International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
499
Development of Compiler Design Techniques for Effective
Code Optimisation and Code Generation
A. Alekhya
1, Prof. Dr. G. Manoj Someswar
2 1Research Scholar, 2Professor & Research Supervisor, Pacific University, Udaipur, Rajasthan, India.
Abstract-- Many research groups have addressed code generation issues for a long time, and have achieved high code quality for regular architectures. However, the recent emergence of the electronics market that involves parallel processors constitutes a large pool of irregular architectures, for which standard techniques result in unsatisfying code quality.
Lee, Lee et al. [LLHT00] focus on minimizing Hamming distances of subsequent instruction words in VLIW processors. They show that their formulation of power-optimal instruction scheduling for basic blocks is NP-hard, and give a heuristic scheduling algorithm that is based on critical-path scheduling. They also show that for special multi-issue VLIW architectures with multiple slots of the same type, the problem of selecting the right slot within the same long instruction word can be expressed as a maximum-weight bipartite matching problem in a bipartite graph whose edges are weighted by negated Hamming distances between microinstructions of two subsequent long instruction words.[3]
Lee, Tiwari et al. [LTMF95] exploit the fact that for a certain 2-issue Fujitsu DSP processor, a time-optimal target schedule is actually power-optimal as well, as there the unit activation/deactivation overhead is negligible compared to the base power dissipation per cycle. They propose a heuristic scheduling method that uses two separate phases, greedy compaction for time minimization followed by list scheduling to minimize inter-instruction power dissipation costs. They also exploit operand swapping for commutative operations (multiplication).
Toburen et al. [TCR98] propose a list scheduling heuristic that could be used in instruction dispatchers for superscalar processors such as the DEC Alpha processors. The time behavior and power dissipation of each functional unit is looked up in an xADML-like description of the processor. The list scheduler uses a dependence level criterion to optimize for execution time. Microinstructions are added to the current long instruction word unless a user-specified power threshold is exceeded. In that case, the algorithm proceeds to the next cycle with a fresh power budget.
Su et al. [STD94] focus on switching costs and propose a postpass scheduling framework that breaks up code generation into subsequent phases and mixes them with assembling. First, tentative code is generated with register allocation followed by pre-assembling. The resulting assembler code contains already information about jump targets, symbol table indices etc., and thus a major part of the bit pattern of the final instructions is known.
This is used as input to a power-aware postpass scheduler, which is a modified list scheduling heuristic that greedily picks that instruction from the zero-indegree set that currently results in the least contribution to power dissipation. The reordered code is finally completed with a post-assembler.[1]
Aho and Johnson [AJ76] use a linear-time dynamic programming algorithm to determine an optimal schedule of expression trees for a single-issue, unitlatency processor. The addressed processor class has a homogeneous register set and allows multiple addressing modes, fetching operands either from registers or directly from memory.
Keywords-- Lexical Analysis, Syntax Analysis, Semantic Analysis, Code Optimization, Very Long Instruction Word, Load Imbalance
I. INTRODUCTION
Compiler Design Techniques
Programming languages are notations for describing computations to people and to machines. The world as we know it depends on programming languages, because all the software running on all the computers was written in some programming language. But, before a program can be run, it first must be translated into a form in which it can be executed by a computer. The software systems that do this translation are called compilers.
Structure of a Compiler
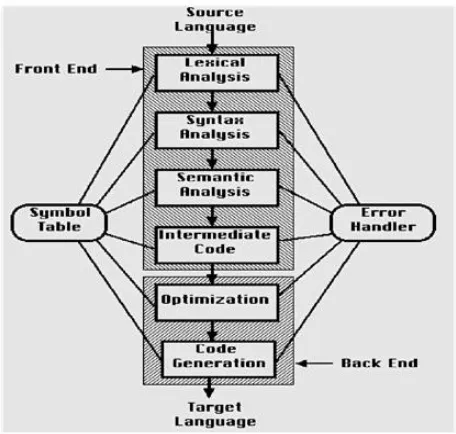
A compiler is a program that can read a program in one language, the source language and translate it into an equivalent program in another language, the target language. A compiler is a box that maps a source program into a semantically equivalent target program. If we open up this box a little, we see that there are two parts to this mapping: analysis and synthesis.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
500
The analysis part also collects information about the source program and stores it in a data structure called a symbol table, which is passed along with the intermediate representation to the synthesis part.[2]The synthesis part constructs the desired target program from the intermediate representation and the information in the symbol table. The analysis part is often called the front end of the compiler; the synthesis part is the back end.
