International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)458
Efficient Clustering Technique for Information Retrieval
in Data Mining
Anoop Jain
1, Aruna Bajpai
2, Manish Kumar Rohila
31,2,3Department of Computer Application, Samrat Ashok Technological Institute, Vidisha (M.P.), India.
2
Abstract- In the emerging new wave of applications where people are the ultimate target of text clustering methods, cluster labels are intended to be read and comprehended by humans. The primary objective of a clustering method should be to focus on providing good, descriptive cluster labels in addition to optimizing traditional clustering quality indicators such as document-to-group assignment. In yet other words: in document browsing, text clustering serves the main purpose of describing and summarizing a larger set of documents; the particular document assignment is of lesser importance. Descriptive clustering is a problem of discovering diverse groups of semantically related documents described with meaningful, comprehensible and compact text labels. In this paper we implement a new type of clustering methods for information retrieval which focuses on revealing the structure of document collections, summarizing their content and presenting this content to a human user in a compact way. In our implementation of Description Comes First (DCF) are in two clustering algorithms. First one is applicable to search results clustering and in second one is Descriptive k-Means which is applicable to collections of several thousand short and medium documents. Our experimental results show the performance and scalability are more efficient than existing works.
I.
I
NTRODUCTIONJust a few years ago size seemed to be everything the search engines weekly published numbers of Web pages indexed and available for immediate access to the public.
But as the numbers grew into billions, size became just another incomprehensible factor. Nowadays electronic information sources on the Web include a great variety of different content.
Alongside traditional Web pages in html, we have newswire stories, books, e-mails, blogs, source code repositories, video streams, music and even telephone conversations. Even narrowing the scope to textual content, the range of different possibilities is overwhelming.
A piece of text downloaded from the Internet is usually unstructured, multilingual, touching upon all kinds of subject (from encyclopedia entries to personal opinions) and in general unpredictable (think of all the typographical conventions, abbreviations, new words that come with electronic publications). We search for concrete pieces of information when we need to find a particular Web page, document, historical fact or a person. This kind of information need has an interesting property: we can express it to a computer system using a query. The computer system may try to find a direct answer to our query (as in question-answering systems), but more often just locate a resource (document) that possibly contains the answer our query. The latter systems are called document-retrieval systems or in short search engines and in this thesis our discussion concerns mostly programs of this type [2] and [3] and [4].
II.
B
ACKGROUNDInternational Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)459
The activity of exploring a collection of documents takes place when there is no information need or it is too vague to formulate a specific query. For example, imagine creating a query for the following question: given a set of previously unseen documents, what subjects are they about? An alternative task could be this: what subjects dominate the headlines of all major newspapers today? A human being could answer these questions simply by reading through all the available documents, but such solution is usually unacceptable as it requires too much time and effort. Exploration problems are also encountered in combination with search engines. Queries issued to search engines are mostly short and ambiguous and match vast numbers of documents concerning variety of subjects. Creating a linear hit list out of such a broad set of results often requires trade-offs and hiding documents that could prove useful to the user. If shown an explicit structure of topics present in a search result, users quickly narrow the focus to just a particular subset (slice) of all returned documents [2] and [6].
III.
D
OCUMENTC
LUSTERINGGiven a number of objects or individuals, each of which is described by a set of numerical measures, devise a classification scheme for grouping the objects into a number of classes such that objects within classes are similar in some respect and unlike those from other classes. The number of classes and the characteristics of each class are to be determined.
By analogy to the above definition document clustering, or text clustering, can be defined as a process of organizing pieces of textual information into groups whose members are similar in some way, and groups as a whole are dissimilar to each other. But before we delve into text clustering, let us take a look at clustering in general. There are many kinds of clustering algorithms, suitable for different types of input data and diverse applications. A great deal depends on how we define similarity between objects. We can measure similarity in terms of objects’ proximity (distance), or as a relation between the features they exhibit.
