2018 3rd International Conference on Information Technology and Industrial Automation (ICITIA 2018)
ISBN: 978-1-60595-607-7
An Improved Attribute Reeducation Algorithm
Based on Mutual Information for Non-Care
Information System
Sumin Yang, Shaochong Feng, Jing Chen and Hongli Yuan
ABSTRACT
For an information system the attribute reduction is one key to choose some important indexes, but the core attribute is the foundation for the present heuristic attribute reduction algorithms of rough set theory based on discernibility matrix and mutual information theory. When we apply these algorithms on the non-core information system, there will be the following problems, such as too much calculation problem, excessive reduction, or insufficient reduction. According to the characteristics of non-core information system, we propose one new heuristic attribute reduction algorithm based on mutual information, in which the evaluation of attribute important degree depends on the increment of mutual information and information entropy. And the attribute with the largest attribute important degree is selected for the initial core attribute, by which the problem that the random selection attribute cause the computational complexity is solved. By the proposed algorithm we cannot only improve the efficiency of attribute reduction, but decrease the number of attribute reduction. Both the theoretic analysis and the simulation experiments verify that the proposed algorithm is validity.1
INTRODUCTION
Rough set theory was first proposed by Poland mathematician Z. Pawlak in 1982, which can effectively analyse and deal with the imprecise, inconsistent, incomplete or other imperfect information so as to find out the implied knowledge and rules. The most significant difference compared with other uncertainty and
1
imprecise theory is that it can objectively describe or deal with uncertainty problem without providing any priori information of the processing data, such as the probability distribution of the statistics, membership function of the fuzzy theory.
THE BASIC CONCEPTS OF ROUGH SET THEORY
Definition 1: S(U,A,V,f) is set to an information system. Among them, U U Un
U 1, 2,, is non- empty finite sets which is called the domain space, a a am
A 1,2,, is non-empty finite attribute set, which is called the attribute set,
a
A
V ,aA,Vais attribute’s domain range, f:UAVais the information function,
when x is a , x has unique value in Va.On the side, for sequence C(c1(x),c2(x),,cn(x)and
sequenceD(d1(x),d2(x),,dn(x), ACD,CD,S(U,A,V,f)is called as decision table of
the information system. c1(x),c2(x),,cn(x)is called as the condition attribute set.
Definition2: For the given knowledge representation systemS(U,A,V,f), B A , the in-discernable relationship of any attribute is as follows:
( , ) : ( ( , ) ( , )
)
(B x y U U a B f xa f ya
IND
Definition 3: U is a domain set, P and U is two equivalent relation of domain
U (knowledge), U/ind(P){x1,x2,,xn}, U/ind(Q){y1,y2,,yn}, then the probability
distribution that P and Q effect on the U is defined as follows:
) ( ) ( ) ( : 2 1 2 1 n n x p x p x p x x x p X ; ) ( ) ( ) ( : 2 1 2 1 m m y p y p y p y y y p Y
(2)
Among them, ( ) , 1,2, , ; ( ) U,j 1,2, ,m; y y p n i U x x
p i j
i
i
the symbol E is the base ofE.
Definition 4: According to the information theory, the information entropy of
knowledge P is
n
i
i
i px
x p P H 1 ) ( log ) ( ) (
, the conditional entropy H(QP) of the knowledgeP relative to Qis:
) ( log ) ( ) ( ) ( 1 1 i j n i m j i j
i py x py x
x p P
Q
H
(3)
The mutual information I(P;Q)of the knowledgeP relative to Q is:
) ( ) ( ) ;
(PQ HQ HQP
I ; (4)
Definition 5: U is a domain set, P and U is two equivalent relation of domain
U (knowledge),ifInd(P)Ind(Q),then H(P) H(Q)
Definition 6: The Independent necessary and sufficient conditions of equivalent relationP of domain Uis that there is H(RP R)0for anyRP.
