Universidade de São Paulo
2014-08
Using contextual information from topic
hierarchies to improve context-aware
recommender systems
International Conference on Pattern Recognition, 22nd, 2014, Stockholm.
http://www.producao.usp.br/handle/BDPI/48599
Downloaded from: Biblioteca Digital da Produção Intelectual - BDPI, Universidade de São Paulo
Biblioteca Digital da Produção Intelectual - BDPI
Using Contextual Information from Topic
Hierarchies to Improve Context-Aware
Recommender Systems
Marcos Aur´elio Domingues∗, Marcelo Garcia Manzato∗, Ricardo Marcondes Marcacini†, Camila Vaccari Sundermann∗, Solange Oliveira Rezende∗
∗Institute of Mathematics and Computer Science - University of S˜ao Paulo S˜ao Carlos, SP, Brazil
{mad, mmanzato, camila, solange}@icmc.usp.br †Federal University of Mato Grosso do Sul
Trˆes Lagoas, MS, Brazil [email protected]
Abstract—Unlike the traditional recommender systems, that make recommendations only by using the relation between user and item, a context-aware recommender system makes recom-mendations by incorporating available contextual information into the recommendation process as explicit additional categories of data to improve the recommendation process. In this paper, we propose to use contextual information from topic hierarchies to improve the accuracy of context-aware recommender systems. Additionally, we also propose two context-aware recommender algorithms for item recommendation. These are extensions from algorithms proposed in literature for rating prediction. The empirical results demonstrate that by using topic hierarchies our technique can provide better recommendations.
I. INTRODUCTION
Nowadays, most web sites offer a large number of items (e.g., movies, music, web pages, etc) to their users. Finding relevant content according to each individual’s tastes has, thus, become a challenge. Recommender systems have emerged in response to this problem. A recommender system is an information filtering technology which can be used to predict preference ratings of items, not currently rated by the user, and/or to output a personalized ranking of items that are likely to be of interest to the user [1]. These systems have flourished on the Internet, and web sites such as Amazon1, Netflix2 and Last.fm3 are good examples of recommenders that adapt recommendations to particular user’s tastes.
Traditionally, the data that are most often available for recommender systems are web access logs which represent the interaction activity between users and items. Therefore, the most common systems focus on these two entities to build a model which is used to recommend an ordered list of 𝑁 items that are expected to be of interest to a certain user.
Unlike the traditional systems, that make recommendations only by using the relation 𝑈𝑠𝑒𝑟 ×𝐼𝑡𝑒𝑚, a context-aware
1http://www.amazon.com 2http://www.netflix.com 3http://www.last.fm
recommender system makes recommendations by incorporat-ing available contextual information into the recommendation process as explicit additional categories of data [2]:
𝑈𝑠𝑒𝑟×𝐼𝑡𝑒𝑚×𝐶𝑜𝑛𝑡𝑒𝑥𝑡→𝑅𝑒𝑐𝑜𝑚𝑚𝑒𝑛𝑑𝑎𝑡𝑖𝑜𝑛, where𝐶𝑜𝑛𝑡𝑒𝑥𝑡specifies the contextual information associated with the application.
There are many definitions of context in the literature de-pending on the field of application and the available customer data [1]. In this paper, context is defined as any information that can be used to characterize the situation of an entity (e.g., a web page) [3].
Thus, a promising way to improve the accuracy of rec-ommender systems is to incorporate additional information, such as context, besides the typical information about users and items. However, it is usually necessary an intense and time-consuming human effort to identify, collect and label this additional information about the items to be properly employed in recommender systems. Moreover, manually labeling the content becomes impracticable for large databases. Thus, in these situations, one possible solution is to use unsupervised learning methods. In this sense, topic hierarchies are efficient models to capture the context of textual data in order to orga-nize them [4]. These models allow the organization of items into topics and subtopics, providing an intuitive way to explore contextual information at different levels of granularity. Topic hierarchies can also be viewed as contextual information that characterize the items, and used to better characterize the user’s preferences with respect to the items.
In this paper, we propose to use contextual information from topic hierarchies to improve the accuracy of context-aware recommender systems. Additionally, we also propose two context-aware recommender algorithms for item recom-mendation. These are extensions of the algorithms proposed in [5] for rating prediction. The empirical results demonstrate 2014 22nd International Conference on Pattern Recognition
that by using topic hierarchies our technique can provide better recommendations.