Brian Everitt et al. suggest the following classification of clustering methods:
Hierarchical techniques — in which clusters are recursively grouped to form a tree,
Optimization techniques — where clusters are formed by the optimization of a clustering criterion,
Density or mode-seeking techniques — in which clusters are formed by searching for regions containing a relatively dense concentration of entities,
Clumping techniques — in which classes or clumps can overlap,
Others — methods which do not fall clearly into any of the above.
Alternative classifications of clustering algorithms can be suggested, depending on the aspect we look at. In our opinion it is worthwhile to take a look at several aspects. Looking at the structure of discovered clusters we can distinguish flat and hierarchical clustering algorithms. Depending on the type of assignment between documents and clusters we can have:
partitioning algorithms — which assign each document to exactly one cluster,
clumping techniques — described above; note that this type of clustering is natural and desirable for texts because a single document can be assigned to more than one topic,
Partial clustering — algorithms which may leave some objects unassigned at all; in this thesis we will use the term “others” to refer to a synthetic group of un-clustered objects.
Finally, the classification can be made depending on the strength of relationship between an object and a cluster:
Crisp clustering — with a binary assignment when a document is either assigned to a cluster or not assigned to it,
Fuzzy clustering — when the degree of assignment is expressed on the scale of “not associated” to “fully associated”, typically with a number between 0 and 1 [3] and [4].
IV.
O
VERVIEW OFS
ELECTEDC
LUSTERINGA
LGORITHMSClustering analysis is a very broad field and the number of available methods and their variations can be overwhelming. A good introduction to numerical clustering can be found in Cluster Analysis or in Cluster
Classification.
A more up-to-date view of clustering in the context of data mining is available in Data Mining: Concepts and Techniques.
Partitioning Methods
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)460
Because enumeration of all possible subsets of the input is usually computationally infeasible, partitioning clustering employs an iterative improvement procedure which moves objects between clusters until the optimality criterion can no longer be improved.
The most popular partitioning algorithm is the k-Means
algorithm. In k-Means, we define a global objective function and iteratively move objects between partitions to optimize this function. The objective function is usually a sum of distances (or sum of squared distances) between objects and their cluster’s centers and the objective is to minimize it. The representation of a cluster can be an average of its elements (its centroid) or a mean point (object closest to the centroid of a cluster). In the latter case we call the algorithm k-Medoids. Given the number of clusters k a priori, a generic k-Means procedure is implemented in four steps:
1. Partition objects into k nonempty subsets (most often randomly),
2. Compute representation of centers for current clusters, 3. Assign each object to the closest cluster,
4. Repeat from step 2 until no more reassignments occurs.
By moving objects to their closest partition and recalculating partition’s centers in each step the method eventually converges to a stable state, which is usually a local optimum. We discuss computational complexity of k-Means in later sections, for now let us just comment that the entire procedure is efficient in practice and usually converges in just a few iterations on non-degenerated data. Another thing worth mentioning is that clusters created by k-Means are spherical with respect to the distance metric; the algorithm is known to have problems with non-convex, and in general complex, shapes.
Hierarchical Methods
A family of hierarchical clustering methods can be divided into agglomerative and divisive variants.
Agglomerative Hierarchical Clustering (ahc) initially places each object in its own cluster and then iteratively combines the closest clusters merging their content. The clustering process is interrupted at some point, leaving a dendrogram with a hierarchy of clusters. Many variants of hierarchical methods exist, depending on the procedure of locating pairs of clusters to be merged. In the
single link method, the distance between clusters is the minimum distance between any pair of elements drawn from these clusters (one from each), in the complete link it is the maximum distance and in the average link it is correspondingly an average distance (a discussion of other
merging methods can be found. Each of these has a different computational complexity and runtime behavior. Single link method is known to follow “bridges” of noise and link elements in distant clusters (a chaining effect). Complete link method is computationally more demanding, but is known to produce more sensible hierarchies. Average link method is a trade-off between speed and quality and efficient algorithms for its incremental calculation exist such as in the Buckshot/ Fractionation algorithm [2] and [7].
