Rewarding Coreference Resolvers for Being Consistent
with World Knowledge
Rahul Aralikatte1,Heather Lent1,Ana Valeria Gonzalez1,Daniel Hershcovich1, Chen Qiu1,2,Anders Sandholm3,Michael Ringaard3, andAnders Søgaard1,3 1University of Copenhagen,2China University of Geosciences,3Google Research
{rahul,hcl,ana,hershcovich,chen.qiu,soegaard}@di.ku.dk,
{sandholm,ringgaard}@google.com
Abstract
Unresolved coreference is a bottleneck for re-lation extraction, and high-quality coreference resolvers may produce an output that makes it a lot easier to extract knowledge triples. We show how to improve coreference resolvers by forwarding their input to a relation extraction system and reward the resolvers for produc-ing triples that are found in knowledge bases. Since relation extraction systems can rely on different forms of supervision and be biased in different ways, we obtain the best perfor-mance, improving over the state of the art, us-ing multi-task reinforcement learnus-ing.
1 Introduction
Coreference annotations are costly and difficult to obtain, since trained annotators with sufficient world knowledge are necessary for reliable anno-tations. This paper presents a way tosimulate an-notators using reinforcement learning. To moti-vate our approach, we rely on the following exam-ple fromMartschat and Strube(2014, colors added to mark entity mentions):
(1) [Lynyrd . . . .. . . .Skynyrd]1was formed inFlorida2.
Other bands from [the Sunshine State]2 in-cludeFireflightand::::::::Marilyn::::::::Manson.
Martschat and Strube (2014) cite the associa-tion betweenFloridaandthe Sunshine Stateas an example of a common source of name-name re-call error for state-of-the-art coreference resolu-tion systems. The challenge is that the two names co-occur relatively infrequently and are unlikely to do so in a moderate-sized, manually annotated training corpus. A state-of-the-art system may be able to infer the relation using distributional infor-mation about the phrasethe Sunshine State, but is likely to have limited evidence for the decision that it is coreferential withFloridarather thanLynyrd. . . .
. . . . Skynyrd.
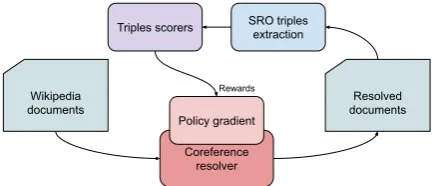
Wikipedia documents
Resolved documents
Coreference resolver Policy gradient
Rewards
[image:1.595.308.528.207.300.2]SRO triples extraction Triples scorers
Figure 1: Our strategy for training a coreference re-solver using reward from relation extraction.
While coreference-annotated data is scarce, knowledge bases including factual information (such as that Fireflight is from Florida) are in-creasingly available. For a human annotator un-aware thatFloridais sometimes referred to asthe Sunshine State, the information thatFireflight is fromFloridais sufficient to establish thatFlorida
andthe Sunshine Stateare (with high probability) coreferential. This paper explores a novel archi-tecture for making use of such information from knowledge bases by tying a coreference resolution system to a relation extraction system, enabling us to reward the coreference system for making predictions that lead us to infer facts that are con-sistent with such knowledge bases. This poten-tially provides us with more evidence for resolving coreference such as (1).
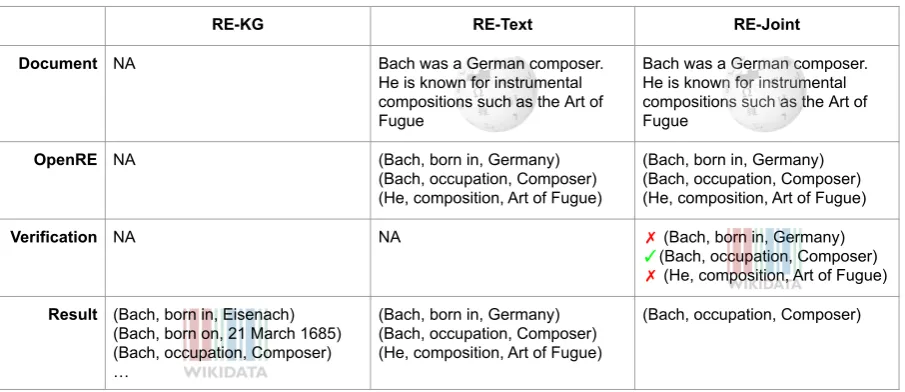
RE-KG RE-Text RE-Joint
Document NA Bach was a German composer.
