IT 13 047
Examensarbete 30 hp
Juni 2013
Porting Linux to a Hypervisor
Based Embedded System
G Hariprasad
Institutionen för informationsteknologi
Teknisk- naturvetenskaplig fakultet UTH-enheten Besöksadress: Ångströmlaboratoriet Lägerhyddsvägen 1 Hus 4, Plan 0 Postadress: Box 536 751 21 Uppsala Telefon: 018 – 471 30 03 Telefax: 018 – 471 30 00 Hemsida: http://www.teknat.uu.se/student
Abstract
Porting Linux to a Hypervisor Based Embedded
System
G Hariprasad
Virtualization is used to improve overall system security, isolate the hardware and it properly manages the available system resources also. The main purpose of using virtualization in embedded systems is to increase the system security by isolating the underlying hardware and also by providing multiple secure execution environments for the guests. A hypervisor also called as the Virtual Machine monitor is responsible for mapping virtual
resources to physical resources.
Hypervisor based virtualization is gaining more popularity in embedded systems because of the security focussed mission critical applications. Linux OS is chosen because of its popular use in embedded systems. In this thesis, we list out the modifications required to port a Linux kernel onto a hypervisor. This Linux Kernel is already ported to ARM CPU and the hypervisor in question has been
developed by Swedish Institute of Computer Science (SICS).
Tryckt av: Reprocentralen ITC IT 13 047
Examinator: Philipp Rümmer Ämnesgranskare: Arnold Pears Handledare: Oliver Schwarz
Acknowledgments
My sincere thanks to Christian Gehrmann for giving me an opportunity to carry out my thesis work at SICS. I would like to thank Oliver Schwarz, my supervi-sor for guiding me during the course of my thesis work. Viktor Do and Arash Vahidi for helping me out with all the technical questions and details.
My heartiest thanks to Nikos Nikoleris and Dr. Philipp Rummer for their sup-port, guidance and patience in reviewing my thesis. Without them this would not have been possible.
Contents
1 Introduction 12
1.1 Operating Systems . . . 12
1.2 Embedded Systems . . . 12
1.3 Virtualization and Embedded Systems . . . 13
1.4 Hypervisors . . . 14
1.4.1 The SICS Hypervisor . . . 15
1.5 Problem Definition . . . 15
1.6 Thesis Organization . . . 16
2 Background 17 2.1 Kernels . . . 17
2.2 Linux Kernel . . . 17
2.2.1 Linux System Call . . . 18
2.2.2 Linux Interrupt Handling . . . 18
2.2.3 Linux Memory Management . . . 18
2.3 Virtualization and Virtual Machines . . . 19
2.3.1 Binary Translation . . . 19
2.3.2 Para-Virtualization . . . 19
2.3.3 Hardware Virtualization . . . 19
2.4 ARM Architecture . . . 20
2.4.1 ARM Introduction . . . 20
2.4.2 ARM Processor modes . . . 20
2.4.3 ARM Registers . . . 21
2.4.4 CPSR . . . 21
2.4.5 Interrupt Handling in ARM . . . 21
2.4.6 ARM Coprocessor . . . 22 2.4.7 MMU . . . 23 2.4.8 Page Tables . . . 23 2.4.9 TLB . . . 23 3 Related Work 1 3.1 Hypervisors . . . 1 3.1.1 Xen Hypervisor . . . 1
3.2 Related porting work done . . . 3
3.2.1 OpenBSD is ported on Fiasco . . . 3
3.3 freeRTOS porting to ARM based Hypervisor . . . 4
3.3.1 Interposition . . . 4
3.3.2 Memory Protection . . . 4
4 OVP Installation and Setup 6
4.1 Introduction to OVP . . . 6
4.2 OVP Tools . . . 6
4.2.1 ARM Integrator/CP . . . 6
4.2.2 Sourcery G++ Lite for ARM EABI . . . 7
4.3 Server-Client Setup . . . 7 5 Kernel Modifications 8 5.1 SICS Hypervisor . . . 8 5.1.1 The Hypervisor . . . 8 5.1.2 Hypervisor Modes . . . 8 5.1.3 Hypercall Interface . . . 9 5.1.4 DMA Virtualization . . . 10 5.2 Linux Kernel . . . 10
5.3 IVT and modification . . . 11
5.3.1 Program flow . . . 12
5.4 Page Tables . . . 13
6 Conclusion and Future Work 15 6.1 Conclusion . . . 15
6.2 Future Work . . . 15
List of Figures
1.1 Use case for Virtualization in Embedded systems . . . 13
1.2 Standard security use case . . . 14
1.3 General Hypervisor . . . 14 1.4 SICS Hypervisor . . . 15 2.1 CPSR . . . 21 3.1 Xen Architecture . . . 2 5.1 IVT Modification . . . 12 6
List of Tables
2.1 Vector Table . . . 22 2.2 ARM Page tables . . . 23
5.1 Hypercall Interface . . . 10
ABI Application Binary Interface
API Application Programming Interface
CPSR Current Program Status Register
CPU Central Processing Unit
DMA Direct Memory Access
DMAC Direct Memory Access Controller
DMR Dual Modular redundancy
DRM Digital Rights Management
EPT Extended Page Table
FCSE PID Fast Context-Switch Extension Process ID
I/O Input/Output
IOMMU I/O Memory Management Unit
IPC interprocess communication
ISA Instruction Set Architecture
MAC Mandatory Access Control
MMM Mixed-Mode Multicore reliability
MMU Memory management Unit
MPU Memory Protection Unit
MVA Modified Virtual Address
NUMA Non-Uniform Memory Architecture
OMTP Open Mobile Terminal Platform
OSTI Open and Secure Terminal Initiative
OVP Open Virtual Platforms
SPMD Single Program Multiple Data
SPSR Saved Program Status Register
TCB Trusted Computing Base
TCB Task Control Block
TCG Trusted Computing Group
TLB Translation Lookaside Buffer
TPM Trusted platform Module
TPR Task Priority Register
VBAR Vector Base Address Register
VM Virtual Machine
VMCB Virtual Machine Control Block
VMCS Virtual Machine Control Structure
VMI VM Introspection
VMM VM Monitor
VPID Virtual Process Identifier
Chapter 1
Introduction
Security has always been an essential feature of embedded systems and the rapid increase in growth, design requirements and performance of the embed-ded systems has made security a challenging feature of the modern systems. The demand for a secure system is natural. Even though by creating an inde-pendent execution environment in the hardware where the trusted application is safe, this method is expensive.
A way to create a secure system is through virtualization which uses hypervisors to provide an abstraction layer separating virtual machines from the CPU and isolating the virtual machines from one another. Also, in a complex multi-core hardware abstraction layer provided can manage the system more easily.
In this thesis, we describe the modifications needed to port a complex oper-ating system like Linux onto a hypervisor and the challenges faced.
1.1
Operating Systems
General purpose computers typically have an operating system, a software which acts as an interface between the user and the hardware. By providing an in-terface to the user, the operating systems makes the computer more convenient to use. It is designed to manage the system resources and the memory alloca-tion, controlling input and output devices [16]. With the development of lighter kernels, the use of operating systems in embedded systems has become common.