V.
R
ELATEDW
ORKSTo present currently available algorithms and methods that closely corresponds to the ideas presenting in this thesis.
Clustering
The criterion forming a cluster is still (as in stc) the fact of sharing a sufficient number of approximate phrases. The implementation and algorithm’s design is by far more complex than stc’s and uses custom data structures similar to frequent itemset detection in data mining, but the authors pay attention to cluster label comprehensibility and enrich cluster descriptions with data extracted from a predefined ontology.
In recent, authors present a search results clustering algorithm which attempts to associate documents with a single concept where labels are chosen so that “they are good indicators of the documents they contain”. The algorithm uses frequent terms, but also preprocessed noun phrases. Unfortunately, as the authors put it: “[stems] are not usually very meaningful for use as node labels, therefore we replace each stemmed term by the most frequently occurring original term”. Note that such heuristic would obviously fail for documents in Polish. The provided screenshots show that the generated cluster labels are mostly based on single-words.
In previous, a Conceptual Clustering system that refines cluster descriptions using concept lattices. Their cluster descriptions are still single words but they use a large thesaurus and formal concept analysis to avoid repetitions and synonyms in cluster keywords.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)461
The specific weights and scores for each of these factors are learnt from examples of manually prioritized cluster labels.
In recent, present a very interesting clustering algorithm called Clustering with Committees which builds clusters around groups of few strongly associated (most similar) documents, called committees. Because committees are so strongly related with their set of features they usually point to an unambiguous concept (which authors even evaluate using semantic relationships from WordNet). The cluster description remains to be a list of strong features, but hopefully unambiguous. Pantel recently attempted to label the output classes with more “semantic” labels, but this work goes definitely deeper into natural language processing than information retrieval.
A concepts of clustering combined with pattern selection (similar to the dcf approach) where authors present a classification system which uses clusters to select labeled objects and expand the set of labeled objects with elements from within the cluster to improve classification. Cluster descriptions are not part of the consideration.
Mark Sanderson and Bruce Croft present a completely different, yet related approach to exploring document collections. Instead of clustering input documents, they start with salient terms and phrases taken from predefined queries to a document collection and expand this set with a technique called Local Context Analysis. Once a big enough collection of terms and phrases is gathered, it is automatically organized into a hierarchy, starting with most generic terms at the top and descending to most detailed ones at the bottom. The technique used by authors is very interesting as it involves no clustering techniques, yet provides a hierarchy of (quite comprehensible) descriptions of groups of documents in the output. The disadvantage is that authors bootstrap their method with a predefined set of queries, which would be unavailable for another collection of documents.
An interesting cluster labeling procedure is also shown in the Weighted Centroid Covering algorithm. Authors start from a representation of clusters (centroids of document groups) and then build their (word-based) descriptions by iterative assignment of highest scoring terms to each category, making sure each unique term is assigned only once. Interestingly, the authors point out that this kind of procedure could be extended to use existing ontologies and labels, but they provide no experimental results of any kind [2], [4], [9] and [10].
In our opinion the dcf is a meta-method which can be used to construct algorithms following a certain paradigm. We are going to demonstrate its practical implementation using two examples: Lingo and Descriptive k-Means.
The Lingo algorithm was the first implementation of the dcf approach. The algorithm was originally developed by Stanisław and presented in his master’s thesis written under supervision of Jerzy Stefanowski. Several concepts presented here are a result of author’s close collaboration with Stanisław. Lingo’s motivation and implementation fall exactly in the general pattern introduced in the dcf approach, so we present the algorithm and our
joint experiments as an example of a dcf-based method applicable to clustering search results. A detailed overview of Lingo can be found in Section 5, the next paragraph shows a general look at the algorithm.