This paper is structured as follows: in Section II we depict the related work. Section III discusses some definitions of context and the adopted one in this paper. In Section IV, we present our proposal. The learning of topic hierarchies is described in Section IV-A and the context-aware recom-mender systems are presented in Section IV-B. We evaluate our proposal in Section V. Finally, in Section VI, we present conclusion and future work.
II. RELATEDWORK
In this paper, we exploit the extraction of topic hierarchies, which capture information from web content as additional data used to improve context-aware recommender systems.
Some state-of-the-art approaches for contextual informa-tion extracinforma-tion from web content have been proposed in the literature. In [6], [7], the authors obtain contextual information from online reviews in order to improve item recommendation. In particular, Li et al. [6] compile a list of lexicons and use a string matching method to extract different types of contextual metadata from reviews. In [7], Hariri et al. propose a multi-labeled text classifier based on Labeled Latent Drichlet Allo-cation. They assume that there are explicit labels representing contextual information, and such information is obtained for each review by mapping it to the labels. Our proposal exploits an unsupervised method to learn topic hierarchies by analyzing the web content, and then, the extracted topics are used as context to characterize the items. Thus, it differs from [6], [7] because it does not need a lexicon or a set of labels to extract metadata, which usually are unavailable for web content.
In [8], Semeraro et al. propose to use a spreading activation algorithm in order to compute the correlation between terms from the web document and from a set of external knowledge sources related to linguistic, world and social domains. They use the most correlated external terms as meaningful contex-tual features in a content-based recommendation process. An important issue related to this approach is that it can only be used when external knowledge sources are available. Thus, our proposal takes some advantage over this approach since it can be used with internal and external data sources.
Regarding the use of context in the recommendation pro-cess, there is a growing research effort in finding better context-aware recommender algorithms. A context-aware rec-ommender system can be classified in three distinct categories, which differ from each other according to the use of context in the recommendation process [9]. In pre-filtering, the contextual information is used to filter out irrelevant items before building the recommendation model. In contextual modeling, the use of context is accomplished within the recommendation models. Finally, in post-filtering, the contextual information is used after building a traditional recommendation model to reorder or filter out recommendations.
To the best of our knowledge, the first context-aware recommender algorithm was proposed in [2]. This one is called combined reduction-based and consists of a pre-filtering algorithm which uses the contextual information as a label for filtering out those data that do not correspond to the
specified contextual information. This filtering procedure is accomplished before the main recommendation method, and is launched on the remaining data that passed the filter (con-textualized data) to generate the model. In [10], Domingues et al. propose a contextual modeling approach, called DaVI-BEST, that treats contextual information as virtual items, using them along with the regular items in a recommender system. Another contextual modeling approach is proposed by Shi et al. [11], which is based on Tensor Factorization for Mean Average Precision maximization (TFMAP). To generate top-𝑁 recommendations under different types of context, the technique optimizes the MAP metric for learning the model parameters, i.e., latent factors of users, items and context types. With respect to post-filtering approaches, two methods for rating prediction are proposed in [5]. The methods first ignore all the contextual information in the data and apply a traditional𝑈𝑠𝑒𝑟×𝐼𝑡𝑒𝑚recommendation method on the whole un-contextual data set. After building/learning the traditional model, the contextual information is used to contextualize (i.e., reorder or filter out) the recommendations generated by the model. As we will see in next sections, our proposal extends the two methods proposed in [5] to generate item recommendations to the users instead of rating prediction.
III. HIERARCHICALCONTEXTINFORMATION
According to [12], the concept of context has been studied extensively in areas of computing and other disciplines. As it has already been mentioned before, context can be defined in many ways, depending on the field of application. After examining150 different definitions of context from different fields, Bazire and Brezillon [13] concluded that it’s difficult to find a unifying definition. They raised some questions, such as: “Is context a frame for a given object? Is it the set of elements that have any influence on the object? Is something static or dynamic?”. For Dourish [14], there are two different views of context: the interactional view and the representational view. In the interactional view the context is defined dynamically and there is a relationship between context and activity, in which the activity gives rise to context and context influences activity. In contrast, in representational view, context can be described as a set of known attributes, whose structure does not change through the time.