He is known for instrumental compositions such as the Art of Fugue
Bach was a German composer. He is known for instrumental compositions such as the Art of Fugue
OpenRE NA (Bach, born in, Germany)
(Bach, occupation, Composer) (He, composition, Art of Fugue)
(Bach, born in, Germany) (Bach, occupation, Composer) (He, composition, Art of Fugue)
Verification NA NA ✗ (Bach, born in, Germany)
✓(Bach, occupation, Composer)
✗ (He, composition, Art of Fugue)
Result (Bach, born in, Eisenach) (Bach, born on, 21 March 1685) (Bach, occupation, Composer) …
(Bach, born in, Germany) (Bach, occupation, Composer) (He, composition, Art of Fugue)
[image:2.595.74.527.61.257.2](Bach, occupation, Composer)
Figure 2: The columns show the different pipelines used to obtain data for training the reward models. The pipeline for: (i) RE-KG directly extracts triples from Wikidata, (ii) RE-Text runs Wikipedia summaries through OpenRE to generate triples, and (iii) RE-Joint adds an additional verification step by checking if the generated triples exist in Wikidata.
we do policy-gradient fine-tuning of our coref-erence resolver, effectively optimizing its predic-tions’ consistency with world knowledge.
Contributions We demonstrate that training a coreference resolver by reinforcement learning with rewards from a relation extraction system, re-sults in improvements for coreference resolution. Our code is made publicly available at https: //github.com/rahular/coref-rl
2 Consistency Reward for Coreference Resolution
In order to reward a coreference resolver for be-ing consistent with world knowledge, we propose a simple training strategy based on relation extrac-tion: (i) Sample a Wikipedia1 document at ran-dom, (ii) Replace mentions with their antecedents using a coreference resolver, (iii) Apply an off-the-shelf openRE system to each rewritten docu-ment, (iv) Score relationships that include corefer-ent mcorefer-entions using Universal Schema, and (v) Use the score as a reward for training the coreference resolvers.
Reward functions To model consistency with world knowledge, we train different Universal Schema models (Riedel et al., 2013; Verga and McCallum,2016), resulting in three reward func-tions (Figure2):RE-KG(Knowledge Graph Uni-versal Schema) is trained to predict whether two
1https://www.wikipedia.org
entities are linked in Wikidata2; RE-Text (Text-based Universal Schema) is trained to predict whether two entities co-occur in Wikipedia; and RE-Joint (Joint Universal Schema) is trained to predict whether two entities are linked and co-occur. The three rewards focus on different aspects of relationships between entities, giving compli-mentary views of what entities are related.
Similar to Verga et al. (2016), we parameter-ize candidate relation phrases with a BiLSTM (Graves and Schmidhuber, 2005), and use pre-trained Wikidata BigGraph embeddings (Lerer et al.,2019) as the entity representations. We ap-ply a one-layer MLP on the concatenated repre-sentations to get the reward value.
Updating the coreference resolver Each re-solved document is converted into n subject-relation-object (SRO) triples by an open informa-tion retrieval system (Angeli et al., 2015). Each tripleti is then scored using a reward function to obtain a reward ri for i ∈ {1, . . . , n}. The fi-nal document-level reward is the normalized sum of the individual rewards as shown in Equation1, whereRhis a moving window containing the pre-vioush= 100normalized reward values.
R=
P
iri−mean(Rh) stddev(Rh)
(1)
Since R is not differentiable with respect to the coreference resolver’s parameters, we use
icy gradient training to update the coreference re-solver. We select the best action according to the current policy, using random exploration of the al-ternative solutions withp= 101.
