Clark. 2011. Syntactic pro-cessing using the generalized perceptron and beam search. Computational Linguistics, 37:105–151. Yue Zhang and Joakim Nivre. 2011.
Transition-based dependency parsing with rich non-local fea-tures.Proc. of ACL 2011, pages 188–193.
Hai. Zhao, Chang-Ning Huang, and Mu Li. 2005. An improved chinese word segmentation system with conditional randome fileds. Proc. of SIGHAN 2006, pages 162–165.