[image:2.612.54.282.245.462.2]Below figure shows the structure of a compiler:
Figure 1: The structure of a Compiler
Lexical Analysis
The first phase of a compiler is called lexical analysis or scanning. The lexical analyzer reads the stream of characters making up the source program and groups the characters into meaningful sequences called lexemes. For each lexeme, the lexical analyzer produces as output a token of the form:
(Token-name, attribute-value)
That it passes on to the subsequent phase, syntax analysis. In the token, the first component token-name is an abstract symbol that is used during syntax analysis, and the second component attribute-value points to an entry in the symbol table for this token. Information from the symbol-table entry Is needed for semantic analysis and code generation.
Syntax Analysis
The second phase of the compiler is syntax analysis or parsing. The parser uses the first components of the tokens produced by the lexical analyzer to create a tree-like intermediate representation that depicts the grammatical structure of the token stream. A typical representation is a syntax tree in which each interior node represents an operation and the children of the node represent the arguments of the operation. The subsequent phases of t he compiler use the grammatical structure to help analyze the source program and generate the target program.
Semantic Analysis
The semantic analyzer uses the syntax tree and the information in the symbol table to check the source program for semantic consistency with the language definition. It also gathers type information and saves it in either the syntax tree or the symbol table, for subsequent use during intermediate-code generation.[4]
An important part of semantic analysis is type checking, where the compiler checks that each operator has matching operands. For example, many programming language definitions require an array index to be an integer; the compiler must report an error if a floating-point number is used to index an array.
The language specification may permit some type conversions called coercions. For example, a binary arithmetic operator may be applied to either a pair of integers or to a pair of floating-point numbers.
If the operator is applied to a floating-point number and an integer, the compiler may convert or coerce the integer into a floating-point number.
II. INTERMEDIATE CODE GENERATION
In the process of translating a source program into target code, a compiler may construct one or more intermediate representations, which can have a variety of forms. Syntax trees are a form of intermediate representation; they are commonly used during syntax and semantic analysis.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
501
There are several points worth noting about three-address instructions. First, each three-three-address assignment instruction has at most one operator on the right side. Thus, these instructions fix the order in which operations are to be done; second, the compiler must generate a temporary name to hold the value computed by a three-address instruction. Third, some "three-address instructions" have fewer than three operands.Code Optimization
The machine-independent code-optimization phase attempts to improve the intermediate code so that better target code will result. Usually better means faster, but other objectives may be desired, such as shorter code, or target code that consumes less power.
A simple intermediate code generation algorithm followed by code optimization is a reasonable way to generate good target code. The optimizer can deduce that the conversion of 60 from integer to floating point can be done once and for all at compile time, so the inttofloat operation can be eliminated by replacing the integer 60 by the floating-point number 60.0. Moreover, t3 is used only once to transmit its value to i d l so the optimizer can transform (1.3) into the shorter sequence.[6]
There is a great variation in the amount of code optimization different compilers perform. In those that do the most, the so-called "optimizing compilers," a significant amount of time is spent on this phase. There are simple optimizations that significantly improve the running time of the target program without slowing down compilation too much.
Code Generation
The code generator takes as input an intermediate representation of the source program and maps it into the target language. If the target language is machine code, registers or memory locations are selected for each of the variables used by the program. Then, the intermediate instructions are translated into sequences of machine instructions that perform the same task. A crucial aspect of code generation is the judicious assignment of registers to hold variables. For example, using registers Rl and R2, the intermediate code in might get translated into the machine code
The first operand of each instruction specifies a destination. The F in each instruction tells us that it deals with floating-point numbers. The code in loads the contents of address id3 into register R2, and then multiplies it with floating-point constant 60.0.[7] The # signifies that 60.0 are to be treated as an immediate constant. The third instruction moves id2 into register Rl and the fourth adds to it the value previously computed in register R2.
Finally, the value in register Rl is stored into the address of i d l, so the code correctly implements the assignment statement.
