ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
QUERY ADAPTIVE HASH BASED IMAGE RETRIEVAL IN
INTENT IMAGE SEARCH
1B. PRASANTHI, 2SURESH PABBOJU, 3D. VASUMATHI
1
Dept of CSE, MGIT,Hyderabad, Telangana, India
2
Department of IT, CBIT, Hyderabad, Telangana, India
3
Department of CSE, JNTUH, Hyderabad, Telangana, India Email: [email protected], [email protected],
3
ABSTRACT
Now-a-days in websearch engines like Google, Bingo enable image search, especially the crucial task of text feature-based image retrieval. Features are very important in Content Based Image Retrieval (CBIR) that deal with web scale image search. Features like color, shape, texture etc. are used to represent quality, efficiency and scalability of images from large image databases. Conventionally, CBIR was used for dealing with quality and other features in relevant image search for image retrieval. CBIR follows high time complexity on index arrangement in large image databases. Feature Extraction is also a complex task in CBIR to retrieve quality images from overall image databases. It is considered as a very important measure to solve ambiguity in text-based image retrieval. In this paper, we propose to develop a Novel Image Intent Query Adaptive Search approach based on user query image with limited focus on text-based image retrieval. Our research seeks to capture the users search intents from the click-based image retrieval approach. Experimental evaluation shows that our approach improves precision in top ranked images, apart from user experiences with intention and visual features.
Keywords: Content Based Image Retrieval (CBIR), Intent Image Search, Color, Shape, Visual Features.
1. INTRODUCTION
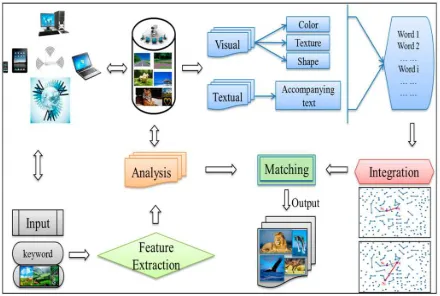
[image:1.612.310.530.410.558.2]Retrieving relevant data (i.e. images, videos and other forms) is a progressive concept in the present day scenario due to the increase in online image repositories for real time applications. These modern repositories offer multiple techniques for navigating, indexing and searching relevant data from large image databases. In recent times, indexing primarily focuses on manually-entered tags or individuals and usage of group patterns in real time image data retrieval. Manually-designed tags can be quite subjective when applied to the shown image content with tags as related to relevant data. For example manual instance tag for “Cristamus” in Flicker database extract relevant data is related to Christmas with content images applied to retrieve relevant data. It is applicable only when a few images tagged as well as content. If one query consists of a large number of images (thousands of images related to Cristamus) then, manual tagging is not possible to arrange retrieval of images with tagged content. The procedure for tag-based image retrieval from large image databases is shown in figure 1:
Figure 1: Procedure For Retrieving Tag-Based Image Retrieval With Visual Features.
ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
probabilistic Latent Semantic Research (Paul) [7] and Invisible Dirichlet Allocation (IDA) [4] have been presented and realigned for Image material analysis projects such as field category [8] and item identification [10]. Records are considered as mixtures of innovative (hidden) subjects (also known as aspects) under the premise of a bag-of-words papers reflection. Applied to visible projects, the combination of hidden topics refers to the level to which a certain object/scene type is contained in the picture. In the ideal case, this must bring about a low-dimensional information about the rough picture material and thus allows recovery in substantial databases. By observing the analysis present in [1], we find Content Based Image Retrieval (CBIR) to be an effective research concept in recent years to eliminate manual tag implementation in large image databases. Considering the procedure for employing conventional manual image repository in relevant image data retrieval from large image data bases, it has two major disadvantages. Firstly, it is broadly labor- intensive, time consuming and expensive in real-time application. Secondly, semantic image tag representation is difficult when more number of images contain same features in different scenarios. So, the Content Based Image Retrieval (CBIR) approach that tries to recover pictures straight and instantly by being centered on their visible material such as color, structure and shape was suggested [1,2]. In an average content-based picture recovery system, the question design is questioned by example, which queries the top N pictures similar to an example picture. Before the recovery, the visible features are produced from all pictures in a picture data source off-line.