THE ATTRIBUTE IMPORTANCE BASED ON THE MUTUAL INFORMATION
Inthe process of decision, we pay attention which condition attribute is the most important for the last decision, so we must consider the mutual information between condition attribute and decision attribute. The article[7] proposed the method that obtain the attribute importance by the increasing amount of mutual information with adding one attribute. It is defined as follows:
}) { ( ) ( ) ; ( }) { ; ( ) , ,
(a R Q IQ R a IQ R H QR H QR a
SGF (5)
Based on the above formula(5), the chosen attributes are that there is more number in the domain, but from the information theory, it is to select the one which is chaotic, but the selected attributes are not useful for the decision.
In view of the above problems, the article [8] has made the improvement to the importance of attributes, which is defined as follows:
) ( / })) { ( ) ( ( ) ( / ) ( }) { ( ) , ,
(a RQ IQR a IQR Ha HQR HQR a Ha
SGF (6)
The improved method not only considers the increment of mutual information after adding the attribute, but also considers its own information entropy. When the mutual information increment is equal, the smaller H(a) is, the higher attribute importance degree is. But the above algorithm depends on the core attributes, when there is no core attribute, formula (6) become into:
) ( / ) , ( ) ( / ) ( ) ( ) , ,
(a R D I D I Da H a I a D H a
SGF (7)
In order to solve the problem, we improve formula (6), firstly the attribute importance of each condition attribute is calculated by formula (7), and we set the attribute with the maximal attribute important degree as the core attribute, the attribute important degree formula becomes:
) ( / })) { ( ) ( ( ) ( / ) ( }) { ( ) , ,
(a R* Q IQR* a IQR* H Qa HQR* HQR* a H a
SGF (8)
AN IMPROVED ATTRIBUTE REDUCTION ALGORITHM BASED ON MUTUAL INFORMATION
that both the increment of mutual information and attribute important degree are the biggest. The specific algorithm description is as follows:
The Input: A compatible decision tablesystem, Cis condition attributes set, Dis
the decision attribute, Uand is the domain. The Output: One attribute reduction sets;
(1)The mutual information I(C;D)is calculated between condition attribute C and decision attribute setD;
(2)All the attribute important is calculated by the formula (7),and set the
attribute with maximal attribute importance degree for the core attributeR*; (3)LetRR*
, the process is performed on the attribute setR' C R
,C' C R
as follows:
①For each attributeciC', we calculateI(QR {ci})I(QR)/H(a), and select the
one that has maximum valueci, if there is the same value for multiple attributes, we
choose one which comes the earliest, then R R {ci},C'C R
②Then we judge whether I(C;D) and I(R;D)is equal, if they are the same, then the
next step goes to (3), otherwise goes to ①.
(4) Ris a reduction result, and we output it.
THE SIMULATION EXPERIMENT
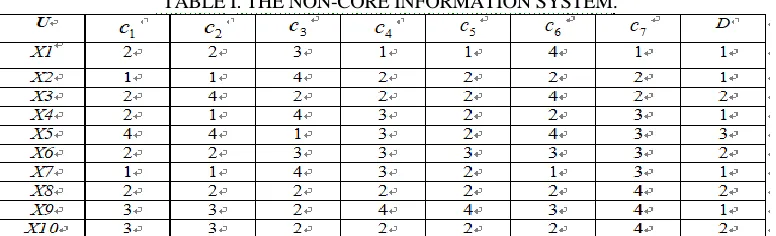
In order to verify the validity of the algorithm, we validate our algorithm by one non-core information system shown in Table 1:
From table 1, we can see that the information system has seven condition attributes C {c1,c2,c3,c4,c5,c6,c7} , ten experts give those evaluation results
} , , , , , , , , ,
{x1 x2 x3 x4 x5 x6 x7 x8 x9 x10
U , decision attributes are {d}, the value of set
C is set as V {1, 2, 3, 4}, the value of set Dis set as {1,2,3}, the in-discernable
[image:5.612.102.490.547.665.2]relationship sets of attribute D is IND(D){{x1,x2,x4,x7,x9},{x3,x6,x8,x10},{x5}, the below is the process in accordance with the algorithm of section 3:
TABLE II. THE ATTRIBUTE MUTUAL INFORMATION AND THE ATTRIBUTE IMPORTANT DEGREE.