All candidate cluster labels in Lingo are discovered directly from the input text by selecting frequently repeated phrases and terms (so-called recurring phrases). This step is similar to phrase discovery in the stc algorithm. Concurrently to candidate label discovery, a vector space model is built for all documents in the input. Lingo uses dimensionality reduction methods applied to the term-document space to find synthetic vectors that approximate topics present in the input documents. These vectors are then used to select final cluster labels from the set of all candidates. In the final step, the selected cluster labels are treated as queries to a conventional vsm-based search system and documents matching a given label are assigned to it forming a final cluster.
Descriptive k-Means (dkm), introduced in this thesis, is the second algorithm following the dcf approach. The dkm was created for two reasons: first, to deal with a different type of input data — thousands of short and medium documents. Second, to provide answers to a few interesting questions that arose during the work on descriptive clustering. The field of search results clustering is still quite recent and there is a significant shortage of data sets and methods of quality evaluation.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)462
The obvious challenge was to keep the algorithm efficient considering the predicted large number of input documents. We implement dkm by reusing efficient data structures and algorithms known in document retrieval and already present in a typical search engine used for document storage.
VI.
P
ROPOSEDT
ECHNIQUESThe propose techniques are define in two parts, first is an algorithm for clustering search results capable to discover diverse groups of documents and at the same time keep cluster labels sensible. And second is Descriptive k-Means which is applicable to collections of several thousand short and medium documents.
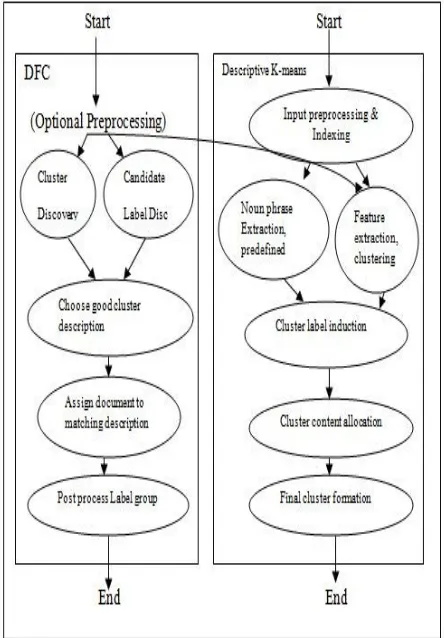
In first phase, clustering algorithm processes the input in four phases: snippets preprocessing, frequent phrase extraction, cluster label induction and content allocation. The parallels to the generic scheme introduced in the DCF are illustrated in Figure.
Figure1: Generic elements of DCF and their counterparts in Lingo.
The decomposition takes place inside cluster label induction phase; it is extracted here for clarity.
Input Preprocessing
In the preprocessing phase the input documents (titles and snippets) are tokenized and split into terms. Lingo is implemented as a component embedded in the Carrot framework and uses its infrastructure to perform certain text preprocessing tasks — stemming, marking stop words and simple text segmentation heuristics.
After tokenization is complete, a term-document matrix is constructed out of the terms that exceed a predefined term frequency threshold. After that, document vectors are weighted using.
Terms present in document titles are additionally boosted compared to these appearing in snippets by a predefined constant because titles are more likely to contain sensible information.
Frequent Phrase Extraction-
The aim of this step is to discover a set of cluster label candidates — phrases (but also single terms) that can potentially become cluster labels later. Lingo extracts frequent phrases using a modification of an algorithm presented. A word-based suffix array is constructed and extended with an auxiliary data structure — the LCP (Longest Common Prefix). This allows the algorithm to identify all frequent complete phrases in order of n time, n being the total length of all input snippets. The frequent phrase extraction algorithm ensures that the discovered labels fulfill the following conditions:
Appear in the input at least a given number of times (it is a tuning threshold);
Not cross sentence boundaries; sentence markers indicate a topical shift, therefore a phrase extending beyond one sentence is unlikely to be meaningful;
Be a complete frequent phrase (the longest possible phrase that is still frequent); compared to partial phrases, complete phrases should allow clearer description of clusters.