Current content-centered picture recovery methods are split into three categories: shape, structure and Color. Shape details of the pictures are used for special picture recovery techniques, whereas, color and structure-centered recovery methods are used for worldwide and quite automatic techniques.Retrieval methods centered on shape features are an appealing track [4,5] to provide the required performance. However, the recovery methods centered on shape histograms mostly neglect spatial details in the related process. As considered, the procedure of current manual image retrieval technique does not follow any systematic or automatic step-by-step procedure for retrieving relevant images with respect to feature extraction from large image databases.
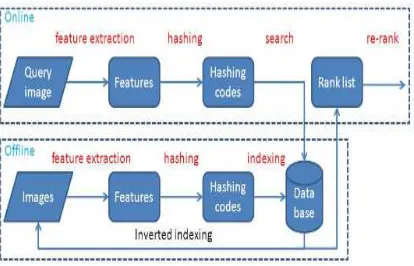
[image:2.612.326.533.241.374.2]In fact, effective and quality-based image retrieval may achieve better results in the automatic image retrieval system based on tag implementation with feature extraction. So in this paper, we propose to implement Adaptive Query Intent Search approach for quality based image retrieval. The procedure for the proposed approach is delineated in figure 2. The essential aspect of this record is the offer of a novel approach that decides inquiry versatile burdens for every piece of the hash necessities, which has two essential advantages.
Figure 2: Illustration Of Proposed Work With Query Adaptive Search.
ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
then utilized for web figurings of the inquiry versatile burdens by rapidly breaking down the region of an inquiry picture to the image sorts of the semantic sessions. In conclusion, computed Hamming distance is utilized for inspecting similarities between the inquiry and pictures with an emphasis on the information source. We name this ascertained extent as question versatile Hamming distance, when contrasted with the inquiry free Hamming distance as utilized as a part of current performs. Considering its poor application on web, any search to assess the ascertained is considered unnecessary.Hamming distance takes into account genuine weights implemented on the hash codes, which is one of the most critical advantages of hashing. Rather the heaps might be utilized as signs to successfully arrange the returned pictures (found by sensible XOR operations) at the hash guideline stage. We see that the proposed procedure creates unmistakably better result (base column) by obtaining pictures with Hamming separation 1 to the inquiry. Considering that by and large, not enough,if not zero pictures with Hamming separation are available to search queries for effective image retrieval. Experimental evaluation for proposed approach achieves extensive utilization in real time demonstration in content-based image retrieval.
The rest of this paper is organized as given hereunder: Section II describes related work on query image retrieval by various authors with sequential execution of content based image retrieval in real time applications. Section III formalizes CBIR for image retrieval with architectural implementation and progress improvement in image retrieval. Section IV executes the proposed approach for image retrieval. Section V breiefly describes the comparison between CBIR and Adaptive Query Search experimental setup in image retrieval. Section VI deals with the overall conclusion in visual image retrieval.
2. RELATED WORK
In this section, we observe different image retrieval techniques with implementation in real time application development. The system proposed by D. Nister et al [15] , separates pictures by utilizing a quad-tree. In Leung and Ng's technique [5] , every image has a 4-level multi-determination reflection. At the first stage, the image appears as a stand out shape of histogram. In the second stage, the image is
isolated into four non-covering items, each one representated by one shape histogram. Remaining 2 stages have progressively devolved four new contracts based on dimensionality, shape and color. The work of Ha nguyen et al [2] , separates pictures into three phases. In the first stage, the entire image data base maintains itself. In the second stage, a 3 level image repository and in the third stage, a 5 level image storage is located. The ranges in this technique are of different measurements (as per their level), covered in various stages. The procedure of
A.
Torralba et al [7], is much thesame as the past methodology: they utilize a quad bush of three phases to separate an image.
A strategy for shading pair has been represented by a diverse state of an image as recommended by A. M. Muja et.al, G. Lowe et al. [18] upgraded by Chua et al. Areas abutting outline elements in the pictures is an examination of picture fragmented systems. There are extremely astounding sentiments related to the normal picture recovery process.Numerous individuals have executed straightforward components, for example, shape and structure in frameworks introduced years earlier, while more successful elements, for example, GIST and SIFT have been used more recently [2]. In this task, we have chosen the favored Bag of Words (BoW) reflection in light of the nearby invariant SIFT highlights. The intensity of this determination reflection has performance in this report is more suitable for a successful search , this territory mostly is premised on the ebb and flow tasks found as a compelling search for frameworks, which are roughly isolated into three classifications: Topsy turvy data record, tree-based posting, and hashing.
ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
each inquiry in Google web search, 2 I n the BoW reflection.A single image may contain a huge number of unmistakable terms, bringing forward a vast number of candidate pictures (starting from the upside records) that need further confirmation-a procedure that is typically fixated on similatities with unique BoW highlights. This, for the most part, limits the application of Topsy turvy data documents for broad picture search. A large portion of the current hashing methods is without supervision. Among them, the most easily understood hashing system is Locality Sensitivity Hashing (LSH). As of late, B. Ko et.al [4] and h. Byun et.al [4] delayed LSH to work in the relevant piece area, and P. Indyk et al [19]. Proposed min-Hashing to build LSH for classes of components. Since these LSH-based systems use irregular projections, when the measuring of the input territory is great, many more pieces (irregular projections) are expected to get easily executed. Essentially propelled by this, Weiss et al. [9] proposed a strange hashing (SH) technique that hashes the critical region that is fixated on data accommodation. SH additionally ensures that the guesses are orthogonal and case assortment is solid crosswise over various buckets. Despite the fact that SH can fulfill differential or surprisingly better effectiveness than LSH with a less collection of pieces, it is important to underline that these without supervision hashing systems are not sufficiently viable for indistinguishable picture searches. This is due to the way the similarity in picture search is not just equivalent to the region of low-level obvious elements,even though it is more suitable for abnormal state picture semantics (e.g., things and scenes). Under this circumstance, it is important to utilize some gadget examining techniques to segment the low-level capacity range as per preparing bands on semantic stage. A few observed procedures have been proposed of late to comprehend attractive hash features, [4], [5], [6]. In [15], Kulis and Darrell recommended a technique to comprehend hash highlights by lessening remodel friction between novel capacity ranges and Hamming scopes of hash prerequisites. By changing the remarkable capacity ranges with semantic similarities, this methodology can accommodate checked hash elements. In [16], Lin et al. recommended hash highlights that are fixated on semantic similarities of things in pictures.
3. CBIR BASED IMAGE RETRIEVAL
Color performs a very small part in picture recovery that is not enough to a image. For example, when we consider two pictures, their structural likeness may match, but their combinations are different. If the recovery is centered only on color, these pictures are different, otherwise they are similar.
3.1.Spatial Features
Therefore, we can consider that the mixing of spatial and color functions are very necessary. Two pictures are found to be similar, if they contain identical areas with letters, roles of two pictures. Therefore, two pictures are contain areas with identical color roles. One can be chosen, if its regularity is chosen based on unwanted features. To determine color, material one uses color histogram. Histogram H (Img, i) of a picture can be approximated as a variety of p with the same color I. During the building of color histogram, histogram HImg symbolizes color arrangements of the whole picture. After that, color histogram is turned by regularity of each color. Depending on the color, we execute plans to get spatial details functions that are used for calculating likeness of pictures. Then, we cope with a formula for getting spatial details of any given color. Let us consider the result showed by n variables
( 1, 2,...