TABLE III. THE ATTRIBUTE MUTUAL INFORMATION AND THE ATTRIBUTE IMPORTANT DEGREE.
TABLE IV. THE ATTRIBUTE MUTUAL INFORMATION AND THE ATTRIBUTE IMPORTANT DEGREE.
According to formula (4), the mutual information I(C;D) is calculated betweencondition attribute Cand decision attribute set D ;
3219 . 3 ) ( ) ( ) ;
(C D H D H DC I
;
According to the formula (6), the attribute important degree of each attribute in C sets is calculated ,the results is listed in the table II, from the table we can see that
the attribute c3has the most attribute important degree , so we set c3 for core
attribute, i.e. { 3} *
c
R ;
We Set *
R
R ,and perform the following operations on the attribute R' CR,
R C
C'
;
Then we calculate the attribute important degree of the{ci,c3} sets ,the results is
shown in Table III, it can be seen from the table III, c4,c5andc6have the same
attribute important degree, but c6has the maximal mutual information increment , so we add into the attributes reduction sets;
But I(R;D) 2.9219, it is not equal to I(C;D);
We can see thatI(R;D) 3.3219,which is the same as I(C;D),so we can terminate
this algorithm. R {c1,c3,c6}is one reduction attribute for the non-core information system.
But according to the attribute reduction algorithm proposed by article[8], the attribute reduction{c1,c2,c3,c4,c5,c6,c7} is obtained by the algorithm because the non-core factor is not considered. With the simulation experiment results ,we can see that the proposed algorithm can reduce the number of attribute reduction 57%, and decrease attribute reduction time about 42% while maintaining the information system classification ability unchanged. The experiment results validate the proposed algorithm has good attribute reduction quality and high efficiency for non-core information system.
CONCLUSIONS
According to the characteristics of non-core information system, we propose a new heuristic attribute reduction algorithm based on rough set theory in this paper, which makes use of information entropy and mutual information increment to evaluate attribute important degree. The most important attribute is selected with both the maximal mutual information and the highest attribute important degree, so we can ensure that the added attribute is surely the most influence on decision attribute. The simulation experiment results also verify the correctness and validity of the proposed algorithm.
REFERENCES
1. S. K. M. Wong. Ziarko W. 1985. On Optional Decision Rules in Decision Tables. Bulletin of Polish Academy of Sciences, 33(11):693-696.
2. Skowron A., Rauszer C. 1992.The Discernibility Matrices and Functions in Information Systems. In: Slowinski R (Eds.): Intelligent Decision Support-Handbook of Applications and Advances of the Rough Sets Theory, Kluwer Academic Publishers. London, PP: 331-362.
3. Jianhua Zhou, Zhangyan Xu, Chenguang Zhang. 2014. Quick Attribute Reduction Algorithm Based on Improved Discernibility Matrix. Journal of Chinese Computer System, 4(4):831- 835. 4. Wei Xu Zhang, Yan Zhang, Xiaoyu Wang. 2013. An Attribute Reduction Algorithm Combining
Probability Heuristic. Information and Knowledge Granularity. Computer Applications and Software, 30(7):43-46.
5. Shuhua Teng, Shilin Zhou, Jixiang Sun, et al. 2010. Attribute Reduction Algorithm Based on Conditional Entropy Under Incomplete Information System. Journal of National University of Defense Technology, 32(1): 90-94.
6. Duoian Miao, Shidong Fan. 2002. The Calculation of Knowledge Granulation and Its Application. System Engineering Theory &Practice, 1(1): 48-56.
7. Yan Yan, Huizhong Yang. 2007. Knowledge Reduction Algorithm Based on Mutual Information. Tsinghua Science and Technology, 47(S2):1903-1906.