Neither begins nor ends with a stop word; stop words that appear in the middle of a phrase should not be discarded.
Cluster Label Induction-
During the cluster label induction phase, Lingo identifies the abstract concepts (or dominant topics in the terminology used in DCF) that best describe the input collection of snippets. There are two steps to this: abstract concept discovery, phrase matching and label pruning.
Cluster Content Allocation
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)463
Note that from the point of view of DCF, traditional Vector Space Model used for comparisons is not ideal — the label’s word order and proximity is not taken into account.
Final Cluster Formation-
Finally, clusters are sorted for display based on their score, calculated using the following formula:
Cscore = label score×||C||,
Where ||C|| is the number of documents assigned to cluster C. The scoring function, although simple, prefers well-described and relatively large groups over smaller ones.
Descriptive k-Means algorithm
The second phase of our propose technique is Descriptive k-Means closely follows the DCF approach. The cluster label discovery phase is implemented in two alternative variants: using frequent phrase extraction and with shallow linguistic processing for English texts (extraction of noun phrase chunks). Dominant topic discovery is performed by running a variant of k-Means algorithm on a sample of input documents.
We experimented with various types of features and weighting schemes for document representation and found out that, except for point wise mutual information which is known to cause problems, all of them gave similar results. In pattern phrase selection phase the algorithm uses a Vector Space Model to calculate similarities between cluster label candidates and dominant topics (represented by cluster centroids). Document assignment phase uses a mix of vsm and a Boolean model implemented on top of a search engine (and utilizing its data structures) to ensure processing efficiency. The document assignment phase, unlike in Lingo, searches for documents that contain a pattern phrase, but allowing certain distortions such as minor word reordering and different words injected inside. The level of pattern phrase distortion is adjustable and is a parameter of the algorithm.
Preprocessing
In the preprocessing step we initialize two important data structures: an index of documents and an index of cluster candidate labels. An index is a fundamental structure in information retrieval. Each entry added to an index (document or candidate cluster label in our case) is accompanied by a vector of terms and their counts appearing in that entry. The index also maintains an associated list containing all unique terms and pointers to entries a given term occurred in (inverted index).
The index allows performing queries that is search for entries that contain a given set of terms and sort them according to weights associated with these terms. In our experiments we utilize a document retrieval library that creates indices.
Indices are essential in dkm to keep the processing efficient. Note that the index of documents is usually created anyway to allow searching in the collection and the index of cluster labels may be reused in the future, so the overhead of introducing these two auxiliary data structures should not be too big.
Each incoming document is segmented into tokens using the heuristic implemented. A unique identifier is assigned to the document and then it is added to an index ID. If cluster candidate labels are to be extracted directly from the input documents, this process takes place concurrently to document indexing. Depending on the variant of dkm, we extract frequent phrases or noun phrases (from English documents). The resulting set of candidate labels is added to a separate index IP. Each candidate cluster label is indexed as if it were a single document. To minimize the number of identical index entries, we keep a buffer of unique labels in memory and flushing them to the index in batches.
Dominant Topic Detection
Dominant topic detection reuses data structures already present in the index of documents ID and runs the k-Means clustering algorithm on a sample of documents to detect dominant topics.
Preparation of Document Vectors
Let us recall that the index contains a vector of terms and their occurrences for each document. Depending on the input size, we either take all documents or select a uniform random subset and fetch their feature vectors from the index. To speed up computations (cosine similarities), we weight all the features and then limit the number of features for each selected document to a given number of most significant terms to make document vectors even more sparse.
Anticipating experimental results shown in the next section, the choice of a weighting formula was marginally important; with the exception of point wise mutual information, all other strategies behaved similarly.
Clustering with k-Means-
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)464
Similarity
Cosine distance is used to calculate similarity between document vectors. This choice is motivated by computation efficiency needed for handling large numbers of documents.