1.2
Embedded Systems
An embedded system can be defined as a computer which is designed for a specific purpose. Since it is designed for a particular task, embedded system cannot be used as general purpose computer. The firmware, which is the soft-ware required for an embedded system is typically stored on the chip whereas in a general purpose computer, the software is stored in the disk. Depending on the task it is designed for, an embedded system can use real time operat-ing systems with smaller footprints. Designoperat-ing embedded systems faces design constraints like limited memory, low cost, low power consumption, reliability, and guaranteed real time behaviour [9]. The embedded systems are widely used in industries like power generation, process control, manufacturing, defence,
telecommunication, automotive systems etc. An embedded system mainly con-sists of 2 parts:
1. Thehardware which in turn consists of a micro-controller/microprocessor along with memory, input/output peripherals, display and any other user interface.
2. Thesoftware written to perform a dedicated task is written, compiled and flashed into the non volatile memory within the hardware.
1.3
Virtualization and Embedded Systems
A few decades back, when the concept of embedded systems was introduced, it basically meant systems which are simple, single purpose and came with lot of design constraints. They offered relatively less complex software. But the present and future embedded systems like smartphones or mission critical sys-tems offer more functionality compared to their predecessors and the developers needs to address a lot of issues. They are expected to run applications meant for general purpose systems and designed accordingly.
By introducing virtualization in embedded systems, the system developer can address certain key issues:
1. Since embedded systems tend to become more open, the developers need to isolate the proprietary software and open source software [10]. The embedded hypervisor provides isolation between the open source software and proprietary software to coexist in the same system.
2. By running the operating system in a virtual machine, access to the rest of the system is minimal thereby increasing the security in an open system. 3. In multi-core systems, the developer can use the hypervisor to dynamically allocate resources to an application domain. This leads to less power consumption. Also, a hypervisor can be used to set up the redundant domains for fault tolerance or hot fail over configuration [6].
Figure 1.1: Use case for Virtualization in Embedded systems
The two figures explains the use of virtualization in embedded systems. The first figure [6], 1.1 explains the main use case for virtualization in embedded
Figure 1.2: Standard security use case
systems where two distinct operating systems coexist in a single system. In the second figure [6], 1.2, a standard security use case where an operating system encapsulated in a virtual machine provides protection to the rest of the system.
1.4
Hypervisors
A virtual machine runs on top of a software layer and that software is called a hypervisor or Virtual Machine Monitor. The purpose of a VMM is to map the virtual resources to the physical resources and therefore it is the heart of virtual machine technology [12].
Figure 1.3: General Hypervisor
A hypervisor provides an abstraction layer which separates the virtual ma-chines from real hardware along with isolating virtual mama-chines from each other so that guest OS do not interact with the hardware directly, thereby isolat-ing the memory. Since VMMs do not need extra hardware support and offer increased hardware and system management flexibility, hypervisors are
ing more popular. Xen and VMWare ESX are examples of popular hypervisors. Both hypervisors achieve complete virtualization of the system through different means, Xen uses paravirtualization and VMWare ESX uses binary translation.
Hypercalls are functions which are used by modified guest operating systems to communicate with the hypervsior [11]. When a hypercall is issued, the system control is transferred to a more privileged state and highly privileged operations like updating page tables can take place. The hypercall in a hypervisor is similar to system call in an operating system.
1.4.1
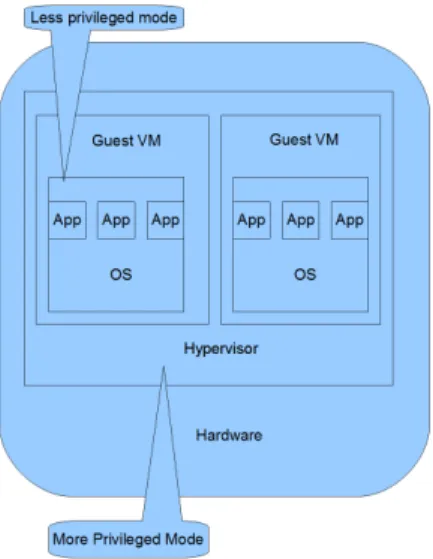
The SICS Hypervisor
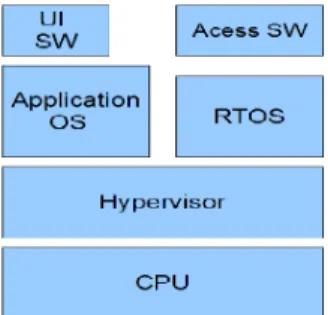
Figure 1.4: SICS Hypervisor [2]
Heradon Douglas developed the SICS hypervisor software. The ARM pro-cessor ARM926EJ-S was chosen as the target and it supports Linux Kernel as a single guest OS. The interesting feature about the SICS hypervisor is that, it is a type 1 hypervisor, developed on ARM. The popular hypervisors are yet to be ported on ARM platform. The OVP (Open Virtualization Platform) tools are used to simulate and develop the hardware and peripherals needed for the hypervisor.
1.5
Problem Definition
The aim of this thesis as outlined before is to investigate the modifications needed to port a Linux kernel running on the ARM processor to a hypervisor.
1.6
Thesis Organization
The thesis is organized into 6 chapters. The first chapter is aboutIntroduction, which will have general information about the operating systems, embedded systems, virtualization and embedded systems, hypervisors and the SICS hy-pervisor. The 2nd chapter Background has information about kernels, Linux kernel, types of virtualization, and a brief description about the ARM archi-tecture. In chapter 3, Related Work we describe the Xen hypervisor and the para-virtualization using Xen. Also, the OpenBSD porting on Fiasco and freeR-TOS porting on the SICS hypervsior are discussed. The differences between the normal freeRTOS kernel and the changes made to it so that it can be ported to a hypervisor are also included.
Chapter 4 OVP Installtion and Setup describes the tools needed to modify, re-compile and simulate the system. In chapter5 Kernel Modifications we dis-cuss the porting of the Linux kernel. It includes the identification of the Linux kernel to be modified and two major modifications needed to port the identified Linux kernel on to the hypervisor are explained. The last chapter6,Conclusion and Future Work has the conclusion of the thesis and possible future work re-lated to this is discussed. The literature work done by others rere-lated to this thesis is also included.
Chapter 2
Background
This background chapter has all the needed information about kernels, general Linux kernel, system calls in Linux, handling interrupts in Linux and managing memory in Linux. Also, ARM architecture and its features are explained.
2.1
Kernels
A kernel is the main component of an operating system, immediately above the hardware architecture level and generally considered as the lowest level of soft-ware. The most basic operations performed by an operating system is resource management and resource sharing are taken care of by the kernel [8]. Also, the kernel provides the abstractions for the processes running in the user mode. This abstraction is necessary since the processes running in the user mode require access to the hardware resource but cannot access them directly. To achieve protection between the processes, we can divide the OS into two parts [19], the
kernel space and theuser space.
There are two types of kernel architectures available. One is the monolithic kernel and the second one is the micro-kernel. A monolithic kernel architecture has all the code to get executed in the kernel space. All the needed device drivers, protocols, IPC modules are included in that kernel. In a micro-kernel, only the code needed to run an operating system gets executed in the kernel space. The device drivers, file systems, protocol stacks run in user space. Both monolithic kernels and micro kernels have their own advantages and disadvan-tages. When the monolithic kernel crashes, then the entire system crashes. Also, monolithic kernel has a typically larger memory footprint when compared with a micro kernel. On the other hand, performance has been a major challenge for micro-kernels.
2.2
Linux Kernel
Developed by Linus Torvalds, the Linux kernel is a member of family of Unix like operating systems. Linux is an open source operating system and its source code is available under the GNU General Public License (GPL).