The most widely accepted definition of context and that was used in this paper was proposed by Dey [3]: “Context is any information that can be used to characterize the situation of an entity”. The entities are, in our work, web pages. The contextual information can be organized as a hierarchical structure that can be represented as trees [2], [15], [5]. In this way, the contextual information is a set of contextual dimensions 𝐶, where each dimension 𝐶 is defined by a set of𝑡 attributes/values, i.e., 𝐶 =𝑐1, 𝑐2, ..., 𝑐𝑡. These attributes have a hierarchical structure. The values taken by attribute𝑐𝑡 define more granular levels, while𝑐1less granular levels of the contextual information. For example, in [5], they represented the contextual attribute “period of the year” as a hierarchical structure illustrated in Figure 1.
IV. OUR PROPOSAL
In this paper, we first propose to use an unsupervised learn-ing method, called BC2(Buckshot Consensus Clustering) [4],
Fig. 1: Hierarchical structure of the contextual attribute “period of the year” [5]
to generate topic hierarchies from textual data, that can be viewed as contextual information that characterize the items. In Figure 2 we see a dendrogram (i.e., a topic hierarchy), which is a binary tree where each node represents a set of documents and there are contextual descriptors/topics that indicate the context of these documents. Then, we use the contextual information (topics) to characterize the items in a context-aware recommender system.
Fig. 2: Example of dendrogram [16]
A. Contextual Information from Topic Hierarchies
Although the use of textual information available about the items is a promising way to improve the accuracy of recommendation systems, there are many challenges on how to extract useful knowledge from these textual information [17]. Textual data are inherently unstructured, thereby requiring the application of techniques for text preprocessing to represent textual data in a concise and representative manner. More-over, choosing the appropriate algorithm for extracting and organizing knowledge from texts, such as algorithms for topic hierarchies construction, is an important task for context-aware recommender systems.
Several approaches have been proposed in literature for topic hierarchies construction, such as algorithms based on term-clustering [18], [19] and clustering labeling [17]. Despite the large number of existing algorithms, no single algorithm is able to extract all possible topic structures from texts [20]. Each algorithm has a bias regarding the coverage and number of topics, making it difficult to decide which one is the best algorithm for each possible domain. For example, even a single topic hierarchy construction algorithm, with different initializa-tions and parameters, can produce very different results.
In this sense, we use an approach for topic hierarchy construction based on the consensus clustering called BC2 (Buckshot Consensus Clustering) [4]. In BC2 approach, it is possible to combine solutions of different topic extraction algorithms in a single consensual solution. The results obtained with consensus clustering are promising in many aspects. Combining different structures usually results in a final solu-tion of better quality than the individual solusolu-tions. Moreover, consensus clustering is easily parallelizable, promoting the scalability of applications.
In BC2approach, several topics are initially extracted from textual data by executing different topic extraction algorithms. Each topic has a set of associated text documents (textual information about the items). Assuming that similar documents will be allocated on the same topics in several of the different solutions, then we compute a co-association matrix. The basic idea is to summarize a set of topics 𝑇 by means of a matrix where each element has the value 𝑀(𝑤, 𝑣) = 𝑎𝑤𝑣∣𝑇∣ where 𝑎𝑤𝑣 is the number of times that the textual information about
the items 𝑤 and 𝑣 are allocated in the same topic. The co-association matrix represents a new proximity relationship for the textual information about the items.
The “consensus” topic hierarchy is constructed from the relations of co-association matrix. The BC2 approach uses an agglomerative clustering strategy to compute the dendrogram. In this case all the documents are initially considered single-tons (unitary clusters). Then the most similar pairs of clusters are iteratively merged until all the documents are allocated into a single cluster. Finally, it is associated a set of descriptors for each (sub)cluster of the dendrogram, thereby obtaining a topic hierarchy. For the descriptors extraction, we can use the most frequent terms (keywords, phrases, or expressions) of each cluster or even apply feature selection techniques to select relevant terms of each cluster.
B. Context-Aware Recommender Systems
The proposed context-aware recommender systems are based on the well known Item-based Collaborative Filtering algorithm [21], which analyzes items in order to identify relations among them.