Multi-task reinforcement learning Our overall training procedure is presented in Algorithm 1. After training the three aforementioned reward models, we create RE-Distill by interpolating their trained weights. Next, we pre-train a corefer-ence resolver using supervised learning, and fine-tune it using each of the three reward functions to get three different coreference policies: Coref-KG, Coref-Text and Coref-Joint, respectively. We then use multi-task reinforcement learning to combine these three policies to getCoref-Distill. Our approach is a particular instance of DisTraL (Teh et al.,2017), using policy gradient and model interpolation. Finally, Coref-Distill is fine-tuned with rewards fromRE-Distill.
Algorithm 1 Multi-task Reinforcement Learning
Require: Baseline initialized policiesθnforn∈ {1,2,3}
Require: Reward functionsrewardnforn∈ {1,2,3}
Require: Distilled reward functionreward∗
whilestopping criterion not metdo
SamplekdocumentsDk ford∈Dkdo
forn∈ {1,2,3}do
Cd= entity clusters withθn
d0= resolvedwithCd
T = obtain OpenIE triples ford0 r= rewardn(d0)
ˆ
gk= policy gradient forθnwith rewardr
θk+1n =θkn+αkˆgk
end for end for end while
Distilled policyθ∗=θ1+θ32+θ3
SamplekdocumentsDk
ford∈Dkdo
d0= resolvedwithCd
T = obtain OpenIE triples ford0 r= reward∗(d0)
ˆ
gk= policy gradient forθ∗with rewardr
θ∗k+1=θ∗k+αkgˆk
end for
return Distilled policyθ∗
3 Experiments
We use a state-of-the-art neural coreference res-olution model (Lee et al., 2018) as our baseline coreference resolver.3 This model extends Lee et al. (2017) with coarse-to-fine inference and ELMo pretrained embeddings (Peters et al.,2018).
3https://github.com/kentonl/e2e-coref
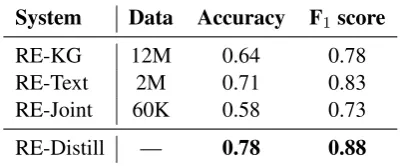
System Data Accuracy F1score
RE-KG 12M 0.64 0.78
RE-Text 2M 0.71 0.83
RE-Joint 60K 0.58 0.73
[image:3.595.316.518.64.147.2]RE-Distill — 0.78 0.88
Table 1: Training data size, accuracy and F1scores of
the reward models on the 200,000 validation triples.
Data We use the standard training, validation, and test splits from the English OntoNotes.4 We also evaluate on the English WikiCoref (Ghaddar and Langlais,2016), with a validation and test split of 10 and 20 documents respectively.
Reward model training We use data from En-glish Wikipedia and Wikidata to train our three re-ward models. For trainingRE-KG, we sample 1 million Wikidata triples, and expand them to 12 million triples by replacing relation phrases with their aliases. ForRE-Text, we pass the summary paragraphs from 50,000 random Wikipedia pages to Stanford’s OpenIE extractor (Manning et al.,
2014), creating 2 million triples. For RE-Joint, we only use Wikipedia triples that are grounded in Wikidata, resulting in 60,000 triples.5 We fur-ther sample 200,000 triples from Wikidata and Wikipedia for validation, and train the reward models with early stopping based on the F1 score of their predictions.
Evaluation All models are evaluated using the standard CoNLL metric, which is the average F1 score over MUC, CEAFe, and B3 (Denis and Baldridge,2009).
4 Results
Since the quality of our reward models is essen-tial to the performance of the coreference resolver adaptations, we first report the validation accuracy and F1 scores of the four reward models used, in Table 1. We clearly see the advantage of distil-lation, with a 5% absolute difference between the best single model (RE-Text) andRE-Distill.