A A
An
)
, procedure determining k factors on each axis of an n sizing area defines splitting kn. These factors partition the area into kn cells{
i\
1, 2,... }
nBR
=
BR i
=
k
where theprojector screen of BRi into jth axis figures out an interval
I
i j( ) onA
j(1
≤ ≤
j
n
)
. This probability in image retrieval can be used for processing effective dimensional based data retrieval by partitioning P parts into equalization pixels of histogram generation. The calculation of histogram leveling is for grouping chosen hues. With each chosen shading, the calculation is connected with a picture space as per pivots a and b. The after effect of the calculation is an arrangement of queries with every shading based on relevant group classification features.ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
It is the criteria for making histogram adjustment while bunching picked shapes. With every picked shape, the criteria are utilized with a photo zone as per the hubs, a and b. The after effect of the criteria is an arrangement of zones with every shape. It is extremely basic, in light of the fact that the region BRi is exhibited by territory of rectangular shape
a b a
tli,
tli,
bri,
x
bri . This criteria is portrayed as : First of all, entire picture is viewed as a region. In the first step, the picture can be separated into two ranges of construct in light of the estimation of value work Cost (BRi) and bunching shape utiliziation of histogram leveling system. With every zone, a partitioned necessity is utilized to see if a region is separated. In the event that the discoveries fall into the significant distinction as opposed to the anticipated normality, the region is reliably required, with every territory needed to discover the estimation of value work Cost (BRi) to discover the range BRi isolation as indicated by straight or on a level plane course. Expected normality is measured by experience of outline accommodation. On the odd chance that announcement styles are undesirable in the expected normality, the segment should be progressing and with every territory needed to discover the estimation of work value. Histogram image data retrieval procedure may be presented as follows:Algorithm 1: Algorithm For Procedure In Histogram Verification In Image Retrieval
By using the above procedure in real time, feature extraction may be analyzed with pixel values along with shape function and spatial
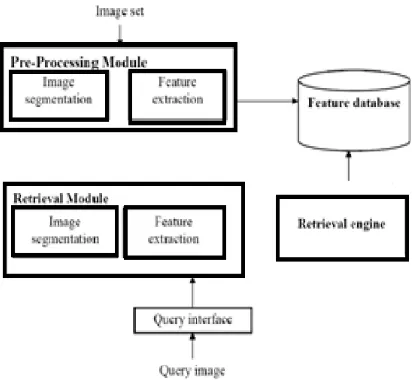
[image:5.612.92.298.468.658.2]details to determine likeness catalog between two pictures Img1 and Img2. Let C(i; k) signify ith group of kth color.
Figure 3: CBIR Procedure For Image Retrieval From Large Data Bases.
The CBIR architecture as per Figure 3 shows the structure of our suggested picture recovery program. The program includes two main modules: pre-processing and recovery component. The pre-processing subsystem is responsible for getting appropriate features from pictures and saving them into the picture data source. This process is performed off-line. The recovery component, inturn is constructed as is given below: the user interface allows a user to specify a question by means of a questionable design and to imagine the recovered identical pictures. The recovery component ingredients, a feature vector from a questionable design is applied with measurement as the Euclidean distance to evaluate the likeness between the questionable picture and the data source pictures. Next, it positions the data source pictures in a diminishing order of likeness to the questionable picture and sends the most identical pictures to the user interface component.
4. PROPOSED SYSTEM FRAMEWORK
The suggested query-adaptive image procedure is depicted in Fig. 4. To achieve the objective of the query-adaptive approach, we utilized a set of semantic idea sessions, each with I/P: Img-Image, Min Area-, E-threshold.
O/P: C-Color Information, BR-Spatial information of Img. tack Img do
1. BR Stack, if (area(BR)>minarea)
2. Split BR into 2 regions {BRj},j=1,2 by
represent horizontal or Vertical based
on cost function
Cost(BR)=MAX(Dselectdrew,Dselectedcol)
3. For each BR, calculate
( ) exp( )
exp( )
obs j
j
DX
j
−
=
ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
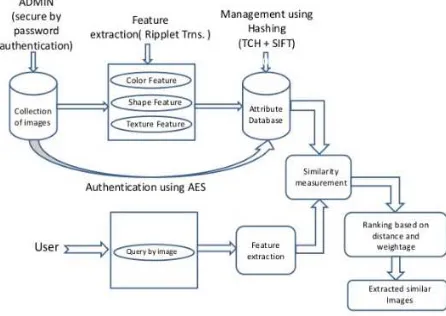
[image:6.612.79.302.223.381.2]a set of associate pictures shown in level by level comparative utilization in segmentation of image retrieval . Low-level functions (bag-of-visual-words) of all the images are included in hash requirements, on top of which we compute bit sensible loads for each of the semantic ideas independently. The bodyweight calculations procedure is done by a formula that lies at the core of our strategy, which will be discussed later in Section V.
Figure 4: Procedure Of Online Framework In Image Retrieval Based On Attribute Database Hashing.
The above figure demonstrates the procedure of online look for relevant images. We first estimate hash rule of the questionable picture, which is used to look for the pictures in the predetermined semantic classes. Next, we share a huge set of pictures that are nearer to the question in Hamming area;and use them to predict bit sensible loads for the question (cf. Section V). One assumption made here is that pictures around the question in Hamming distance jointly should be able to infer, question semantics, and therefore the pre-computed Class Specific bitwise weights of these images can be used to estimate bit sensible loads for query propagation. Lastly, with the query-adaptive loads, pictures from the target database can be quickly routed by calculating (query-adaptive) Hamming distance to the given query.