Let𝑚 be the number of users𝑈 ={𝑢1, 𝑢2, ..., 𝑢𝑚} and 𝑛the number of all possible items that can be recommended 𝐼 = {𝑖1, 𝑖2, ..., 𝑖𝑛}. In addition, we also have the contextual information𝐶={𝑐1, 𝑐2, ..., 𝑐𝑡}, where each𝑐comprehends a contextual value. An item-based collaborative filtering model 𝑀 is a matrix representing the similarities between all the pairs of items, according to a similarity metric. An abstract representation of a similarity matrix is shown in Table I. Each item𝑖∈𝐼 is an accessed item, for example, a web page.
TABLE I: Item-item similarity matrix
𝑖1 𝑖2 ⋅ ⋅ ⋅ 𝑖𝑛
𝑖1 1 𝑠𝑖𝑚(𝑖1, 𝑖2) ⋅ ⋅ ⋅ 𝑠𝑖𝑚(𝑖1, 𝑖𝑛)
𝑖2 𝑠𝑖𝑚(𝑖2, 𝑖1) 1 ⋅ ⋅ ⋅ 𝑠𝑖𝑚(𝑖2, 𝑖𝑛)
⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ ⋅ 1 ⋅ ⋅ ⋅ 𝑖𝑛 𝑠𝑖𝑚(𝑖𝑛, 𝑖1) 𝑠𝑖𝑚(𝑖𝑛, 𝑖2) ⋅ ⋅ ⋅ 1
According to [21], the properties of the model and, con-sequently, the effectiveness of this recommendation algorithm
depend on the method used to calculate the similarity among the items. To compute the similarity 𝑠𝑖𝑚(𝑖1, 𝑖2)between the items𝑖1and𝑖2, for instance, we first isolate their ratings which were commonly assigned by the same users, and then, we apply a similarity metric between both rating vectors. In [22], the authors present three metrics to measure similarity between pairs of items: cosine angle, Pearson’s correlation and adjusted cosine angle. In this paper, because of its better accuracy, we use the cosine angle metric, defined as:
𝑠𝑖𝑚(𝑖1, 𝑖2) =𝑐𝑜𝑠(−→𝑖1,−→𝑖2) = − →𝑖 1⋅−→𝑖2 ∣∣−→𝑖1∣∣ ∗ ∣∣−→𝑖2∣∣ , (1)
where−→𝑖1 and −→𝑖2 are rating vectors with as many positions as existing users in the set𝑈. The operator “⋅” denotes the dot-product of the two vectors. In our case, as we are dealing only with implicit feedback, the rating vectors are binary. The value 1 means that the user accessed the respective item, whereas the value0is the opposite.
Once we obtain the recommendation model, we can gen-erate the recommendations. Given an active user 𝑢𝑎 and its set of observable items 𝑂 ⊆ 𝐼, the model generates the 𝑁 recommendations as follows. First, we identify the set of candidate items for recommendation𝑅by selecting from the model all items𝑖 /∈𝑂. Then, for each candidate item 𝑟∈𝑅, we calculate its recommendation score (i.e., its similarity to the set𝑂) as:
𝑠𝑐𝑜𝑟𝑒(𝑢𝑎, 𝑂, 𝑟) = ∑ 𝑖∈𝐾𝑟∩𝑂𝑠𝑖𝑚(𝑟, 𝑖) ∑ 𝑖∈𝐾𝑟𝑠𝑖𝑚(𝑟, 𝑖) , (2)
where𝐾𝑟 is a set with the𝑘 most similar items (the nearest neighbors) to the candidate item𝑟. The 𝑁 candidate items with the highest score are recommended to the user𝑢𝑎.
In order to contextualize the candidate item 𝑟, before recommending it to the user𝑢𝑎, we compute the probability 𝑃𝑐(𝑢𝑎, 𝑟)of a user𝑢𝑎to access an item𝑟under a given context 𝑐. This post-filtering (𝑃 𝑜𝐹) approach was previously proposed in [5] for rating prediction. In this paper, we extend it for item recommendation. We define the probability𝑃𝑐(𝑢𝑎, 𝑟)as
𝑃𝑐(𝑢𝑎, 𝑟) =𝑁𝑢𝑚𝑁𝑢𝑚𝑐(𝑢, 𝑟)
𝑐(𝑢) , (3)
where 𝑁𝑢𝑚𝑐(𝑢, 𝑟) is the number of users 𝑢 that, similarly to user𝑢𝑎, also accessed the item𝑟 under the context𝑐; and 𝑁𝑢𝑚𝑐(𝑢)is the total number of users that accessed any item
under the context𝑐.