Table 2 presents the downstream effects of applying these reward functions to our baseline
4
https://catalog.ldc.upenn.edu/ LDC2013T19
5That is, we retain only those triples whose subject and
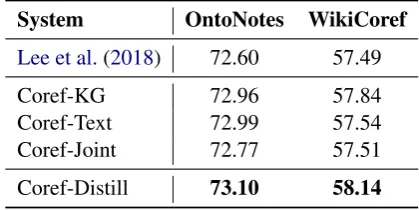
System OntoNotes WikiCoref
Lee et al.(2018) 72.60 57.49
Coref-KG 72.96 57.84
Coref-Text 72.99 57.54
Coref-Joint 72.77 57.51
[image:4.595.75.285.63.168.2]Coref-Distill 73.10 58.14
Table 2: Coreference results: average F1scores on the
OntoNotes and WikiCoref test sets. Differences are significant w.r.t.B3(bootstrap test,p <0.05).
coreference policy.6
The coreference resolution results are similar to the relation extraction results: using a distilled policy, learned through multi-task reinforcement learning, leads to better results on both datasets.7
While improvements over the current state of the art are relatively small, they reflect signifi-cant progress, as they demonstrate the ability to successfully augment coreference resolvers with “free" data from large-scale KB like Wikidata. For relation extraction, this could have positive down-stream effects, and also ensure that relations are consistent with real world knowledge. Moreover, this approach has the potential to also be benefi-cial for coreference resolution in low resource lan-guages, where less annotated data is available, as Wikidata triples are abundant for many languages.
5 Analysis
Empirically, we find that fine-tuning the corefer-ence resolver on Wikidata results in two kinds of improvements:
Better mention detection Since the model is rewarded if the SRO triples produced from the resolved document are present in Wikidata, the model can do well only if it correctly resolves the subject and object, which are usually named en-tities (more generally, noun phrases). Indeed, we see an improvement in mention detection as exem-plified in the first example of Figure3. Compared to the baseline, the fine-tuned model identifies a larger number of entities, including “southern hemisphere”, “Cambridge” and “Oxford”, which are missed by the baseline model.
6The models were re-trained from scratch, and the scores
are slightly different from those reported inLee et al.(2018).
7We repeat this experiment three times with different
ran-dom seeds and observed the same pattern and very robust per-formance across the board.
Better linking As a direct consequence of the above, the model is inclined to also link noun phrases that are not entities. In the second example of Figure3, we see that “This attempt” is linked to “releasing” by the fine-tuned model. Interestingly, we do not see this type of eventive noun phrase linking either in OntoNotes or in the predictions of the baseline model.
This phenomenon, however, also has a side-effect of producing singleton clusters and spurious linking, which adversely affect the recall. On the OntoNotes test data, while the average precision of the best performing fine-tuned model is higher than the baseline (75.62 vs. 73.80), a drop in recall (70.75 vs. 71.34) causes the final F1score to only marginally improve.
6 Related Work
Coreference resolution Among neural corefer-ence resolvers (Wu and Ma, 2017; Meng and Rumshisky, 2018), Lee et al. (2017) were the first to propose an end-to-end resolver which did not rely on hand-crafted rules or a syntactic parser. Extending this work, Lee et al. (2018) introduced a novel attention mechanism for it-eratively ranking spans of candidate coreferent mentions, thereby improving the identification of long distance coreference chains. Zhang et al.
(2019) improve pronoun coreference resolution by 2.2 F1 using linguistic features (gender, animacy and plurality) and a frequency based predicate-argument selection preference as external knowl-edge. Emami et al.(2018) incorporate knowledge into coreference resolution by means of informa-tion retrieval, finding sentences that are syntacti-cally similar to a given instance, and improving F1 by 0.16.
Baseline system Fine-tuned system
Mention detection
According to thelibrary's publications, it is the largest academic library in the southern hemisphere. The university has a number of residential college and halls of residence, based on the college system of Cambridge and Oxford universities.
According to thelibrary's publications, it is the largest academic library in the
southern hemisphere. The university has a number of residential college and halls of residence, based on the college system of Cambridge and Oxford universities.
Linking
On March 19, Obama continued his
outreach to the Muslim world, releasing a New Year’s video message to the people and government of Iran. This attempt was rebuffed by the Iranian leadership.
On March 19, Obama continued his
[image:5.595.71.525.81.224.2]outreach to the Muslim world, releasing a New Year’s video message to the people and government of Iran. This attempt was rebuffed by the Iranian leadership.