III. SYMBOL-TABLE MANAGEMENT
An essential function of a compiler is to record the variable names used in the source program and collect information about various attributes of each name. These attributes may provide information about the storage allocated for a name, its type, its scope (where in the program its value may be used), and in the case of procedure names, such things as the number and types of its arguments, the method of passing each argument (for example, by value or by reference), and the type returned.[8]
The symbol table is a data structure containing a record for each variable name, with fields for the attributes of the name. The data structure should be designed to allow the compiler to find the record for each name quickly and to store or retrieve data from that record quickly.
The Grouping of Phases into Passes
The discussion of phases deals with the logical organization of a compiler. In an implementation, activities from several phases may be grouped together into a pass that reads an input file and writes an output file. For example, the front-end phases of lexical analysis, syntax analysis, semantic analysis, and intermediate code generation might be grouped together into one pass. Code optimization might be an optional pass. Then there could be a back-end pass consisting of code generation for a particular target machine.[9]
Some compiler collections have been created around carefully designed intermediate representations that allow the front end for a particular language to interface with the back end for a certain target machine. With these collections, we can produce compilers for different source languages for one target machine by combining different front ends with the back end for that target machine.
Similarly, we can produce compilers for different target machines, by combining a front end with back ends for different target machines.
IV. COMPILER-CONSTRUCTION TOOLS
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
502
These tools use specialized languages for specifying and implementing specific components, and many use quite sophisticated algorithms.[10] The most successful tools are those that hide the details of the generation algorithm and produce components that can be easily integrated into the remainder of the compiler. Some commonly used compiler-construction tools include1.Parser generators that automatically produce syntax
analyzers from a grammatical description of a programming language.
2.Scanner generators that produce lexical analyzers
from a regular- expression description of the tokens of a language.
3.Syntax-directed translation engines that produce
collections of routines for walking a parse tree and generating intermediate code.
4.Code-generator generators that produce a code
generator from a collection of rules for translating each operation of the intermediate language into the machine language for a target machine.
5.Data-flow analysis engines that facilitate the
gathering of information about how values are transmitted from one part of a program to each other part. Data-flow analysis is a key part of code optimization.
6.Compiler-construction toolkits that provide an
integrated set of routines for constructing various phases of a compiler.
Application and impact of a Compiler
Compiler design is not only about compilers, and many people use the technology learned by studying compilers in school, yet have never, strictly speaking, written (even part of) a compiler for a major programming language. Compiler technology has other important uses as well. Additionally, compiler design impacts several other areas of computer science. Let us review the most important interactions and applications of the technology.
V. OPTIMIZATIONS FOR COMPUTER ARCHITECTURES
The rapid evolution of computer architectures has also led to an insatiable demand for new compiler technology. Almost all high-performance systems take advantage of the same two basic techniques: parallelism and memory hierarchies.[11]
Parallelism can be found at several levels: at the instruction level, where multiple operations are executed simultaneously and at the processor level, where different threads of the same application are run on different processors.
Memory hierarchies are a response to the basic limitation that we can build very fast storage or very large storage, but not storage that is both fast and large.
Parallelism
All modern microprocessors exploit instruction-level parallelism. However, this parallelism can be hidden from the programmer. Programs are written as if all instructions were executed in sequence; the hardware dynamically checks for dependencies in the sequential instruction stream and issues them in parallel when possible. In some cases, the machine includes a hardware scheduler that can change the instruction ordering to increase the parallelism in the program.
Whether the hardware reorders the instructions or not, compilers can rearrange the instructions to make instruction-level parallelism more effective.Instruction-level parallelism can also appear explicitly in the instruction set.
VLIW (Very Long Instruction Word) machines have instructions that can issue multiple operations in parallel. The Intel IA64 is a well-known example of such
architecture. All high-performance, general-purpose
microprocessors also include instructions that can operate on a vector of data at the same time. Compiler techniques have been developed to generate code automatically for such machines from sequential programs.[12]
Multiprocessors have also become prevalent; even personal computers often have multiple processors.
Programmers can write multithreaded code for
multiprocessors, or parallel code can be automatically generated by a compiler from conventional sequential programs. Such a compiler hides from the programmers the details of finding parallelism in a program, distributing the computation across the machine, and minimizing synchronization and communication among the processors. Many scientific-computing and engineering applications are computation-intensive and can benefit greatly from parallel processing. Parallelization techniques have been developed to translate automatically sequential scientific programs into multiprocessor code.