We also extend the𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹and𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹methods, proposed in [5], for using the probability𝑃𝑐(𝑢𝑎, 𝑟)to contex-tualize the item recommendation. The𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹multiplies each𝑠𝑐𝑜𝑟𝑒(𝑢𝑎, 𝑂, 𝑟)of a user by𝑃𝑐(𝑢𝑎, 𝑟), i.e.,
𝑠𝑐𝑜𝑟𝑒𝑐(𝑢𝑎, 𝑂, 𝑟) =𝑠𝑐𝑜𝑟𝑒(𝑢𝑎, 𝑂, 𝑟)×𝑃𝑐(𝑢𝑎, 𝑟), (4) whereas 𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 filters recommendations out based on a threshold value𝑃∗with respect to 𝑃𝑐(𝑢𝑎, 𝑟):
𝑠𝑐𝑜𝑟𝑒𝑐(𝑢𝑎, 𝑂, 𝑟) = {
𝑠𝑐𝑜𝑟𝑒(𝑢𝑎, 𝑂, 𝑟) if𝑃𝑐(𝑢𝑎, 𝑟)≥𝑃∗
0 if𝑃𝑐(𝑢𝑎, 𝑟)< 𝑃∗
(5) The intuition behind the𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 heuristic is that if only few similar users access an item under a particular context, therefore, it is better not to recommend this item to the user, even though the un-contextual score is high and suggests recommending that item to the user.
V. EMPIRICALEVALUATION
The empirical evaluation consists of comparing 𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹 and 𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 approaches against the un-contextual item-based collaborative filtering (i.e., 𝑈𝑠𝑒𝑟 × 𝐼𝑡𝑒𝑚) in order to demonstrate how much the results are influenced if we adopt hierarchical topics as contextual information.
A. Data Set
The experiments were executed with a data set from an agrobusiness web site. The data set consists of 4,659 users and 1,543 different web pages about agrobusiness written in Portuguese language. This textual data is used directly to obtain the set of topics. The users generated a total of15,037 accesses to these pages.
In this evaluation, we considered the topics generated by the BC2 method as contextual information. For the topic hierarchy construction, we used different runs of the well-known𝑘-means algorithm (with random centers initializations and cosine similarity) to obtain several data partitions for the consensus clustering. To analyze the effect of the number of topics used as context in the recommendation task, we selected subsets of topics using seven different granularities:{50,100},
{15,20},{10,15},{10,50},{5,10},{5,100} and{2,7}. In the granularity configuration{𝑥, 𝑦}, the parameter𝑥identifies the minimum number of items allowed in the topic, while the parameter𝑦 identifies the maximum number of items per topic. When a topic has a few items associated, usually the topic represents more specific contextual information. On the other hand, topics with many items associated represent more general contextual information about the items. Thus, the seven configurations presented above generate subsets of 26, 44, 101, 210, 305, 510 and 1230 topics, respectively, for the data set. B. Experimental Setup and Evaluation Measures
To measure the predictive ability of the recommender systems, we use the All But One protocol [23] with10-fold cross validation, and calculate the metrics Precision and Mean Average Precision (MAP) [24]. To do this, the sessions in the data set are randomly partitioned into 10 subsets. For each fold, we use 𝑛−1 of those subsets of data for training and the remaining one for testing. The training set 𝑇𝑟 is used to build the recommendation model. For each user in the test set 𝑇𝑒, we randomly hide one item, referred to as the singleton set𝐻. The remaining items represent the set of observables, 𝑂, based on which the recommendation is made. Then, we compute Precision and Mean Average Precision as follows:
Precisioncalculates the percentage of recommended items that are relevant. This metric is calculated by comparing, for each user in the test set𝑇𝑒, the set of recommendations𝑅that the system makes, given the set of observables𝑂, against the set𝐻: 𝑃 𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛(𝑇𝑒) = ∣𝑇1 𝑒∣ ∣𝑇𝑒∣ ∑ 𝑗=1 ∣𝑅𝑗∩𝐻𝑗∣ ∣𝑅𝑗∣ . (6)
Mean Average Precisioncomputes the precision consider-ing the respective position in the ordered list of recommended items. With this metric, we obtain a single value accuracy score for a set of test users𝑇𝑒:
𝑀𝐴𝑃(𝑇𝑒) = ∣𝑇1 𝑒∣ ∣𝑇𝑒∣ ∑ 𝑗=1 𝐴𝑣𝑒𝑃(𝑅𝑗, 𝐻𝑗), (7) where the average precision (AveP) is given by
𝐴𝑣𝑒𝑃(𝑅𝑗, 𝐻𝑗) = ∣𝐻1 𝑗∣ ∣∑𝐻𝑗∣ 𝑟=1 [𝑃 𝑟𝑒𝑐(𝑅𝑗, 𝑟)×𝛿(𝑅𝑗(𝑟), 𝐻𝑗)], (8) where𝑃 𝑟𝑒𝑐(𝑅𝑗, 𝑟)is the precision for all recommended items up to rank 𝑟 and 𝛿(𝑅𝑗(𝑟), 𝐻𝑗) = 1, iff the predicted item at rank𝑟 is a relevant item(𝑅𝑗(𝑟)∈𝐻𝑗)or zero otherwise.