Figure 3: Mention detection and linking examples by the baseline system from Lee et al.(2018), and the best performing fine-tuned system (Coref-Distill). Mentions of the same color are linked to form a coreference cluster.
tasks other than knowledge base construction.8
Knowledge bases Knowledge bases have been leveraged across multiple tasks across NLP ( Bor-des et al., 2011; Chang et al., 2014; Lin et al.,
2015;Toutanova et al., 2015;Yang and Mitchell,
2017). Specifically for coreference resolution,
Prokofyev et al.(2015) implement a resolver that ensures semantic relatedness of resulting corefer-ence clusters by leveraging Semantic Web anno-tations. Their work incorporates knowledge graph information only in the final stage of the resolver’s pipeline, and not during training. In contrast, our work augments information from the knowl-edge base directly into the training pipeline. Also, they use DBpedia (Auer et al., 2007) as the on-tology. Although both Wikidata and DBpedia are designed to support working with Wikipedia ar-ticles, DBpedia can be considered as a subset of Wikidata as Wikipedia infoboxes are its main data source. The advantage of Wikidata over DBpedia is its size, and the fact that it is multilingual, which will allow applying our method to other languages in the future.
7 Conclusion
We presented an architecture for adapting corefer-ence resolvers by rewarding them for being consis-tent with world knowledge. Using simple multi-task reinforcement learning and a knowledge ex-traction pipeline, we achieved improvements over the state of the art across two datasets. We believe
8Mao et al. (2018), for example, use reinforcement
learning with consistency-like reward to induce lexical tax-onomies.
this is an important first step in exploring the use-fulness of knowledge bases in the context of coref-erence resolution and other discourse-level phe-nomena. In this area, manually annotated data is particularly expensive, and we believe leveraging knowledge bases will eventually reduce the need for manual annotation.
Acknowlegments
We thank the reviewers for their valuable com-ments. Rahul Aralikatte, Daniel Hershcovich, Heather Lent, and Anders Søgaard are funded by a Google Focused Research Award. Heather Lent is also funded by the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 801199. Chen Qiu is funded in part by the Na-tional Natural Science Foundation of China under grant No. 61773355 and the China Scholarship Council.
References
Gabor Angeli, Melvin Jose Johnson Premkumar, and Christopher D. Manning. 2015. Leveraging linguis-tic structure for open domain information extraction. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Lan-guage Processing (Volume 1: Long Papers), pages 344–354, Beijing, China. Association for Computa-tional Linguistics.
Seman-tic Web Conference, ISWC’07/ASWC’07, pages 722–735, Berlin, Heidelberg. Springer-Verlag.
Antoine Bordes, Jason Weston, Ronan Collobert, and Yoshua Bengio. 2011. Learning structured embed-dings of knowledge bases. InAAAI.
Kai-Wei Chang, Wen tau Yih, Bishan Yang, and Christopher Meek. 2014. Typed tensor decompo-sition of knowledge bases for relation extraction. In
EMNLP.
Kevin Clark and Christopher D Manning. 2016. Deep reinforcement learning for mention-ranking coref-erence models. In Proceedings of the 2016 Con-ference on Empirical Methods in Natural Language Processing, pages 2256–2262.
Pascal Denis and Jason Baldridge. 2009. Global joint models for coreference resolution and named entity classification.Procesamiento del Lenguaje Natural, 42.
Ali Emami, Adam Trischler, Kaheer Suleman, and Jackie Chi Kit Cheung. 2018.A generalized knowl-edge hunting framework for the Winograd schema challenge. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Student Research Work-shop, pages 25–31, New Orleans, Louisiana, USA. Association for Computational Linguistics.
Abbas Ghaddar and Philippe Langlais. 2016. Wiki-coref: An english coreference-annotated corpus of wikipedia articles. In Proceedings of the Tenth In-ternational Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia. Euro-pean Language Resources Association (ELRA), Eu-ropean Language Resources Association (ELRA).
Alex Graves and Jürgen Schmidhuber. 2005. Frame-wise phoneme classification with bidirectional lstm and other neural network architectures. Neural Net-works, 18(5-6):602–610.
Kenton Lee, Luheng He, Mike Lewis, and Luke Zettle-moyer. 2017. End-to-end neural coreference reso-lution. InProceedings of the 2017 Conference on Empirical Methods in Natural Language Process-ing, pages 188–197.