Memory Hierarchies
A memory hierarchy consists of several levels of storage with different speeds and sizes, with the level closest to the processor being the fastest but smallest.[13]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
503
Memory hierarchies are found in all machines. A processor usually has a small number of registers consisting of hundreds of bytes, several levels of caches containing kilobytes to megabytes, physical memory containing megabytes to gigabytes, and finally secondarystorage that contains gigabytes and beyond.
Correspondingly, the speed of accesses between adjacent levels of the hierarchy can differ by two or three orders of magnitude. The performance of a system is often limited not by the speed of the processor but by the performance of the memory subsystem. While compilers traditionally focus on optimizing the processor execution, more emphasis is now placed on making the memory hierarchy more effective.
Using registers effectively is probably the single most important problem in optimizing a program. Unlike registers that have to be managed explicitly in software, caches and physical memories are hidden from the instruction set and are managed by hardware. It has been found that cache-management policies implemented by hardware are not effective in some cases, especially in scientific code that has large data structures (arrays, typically). It is possible to improve the effectiveness of the memory hierarchy by changing the layout of the data, or changing the order of instructions accessing the data. We can also change the layout of code to improve the effectiveness of instruction caches.
VI.
DESIGN OF NEW COMPUTER ARCHITECTURESIn the early days of computer architecture design, compilers were developed after the machines were built. That has changed. Since programming in highlevel languages is the norm, the performance of a computer system is determined not by its raw speed but also by how well compilers can exploit its features.[14]
Thus, in modern computer architecture development, compilers are developed in the processor-design stage, and compiled code, running on simulators, is used to evaluate the proposed architectural features.
RISC
One of the best known examples of how compilers influenced the design of computer architecture was the invention of the RISC (Reduced Instruction-Set Computer) architecture. Prior to this invention, the trend was to develop progressively complex instruction sets intended to make assembly programming easier; these architectures were known as CISC (Complex Instruction-Set Computer).
For example, CISC instruction sets include complex memory-addressing modes to support data-structure accesses and procedure-invocation instructions that save registers and pass parameters on the stack.[15]
Compiler optimizations often can reduce these instructions to a small number of simpler operations by eliminating the redundancies across complex instructions.
Thus, it is desirable to build simple instruction sets; compilers can use them effectively and the hardware is much easier to optimize. Most general-purpose processor architectures, including PowerPC, SPARC, MIPS, Alpha, and PA-RISC, are based on the RISC concept. Although the x86 architecture—the most popular microprocessor— has a CISC instruction set, many of the ideas developed for RISC machines are used in the implementation of the processor itself. Moreover, the most effective way to use a high-performance x86 machine is to use just its simple instructions.
Specialized Architectures
Over the last three decades, many architectural concepts have been proposed. They include data flow machines, vector machines, VLIW (Very Long Instruction Word) machines, SIMD (Single Instruction, Multiple Data) arrays of processors, systolic arrays, multiprocessors with shared memory, and multiprocessors with distributed memory. The development of each of these architectural concepts was accompanied by the research and development of corresponding compiler technology.
Some of these ideas have made their way into the designs of embedded machines. Since entire systems can fit on a single chip, processors need no longer be prepackaged commodity units, but can be tailored to achieve better cost-effectiveness for a particular application. Thus, in contrast to generalpurpose processors, where economies of scale have led computer architectures to converge, application-specific processors exhibit a diversity of computer architectures.[16]
Compiler technology is needed not only to support programming for these architectures, but also to evaluate proposed architectural designs.
VII. PERFORMANCE OF PARALLEL PROCESSORS
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
504
The elapsed time to run a particular job on a given machine is the most important metric. Price/performance of a parallel system is simply the elapsed time for a program divided by the cost of the machine that ran the job. It is important if there are a group of machines that are ―fast enough.‖The speed-up is generally measured by running the same program on a varying number of processors. The speed-up is then the elapsed time needed by 1 processor divided by the time needed on p processors.
The issue of efficiency is related to that of price/performance. Efficiency close to unity means that you are using your hardware effectively; low efficiency means that you are wasting resources.