5. ADAPTIVE QUERY SEARCH IMPLEMENTATION
With hash prerequisites, versatile picture search for Hamming region utilizes Hamming distance. Significantly, the Hamming distance between two hash prerequisites is the check of prices at which the parallel standards are
distinctive. Specific records/spots of the pieces with various standards are not respected. For instance, given three hash necessities, the Hamming scope of X and Y is comparable to that of Z and X, even while paying little attention of which Z is distinctive X in the initial two pieces while Y shifts in the last two pieces (X,Y,Z taken bit values as default i.e. 16 bit). Because of this attribute of the Hamming range, in essence, there can be a lot of illustrations, talking about the same result of an inquiry. Coming back to the case, we understood that if the initial two pieces were more crucial (discriminative) for X, then one ought to be evaluated better than in the inquiry. Here, we prescribe to comprehend inquiry versatile burdens for every piece of the hash necessities, so that photos with the same Hamming extent to the inquiry can be asked for in a superior quality.
5.1.Learning Class-Specific Bitwise Weights
To effectively assess the inquiry versatile burdens, we prescribe that as a matter of first importance let’s comprehend class-specific bit wise loads for a few semantic thought sessions (e.g., minutes and articles). Assuming that, we have a data set of semantic sessions, each with an arrangement of related pictures (preparing data). We comprehend bit-wise stacks autonomously for every classification, with the objective of maximizing intra-class resemblance and in addition, keeping similarity between class association. Authoritatively, for two hash necessities X and Y in sessions i and j individually, their region is configured by
ascertained Hamming distance
2
||
x oX
i−
x oY
i||
where o denotes element-wise product and qualified as follows:( ) 2 1
1
( ,... )
||
||
i
k
i
k i i
i x X
f a
a
a oX
a oc
= ∈
=
∑ ∑
−
where c(i) is center of the hashcodes. Bit-wise weight in adaptive class label image search may achieve intra- class similarity and inter-class similarity, then quantification function for semantic representation class labels is presented as follows:
min
1
,...
( ,...
1( ,... ))
1.
1 1,
1,...,
k k k
T i
a
a f a
a
g a
a
s t a
i
k
λ
+
=
=
0,
1,..., ,
iISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
Where
λ
≥
0
is a parameter controlling the balance of the two terms. Optimized sementric matrix for above optimized hamming distance as follows:1
( 1,...
)
kT i i i i
f a
ak
a A a
=
=
∑
Where
(
(
( )) (
( )))
i
i i
i
x
A
diag
x c
o x c
χ
∈
=
∑
−
−
Expand the above equation for similarity achievement re write with following procedures,
1 1
1 , 1
#
( ,...,
)
( ,...,
)
(
2
)
(
2 (
)
)
(4
)
1
2
k k
k k
T T T T
i i i jl i ij j ij l ll l
i j l
T T
l i il ii ii i ij ij j i
l j i
T T
i i i i i i
f a
a
g a
a
a A a
s
a C
a C al
a C a
a
A
s
s C a
s C a
a
a Q a
p a
t
λ
λ
λ
λ
= =
+
=
+
×
−
+
=
+
−
−
=
+
+
∑
∑
∑
∑
By noticing the above equations,we summarized bit- wise arrangement based on weights in class labels range measurement after trying to choose proper measurement so that samples of different sessions in the discovered measurement area can be better separated. For faster calculation of query adaptive bitwise weights, the above procedure is used to describe semantic database with credible and pre-defined query weights in image data retrieval.
The above system is made to utilize an individual arrangement of general hash necessities for picture search. In this subsection, we facilitate and aurgment our method for the circumstance where a few classifications of hash codes are accessible. Since there are a few semantic thought sessions, it is extremely easy to hone an arrangement of hash prerequisites for every classification by widely utilizing pictures containing the comparing thought. The class-specific hash prerequisites should be discriminatory for the specific kind of image retrieval.
6. EXPERIMENTAL EVALUATION
We performed picture search tests by using the commonly implemented NUS-WIDE dataset [42]. NUS-WIDE contains 1000 Reddit pictures, split into a training set (500 images) and quality set (500 images). It is completely marked with 81 semantic idea sessions, protecting many subjects from things (like e.g., fowl and car) to attributes(like e.g., hill and harbor). Each picture
in NUS-WIDE may be contain several semantic sessions.