Kenton Lee, Luheng He, and Luke Zettlemoyer. 2018. Higher-order coreference resolution with coarse-to-fine inference. InProceedings of the 2018 Confer-ence of the North American Chapter of the Associ-ation for ComputAssoci-ational Linguistics: Human Lan-guage Technologies, Volume 2 (Short Papers), pages 687–692.
Adam Lerer, Ledell Wu, Jiajun Shen, Timothee Lacroix, Luca Wehrstedt, Abhijit Bose, and Alex Peysakhovich. 2019. PyTorch-BigGraph: A Large-scale Graph Embedding System. InProceedings of the 2nd SysML Conference, Palo Alto, CA, USA.
Yankai Lin, Zhiyuan Liu, and Maosong Sun. 2015. Modeling relation paths for representation learning of knowledge bases. InEMNLP.
Christopher D. Manning, Mihai Surdeanu, John Bauer, Jenny Finkel, Steven J. Bethard, and David Mc-Closky. 2014. The Stanford CoreNLP natural lan-guage processing toolkit. InAssociation for Compu-tational Linguistics (ACL) System Demonstrations, pages 55–60.
Yuning Mao, Xiang Ren, Jiaming Shen, Xiaotao Gu, and Jiawei Han. 2018. Building a large-scale anno-tated chinese corpus. InACL.
Sebastian Martschat and Michael Strube. 2014. Recall error analysis for coreference resolution. In Pro-ceedings of the 2014 Conference on Empirical Meth-ods in Natural Language Processing (EMNLP), pages 2070–2081, Doha, Qatar. Association for Computational Linguistics.
Yuanliang Meng and Anna Rumshisky. 2018. Triad-based neural network for coreference resolution. In
COLING.
Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word rep-resentations. In Proceedings of the 2018 Confer-ence of the North American Chapter of the Associ-ation for ComputAssoci-ational Linguistics: Human Lan-guage Technologies, Volume 1 (Long Papers), pages 2227–2237.
Roman Prokofyev, Alberto Tonon, Michael Luggen, Loic Vouilloz, Djellel Eddine Difallah, and Philippe Cudré-Mauroux. 2015. Sanaphor: Ontology-based coreference resolution. In International Semantic Web Conference.
Sebastian Riedel, Limin Yao, Andrew McCallum, and Benjamin M. Marlin. 2013.Relation extraction with matrix factorization and universal schemas. In Pro-ceedings of the 2013 Conference of the North Amer-ican Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 74–84, Atlanta, Georgia. Association for Computa-tional Linguistics.
Yee Teh, Victor Bapst, Wojciech M. Czarnecki, John Quan, James Kirkpatrick, Raia Hadsell, Nicolas Heess, and Razvan Pascanu. 2017. Distral: Robust multitask reinforcement learning. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vish-wanathan, and R. Garnett, editors,Advances in Neu-ral Information Processing Systems 30, pages 4496– 4506. Curran Associates, Inc.
Patrick Verga, David Belanger, Emma Strubell, Ben-jamin Roth, and Andrew McCallum. 2016. Multi-lingual relation extraction using compositional uni-versal schema. In Proceedings of the 2016 Con-ference of the North American Chapter of the As-sociation for Computational Linguistics: Human Language Technologies, pages 886–896, San Diego, California. Association for Computational Linguis-tics.
Patrick Verga and Andrew McCallum. 2016. Row-less universal schema. InAKBC.
Jheng-Long Wu and Wei-Yun Ma. 2017. A deep learning framework for coreference resolution based on convolutional neural network. 2017 IEEE 11th International Conference on Semantic Computing (ICSC), pages 61–64.
Bishan Yang and Tom Michael Mitchell. 2017. Lever-aging knowledge bases in lstms for improving ma-chine reading. InACL.
Xiangrong Zeng, Shizhu He, Kang Liu, and Jian Zhao. 2018. Large scaled relation extraction with rein-forcement learning. InAAAI.
Hongming Zhang, Yan Song, and Yangqiu Song. 2019.