Polylingual Topic Models
Full text
Figure



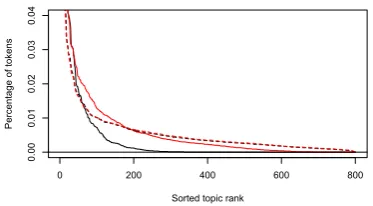
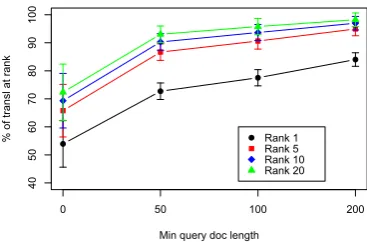


Related documents
Richmond, Smith and Amitay designed an algorithm for topic segmentation that weighted words based on their frequency within a document and subsequently used
If the term distributions for the topics are already given by a previously fitted model, only the topic distributions for documents can be estimated using estimate.beta = FALSE..
We first estimate the topic distribution for each document in training data, and assign those topic probabilities to each sentence, then, we train a topic-specific n -gram LM for
In many scenarios, users have external knowledge regarding word correlation, document labels, or document relations, which can reshape topic models and improve coherence..
Figure 1: Interactive document labeling: Start with lda topic modeling, show users relevant documents for each topic, get user labels, classify documents, and use slda to
The logistic normal distribution, used to model the latent topic proportions of a document, can represent correlations between topics that are impossible to capture using a
(2009) propose an integrated nested Laplace approximation to approximate these pos- terior marginal distributions. Their procedure consists of three steps. 1) Approximate the
We compare the perplexity of the topic model (TM), concept-topic model (CTM) and the hierar- chical concept-topic model (HCTM) trained on document sets from the science and