For normalized vectors dt and d j the cosine similarity
simplifies to:
sim( dt, d j) = cos(α)= (d t . d j)/ |d t | |d j |= (d t . d
j)………(1)
[image:7.612.57.279.369.688.2]By representing cluster centroids as dense vectors and documents as sparse vectors, multiplication of two document vectors in Equation 1 can be implemented in one loop iterating over the components of the sparse vector only (this is the reason for making feature vectors as short as possible). The total cost of calculating similarity between two documents is the order of O (m) floating point multiplications, where m is the number of components of the sparse vector.
Figure 2: Generic elements of DCF and their counterparts in Descriptive k-Means.
Algorithm used to bootstrap k-Means-
1: D ← a set of input documents;
2: k ← number of “topics” expected in the input;
3: C ← a set of k centroid vectors c 1 . . . c k, initially
empty;
4: s = 0.1× ||D||; /* Subsample ratio. */
5: Ds = random_sample (D, s); /* Select random sample of size s. */
6: c1 = average (Ds ); /* The first centroid is the average of the sample. */
7: for all i = 2,3, . . . ,k do
8: /* Next centroid is initialized to a document most dissimilar to previous centroids. */
9: c i= argmax (∑j=1,2,3……..i-1 sim (d, c j))
d ∈D s
10: end for
11: C contains the initial centroids.
Initial StateProper selection of the initial state is crucial in k-Means to ensure the clusters are diverse and truly representative. We chose to initialize the algorithm by selecting most diverse documents from a subsample of the input (above).
Convergence Criterion We used a composite convergence
criterion for interrupting the computation loop in k-Means. The computation ends when any of the conditions below is true:
1. Global objective function (sum of distances from documents to their centroids,
Or
2. Fewer number of documents than min is reassigned between clusters.
The objective function in k-Means is by itself monotonic, so the algorithm will always terminate at some point. We added the second condition to trim the trailing iterations which might keep improving the global function, without affecting the centroid vectors.
Selection of the Desired Number of Clusters -We assumed
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)465
Once k-Means converges to stable cluster centroids, they become the final result of this Phase.
VII.
R
ESULTSE
VALUATIONThe goals of descriptive clustering differ slightly from those of typical clustering; we try to find coherent, properly described groups of documents, not just groups of documents. This particular aspect seemed to be completely locked for any kind of objective assessment and we knew that finding a way of performing evaluation would be a difficult issue.
A user survey is practically the only way of evaluating the quality of cluster labels. The cutting edge of dcf is in providing more comprehensible cluster labels as an outcome of how the algorithms are built hopefully with meaningful clusters label candidates from the start. By showing that the document clustering quality does not degrade, and at the same time knowing a dcf-based algorithm should be able to explain its results more clearly, we could indicate its advantage. To summarize, the evaluation presented in this chapter has two different aspects.
The aspect of clustering quality, measured as conformity to a predefined structure of classes (comparison against a set of given classes, the ground truth).
The utilitarian value of the concepts presented in this thesis and published in the Carrot framework. The system has been available as an open source project for a few years, so we have a good perspective of who and how has been using it. We present the feedback we received from its users.
In the first experiment, we compared the clustering quality of Lingo against the benchmark algorithm Suffix Tree Clustering (stc). We used two different ways of inspecting the results. In the first analysis the results for a few synthetic data sets were inspected and evaluated manually. The second analysis attempted to measure the distribution of original ground truth partitions in the final result.
The second experiment provided us with observations that applying dcf to a well known clustering algorithm does not decrease its quality. Quite the contrary: all the results seem to indicate that we gained on purity of the resulting clusters and knowing how dcf constructs cluster labels, these should improve as well. Obviously, the baseline algorithm in our experiment (k-Means) is quite weak and a fine text clustering algorithm would have a higher quality rating, but we believe that an initial conclusion is justified: dcf does not have a destructive effect on the original
clustering and offers rewards in the area of cluster labeling. Summarizing, the outcomes from the experiment are:
Modifying an existing clustering algorithm by applying dcf did not seem to have any negative effect on clustering quality.