Each of these metrics has disadvantages. In fact, there is important information that cannot be obtained even by looking at all of them. It is obvious that adding processors should reduce the elapsed time, but by how much? That is where speed-up comes in. Speed-up close to linear is good news, but how close to linear is good enough? Well, efficiency will tell you how close you are getting to the best your hardware can do, but if your efficiency is not particularly high.[17]
In practice, the performance evaluation of
supercomputers is still substantially driven by singlepoint estimates of metrics (e.g., MFLOPS) obtained by running characteristic benchmarks or workloads. With the rapid increase in the use of time-shared multiprogramming in these systems, such measurements are clearly inadequate. This is because multiprogramming and system overhead, as well as other degradations in performance due to time varying characteristics of workloads, are not taken into account. In multiprogrammed environments, multiple jobs and users can dramatically increase the amount of system overhead and degrade the performance of the machine. Performance techniques, such as benchmarking, which characterize performance on a dedicated machine, ignore this major component of true computer performance. Due to the complexity of analysis, there has been little work done in analyzing, modeling, and predicting the
performance of applications in multiprogrammed
environments. This is especially true for parallel processors, where the costs and benefits of multi-user workloads are exacerbated.
While some may claim that the issue of
multiprogramming is not a viable one in the supercomputer market, experience shows otherwise. Even in recent massively parallel machines, multiprogramming is a key component. It has even been claimed that a partial cause of the demise of the CM2 was the fact that it did not efficiently support time-sharing.
In the same paper, Gordon Bell postulates that, multicomputers will evolve to multiprocessors in order to support efficient multiprogramming. Therefore, it is clear that parallel processors of the future will be required to offer the user a time-shared environment with reasonable response times for the applications. In this type of environment, the most important performance metric is the completion of response time of a given application.
The first criterion taken into consideration when the performances of the parallel systems are analyzed is the speedup used to express how many times a parallel program works faster than a sequential one, where both programs are solving the same problem. The most important reason of parallelization a sequential program is to run the program faster.
If a parallel program is executed on a computer having p processors, the highest value that can be obtained for the speedup is equal with the number of processors from the system. The maximum speedup value could be achieved in an ideal multiprocessor system where there are no communication costs and the workload of processors is balanced.
There is a very simple reason why the speedup value cannot be higher than p – in such a case, all the system processors could be emulated by a single sequential one obtaining a serial execution time lower than Ts. But this is not possible because Ts represents the execution time of the fastest sequential program used to solve the problem.
According to the Amdahl law, it is very difficult, even into an ideal parallel system, to obtain a speedup value equal with the number of processors because each program, in terms of running time, has a fraction that cannot be parallelized and has to be executed sequentially by a single processor. The rest of (1 - ) will be executed in parallel.The maximum speedup that could be obtained running on a parallel system a program with a fraction that cannot be parallelized is 1/ , no matter of the number of processors from the system.[18]
The parallel execution time will be 40% of the serial execution time and the parallel program will be only 2.5 times faster than the sequential one because 20% of the program cannot be parallelized. The maximum speedup that we can obtain is 1/0.2 = 5 and this means that the parallel execution time will never be shorter than 20% of the sequential execution time even in a system with an infinite number of processors.
It is very important to identify the fraction of a program than cannot be parallelized and to minimize it.
The parallel efficiency quantifies the number of the
valuable operations performed by the processorsduring the
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
505
Due to the fact the speedup value is lower than the number of processors; the parallel efficiency will be always located between 0 and 1. Another important indicator is the execution cost representing the total processor time used to solve the problem. For a sequential program, its cost (sequential cost) will be equal with the total execution time. Finally, the supplementary cost of parallel processing indicates the total processor times spent for secondary operations not directly connected with the main purpose of the program that is executed. Such a cost cannot be identified for a sequential program.The source of this type of cost is represented by the following elements:
Load imbalance – is generated by the unbalanced tasks
that are assigned to different processors. In such a case,
some processors will finish the execution earlier so they need to wait in an idle state for the other tasks to be completed. Also, the presence of a program fraction that cannot be parallelized generates load imbalance because this portion of code should be executed by a single processor in a sequential manner.
Supplementary calculations – generated by the need to
compute some value locally even if they are already
calculated by another processor that is, unfortunately, busy at the time when these data are necessary.
VIII.COMMUNICATION AND SYNCHRONIZATION BETWEEN
PROCESSORS
The processors need to communicate each others in
order to obtain the final results. Also, there are some predefined execution moments when some processors should synchronize their activity.