In the empirical evaluation, we computed Precision@𝑁, for 𝑁 equal to1,2,3,5and10recommendations; and MAP@𝑁, for𝑁 equal to5and10recommendations. For each configura-tion and measure, the10-fold values are summarized by using mean and standard deviation. To compare two recommendation algorithms, we apply the two-sided paired t-test with a 95% confidence level. For the item-based collaborative filtering algorithm, we used the 4 most similar items to make the top 𝑁 recommendations (i.e., ∣𝐾𝑟∣ = 4), because this value provided the best results. In the experiments, we also varied the threshold value𝑃∗ from 0.1 to 0.9, and obtained the best results for𝑃∗= 0.1, which are presented as follows. C. Results
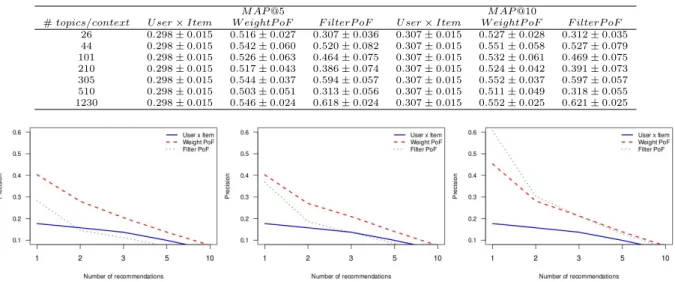
In Table II, we present the ranking evaluation by means of MAP@5 and MAP@10 for the two context-aware rec-ommendation algorithms (𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹 and𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹), and also for the 𝑈𝑠𝑒𝑟×𝐼𝑡𝑒𝑚 collaborative approach, which is used as baseline. The results were obtained at different levels of granularity: as previously mentioned, higher amount of topics means that more specific context types are used by the algorithm. In the table, it is possible to note that, for most granularity levels, both context-aware techniques were able to obtain a statistically significant improvement over the baseline. The baseline, in turn, obtained the same results regardless of the amount of topics because it does not use contextual information. In addition, the best results of both context-aware recommenders were obtained when the highest number of topics was considered, which means that the more the system knows about the context, the better is the accuracy. This
conclusion implies that the design of a recommender algorithm should consider gathering contextual information as much as possible; the advantage of our proposal, in this argument, is that this information extraction procedure is accomplished by an unsupervised technique.
In Figure 3 it is possible to get a better insight of the algorithms’ accuracy according to the number of topics. We selected three granularity levels (most general, most specific and one mid-term), and compared the precision accuracy for a varying number of recommendations. Analyzing Figure 3, we note that 𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 obtained low precision when us-ing general context types, whereas its accuracy increased to the best of the three algorithms when more specific context types were considered. On the other hand, 𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹 also achieved better results when more specific context types were considered, but such improvement was not as significant as the one obtained by𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹. This difference can be explained by the design of these two context-aware algorithms: in the case of 𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹, it will recommend items under a given context only if such context is relevant for those candidate items, i.e., the probability𝑃𝑐(𝑢𝑎, 𝑟)is higher than the threshold 𝑃∗. Indeed, as explained in Section IV-B, such probability is
computed by the number of users who access the candidate item under a particular context divided by the number of users who access any item under that context. Thus, given that more specific context types mean fewer items, such probability will have a stronger influence over the decision process.
Regarding𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹, the importance of a given context is used to weight the score of a candidate item by means of multiplying its probability with the similarity values computed between the candidate and the observable items. In other words, items which are very similar to the observable ones may be recommended regardless of the considered context, which is used, in turn, only to weight the score function.