2.2.1
Linux System Call
A system call can be defined as a request sent by the programs to the operating system to access services that are strictly controlled by the kernel. Some exam-ples of popular system calls areopen, read, write, close, exit, fork, kill,
wait etc. There are around 300 system calls in the Linux operating system. The following steps describes how to create and add Linux system calls in the Linux OS.
1. The system call table is found in the file /arch/arm/kernel/calls.S. The programmer adds his own system call at the end of the file in the following format.long SYS_CALL_NAME
2. Then the system call is declared in the file unistd.h present in the folder /arch/arm/include/asm/unistd.h. Increment the existing sys-tem call number by 1. The new syssys-tem call declaration looks like this
#define __NR_SYS_CALL_NAME XXX
3. Define the system call function in C language and store the .c file in the folder/usr/src/Linux-x.x.x/Kernel
4. Declare the system call in the file /include/linux/syscalls.h so that the system call gets linked with the ASM table in the file calls.h The linkage is done throughasmlinkage long CALL_NAME(parameters)
5. Now create a makefile in the folder where the system call is defined. The make file must contain the path to the system call definition file
core-y += /kernel /.../... /syscall.
6. Finally the object file of the system call definition is added to the make file. obj-y := mysyscall.o
2.2.2
Linux Interrupt Handling
In the Linux operating system, interrupts are handled in a similar way to the signals in the user space. In simple words, the device’s interrupt handler is reg-istered and are invoked when an interrupt is generated. If the software handler is not registered in the Linux kernel, then the interrupt is simply ignored. A registry is available in the Linux kernel which keeps the interrupt lines some-thing analogous to the I/O port registry. When an interrupt channel is needed by a module, the particular module requests an interrupt channel or IRQ and the same module has to release it after finished using the interrupt channel. The library file<linux/interrupt.h>contains the necessary functions needed to implement interrupt registration [1].
2.2.3
Linux Memory Management
Like any other operating system, Linux also provides memory related services like virtual memory, shared memory and protection to the applications run-ning on it. These services [5] are built on a programming foundation includ-ing a peripheral device called MMU. The purpose of a MMU is to trans-late the physical address into linear address and when a CPU tries to ac-cess the memory region illegally the MMU requests for a page fault interrupt.
Linux’spte_*(), flush_tlb_*() and update_mmu_cache()functions are the kernel’s Memory Management Unit API. These functions connect Linux’s hardware-generic memory management service algorithms to the host processor’s Memory Management Unit hardware. They are sufficiently abstract, however, in that they depend completely on the MMU API. A thorough understanding of this API is therefore essential to successful use of Linux in an embedded setting.
2.3
Virtualization and Virtual Machines
We can define virtualization as the creation of a virtual version of resources, like memory or operating systems or servers or network resources [21]. In this thesis we deal with a certain type of virtualization called para-virtualization where one can create many virtual systems inside a single physical system. System virtu-alization is achieved by running an additional layer called hypervisor, between the hardware and the virtualized systems. This hypervisor manages in sharing of all hardware resources of the hardware between the guests. A virtual machine can be defined as a software implementation of a computer which functions like a real physical machine.
Some privileged instructions have one result when executed in privileged mode and a different result when executed in non-privileged mode. Those instruc-tions are calledprivilege-sensitive instructions. An Instruction Set Architecture (ISA) can be called classically virtualizable provided if it does not contain the
privilege-sensitive instructions.
2.3.1
Binary Translation
The Intel x86 architecture has privilege-sensitive instructions making full vir-tualization impossible. So, to achieve virvir-tualization in Intel x86 architecture, VMware employed Binary translation.
2.3.2
Para-Virtualization
A guest OS is modified and recompiled prior to installation inside a virtual machine. The guest OS is modified in such a way that the instructions which are non virtualizable are replaced by hypercalls. The hypercalls communicate directly with the virtualization layer hypervisor [24]. This virtualization tech-nology is called Para-Virtualization, and provides an interface to the virtual machine that can differ slightly from that of the underlying hardware [20]. One important advantage of para-virtualization over binary translation is that it typ-ically has lower performance overhead. The guest operating systems run with a fully paravirtualized disk and network interfaces, timers, interrupts, access to page table[4].
2.3.3
Hardware Virtualization
In hardware virtualization, a hypervisor is used to abstract the physical hard-ware layer [7]. A good example is the AMD-V and Intel virtualization technology
processor where the hardware is custom made to support the external virtual-ization software. Virtualizing the hardware enables the use of more than one operating system on the same hardware [13].
2.4
ARM Architecture
2.4.1
ARM Introduction
As mentioned earlier, the hypervisor developed by SICS is implemented on top of the ARM926EJ-S CPU. The contemporary CPUs available in the market can be classified as either RISC or CISC CPUs. Many 32-bit embedded systems are built on an ARM CPU, which is a RISC (Reduced Instruction Set Computer). The important attributes exhibited by a RISC CPU are:
1. A large uniform register file.
2. Load/Store architecture, which implies that the operations executed op-erate only on the contents of the register and not on the memory contents. 3. Simple addressing mode.
4. For simplifying the instruction decode, uniform and fixed length instruc-tion fields are provided.
The instructions for CISC are more complex, variable in size and need more execution cycles. This is due to the fact that CISC machines are dependent on the hardware for the instruction functionality. The ability to achieve target code density and low power consumption has made the ARM processor to be present in almost all the embedded devices manufactured.
2.4.2
ARM Processor modes
There are 7 processor modes supported by the ARM CPU. They are: 1. User modeThe normal execution mode for user programs
2. Fast Interrupt (FIQ)This mode supports high speed interrupts. 3. Interrupt request (IRQ)This mode handles the general interrupts 4. Supervisor modeThe mode in which the OS operates normally and also
the mode when the power is applied to the system
5. Abort modeThe mode is needed for implementing virtual memory 6. UndefinedSupports software emulation of hardware co-processors 7. SystemThis mode runs the OS tasks
Other than the user mode all the other modes are privileged modes. The dif-ference between a privileged mode and non privileged mode is that a privileged mode has both read and write control over the CPSR whereas a non privileged mode has only read control over the CPSR.
2.4.3
ARM Registers
There are 31 registers available on an ARM core where only 16 registers (r0-r15) are visible at a particular point of time. Among the 16 registers available, the last 3 registers, r13-r15 are assigned with special functions.
Stack Pointer : The register r13 is used as the stack pointer, where the head of the stack is stored in current processor mode.
Link Register: The register r14 is used as the Link register. Whenever a subroutine is called the CPU stores the return address in LR.
Program Counter: The register r15 is used as the Program Counter. The address of the next instruction to be fetched is stored here.
2.4.4
CPSR
The current program status register is a 32-bit register apart from the 16 general purpose registers, which is used to monitor and control the internal operations of the ARM CPU. As seen in the figure below [17], the CPSR has 4 sub-fields each 8 bits wide.
The first 8 bits represent the control field and contain the details about the processor modes, thumb state and the interrupt masks. The next 16 bits rep-resent an extension and status fields and they are reserved for future use. The last 8 bits are the flag fields where the last 4 bits represent the conditional flags where the results of the arithmetic operations are stored.
Figure 2.1: CPSR
2.4.5
Interrupt Handling in ARM
In this section we will discuss the exception handling mechanism in the ARM processor. Whenever the system is interrupted, the CPU suspends temporarily the execution and starts executing the interrupt service routine (ISR). This ISR is stored in the exception vector table which in turn is saved at a specific memory
address. The entries in the vector table usually contain a branch instruction which points to the start of a routine.