Descriptive k-Means tends to produce small, compact but also relatively pure clusters.
Pointwise mutual information is not a good feature weighting scheme for dcf because it tends to pick low-frequency terms with no matches in the candidate cluster labels set.
We noticed no extra quality gain from using noun phrases instead of frequent phrases, although manual inspection of the output cluster labels shows that in many cases noun phrases were more clear and accurate (this judgment is very subjective though).
It seems that Descriptive k-Means can be successfully applied to efficiently cluster thousands of documents (as in the experiment) and even if memory or disk space becomes a problem then sub-sampling of the original document set delivers an sufficient approximation of the exact result.
VIII.
C
ONCLUSIONDocument clustering becomes a front-end utility for searching, but also comprehending information. We started this paper from the observation that clustering methods in such applications are inevitably connected with finding concise, comprehensible and transparent cluster labels a goal missing in the traditional definition of clustering in information retrieval.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 5, May 2012)466
We demonstrate dcf on two concrete algorithms applicable to important problems found in practice: clustering results returned by search engines and clustering larger collections of longer documents such as news stories or mailing lists. The paper ends with a presentation of results collected from empirical experiments with the two presented algorithms.
The motivation for this paper arose as a consequence of observing new applications of clustering methods in information retrieval and the needs of real users using these applications. Our initial goals were to create a method able to accurately describe existing clusters, but they soon changed when we realized that the problem itself needs to be rewritten to permit sensible solutions. The definition of descriptive clustering is, in our opinion, a better way of reflecting the needs of a user who needs to browse a collection of texts, whether they are snippets or other documents.
Moreover, we show that dcf combined with smart candidate label selection (noun phrases, for example), allows easier resolution to the problem of cluster labeling that are more likely to fulfill the requirements of descriptive clustering defined at the beginning of this paper, especially comprehensibility and transparency.
R
EFERENCES[1] A. El Oirrak, and D. Aboutajdine, “Combining BOW representation and Appriori algorithm for Text mining”, IEEE 2010.
[2] Jiabin Deng, JuanLi Hu, Hehua Chi, and Juebo Wu, “An Improved Fuzzy Clustering Method for Text Mining”, IEEE 2010 Second International Conference on Networks Security, Wireless Communications and Trusted Computing, pp. 65-69.
[3] Bin XU and Yufeng Zhang, “A New Polarity Clustering Algorithm Based on Semantic Criterion Function For Text of the Chinese Commentary”, IEEE 20I0 3rd International Conference on Advanced Computer Theory and Engineering (ICACTE), pp. V4-116-119.
[4] Yan Zhang, Mingyan Jiang, “Chinese Text Mining Based on Subspace Clustering”, IEEE 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010), pp. 1617-1620.
[5] Mohamed Yassine, and Hazem Hajj, “A Framework for Emotion Mining from Text in Online Social Networks”, IEEE 2010 International Conference on Data Mining Workshops, pp. 1636-1642.
[6] Hui Yang , Bin Yang, Xu Zhou, Chunguang Zhou, and Zhou Chai, “Community Discovery and Sentiment Mining for Chinese BLOG”, IEEE 2010 Seventh International Conference on Fuzzy Systems and Knowledge Discovery (FSKD 2010), pp. 1740-1745.
[7] Lijun Wang, Manjeet Rege, Ming Dong, and
Yongsheng Ding, “Low-rank Kernel Matrix
Factorization for Large Scale Evolutionary Clustering”, IEEE 2010.
[8] Rekha Baghel and Renu Dhir, “Text Document Clustering Based on Frequent Concepts”, IEEE 2010 1st International Conference on Parallel, Distributed and Grid Computing (PDGC - 2010), pp. 366-371.
[9] Danushka Bollegala, Yutaka Matsuo, and Mitsuru Ishizuka, “A Web Search Engine-based Approach to Measure Semantic Similarity between Words”, IEEE 2010.