VI. CONCLUSIONS
In this paper, we proposed to use contextual information from topic hierarchies to improve the accuracy of context-aware recommender systems. Additionally, we also proposed two context-aware recommender algorithms for item recom-mendation. These are extensions from algorithms proposed in literature for rating prediction. The empirical evaluation showed that by using topic hierarchies our technique can provide better recommendations.
As future work, we will expand our findings by using other data sets as well as other context-aware recommender systems in order to evaluate the effects of using topic hierar-chies as contextual information in context-aware recommender systems. We will also compare our topic hierarchy proposal against other algorithms for generating contextual information.
ACKNOWLEDGMENT
Thanks to the support from grants 2010/20564-8, 2011/19850-9, 2012/13830-9, 2013/16039-3, 2013/22547-1, S˜ao Paulo Research Foundation (FAPESP); CAPES and CNPq.
REFERENCES
[1] F. Ricci, L. Rokach, B. Shapira, and P. B. Kantor, Eds.,Recommender Systems Handbook. Springer, 2011.
TABLE II: Comparing the context-aware recommendation algorithms against the𝑈𝑠𝑒𝑟×𝐼𝑡𝑒𝑚algorithm. Values for𝑊𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹 and𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 are statistically significant (𝑝-value<0.05)
𝑀𝐴𝑃@5 𝑀𝐴𝑃@10 #𝑡𝑜𝑝𝑖𝑐𝑠/𝑐𝑜𝑛𝑡𝑒𝑥𝑡 𝑈𝑠𝑒𝑟×𝐼𝑡𝑒𝑚 𝑊 𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹 𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 𝑈𝑠𝑒𝑟×𝐼𝑡𝑒𝑚 𝑊 𝑒𝑖𝑔ℎ𝑡𝑃 𝑜𝐹 𝐹 𝑖𝑙𝑡𝑒𝑟𝑃 𝑜𝐹 26 0.298±0.015 0.516±0.027 0.307±0.036 0.307±0.015 0.527±0.028 0.312±0.035 44 0.298±0.015 0.542±0.060 0.520±0.082 0.307±0.015 0.551±0.058 0.527±0.079 101 0.298±0.015 0.526±0.063 0.464±0.075 0.307±0.015 0.532±0.061 0.469±0.075 210 0.298±0.015 0.517±0.043 0.386±0.074 0.307±0.015 0.524±0.042 0.391±0.073 305 0.298±0.015 0.544±0.037 0.594±0.057 0.307±0.015 0.552±0.037 0.597±0.057 510 0.298±0.015 0.503±0.051 0.313±0.056 0.307±0.015 0.511±0.049 0.318±0.055 1230 0.298±0.015 0.546±0.024 0.618±0.024 0.307±0.015 0.552±0.025 0.621±0.025
Fig. 3: Comparison of considered recommendation algorithms at different granularities and top-𝑁 recommendations: the graphic on the left-hand side shows the obtained results using more general context types (26 topics); on the center using context types at mid-term granularity (210 topics); and on the right-hand side using more specific context types (1230 topics)
[2] G. Adomavicius, R. Sankaranarayanan, S. Sen, and A. Tuzhilin, “Incor-porating contextual information in recommender systems using a mul-tidimensional approach,”ACM Transactions on Information Systems, vol. 23, no. 1, pp. 103–145, 2005.
[3] A. K. Dey, “Understanding and using context,”Personal Ubiquitous Computing, vol. 5, no. 1, pp. 4–7, 2001.
[4] R. M. Marcacini, E. R. Hruschka, and S. O. Rezende, “On the use of consensus clustering for incremental learning of topic hierarchies,” in
Proceedings of the 21st Brazilian conference on Advances in Artificial Intelligence, 2012, pp. 112–121.
[5] U. Panniello and M. Gorgoglione, “Incorporating context into recom-mender systems: an empirical comparison of context-based approaches,”
Electronic Commerce Research, vol. 12, no. 1, pp. 1–30, 2012. [6] Y. Li, J. Nie, Y. Zhang, B. Wang, B. Yan, and F. Weng, “Contextual
recommendation based on text mining,” inProceedings of the 23rd International Conference on Computational Linguistics: Posters (COL-ING’10), 2010, pp. 692–700.