1. Reset Vector: This contains the location of the instruction executed first when power is applied to the processor. This will branch into the initialization code.
2. Undefined Instruction Vector: If the processor cannot decode an instruction then this vector table entry is used.
3. Software Interrupt Vector: Whenever there is a software interrupt, this vector table entry is used.
4. Prefetch Abort Vector: If the CPU violates the access rights by trying to access an instruction from an address by violating the access rights then this vector table entry is used.
5. Data Abort Vector: If an instruction attempts to access the data mem-ory without the right access permissions, data abort vector is used. 6. Interrupt request Vector: If an external hardware interrupts the CPU
then this vector is used. It also requires the unmasking of IRQs in the CPSR
7. Fast Interrupt request Vector: It is similar to the interrupt request and reserved for hardware requiring faster response times. It can only be raised if FIQs are not masked in the CPSR
Table 2.1: Vector Table
Exception/Interrupt Shorthand Address High Address Reset RESET 0x00000000 0xffff0000 Undefined instruction UNDEF 0x00000004 0xffff0004 Software interrupt SWI 0x00000008 0xffff0008 Prefetch abort PABT 0x0000000c 0xffff000c Data abort DABT 0x00000010 0xffff0010 Reserved – 0x00000014 0xffff0014 Interrupt Request IRQ 0x00000018 0xffff0018 Fast Interrupt request FIQ 0x0000001c 0xffff001c
2.4.6
ARM Coprocessor
The aim of adding coprocessors to a CPU core is to provide an extension to the already existing instruction set of the CPU. Data transfer, memory transfer instructions, register transfer instructions are included in the coprocessor in-structions. Up to 16 coprocessors can be added to the ARM CPU, where the 15th coprocessor is dedicated for the control functions. The control functions include cache control, MMU and the TLB. It is important to know the func-tioning of the MMU in ARM which will provide a clear picture of the security services provided by the hypervisor.
2.4.7
MMU
The MMU is a hardware feature of the ARM co-processor which needs to be handled in order to achieve virtualization. The MMU converts the virtual ad-dresses provided by a compiler or linker into the physical adad-dresses where the actual program is stored. As a result programs executes using the same virtual addresses but using different physical addresses. If the MMU is disabled then all the virtual addresses will be mapped one to one to the physical addresses. The MMU generates an abort exceptionwhen there is a translation failure, permission or domain faults.
As mentioned earlier, the virtual addresses must be translated before access-ing the memory. If the program tries to map the virtual address to physical address individually, the entire process will be a cumbersome one. For making the translations easier, the MMU will divide the physical memory into contigu-ous sections called pages. The page table is the one which stores the virtual address to physical address mapping and access permissions to the memory pages.
2.4.8
Page Tables
The MMU in the ARM CPU has two levels of page tables namelyLevel 1L1 and
Level 2 L2. The L1 is also known as the master page table. It contains 4096 page table entries, where each table entry describes 1MB of virtual memory, thereby enabling up to 4GB of virtual memory. The L1 table also acts as a page directory of L2 page tables and a page table which translates the 1 MB virtual pages into sections. There are 256 entries in L2 page table and each entry describes 1KB of main memory. Each page table entry in the L2 page table translates a 4KB block of virtual memory to a 4KB of physical memory. The page table entry in L2 page table contains the base address to a 4 or 64KB page frame. The following table [17] summarizes the characteristics of the page tables used in ARM MMU:
Table 2.2: ARM Page tables
Name Type Memory Page Sizes Number of Consumed(KB) supported(KB) Pagetable entries Master/Section level 1 16 1024 4096
Fine level 2 4 1,4 or 64 1024
Coarse level 2 1 4 or 64 256
2.4.9
TLB
A special kind of cache called Translation Lookaside Buffer (TLB) is used to store the recently used page translations. It has two functions, one is to map the virtual page to an active page frame and the second is to store the control data managing access to the memory pages. Only two types of commands are supported by the TLB in the ARM processor. The programmer can either flush it or lock the translations that reside in it. Whenever a program tries to access
the memory, the MMU looks up the virtual page address values stored in the cache. If the lookup is successful then the TLB provides the translation of the physical address and this is called as TLB hit. If the valid translation is not present in the TLB then it is defined asTLB miss. On a TLB miss, the page table provides the translation of the virtual to the physical address and this new translation is stored in the TLB. The register to be replaced is selected by the TLB in the ARM processor using the round robin algorithm.
List of Abbreviations
Chapter 3
Related Work
3.1
Hypervisors
A number of hypervisors are implemented and available on the market. In this chapter, we describe Xen which is widely used and serves as a good introduction to para-virtualization.
3.1.1
Xen Hypervisor
The Xen hypervisor, a free hypervisor licensed under the GNU general public license was originally developed at Cambridge University. It can support the processors like x86, x86-64, Itanium, PowerPC, and ARM processor and OS like Linux, NetBSD, FreeBSD, Solaris, Windows as guest operating systems running on it.
Xen Architecture
The following are the vital components of the Xen environment [25]. 1. Xen Hypervisor
2. Domain 0 guest
3. Domain U Guest (Dom U)
The Xen hypervisor, situated between the hardware and the operating sys-tems, is responsible for CPU scheduling and memory partitioning of the various virtual machines running on the CPU. Domain 0 [25] is a modified Linux kernel. It is a unique virtual machine running on the Xen hypervisor with special rights to access physical I/O resources and it can also interact with the other virtual machines. Running Domain 0 is a mandatory requirement by all Xen virtual-ization environments so that other virtual machines can be started for running. The Domain U is an unprivileged and has two subtypes. TheDomain U PV Guests denotes all the para-virtualized virtual machines like modified Linux OS, Solaris, FreeBSD etc., running on the Xen hypervsior. The Domain U HVM Guestsdenote all the fully virtualized virtual machines like Windows OS. When hardware support is provided, a Domain U PV Guest differs from a Domain U HVM Guest, since it has been modified so that it does not access directly the hardware.
Para-Virtualization with Xen
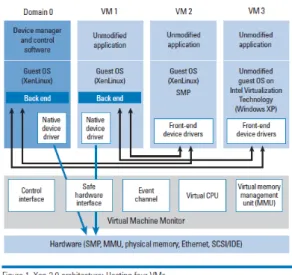
The concept of para-virtualization is already explained in the section 1.1.1. For understanding more about the para-virtualization with Xen hypervisor, we will discuss the Xen architecture 3.0. In the figure, we can see the Xen 3.0 hosting four VMs, including the Xen hypervisor. The control interface of the VMM can be accessed only by Domain O and through Domain O, creating and managing other VMs are possible. The Domain O also runs the management and control software. The VM1 and VM2 contains the modified guest OS so that they can run above Xen and the Xen-aware device drivers.
Figure 3.1: Xen Architecture
The Intel architecture provides 4 levels of privilege modes or rings numbered from 0 to 3. The mode 0 is the most privileged mode where the OS is getting executed in a non-virtualized system. The applications get executed at mode 3 while the other 2 modes are not used. The hypervisor gets executed at mode 0, the guest OS at mode 1 and the applications at mode 3 in the Xen para-virtualization so that the VMM executes in the highest privileged mode, the guest OS executes in a higher privileged mode than the applications and is iso-lated from the applications. In Xen para-virtualization, the guest OS is modified so that it can access memory in a non-contiguous way. Even though the guest OS is responsible for allocating and managing the page tables, the Xen VMM intercepts and validates the direct writes. Non open source operating systems like Windows OS are not supported in a para-virtualization environment. Next we will discuss how para virtualization is achieved in Xen hypervisor.