Table 1: HD (Hamming Distance) Based Images Retrieval From Large Data Bases.
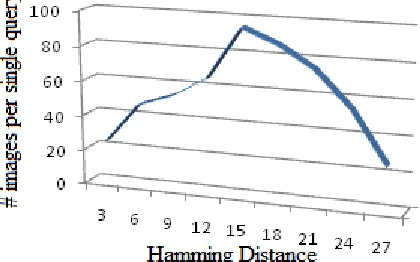
[image:7.612.326.536.353.484.2]We notice excellent performance by way of an increase in the proposed query adaptive technique as shown in fig 5.
Figure 5: Average Images Retrieved Based On Hamming Distance With Query Representation.
Performance of the proposed Query adaptive image search is shown below in table 1 with hamming distance based image arrangement from large data bases.
Let us first look into the quantity of pictures analyzed by aligning each Hamming range value to a question. The 48-bit hash requirement from DBN (Deep Brief Networks) are used in this research. We observe that we will not particularly examine the impact of code-length in this document since several past tasks on hashing have already proven that the requirements of 32–50 pieces work well in reality [8], [15]. In common, the use of more pieces often leads to enhanced perfection, but at the cost of a low memory and higher search time. Fig. 5 visualizes the outcomes, averaged over 20
H.D QUERY
ADAPTIVE SEARCH
3 25
6 55
9 75
12 95
15 85
18 65
21 45
24 35
ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
000 randomly selected concerns. As proved in the task, the quantity of returning images at each Hamming range quickly rises with the distance values until d/2. This encourages the need of our suggested strategy that provides positioning at a better granularity. Although our strategy does not permute/re-rank images with Hamming range 0 to the concerns, this research shows that this is not a crucial problem since most concerns have none or just a few such images. In DBN data network repositories, we compare CBIR with proposed approach in data retrieval based on time complexity and also compare traditional image retrieval with proceedings of real time data assurance.
6.1.Comparison Results w.r.t to Time
[image:8.612.309.552.72.231.2]Next, we move on to examine how many images obtained could be carried out from the suggested query-adaptive Hamming range, using 32-bit and 48-bit hash requirements from both SSH (Semi Supervised Hashing) and DBN (the common places qualified with brands from every class). Fig. 6 reveals the outcomes. For the DBN requirements, it enhances the 32-bit guideline by 6.2% and the 48-bit guideline by 10.1% over the whole position details. A little lower but very reliable development (about 5%) is secured with the SSH requirements. The stable developments clearly confirm the effectiveness of studying query-adaptive bitwise loads for hash requirements-centered picture search. Results obtained are as shown in table 2:
Table 2: Time Efficiency In Image Retrieval From Large Databases.
N. of. Queries
Query Adaptive
CBIR Traditional Image IR Model
1 1.2 2.4 3.7
2 2.5 3.8 4.3
3 3.5 4.8 5.4
4 4.5 5.8 6.4
5 5.5 6.8 8.4
6 6.5 7.8 9.6
Fig 6 reveals overall performance of query adaptive process with equivalence image retrieval from large data bases.
Figure 6: Performance Analysis In Real Time Image Retrieval W.R.T To Time.
To see whether the development is reliable over the evaluated queries, we bunch the concerns into 81 groups centered on their associated brands. Significant efficiency results are observed in almost all the groups, and none of them experienced from efficiency deterioration. This reveals one more approach—it provides continually enhanced outcomes for most concerns. While appealing, it is important to note that the query-adaptive hash rule choice structure happens upon extra computation and storage price. First, question pictures need to be hashed twice and search needs to be conducted with more pieces, which—as mentioned in Section V, are usually appropriate since hashing methods and bitwise functions are efficient.
7. CONCLUSION
[image:8.612.94.294.525.678.2]ISSN: 1992-8645 www.jatit.org E-ISSN: 1817-3195
comparing traditional CBIR techniques in image retrieval based on query propagation from large data sources. Further enhancement of our proposed approach may focus on image re-ranking of user feedback intentions based on user click query propogation.