[7] N. Hariri, B. Mobasher, R. Burke, and Y. Zheng, “Context-aware recom-mendation based on review mining,” inProceedings of the 9th Workshop on Intelligent Techniques for Web Personalization and Recommender Systems (ITWP’11), 2011, pp. 1–7.
[8] G. Semeraro, P. Lops, P. Basile, and M. de Gemmis, “Knowledge infusion into content-based recommender systems,” inProceedings of the 2009 ACM conference on Recommender systems (RecSys’09), 2009, pp. 301–304.
[9] G. Adomavicius and A. Tuzhilin, “Context-aware recommender sys-tems,” inProceedings of the 2008 ACM conference on Recommender systems (RecSys’08), 2008, pp. 335–336.
[10] M. A. Domingues, A. M. Jorge, and C. Soares, “Dimensions as virtual items: Improving the predictive ability of top-n recommender systems,”
Information Processing & Management, vol. 49, no. 3, pp. 698–720, 2013.
[11] Y. Shi, A. Karatzoglou, L. Baltrunas, M. Larson, N. Oliver, and A. Han-jalic, “Climf: learning to maximize reciprocal rank with collaborative less-is-more filtering,” inProceedings of the 2012 ACM Conference on Recommender Systems (RecSys’12), 2012, pp. 139–146.
[12] G. Adomavicius, B. Mobasher, F. Ricci, and A. Tuzhilin, “Context-aware recommender systems,” Association for the Advancement of Artificial Intelligence, vol. 32, no. 3, pp. 67–80, 2011.
[13] M. Bazire and P. Brezillon, “Understanding context before using it,” inProceedings of the 5th International Conference on Modeling and Using Context (CONTEXT’05), 2005, pp. 29–40.
[14] P. Dourish, “What we talk about when we talk about context,”Personal Ubiquitous Computing, vol. 8, no. 1, pp. 19–30, Feb. 2004.
[15] C. Palmisano, A. Tuzhilin, and M. Gorgoglione, “Using context to improve predictive modeling of customers in personalization applica-tions,”IEEE Transactions on Knowledge and Data Engineering, vol. 20, no. 11, pp. 1535–1549, 2008.
[16] R. M. Marcacini and S. O. Rezende, “Incremental construction of topic hierarchies using hierarchical term clustering,” inProceedings of the 22nd International Conference on Software Engineering and Knowledge Engineering, 2010, pp. 553–558.
[17] C. C. Aggarwal and C. Zhai, “A survey of text clustering algorithms,” inMining Text Data, 2012, pp. 77–128.
[18] M. Sanderson and B. Croft, “Deriving concept hierarchies from text,” inProceedings of the 22nd International Conference on Research and Development in Information Retrieval (SIGIR’99), 1999, pp. 206–213. [19] M. Clark, Y. Kim, U. Kruschwitz, D. Song, D. Albakour, S. Dignum, U. C. n. Beresi, M. Fasli, and A. De Roeck, “Automatically structur-ing domain knowledge from text: An overview of current research,”
Information Processing & Management, vol. 48, no. 3, pp. 552–568, 2012.
[20] N. Nguyen and R. Caruana, “Consensus clusterings,” inProceedings of the 2007 Seventh IEEE International Conference on Data Mining (ICDM’07), 2007, pp. 607–612.
[21] M. Deshpande and G. Karypis, “Item-based top-n recommendation algorithms,”ACM Transaction on Information System, vol. 22, no. 1, pp. 143–177, 2004.
[22] B. Sarwar, G. Karypis, J. Konstan, and J. Riedl, “Item-based collabora-tive filtering recommendation algorithms,” inProceedings of the Tenth International Conference on World Wide Web, 2001, pp. 285–295. [23] J. S. Breese, D. Heckerman, and C. M. Kadie, “Empirical analysis of
predictive algorithms for collaborative filtering.” inProceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, 1998, pp. 43–52.
[24] E. Voorhees, D. Harman, N. I. of Standards, and T. (US), TREC: Experiment and evaluation in information retrieval. MIT Press Cambridge, 2005, vol. 63.
![Fig. 1: Hierarchical structure of the contextual attribute “period of the year” [5]](https://thumb-us.123doks.com/thumbv2/123dok_us/421221.2548336/4.918.132.399.110.231/fig-hierarchical-structure-contextual-attribute-period-year.webp)