Xen Memory Management
The most difficult part in para virtulaization is the memory virtualization. With the absence of software-managed TLB in x86 architecture, the processor itself services the TLB misses. With these limitations, the Xen makes sure that the guest operating system is responsible for the hardware page table allocation and management and also the Xen should occupy the top 64MB of the address space. The latter design requirement [18] is done to avoid flushing the TLB
while entering and leaving the hypervisor. But since we are dealing with the ARM CPU, this memory virtualization is easier with the help of the software managed TLB provided by the ARM architecture. The reason behind this is software-managed TLB instructions are explicit and can be translated explicitly.
CPU Virtualization
Only two privileged levels are provided by most processor architectures, which creates a system where the modified guest operating system runs in the non privileged level. In ARM architecture, there are two processor modes which are analogous to the privileged levels of the x86 CPU. They are a supervisor mode with high priority and user mode with lesser priority. The x86 architec-ture virtualizes exceptions including the memory faults and software traps in a straightforward manner. For each type of exception, a table describing the handler is registered with the Xen. Though the exception stack frames are left unmodified [18] in the para virtualized system, the page fault handler has to be modified.
The system call performance is increased by allowing each guest operating sys-tem to register for a fast exception handler. The processor can access this fast exception handler without indirecting via ring 0. This same technique cannot be applied to the page fault handler because the faulting address from the reg-ister CR2 can only be read by the code executed inring 0. By validating the exception handlers when they are presented to the Xen hypervisor, the system safety can be achieved.
3.2
Related porting work done
3.2.1
OpenBSD is ported on Fiasco
In this section we describe the modifications [15] done to run OpenBSD on top of Fiasco. In his thesis work, Christian Ludwig has described the methods to re-host the open BSD on the Fiasco micro-kernel. This fiasco is a L4 family of micro-kernels. The L4 micro-kernel, proposed by Jochen Liedkte has the memory management unified with the IPC semantics which enabled user level memory management. Fiasco.OCand OKL4 from open kernel labs are exam-ples of various implementations of the L4 micro-kernel.
One modification [15] made to OpenBSD was changing the memory configura-tion for porting it.uvm(9)is the machine independent memory manager which knows about the high level information. The machine dependent memory man-ager is called pmap and it has to be implemented in the architecture code of the OpenBSD kernel. The topmost gigabyte of every task is occupied by the Fiasco micro-kernel which implies that the re-hosted OpenBSD kernel has to be implemented as an user space application. The kernel has to be re-linked to an address below the Fiasco kernel memory space. Since the user space and kernel space will be separated in the re-hosted system, the OpenBSD kernel will act as a L4 server by servicing OpenBSD applications separately.
The second modification [15] was changing the page tables on OpenBSD for
re-hosting it. Since the page tables cannot be directly reloaded on the MMU, the server has to maintain mappings of the page table and whenever there is a change on the page tables, inform the Fiasco to carry out the context switch.
3.3
freeRTOS porting to ARM based
Hypervi-sor
In his thesis [3], Heradon Douglas explains the freeRTOS porting done on ARM based hypervisor. For porting freeRTOS, three primary kernel source files were identified. Additional platform dependent code was also needed to port them on ARM platform. The additional code contains[3],
1. To set up the hardware, timer interrupt, establishing stacks in the memory, registering the kernel’s timer tick handler, populating exception vectors we need low level boot and initialization code.
2. For saving and restoring the CPU context, enabling and disabling the interrupts we need Assembler code.
3. Interrupt service routines for handling the interrupts
4. For allocating stack space to tasks, memory management code is needed There were several issues identified and addressed while porting the freeR-TOS kernel to the ARM based hypervisor. These issues are explained here.
3.3.1
Interposition
As mentioned earlier, the hypervisor is designed to run in the privileged mode while the modified guest OS and its tasks run in user mode. The designer has to make sure that interposition between the hardware and freeRTOS is achieved by the hypervisor. The hypervisor also virtualizes the privileged operations required by the kernel and the tasks. For enabling or disabling the interrupts [3], the platform dependent code is implemented though a hyper call.
3.3.2
Memory Protection
The freeRTOS kernel is designed such that each task runs in a privileged mode and the stack of the task gets a dynamically allocated block of memory. This block of memory is allocated from the heap which is maintained by the kernel. That way, no virtual memory address space is allocated by the kernel for its tasks. Also, the tasks can access any memory in the system since there is no inbuilt memory protection. From this the system designer can come to three conclusions[3]:
1. Since there is no table to shadow, the hypervisor does not need to support any shadow page tables.
2. As there is no inbuilt memory protection, the hypervisor can be designed to provide memory protection.
3. If the hypervisor is located in the 32-bit address space as the kernel, then TLB flushing is not needed as part of the context switch.
The memory space can be partitioned using the ARMv5 MMU, into domH, domK and domA. The domA contains the task memory and the domH is a client domain which is only accessible in privileged mode. The unmodified freeRTOS kernel contains the kernel and tasks running at the same privilege level and are implemented as library calls. Now, the hypervisor should be designed such that these tasks should not tamper the kernel memory. This problem is addressed by using the wrapper mechanism by few ports of freeRTOS to systems with a Memory Protection Unit. When the wrapper mechanism is used, the tasks cannot access the kernel directly and need to use a controlled wrapper function to call the desired kernel function.
The next issue addressed in order to port the freeRTOS kernel onto the hy-pervisor is task protection. By separating the stack memory the tasks can be protected from one another. To achieve this, the memory allocation code has to be modified so that memory from different spaces are allocated to different tasks. So, when a particular task gets executed, only that task’s domain for the stack will be enabled while disabling the other stack domains.
Chapter 4
OVP Installation and Setup
4.1
Introduction to OVP
OVP stands for Open Virtualization Platforms. It is an initiative, which aims at making embedded software development easier on virtual platforms. This initiative is made possible by the company called Imperas, which provides all the needed infrastructure like free open source models, API documentation and a simulator for the virtual platforms. OVP is selected because of its features like flexibility, powerful, ability to simulate custom hardware, efficient development and testing. The source code of much of the simulated hardware is available from the OVP website which makes it more helpful in simulating an ARM based system.
4.2
OVP Tools
In this chapter we will discuss the OVP tools needed, their installation and necessary configuration. First of all, the entire tools required were installed in a Ubuntu OS running under an Oracle Virtualbox with Windows OS as the host. Then the executable OVPsim.20111125.2.sfx is downloaded from the OVP website and installed from the command prompt using the com-mand./OVPsim.20111125.2.sfx. We need to create a separate directory titled
Imperas.20111125where the software is installed. Then the following executa-bles,OVPpse.toolchain.20111125.2.sfx and
OVPsim_demo_linux_ArmIntegratorCP_arm_Cortex-A9UP.20111125.2.sfxare
downloaded and they are installed from the command prompt into the same di-rectoryImperas.20111125.
4.2.1
ARM Integrator/CP
The purpose of ARM Integrator/CP is to provide a flexible environment for developing ARM based devices. With this board, one can model a product and allows hardware and software development. The baseboard is divided into two parts [14]:
1. First is the baseboard providing the interface clocks, power, boot and memory interfaces
2. Second is the core module providing the ARM core, SDRAM, SSRAM, memory and core clocks, and an FPGA that implements peripheral de-vices.
The purpose of installing the ARM Integrator/CP is to boot the Linux kernel ported on the ARM processor and see the modifications made to the kernel for porting it.