REFERENCES:
[1] B. Prasanthi, Dr. P. Suresh and Dr.D.Vasumathi,” Index Based Image Retrieval Analyzed Methodologies in CBIR” proceedings in IRSCNS-2016,Vol 54,112-126.
[2] Ha nguyen thi thu and tao ngo quoc,”An effficient content based image retrieval method for retrieving images”, International journal of innovative computing, information and control icic international c 2012 issn 1349-4198 volume 8, number 4, april 2012,2823-2836.
[3] M. L. Kher_, d. Ziou and a. Bernardi, image retrieval from the world wide web: issues, techniques, And systems, acm computing surveys, vol.36, no.1, 2004, pp.35-67. [4] B. Ko and h. Byun, frip: a region-based
image retrieval tool using automatic image segmentation And stepwise boolean and matching, ieee transactions on multimedia, vol.7, no.1, 2005, , pp.105-113.
[5] Yu-gang jiang, jun wang and xiangyang xue “ Query-adaptive image search with hash codes”, proceedings in ieee transactions on multimedia, vol. 15, no. 2, february 2013,pp 442-453.
[6] J. Wang, s. Kumar, and s.-f. Chang, “Semi-supervised hashing for scalable image retrieval” in proc. Ieee conf. Computer vision
and Pattern recognition, 2010, pp 1753–
1760.
[7] A. Torralba, r. Fergus, and w. Freeman, “80 million tiny images: a large data set for nonparametric object and scene recognition,”
ieee Trans. Pattern anal.mach. Intell., vol. 30, no. 11, nov. 2008, pp. 1958–1970. [8] A. Torralba, r. Fergus, and y. Weiss, “Small
codes and large image Databases for recognition,” in proc. Ieee conf. Computer vision and Pattern recognition, 2008, pp 1-8. [9] Y. Weiss, a. Torralba, and r. Fergus,
“Spectral Hashing” in adv. Neural inf. Process. Syst., 2008,pp 1-8.
[10] J. Wang, s. Kumar, and s.-f. Chang, “Sequential projection learning For hashing with compact codes,” in proc. Int.
Conf.machine learning, 2010, pp 1127-1134.
[11] A. W. Smeulders,m.worring, s. Santini, a. Gupta, and r. Jain, “content- Based image retrieval at the end of the early years,” ieee trans. Pattern anal. Mach. Intell., vol. 22, no. 12, dec. 2000, pp. 1349–1380.
[12] R. Datta, d. Joshi, j. Li, and j. Z.wang, “Image retrieval: ideas, influences, And trends of the new age,” acm comput. Surveys, vol. 40, no. 2, 2008.pp 1-60
[13] J. R. Smith and s.-f. Chang, “Visualseek: a fully automated contentbased Image query system” in proc. Acm int. Conf.multimedia, 1996,pp 87-98.
[14] A. Oliva and a. Torralba, “modeling the shape of the scene: a holistic Representation of the spatial envelope,” int. J. Comput. Vision, vol. 42, Pp. 145–175, 2001.
[15] D. Nister and h. Stewenius, “Scalable recogniti on with a vocabulary Tree,” in
proc. Ieee conf. Computer vision and pattern
recognition, 2006, pp 774–781. [16] J.
Zobel and a. Moffat, “inverted files for text search engines,” acm Comput. Surveys, vol. 38, no. 2, 2006.
[17] H. Jegou, m. Douze, and c. Schmid, “Packing bag-of-features” in Proc. Ieee conf.
Computer vision and pattern recognition,
2009, pp 1470– 1477.
[18] M. Muja and d. G. Lowe, “fast approximate nearest neighbors with Automatic algorithm configuration,” in proc. Int. Conf. Computer vision Theory and applications, 2009, pp. 331–340.
[19] P. Indyk, , j. E. Goodman and j. O’rourke, eds., “Nearest neighbors In high-dimensional spaces” in handbook of discrete and
computational Geometry. Boca raton, fl: crc,
2004, ch. 39,pp 509-516.
[20] C. Silpa-anan and r. Hartley, “Optimised kd-trees for fast image descriptor Matching” in
proc. Ieee conf. Computer vision and pattern Recognition, 2008.
[21] Y. Jia, j.wang, g. Zeng, h. Zha, and x.-s. Hua, “optimizing kd-trees For scalable visual descriptor indexing,” in proc. Ieee conf.
Computer Vision and pattern recognition,