In order to obtain a faster program, we can conclude we need to reduce to the minimum the fraction that cannot be parallelized, to assure the load balance of the tasks at the processor level and also to minimize the times dedicated for communication and synchronization.
The performance of parallel algorithms executed on grid systems
A grid is a collection of machines that contribute any combination of resources as a whole. Basically, grid computing represents a new evolutionary level of distributed computing. It tries to create the illusion of a virtual single powerful computer instead of a large collection of individual systems connected together.
These systems are sharing various resources like computing cycles, data storage capacity using unifying file systems over multiple machines, communications, software and licenses, special equipments and capacities.
The use of the grid is often born from a need for increased resources of some type.
Grids can be built in all sizes, ranging from just a few machines in a department to groups of machines organized in hierarchy spanning the world. The simplest grid consists of just few machines, all of the same hardware architecture and same operating system, connected on a local network. Some people would call this a cluster implementation rather than a grid. The next step is to include heterogeneous machines but within the same organization. Such a grid is also referred to as an intragrid. Security becomes more important as more organizations are involved.
Sensitive data in one department may need to be protected from access by jobs running for other departments. Dedicated grid machines may be added to increase the service quality. Over time, a grid may grow to cross organization boundaries and may be used for common interest projects. This is known as an intergrid.
We will consider a parallel program that is executed in a time of p T on a grid network composed by p computers numbered from 1 to p. The speedup of a parallel program that runs on the cluster of stations can be computed by dividing the best sequential time by the parallel one. The individual computers of the grid network are not identical so they will have different processing powers. Each proportion will satisfy the following relation:1 i P.
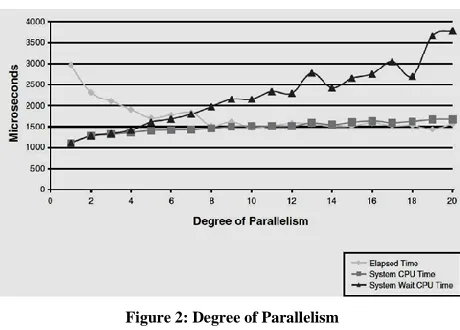
Based on these ratios, we can calculate the heterogeneity factor of the computers being part of the cluster of stations by using the differences in power that exist between them. During a program execution, the degree of parallelism will vary and this will generate the load imbalance of the processors from thesystem. Basically, the degree of parallelism is equal with the number of processors that are participating to the program execution.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
[image:8.612.52.282.134.299.2]506
Figure 2: Degree of Parallelism
IX. SEARCHING AND DICTIONARY OPERATIONS
Searching is one of the most important operations on digital computers and consumes a great deal of resources. A primary reason for sorting, an activity that has been estimated to use up more than one-fourth of the running time on most computers, is to facilitate searching.
Thus, it is safe to say that searching consumes at least 25% of the running time on most computers, directly or indirectly. Obviously, it would be desirable to speed up this operation through the application of parallelism.
During much of the history of parallel processing, parallel applications have been developed as machine-specific, and thus nonportable (often one-of-a-kind), programs. This has made parallel applications quite costly to develop, debug, and maintain. The reasons for this undesirable state of affairs are
Proliferation of parallel architectures and lack of
agreement on a common model
Infeasibility of commercial software development
based on the limited customer base
Desire for efficient hardware utilization, given the
high cost of parallel processors
Changes are afoot in all of these areas, making the prospects of truly portable parallel software brighter than ever. Ideally, a portable parallel program should run on a variety of hardware platforms with no modification whatsoever. In practice, minor modifications that do not involve program redesign or significant investments of time and effort are tolerated.
Program portability requires strict adherence to design and specification standards that provide machine-independent views or logical models. Programs are developed according to these logical models and are then adapted to specific hardware architectures by automatic tools.
X. CONCLUSION &RESULTS
Writing compilers is generally time consuming, and consequently expensive. In the worst case, once the compiler is available it might turn out that the target hardware is already obsolete. Therefore, it is important, for a code generation system to be easily reconfigurable for different architectures, i.e. to be a retargetable code generation system.
Generally, most compilation systems that come with a processor are dedicated compilers for that given architecture. However, in a design and development phase it is desirable to have a retargetable system.