4.2.2
Sourcery G++ Lite for ARM EABI
The Sourcery G++ Lite is CodeSourcery’s customized and validated version of the GNU tool chain useful for building ARM based applications. C/C++ compilers, assemblers, linkers, and libraries and anything else required for the development of the application is included in the tool chain.
It provides the following features for programmers:
1. Running/Debugging the program in a simulator: Without the target hard-ware, one can run/debug the program written using the instruction set simulator provided by Sourcery G++.
2. Debug Sprite to debug a program on the target: When the target hardware is present one can load and execute the code written from the debugger, which is named as Debug Sprite.
3. Using a third party device to debug the program on the target: Third party debugging device can be used to debug programs on the remote target. The communication between the remote target and the third party debugging device takes place through the GDB remote serial protocol.
4.3
Server-Client Setup
For installing the OVP tools and running them in Ubuntu, we need to have a license file which supports the server-client relationship between the host OS and Ubuntu OS. Since Windows OS is the host it will be the server and the client will be the Ubuntu. The license file is placed in the server and the client is connected to the server by running MSYS on the server. The MSYS stands for Minimal System, which consists of GNU utilities like bash, grep etc needed for building the programs which are dependent on UNIX tools. Once the msys terminal is displayed, we can navigate to theIMPERAS_ARCH folder and run the commandlmgrd.exe -c /c/Imperas/OVPsim_float.lic -z. Now the server is up and running and available to the client’s access.
From the Ubuntu terminal, we have to execute the following commands:
source /home/master/OVP/Imperas.20111125/bin/setup.sh
setupImperas /home/master/OVP/Imperas.20111125/ which will set up the Imperas environment variables.
Next is the important step for binding the server and client. For this we must be aware of the IP address of the server and run the following command in the Ubuntu terminal, export IMPERASD_LICENSE_FILE=Port ID@IP Address
which will bind the server and the client.
Chapter 5
Kernel Modifications
5.1
SICS Hypervisor
Heradon Douglas [3] developed the SICS hypervisor in the year 2010 and the hypervisor was designed to run on the ARM926EJ-S CPU. Also, the freeRTOS kernel was modified and ported on the hypervisor. The final system had three parts:
1. The core modified kernel
2. The code needed by the core kernel 3. The Hypervisor
To carry out the critical and low level tasks, the platform dependent code is needed by the kernel. Note that after modification, the kernel will be running in the less privileged level and hypervisor will be running in the most privileged level. This means, all the privileged instructions were replaced by hypercalls and the platform dependent code of the guest OS is para-virtualized.
5.1.1
The Hypervisor
As mentioned earlier, the SICS hypervisor was developed for a particular ARM platform. Hence, it contains boot code, exception handlers, and to allow the safe implementation of critical platform dependant functionality it has the hypercall interface. By having several virtual guest modes, multiple execution environ-ments are possible and these multiple environenviron-ments are supported by the SICS hypervisor. The hypervisor uses the MMU to provide the memory isolation between the different operating systems and its safety critical applications.
5.1.2
Hypervisor Modes
The number of guest modes supported by the hypervisor is arbitrary. Also, each guest mode has its own memory configuration and execution context with the hypervisor controlling the guest mode under execution. The SICS hypervisor supports 4 guest modes at present:
1. Kernel Mode for executing the kernel code
2. Task Mode for executing the application code 3. Trusted Mode for executing trusted code 4. Interrupt Mode for executing interrupt code
The ARMv7 architecture comes with new virtualization extensions and these guest modes are no more necessary. The ARMv7 architecture provides a new execution mode which has more priority than the supervisor mode. So, the hypervisor can execute in the new mode and the guest OS can execute with its default privileges. This also removes the necessity for para-virtualization thus simplifying the design.
By having a linker script file, the designer can control the location of hyper-visor, kernel, task and trusted code in the memory. The hypervisor domain is only accessible in privileged mode and this domain contains the hypervisor and the critical devices. The hardware is set and the MMU is configured by the hy-pervisor when the system is booted. Initially the kernel applications run in the user mode and when a hypercall is issued or hardware exception is encountered transition to the privileged mode takes place. This results in making sure that only the hypervisor can modify the memory configurations of the MMU.
The kernel contains the kernel code and the data required by the kernel code. After modifying the guest OS, the kernel APIs are wrapped around the collection of wrapper functions, enter transition hypercall and exit transition hypercall to protect the kernel from task applications. Those two transitions cause the guest OS mode to change from user mode to kernel mode, thereby providing a se-cure interface to use the kernel functions. When an exit transition hypercall is issued, the mode changes from privileged mode to the user mode. For the security critical applications, a separate domain completely isolated from all the other domains is allotted. Remote Procedure Call (RPC) is the secure and well defined interface provided to access all these secure services.
5.1.3
Hypercall Interface
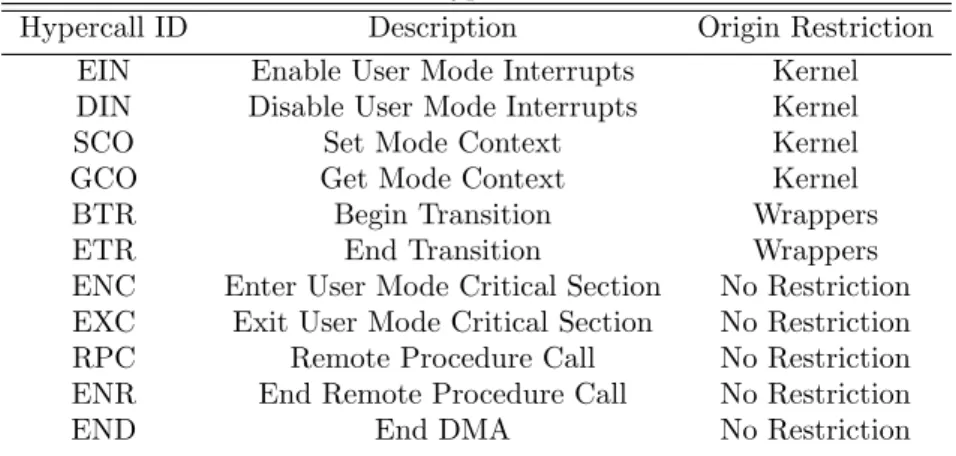
Totally 11 hypercalls given the table 5.1 are provided by the hypervisor and these hypercalls are used to access the privilege functions safely [2]. The term
Origin Restriction refers to where the origin of the hypercall is restricted by the hypervisor. The last 5 hypercalls can be issued by the tasks itself and hence they require no origin restriction.
As the name suggests, the EIN and DIN hypercalls are used to enable and disable the interrupt. To save and restore the execution context, SCO and GCO hypercalls are used. To change from guest mode to kernel mode and change back to guest mode, Begin and End transition hypercall is used by the kernel wrapper functions. To ensure that a particular task is the only task with exclusive rights to the shared resource in the critical section. When the particular task enters the critical section, interrupts will be disabled by those hypercalls and enable the interrupts at exit. When there are multiple guest modes, the RPC is used to achieve communication between those different guest modes. Starting the kernel scheduler or task yielding are the possible operations that can be made with the
Table 5.1: Hypercall Interface
Hypercall ID Description Origin Restriction EIN Enable User Mode Interrupts Kernel DIN Disable User Mode Interrupts Kernel SCO Set Mode Context Kernel
GCO Get Mode Context Kernel
BTR Begin Transition Wrappers
ETR End Transition Wrappers
ENC Enter User Mode Critical Section No Restriction EXC Exit User Mode Critical Section No Restriction RPC Remote Procedure Call No Restriction ENR End Remote Procedure Call No Restriction
END End DMA No Restriction
RPC. A DMA interrupt is generated to call the designated guest handler when the DMA transfer is finished and tell the guest handler that the DMA transfer is done. The END hypercall is used by that handler to yield the control back to the hypervisor.
5.1.4
DMA Virtualization
Direct Memory access (DMA) is a technique uses a special hardware to copy data much faster and free CPU to do other tasks at the same time. All the DMA functions are controlled by a device called DMA controller. The DMAC being an independent hardware does not follow the memory configurations of the MMU leading to compromise on security. Though Input Output Mem-ory Management Unit (IOMMU) can be used to solve the above problem, the IOMMU is not available on all CPU architectures. So, we need a different technique to protect the DMA. Oliver Schwarz [22] has implemented a DMA protection mechanism purely based on software and MMU protection function-ality. The DMA controller is emulated so that the guests do not interact with the physical controller directly. So, whenever there is an attempt to access the physical controller, the control flow will be trapped into the hypervisor and the hypervisor will control and check the access permission based on the predefined access policy. After finishing the DMA transfer, the interrupt is forwarded by the hypervisor to the respective guest.
5.2
Linux Kernel
Having discussed about setting up the development environment, we will now discuss the Linux Kernel to be ported onto the hypervisor. All modifications are based on the Linux kernel version 2.6.34.3. The demo installation package, contains an OVP virtual platform version of an ARM IntegratorCP platform, which uses the ARM Cortex-A9UP model. This makes the kernel porting onto the hypervisor an easier one. Two key modifications, Interrupt Vector Table (IVT) and Memory Management Unit (MMU) are described in the following sections.
5.3
IVT and modification
As discussed already, there are 7 types of exceptions/interrupts, each one can trigger transition from one mode to the other. We know that the guest operating systems interacts with the hypervisor by issuing hypercalls which are in turn treated as SWI (Software Interrupts) by the ARM CPU. So, we must modify the interrupt vector table so that whenever a SWI is encountered, the CPU branches to the address where the Interrupt Service Routine (ISR) for the SWI is stored. When an interrupt occurs the programmer takes the following actions:
1. Copy the CPSR to the supervisor mode SPSR,SPSR_SVC.
2. The CPSR mode bits are set so that it causes the mode change to super-visor mode
3. The IRQs are disabled by setting the IRQ bit. But still FIQs will be accepted since the FIQ bit is not set.
4. The link register should be made to point to the next instruction to be executed. This is done by saving the value PC-4 into the Link Register in the Supervisor mode
5. Now the PC is stored with the address 0x8, which is the address of the SWI handler
Also, to implement an interrupt service routine:
1. Interrupt Vector Table (IVT) of the Linux Kernel is identified in the file
entry-armv.S
2. The ISR is written in C language and stored in a separate file.
3. The IVT is modified so that the CPU branches to the address of the ISR whenever there is a SWI
Now the following steps are followed to return from the SWI handler after executing it:
1. The SPSR_SVC is copied back into the CPSR which restores the system before the SWI was encountered.
2. The value stored in the LR_SVC(Link Register in the Supervisor mode) is moved back to the PC
The instruction MOVS pc, lr can accomplish the above mentioned return ac-tion in a single instrucac-tion. In the privileged mode, theMOVSinstruction copies the SPSR to CPSR provided, the return address is stored in the register r14 and the destination register is the PC. The programmer must also ensure that, when a SWI calls another SWI ie nested handlers, then the Link Register(LR) and SPSR must be stacked before branching to the nested SWI. This should be done to avoid corruption of the LR and SPSR values.
The IVT consist of the ARM instructions which can manipulate the PC to jump to a specific address to handle an interrupt or exception. The IVT starts at the address0x00000000and the SWI handler is stored in the address0x00000008. Now after writing the SWI handler, we must modify the IVT accordingly so that when the SWI is encountered, the corresponding handler is called.
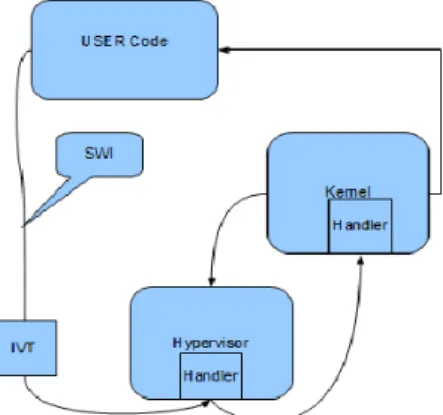
Figure 5.1: IVT Modification
5.3.1
Program flow
One can describe a SWI(Software Interrupt) as a synchronous interrupt instruc-tion which is defined by the user. The aim of this SWI is that, a program running in user mode(unprivileged mode) can request privileged operations, which need to be run in the supervisor mode. Therefore, whenever this instruction is exe-cuted, the processor switches into supervisor mode and branch to the relevant exception vector address(0x00000008) and execute the corresponding handler stored at that address.
SWI
The figure 5.1 shows a sample implementation of a user program receiving a SWI and how the branching takes place. The user applications, initially will be running in the user mode until a SWI is encountered. So, the SWI instruction causing the software interrupt will make the CPU to store the present state of the system into the registers and will look at the IVT(Interrupt Vector Table) to branch to the address0x00000008. The address will have the SWI handler of the hypervisor, which will service the SWI received. The handler will receive the interrupt and send the interrupt to the interrupt handler of the kernel. The interrupt handler of the kernel will now receive the interrupt and then the user program which requested the CPU will run in the supervisor mode.
After the program execution, now the system should be restored back so that the program executed before the interrupt occurrence will continue. This sys-tem is restored by either the handler code in the hypervisor or the handler code in the kernel based on our implementation. If the program flow to returns back from an interrupt via the hypervisor then the handler code in the hypervisor has to restore the system by modifying the contents of the corresponding registers.
Otherwise, if the program flow returns back from an interrupt from the kernel, then the handler code in the kernel is responsible for restoring the system by modifying the corresponding registers.
5.4
Page Tables
The hypervisor is designed to run at the privileged level of the processor. Hence, virtualizing the Memory Management Unit(MMU) and the Input Output Mem-ory Management Unit(IOMMU) of the CPU is the best way to protect them [23]. This CPU based virtualization is better when compared to software based virtualization because it will reduce the code size of the hypervisor and minimal changes are required to port OS kernels to run on the hypervisor. The page tables can be used as the basis of the MMU based memory protections since the page tables are supported by a large number of CPU architectures. We can follow either of the these two ways to protect the page tables.
1. Keeping the page tables in the address space of the hypervisor and allowing the kernel to read and modify it through safe function calls.
2. Virtualizing the physical memory. The result is the addresses sent on the memory bus are different from the physical addresses seen by the kernel [23]. So, the page tables responsible for translating the kernel’s physical addresses to the actual physical addresses seen on the memory bus should be kept in the hypervisor’s address space and should be maintained by the hypervisor. One more important point to note is that the kernel is not aware of the virtualization of the physical memory.
Each method mentioned above has its own advantages and disadvantages. 1. In the first method using the function call interface, the kernel directly
writes in to the page tables. As a result there is no synchronization over-head and this is the faster method. This method will make changes to the kernel’s page table handling code leading to increase in the time required for porting a new kernel to the hypervisor.