In such designs the backend is specific for a given architecture, but also it may not be clearly separated from the rest of the compiler, and often the hardware information is spread within the whole compiler. In order to produce code for a different hardware, say _, it is necessary to spend considerable time and effort in porting the existing _ compiler for _ architecture.
Modular compiler toolkits, such as the compilation system CoSy [AAvS94], provide facilities to exchange compiler components, also called engines, and adapt the whole compilation system for a specific goal. Thus, if the target processor changes, it is theoretically sufficient to replace the backend (engine) of any previously constructed compiler. Modular compiler toolkits facilitate significantly the task of compiler construction, but it is still necessary to write backends for each type of target architecture.
In contrast to dedicated code generation systems, retargetable compilers require additionally to the source program a description of the architecture for which to produce code. Thus, to produce code for the hardware we need to provide the architecture description and the source program. This looks like an extra overhead compared to a dedicated compiler, but considerably facilitates the migration to some other hardware, where it is only required to modify the hardware specifications.
A retargetable codegenerator is a framework that takes the hardware description as input and produces a compiler for the specified hardware. OLIVE [BDB90] and IBURG [FHP92] are examples of a retargetable codegenerator generator tool. Codegenerator generators are generally more complex to write than dynamically retargetable frameworks.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 4, Issue 3, March 2014)
507
REFERENCES[1 ] M. Kalyanakrishnam, Z. Kalbarczyk, and R. Iyer. Failure data analysis of a LAN of Windows NT based computers. In SRDS-18, 1999.
[2 ] G.P.Kavanaugh and W. H. Sanders. Performance analysis of two time-based coordinated checkpointing protocols. In Proc. Pacific Rim Int. Symp. on Fault-Tolerant Systems, 1997.
[3 ] T.-T. Y. Lin and D. P. Siewiorek. Error log analysis: Statistical modeling and heuristic trend analysis. IEEE Trans. on Reliability, 39, 1990.
[4 ] D. Long, A. Muir, and R. Golding. A longitudinal survey of internet host reliability. In SRDS-14, 1995.
[5 ] J. Meyer and L. Wei. Analysis of workload influence on dependability. In FTCS, 1988.
[6 ] B. Mullen and D. R. Lifecycle analysis using software defects per million (SWDPM). In 16th international sympo- sium on software reliability (ISSRE’05), 2005.
[7 ] B. Murphy and T. Gent. Measuring system and software reliability using an automated data collection process. Quality and Reliability Engineering International, 11(5), 1995.
[8 ] S. Nath, H. Yu, P. B. Gibbons, and S. Seshan. Subtleties in tolerating correlated failures. In Proc. of the Symp. on Networked Systems Design and Implementation (NSDI’06), 2006.
[9 ] D. Nurmi, J. Brevik, and R. Wolski. Modeling machine availability in enterprise and wide-area distributed comput- ing environments. In Euro-Par’05, 2005.
[10 ]D. L. Oppenheimer, A. Ganapathi, and D. A. Patterson. Why do internet services fail, and what can be done about it? In USENIX Symp. on Internet Technologies and Systems, 2003.
[11 ]J. S. Plank and W. R. Elwasif. Experimental assessment of workstation failures and their impact on checkpointing systems. In FTCS’98, 1998.
[12 ]R. K. Sahoo, R. K., A. Sivasubramaniam, M. S. Squillante, and Y. Zhang. Failure data analysis of a large-scale hetero- geneous server environment. In Proc. of DSN’04, 2004.
[13 ]D. Tang, R. K. Iyer, and S. S. Subramani. Failure analysis and modelling of a VAX cluster system. In FTCS, 1990.
[14 ]T. Tannenbaum and M. Litzkow. The condor distributed processing system. Dr. Dobbs Journal, 1995.
[15 ]N. H. Vaidya. A case for two-level distributed recovery schemes. In Proc. of ACM SIGMETRICS, 1995.
[16 ]W. Willinger, M. S. Taqqu, R. Sherman, and D. V. Wilson. Self-similarity through high-variability: statistical analysis of Ethernet LAN traffic at the source level. IEEE/ACM Trans. on Networking, 5(1):71–86, 1997.
[17 ]K. F. Wong and M. Franklin. Checkpointing in distributed computing systems. J. Par. Distrib. Comput., 35(1), 1996.