2. The second method is secure and allows easy porting of a kernel to the hypervisor. This is slow due to the synchronization overhead.
Since we are particular about security and easy portability, the second method ie to virtualize the physical memory is preferred.
Configuring the shared address space
In any OS, the kernel is the first program that gets executed when the system is booted. So, a part of the kernel memory is made executable by the initialization of the page tables by the hypervisor. The same address space is shared by the user and kernel memories in most of the operating systems and sharing the same address space makes the control flow of the kernel to execute user code with kernel privilege vulnerable to an external modification. The shared address space should be configured in a way that prevents any external modification. The programmer has to take care that the hypervisor modifies the page table so that the user memory is executable when the CPU is in the user mode and not
executable when the CPU is in the kernel mode[23]. Also, all the transitions modifying the user memory execute permissions in the page table, taking place between the user and kernel mode must be intercepted by the hypervisor. The hypervisor sets the execution permissions only for the memory of the mode that is getting executed currently in the page table.
Protecting Write and Execute permissions
Only the approved code is made executable by the hypervisor which sets the execution rights in the page tables. For this, when the processor enters the kernel mode, an instruction pointer is set to an address in the approved code. There are certain entry points through which the processor enters the kernel mode and the information about these entry points are informed by the kernel to the processor. The addresses of those entry points are written into the processor registers and data structures like IVT. Those entry points are virtualized by the hypervisor and only is allowed to operate on them[23]. For virtualizing the entry points, safe function calls are provided by the hypervisor to the kernel through which those entry points are read and modified. This will lead to a situation where, whenever there is an attempt to execute the not approved code in the kernel mode, an exception will be generated by the processor. This exception generated will cause the OS termination by the hypervisor and also the approved code pages in the page table are marked read-only by the hypervisor preventing any external modifications[23]. Also, the programmer has to make sure that the kernel memory pages in the kernel mode are either writable or executable but not both.
Protecting DMA writes
There are situations where writing by a DMA can modify the approved code pages in the page table. To avoid such modifications, the hypervisor must use the DMA write protection functionality of the IOMMU to protect the approved pages in the page table[23]. This DMA write protection along with the read-only protection makes sure that only the hypervisor modifies the memory containing the approved code and no modifications are done by any code running on the CPU.
Chapter 6
Conclusion and Future
Work
6.1
Conclusion
This thesis explains the necessary background details required for porting a Linux Kernel onto the SICS hypervisor. In the first half of the thesis, setting up the OVP tools, ARM IntegratorCP, the development environment are dis-cussed. Compiling and Building the Linux kernel image using the OVP tools are detailed. In the second half of the thesis, adding system calls in the Linux kernel, Linux kernel’s interrupt vector tables are explained. Two major modifi-cations for the Linux kernel for porting it on to the hypervisor are described in the 5th chapter.
Also, when the freeRTOS kernel was ported onto the hypervisor, tests were carried to calculate the performance overhead. Using a thin hypervisor on an embedded platform resulted in a minimum overhead which was acceptable given the security of the system is improved. So, when the Linux OS is ported there will be minimal performance overhead with a more secure system.
6.2
Future Work
The future work may consist of two parts. First is to list out the remaining modifications to be done and the second is to implement those modifications on the kernel. Simulating the kenel using the OVP tools, comparing the results before and after porting to analyze the impact of porting also needed to be done.
Bibliography
[1] Linux Device Drivers. O’REILLY, 2005.
[2] Viktor Do. Security services on an optimized thin hypervisor for embedded systems. Master’s thesis, Lunds Tekniska Hogskola, 2011.
[3] Heradon Douglas. Thin hypervisor-based security architectures for embed-ded platforms. Master’s thesis, The Royal Institute of Technology, Stock-holm, Sweden, 2010.
[4] George Dunlap. The Paravirtualization Spectrum, part 1: The Ends of the Spectrum. http://blog.xen.org/index.php/2012/10/23/
the-paravirtualization-spectrum-part-1-the-ends-of-the-spectrum,
2012. [Online; accessed 02-April-2013].
[5] William Gatliff. The linux kernel?s memory management unit api, 2001. [6] Gernot Heiser. The role of virtualization in embedded systems. In First
Workshop on Isolation and Integration in Embedded Systems, number ACM 978-1-60558-126-2. IIES’08, Open Kernel Labs and NICTA and University of New South Wales Sydney, Australia, 2008.
[7] Bill Hill. Intro to Virtualization: Hardware, Software, Memory, Stor-age, Data and Network Virtualization Defined.http://www.petri.co.il/ intro-to-virtualization.htm#hardware-virtualization, 2012. [On-line; accessed 30-December-2012].
[8] Thom Holwerda. Kernel designs explained. http://www.osnews.com/ files/17537/kernel\_designs\_explained.pdf, March 2007. [Online; accessed 13-April-2013].
[9] Intel Inc. Introduction to embedded systems. http://www.intel.com/ education/highered/Embedded/Syllabus/Embedded\_syllabus.pdf. [10] M. Tim Jones. Virtualization for embedded systems. publisher, 2011. [11] Cuong Hoang H. Le. Protecting xen hypercalls intrusion detection/
pre-vention in a virtualization environment. Master’s thesis, The University of British Columbia, 2009.
[12] John L.Hennessy and David A.Patterson. Computer Architecture A Quan-titative Approach. Morgan Kaufmann, 4th edition edition, 2007.
[13] John Lister. What Is Hardware Virtualization? http://www.wisegeek. com/what-is-hardware-virtualization.htm, 2008-2013. [Online; ac-cessed 13-April-2013].
[14] ARM Ltd. Integrator/CP Compact Platform Baseboard HBI-0086. ARM Ltd, 2002.
[15] Christian Ludwig. Porting openbsd to fiasco. Technical report, 2011. [16] Jelena Mamcenko. Lecture Notes On OPERATING SYSTEMS, chapter 2.
Vilnius Gediminas Technical University, year.
[17] Andrew N.Sloss, Dominic Symes, and Chris Wright. ARM System Devel-oper’s guide Designing and Optimizing System Software.
[18] Keir Fraser Steven Hand Tim Harris Alex Ho Rolf Neugebauery Ian Pratt Andrew Warfield Paul Barham, Boris Dragovic. Xen and the art of virtual-ization. Technical report, University of Cambridge Computer Laboratory, 2003.
[19] Benjamin Roch. Monolithic vs microkernel. IEEE Multimedia.
[20] Margaret Rouse. Para-virtualization. http://searchservervirtualization.techtarget.com/definition/paravirtualization. Online; accessed 30-July-2012.
[21] Margaret Rouse. Virtualization. http://searchservervirtualization.techtarget.com/definition/virtualization, 2010. Online; accessed 27-July-2012.
[22] Oliver Schwarz and Christian Gehrmann. Securing dma through virtu-alization. In Proceedings of the 2nd IEEE International Conference on Complexity in Engineering, 2012.
[23] Arvind Seshadri, Mark Luk, Ning Qu, and Adrian Perrig. Secvisor: A tiny hypervisor to provide lifetime kernel code integrity for commodity oses. Technical report.
[24] VMware.Understanding Full Virtualization, Paravirtualization, and Hard-ware Assist. VMware Inc, 2007.
[25] Xen. How does xen work. pages 3–5, December 2009.
![Figure 1.4: SICS Hypervisor [2]](https://thumb-us.123doks.com/thumbv2/123dok_us/664524.2580136/18.892.276.614.460.814/figure-sics-hypervisor.webp)